XDP使用介绍
XDP全称为**eXpress Data Path**,是Linux内核网络栈的最底层,它只存在于RX路径上,允许在网络设备驱动内部网络堆栈中数据来源最早的地方进行数据包处理,在特定模式下可以在操作系统分配内存。 XDP只可以出处理设备入口流量控制。
XDP输入参数
XDP暴露的钩子具有特定的输入上下文,它是单一输入参数。它的类型为 **struct xdp_md**,在内核头文件[bpf.h](https://elixir.bootlin.com/linux/latest/source/include/uapi/linux/bpf.h#L3309) 中定义,具体字段如下所示:
/* user accessible metadata for XDP packet hook
* new fields must be added to the end of this structure
*/
struct xdp_md {
__u32 data;
__u32 data_end;
__u32 data_meta;
/* Below access go through struct xdp_rxq_info */
__u32 ingress_ifindex; /* rxq->dev->ifindex */
__u32 rx_queue_index; /* rxq->queue_index */
};
容器环境引入XDP
容器环境是怎么引入xdp. 以下面实例图模拟一个简单容器环境,容器环境网络命名空间是 `container1` ,通过 `veth` 对和主机连接,容器内部接口是 `eth0` 外部通过 `veth0` 接入容器网桥 `cni0` (相当于docker bridge0),通过XDP可以配置容器外部访问这个容器规则,这些规则可以在加入到 `veth0` 上。如图:<br /> 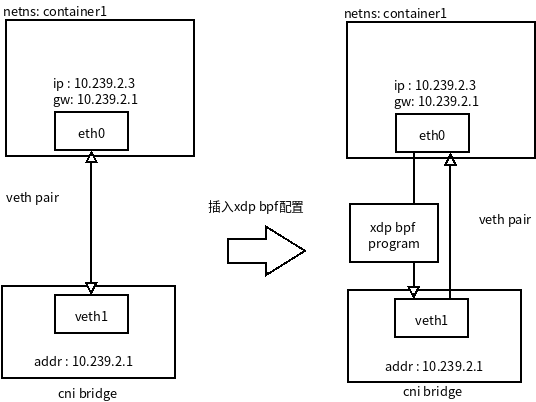<br /> 由于 `veth1` 网桥 `cni0` 上,所有外部或者主机量都是由 `cni0` 进入的,有 `veth1` 发送到 `continer1` 命名空间 `eth0` 接口 ,对应 `veth1` 的RX流量都是从 `eth0` 接口发送出来的流量。可以说 `veth1` Rx流量都是 `from continer` 流量。网络如下图上半部分。容器使用veth对虚拟网卡,可以通过**通用 XDP兼容模式**,加载bpf grogram如图:<br />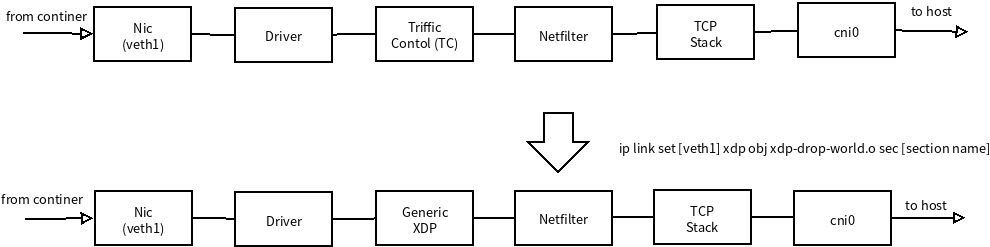
XDP 开发环境搭建
linux 内核
4.8 或以上的版本, 内核对应dev, healders文件yum install kernel-devel kernel-headers安装依赖的软件包
$ yum install clang llvm iproute2 -y编写第一个XDP程序
Facebook基于XDP实现高效的防DDoS攻击,其本质上就是实现尽可能早地实现「丢包」,而不去消耗系统资源创建完整的网络栈链路,即「early drop」。
那么第一个XDP程序就来模拟防DDoS最重要的操作,取名为「丢掉你的整个世界」。如果你对第一个程序的设计有其他想法,建议可以去Linux源码里找找灵感:
xdp-drop-world.c#include <linux/bpf.h> /* * Comments from Linux Kernel: * Helper macro to place programs, maps, license in * different sections in elf_bpf file. Section names * are interpreted by elf_bpf loader. * End of comments * You can either use the helper header file below * so that you don't need to define it yourself: * #include <bpf/bpf_helpers.h> */ #define SEC(NAME) __attribute__((section(NAME), used)) SEC("xdp") int xdp_drop_the_world(struct xdp_md *ctx) { // drop everything // 意思是无论什么网络数据包,都drop丢弃掉 return XDP_DROP; } char _license[] SEC("license") = "GPL";编译XDP程序
可以利用clang命令行工具配合后端编译器LLVM来进行操作
$ clang -O2 -target bpf -c xdp-drop-world.c -o xdp-drop-world.o还可以通过llvm-objdump这个工具来分析下这个可执行文件的反汇编指令信息:
$ llvm-objdump -S xdp-drop-world.o xdp-world-drop.o: file format ELF64-BPF Disassembly of section xdp: #xdp 程序入口section标签 ip命名时候用到的 xdp_drop_the_world: 0: b7 00 00 00 01 00 00 00 r0 = 1 # 1代表XDP_DROP,这句指令表示赋值1到代表返回值的寄存器r0 1: 95 00 00 00 00 00 00 00 exit加载XDP层序
通用XDP模式程序可以通过
ip命令把XDP加载到内核的XDP Hook上。上命令:$ ip link set dev [nic-device-name] xdp obj xdp-drop-world.o sec [section name]sec [section name]就是上文提到的通过Section来指定程序入口
device name是本机某个网卡设备的名称,可以通过ip a查看本机所有的网卡设备。
搭建测试环境
一台台虚拟机器:
node60 eth1 ip 10.5.7.60
容器网络模拟
- netns: 1个名称为: container1
- 接口对:1对 veth1->[container1]eth1,
- 网桥: cni0 : 10.239.2.1
如图:
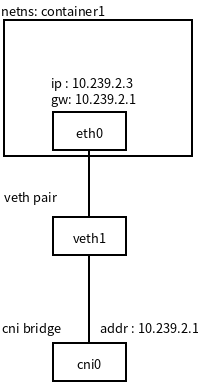
添加网桥接口
添加网桥 `cni0` , ip地址为10.239.2.1, 并且启动网络
$ ip link add cni0 type bridge
$ ip addr add dev cni0 10.239.2.1/24
$ ip link set cni0 up
$ ping 10.239.2.1
PING 10.239.2.1 (10.239.2.1) 56(84) bytes of data.
64 bytes from 10.239.2.1: icmp_seq=1 ttl=64 time=0.057 ms
64 bytes from 10.239.2.1: icmp_seq=2 ttl=64 time=0.027 ms
添加容器网络
添加容器1网络,容器1网络地址为10.239.2.3, 默认路由为10.239.2.1
# 添加容器网络空间
$ ip netns add container1
# 容器基础网络连接
# 1)添加容器1接口对, veth0->veth1,
# 2)把 veth1 移动到container1网络空间,改名为eth0,
# 3)veth0 接入到网桥
$ ip link add veth0 type veth peer name veth1
$ ip link set veth1 netns container1
$ ip netns exec container1 ip link set veth1 name eth0
$ ip link set veth0 master cni0
$ 启动容器网络
$ ip link set veth0 up
$ ip netns exec container1 ip addr add dev eth0 10.239.2.3/24
$ ip netns exec container1 ip link set eth0 up
$ ip netns exec container1 ip link set lo up
$ 配置容器网络路由
$ ip netns exec container1 ip route add default via 10.239.2.1 dev eth0
测试容器网络
测试通过后网络接口配置没有问题
## 容器网络出host
# 容器环接口
$ ip netns exec container1 ping 10.239.2.3
# 容器网络访问网关
$ ip netns exec container1 ping 10.239.2.1
# 容器访问host网络
$ ip netns exec container1 ping 10.5.7.60
## host到容器
$ ping 10.239.2.3
启动和关闭XDP配置
# 启动xdp
ip link set dev veth0 xdp obj /path/to/xdp-drop-world.o sec xdp verbose
# 屏蔽xdp
ip link set dev veth0 xdp off
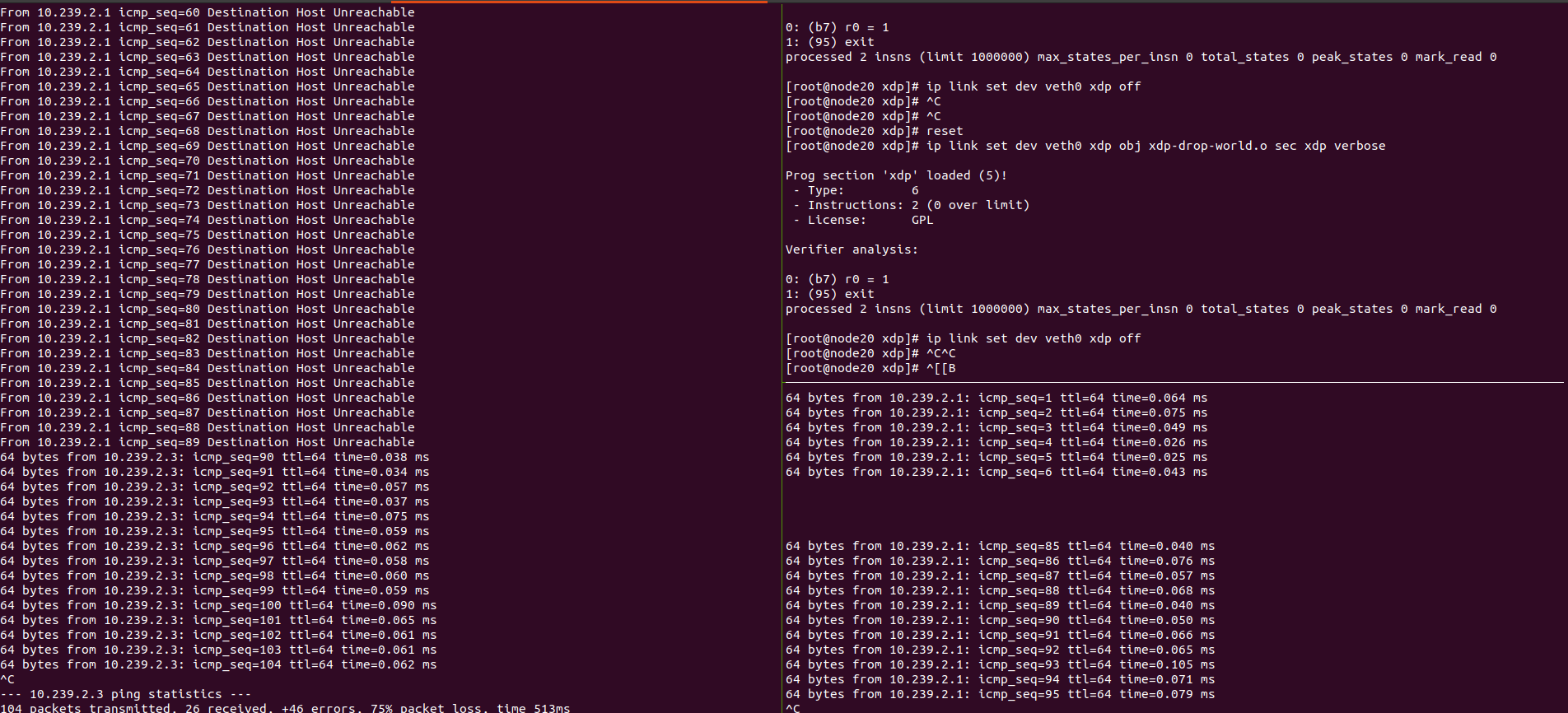
由于在 veth1 加入xdp,容器输出到外部都会流入 veth1 都会流入此接口,所有都被屏蔽了,加入以后容器出/进入容器网络都不通。
XDP 容器网络单向限制
由于xdp接入到`veth1` 上,xdp上数据流称为 `form_continer` 从容器里面流入数据,例如外面访问容器网络时候,容器返回数据数据包就经过 `veth1` 这个xdp。 XDP刚才代码是双向限制,把容器返回数据包都限制了,外面访问容器也不通了。如果可以判断源ip, 目标ip网段,这样就可以实现单向单向限制
XDP 限制容器访问外网
实现一个可以限制容器访问外网,外部可以访问容器服务XDP限制。可以这样实现。由于容器命名空间通过 veth1 接入到 cni0 , 所有所用外网访问都会转化为下面访问:
10.239.2.1 - > 10.239.2.3
这两个访问都是在同一网段 10.239.2.0 ,所有可以通过xdp判断dst地址是否为容器网段 10.239.2.0 可以了,代码可以修改为:
xdp-drop-external-debug.c
#include <stdbool.h>
#include <linux/bpf.h>
#include <linux/if_ether.h>
#include <linux/ip.h>
#include <linux/in.h>
#include <linux/pkt_cls.h>
#include <stdio.h>
#include "bpf_endian.h"
#include "bpf_helpers.h"
/*
check whether the packet is of TCP protocol
*/
static __inline bool is_to_external(void *data_begin, void *data_end){
struct ethhdr *eth = data_begin;
// Check packet's size
// the pointer arithmetic is based on the size of data type, current_address plus int(1) means:
// new_address= current_address + size_of(data type)
if ((void *)(eth + 1) > data_end) //
return false;
// Check if Ethernet frame has IP packet
if (eth->h_proto == bpf_htons(ETH_P_IP))
{
struct iphdr *iph = (struct iphdr *)(eth + 1); // or (struct iphdr *)( ((void*)eth) + ETH_HLEN );
if ((void *)(iph + 1) > data_end)
return false;
// extract src ip and destination ip
u32 ip_src = iph->saddr;
u32 ip_dst = iph->daddr;
// net mask 255.255.255.0
u32 mask = bpf_htonl(0xffffff00);
// check dst if is container network
u32 dst_net_seg = ip_dst & mask;
// 10.239.2.0
u32 veth_net_seg = bpf_htonl(0x0aef0200);
// pkg come from container veth
if (dst_net_seg != veth_net_seg) {
return true;
}
}
return false;
}
SEC("xdp_from_container")
int xdp_drop_to_external_network(struct xdp_md *ctx)
{
void *data_end = (void *)(long)ctx->data_end;
void *data = (void *)(long)ctx->data;
if (is_to_external(data, data_end))
return XDP_DROP;
return XDP_PASS;
}
char _license[] SEC("license") = "GPL";
头文件
bpf_endian.h 网络<->主机 大小端互换
#include <linux/swab.h>
/* LLVM's BPF target selects the endianness of the CPU
* it compiles on, or the user specifies (bpfel/bpfeb),
* respectively. The used __BYTE_ORDER__ is defined by
* the compiler, we cannot rely on __BYTE_ORDER from
* libc headers, since it doesn't reflect the actual
* requested byte order.
*
* Note, LLVM's BPF target has different __builtin_bswapX()
* semantics. It does map to BPF_ALU | BPF_END | BPF_TO_BE
* in bpfel and bpfeb case, which means below, that we map
* to cpu_to_be16(). We could use it unconditionally in BPF
* case, but better not rely on it, so that this header here
* can be used from application and BPF program side, which
* use different targets.
*/
#if __BYTE_ORDER__ == __ORDER_LITTLE_ENDIAN__
# define __bpf_ntohs(x)__builtin_bswap16(x)
# define __bpf_htons(x)__builtin_bswap16(x)
# define __bpf_constant_ntohs(x)___constant_swab16(x)
# define __bpf_constant_htons(x)___constant_swab16(x)
# define __bpf_ntohl(x)__builtin_bswap32(x)
# define __bpf_htonl(x)__builtin_bswap32(x)
# define __bpf_constant_ntohl(x)___constant_swab32(x)
# define __bpf_constant_htonl(x)___constant_swab32(x)
#elif __BYTE_ORDER__ == __ORDER_BIG_ENDIAN__
# define __bpf_ntohs(x)(x)
# define __bpf_htons(x)(x)
# define __bpf_constant_ntohs(x)(x)
# define __bpf_constant_htons(x)(x)
# define __bpf_ntohl(x)(x)
# define __bpf_htonl(x)(x)
# define __bpf_constant_ntohl(x)(x)
# define __bpf_constant_htonl(x)(x)
#else
# error "Fix your compiler's __BYTE_ORDER__?!"
#endif
#define bpf_htons(x)\
(__builtin_constant_p(x) ?\
__bpf_constant_htons(x) : __bpf_htons(x))
#define bpf_ntohs(x)\
(__builtin_constant_p(x) ?\
__bpf_constant_ntohs(x) : __bpf_ntohs(x))
#define bpf_htonl(x)\
(__builtin_constant_p(x) ?\
__bpf_constant_htonl(x) : __bpf_htonl(x))
#define bpf_ntohl(x)\
(__builtin_constant_p(x) ?\
__bpf_constant_ntohl(x) : __bpf_ntohl(x))
#endif /* __BPF_ENDIAN__ */
/* LLVM's BPF target selects the endianness of the CPU
* it compiles on, or the user specifies (bpfel/bpfeb),
* respectively. The used __BYTE_ORDER__ is defined by
* the compiler, we cannot rely on __BYTE_ORDER from
* libc headers, since it doesn't reflect the actual
* requested byte order.
*
* Note, LLVM's BPF target has different __builtin_bswapX()
* semantics. It does map to BPF_ALU | BPF_END | BPF_TO_BE
* in bpfel and bpfeb case, which means below, that we map
* to cpu_to_be16(). We could use it unconditionally in BPF
* case, but better not rely on it, so that this header here
* can be used from application and BPF program side, which
* use different targets.
*/
#if __BYTE_ORDER__ == __ORDER_LITTLE_ENDIAN__
# define __bpf_ntohs(x)__builtin_bswap16(x)
# define __bpf_htons(x)__builtin_bswap16(x)
# define __bpf_constant_ntohs(x)___constant_swab16(x)
# define __bpf_constant_htons(x)___constant_swab16(x)
# define __bpf_ntohl(x)__builtin_bswap32(x)
# define __bpf_htonl(x)__builtin_bswap32(x)
# define __bpf_constant_ntohl(x)___constant_swab32(x)
# define __bpf_constant_htonl(x)___constant_swab32(x)
#elif __BYTE_ORDER__ == __ORDER_BIG_ENDIAN__
# define __bpf_ntohs(x)(x)
# define __bpf_htons(x)(x)
# define __bpf_constant_ntohs(x)(x)
# define __bpf_constant_htons(x)(x)
# define __bpf_ntohl(x)(x)
# define __bpf_htonl(x)(x)
# define __bpf_constant_ntohl(x)(x)
# define __bpf_constant_htonl(x)(x)
#else
# error "Fix your compiler's __BYTE_ORDER__?!"
#endif
#define bpf_htons(x)\
(__builtin_constant_p(x) ?\
__bpf_constant_htons(x) : __bpf_htons(x))
#define bpf_ntohs(x)\
(__builtin_constant_p(x) ?\
__bpf_constant_ntohs(x) : __bpf_ntohs(x))
#define bpf_htonl(x)\
(__builtin_constant_p(x) ?\
__bpf_constant_htonl(x) : __bpf_htonl(x))
#define bpf_ntohl(x)\
(__builtin_constant_p(x) ?\
__bpf_constant_ntohl(x) : __bpf_ntohl(x))
#endif /* __BPF_ENDIAN__ */
[root@node20 headers]# ls
bpf_endian.h bpf_helpers.h
[root@node20 headers]# cat bpf_helpers.h
/* SPDX-License-Identifier: GPL-2.0 */
/* Copied from $(LINUX)/tools/testing/selftests/bpf/bpf_helpers.h */
#ifndef __BPF_HELPERS_H
#define __BPF_HELPERS_H
/* helper macro to place programs, maps, license in
* different sections in elf_bpf file. Section names
* are interpreted by elf_bpf loader
*/
#define SEC(NAME) __attribute__((section(NAME), used))
#ifndef __inline
# define __inline \
inline __attribute__((always_inline))
#endif
/* helper functions called from eBPF programs written in C */
static void *(*bpf_map_lookup_elem)(void *map, void *key) =
(void *) BPF_FUNC_map_lookup_elem;
static int (*bpf_map_update_elem)(void *map, void *key, void *value,
unsigned long long flags) =
(void *) BPF_FUNC_map_update_elem;
static int (*bpf_map_delete_elem)(void *map, void *key) =
(void *) BPF_FUNC_map_delete_elem;
static int (*bpf_probe_read)(void *dst, int size, void *unsafe_ptr) =
(void *) BPF_FUNC_probe_read;
static unsigned long long (*bpf_ktime_get_ns)(void) =
(void *) BPF_FUNC_ktime_get_ns;
static int (*bpf_trace_printk)(const char *fmt, int fmt_size, ...) =
(void *) BPF_FUNC_trace_printk;
static void (*bpf_tail_call)(void *ctx, void *map, int index) =
(void *) BPF_FUNC_tail_call;
static unsigned long long (*bpf_get_smp_processor_id)(void) =
(void *) BPF_FUNC_get_smp_processor_id;
static unsigned long long (*bpf_get_current_pid_tgid)(void) =
(void *) BPF_FUNC_get_current_pid_tgid;
static unsigned long long (*bpf_get_current_uid_gid)(void) =
(void *) BPF_FUNC_get_current_uid_gid;
static int (*bpf_get_current_comm)(void *buf, int buf_size) =
(void *) BPF_FUNC_get_current_comm;
static unsigned long long (*bpf_perf_event_read)(void *map,
unsigned long long flags) =
(void *) BPF_FUNC_perf_event_read;
static int (*bpf_clone_redirect)(void *ctx, int ifindex, int flags) =
(void *) BPF_FUNC_clone_redirect;
static int (*bpf_redirect)(int ifindex, int flags) =
(void *) BPF_FUNC_redirect;
static int (*bpf_perf_event_output)(void *ctx, void *map,
unsigned long long flags, void *data,
int size) =
(void *) BPF_FUNC_perf_event_output;
static int (*bpf_get_stackid)(void *ctx, void *map, int flags) =
(void *) BPF_FUNC_get_stackid;
static int (*bpf_probe_write_user)(void *dst, void *src, int size) =
(void *) BPF_FUNC_probe_write_user;
static int (*bpf_current_task_under_cgroup)(void *map, int index) =
(void *) BPF_FUNC_current_task_under_cgroup;
static int (*bpf_skb_get_tunnel_key)(void *ctx, void *key, int size, int flags) =
(void *) BPF_FUNC_skb_get_tunnel_key;
static int (*bpf_skb_set_tunnel_key)(void *ctx, void *key, int size, int flags) =
(void *) BPF_FUNC_skb_set_tunnel_key;
static int (*bpf_skb_get_tunnel_opt)(void *ctx, void *md, int size) =
(void *) BPF_FUNC_skb_get_tunnel_opt;
static int (*bpf_skb_set_tunnel_opt)(void *ctx, void *md, int size) =
(void *) BPF_FUNC_skb_set_tunnel_opt;
static unsigned long long (*bpf_get_prandom_u32)(void) =
(void *) BPF_FUNC_get_prandom_u32;
static int (*bpf_xdp_adjust_head)(void *ctx, int offset) =
(void *) BPF_FUNC_xdp_adjust_head;
/* llvm builtin functions that eBPF C program may use to
* emit BPF_LD_ABS and BPF_LD_IND instructions
*/
struct sk_buff;
unsigned long long load_byte(void *skb,
unsigned long long off) asm("llvm.bpf.load.byte");
unsigned long long load_half(void *skb,
unsigned long long off) asm("llvm.bpf.load.half");
unsigned long long load_word(void *skb,
unsigned long long off) asm("llvm.bpf.load.word");
/* a helper structure used by eBPF C program
* to describe map attributes to elf_bpf loader
*/
struct bpf_map_def {
unsigned int type;
unsigned int key_size;
unsigned int value_size;
unsigned int max_entries;
unsigned int map_flags;
unsigned int inner_map_idx;
};
static int (*bpf_skb_load_bytes)(void *ctx, int off, void *to, int len) =
(void *) BPF_FUNC_skb_load_bytes;
static int (*bpf_skb_store_bytes)(void *ctx, int off, void *from, int len, int flags) =
(void *) BPF_FUNC_skb_store_bytes;
static int (*bpf_l3_csum_replace)(void *ctx, int off, int from, int to, int flags) =
(void *) BPF_FUNC_l3_csum_replace;
static int (*bpf_l4_csum_replace)(void *ctx, int off, int from, int to, int flags) =
(void *) BPF_FUNC_l4_csum_replace;
static int (*bpf_skb_under_cgroup)(void *ctx, void *map, int index) =
(void *) BPF_FUNC_skb_under_cgroup;
static int (*bpf_skb_change_head)(void *, int len, int flags) =
(void *) BPF_FUNC_skb_change_head;
#if defined(__x86_64__)
#define PT_REGS_PARM1(x) ((x)->di)
#define PT_REGS_PARM2(x) ((x)->si)
#define PT_REGS_PARM3(x) ((x)->dx)
#define PT_REGS_PARM4(x) ((x)->cx)
#define PT_REGS_PARM5(x) ((x)->r8)
#define PT_REGS_RET(x) ((x)->sp)
#define PT_REGS_FP(x) ((x)->bp)
#define PT_REGS_RC(x) ((x)->ax)
#define PT_REGS_SP(x) ((x)->sp)
#define PT_REGS_IP(x) ((x)->ip)
#elif defined(__s390x__)
#define PT_REGS_PARM1(x) ((x)->gprs[2])
#define PT_REGS_PARM2(x) ((x)->gprs[3])
#define PT_REGS_PARM3(x) ((x)->gprs[4])
#define PT_REGS_PARM4(x) ((x)->gprs[5])
#define PT_REGS_PARM5(x) ((x)->gprs[6])
#define PT_REGS_RET(x) ((x)->gprs[14])
#define PT_REGS_FP(x) ((x)->gprs[11]) /* Works only with CONFIG_FRAME_POINTER */
#define PT_REGS_RC(x) ((x)->gprs[2])
#define PT_REGS_SP(x) ((x)->gprs[15])
#define PT_REGS_IP(x) ((x)->psw.addr)
#elif defined(__aarch64__)
#define PT_REGS_PARM1(x) ((x)->regs[0])
#define PT_REGS_PARM2(x) ((x)->regs[1])
#define PT_REGS_PARM3(x) ((x)->regs[2])
#define PT_REGS_PARM4(x) ((x)->regs[3])
#define PT_REGS_PARM5(x) ((x)->regs[4])
#define PT_REGS_RET(x) ((x)->regs[30])
#define PT_REGS_FP(x) ((x)->regs[29]) /* Works only with CONFIG_FRAME_POINTER */
#define PT_REGS_RC(x) ((x)->regs[0])
#define PT_REGS_SP(x) ((x)->sp)
#define PT_REGS_IP(x) ((x)->pc)
#elif defined(__powerpc__)
#define PT_REGS_PARM1(x) ((x)->gpr[3])
#define PT_REGS_PARM2(x) ((x)->gpr[4])
#define PT_REGS_PARM3(x) ((x)->gpr[5])
#define PT_REGS_PARM4(x) ((x)->gpr[6])
#define PT_REGS_PARM5(x) ((x)->gpr[7])
#define PT_REGS_RC(x) ((x)->gpr[3])
#define PT_REGS_SP(x) ((x)->sp)
#define PT_REGS_IP(x) ((x)->nip)
#elif defined(__sparc__)
#define PT_REGS_PARM1(x) ((x)->u_regs[UREG_I0])
#define PT_REGS_PARM2(x) ((x)->u_regs[UREG_I1])
#define PT_REGS_PARM3(x) ((x)->u_regs[UREG_I2])
#define PT_REGS_PARM4(x) ((x)->u_regs[UREG_I3])
#define PT_REGS_PARM5(x) ((x)->u_regs[UREG_I4])
#define PT_REGS_RET(x) ((x)->u_regs[UREG_I7])
#define PT_REGS_RC(x) ((x)->u_regs[UREG_I0])
#define PT_REGS_SP(x) ((x)->u_regs[UREG_FP])
#if defined(__arch64__)
#define PT_REGS_IP(x) ((x)->tpc)
#else
#define PT_REGS_IP(x) ((x)->pc)
#endif
#endif
#ifdef __powerpc__
#define BPF_KPROBE_READ_RET_IP(ip, ctx) ({ (ip) = (ctx)->link; })
#define BPF_KRETPROBE_READ_RET_IP BPF_KPROBE_READ_RET_IP
#elif defined(__sparc__)
#define BPF_KPROBE_READ_RET_IP(ip, ctx) ({ (ip) = PT_REGS_RET(ctx); })
#define BPF_KRETPROBE_READ_RET_IP BPF_KPROBE_READ_RET_IP
#else
#define BPF_KPROBE_READ_RET_IP(ip, ctx) ({ \
bpf_probe_read(&(ip), sizeof(ip), (void *)PT_REGS_RET(ctx)); })
#define BPF_KRETPROBE_READ_RET_IP(ip, ctx) ({ \
bpf_probe_read(&(ip), sizeof(ip), \
(void *)(PT_REGS_FP(ctx) + sizeof(ip))); })
#endif
#endif
编译和更新
$ clang -I ./headers/ -O2 -target bpf -c xdp-drop-external-debug.c -o xdp-drop-external-debug.o
# 关闭之前xdp
ip link set veth0 xdp off
# 设置新的xdp
$ ip link set dev veth0 xdp obj xdp-drop-external-debug.o sec xdp_from_container
测试
外面访问容器
$ ping 10.239.2.3
PING 10.239.2.3 (10.239.2.3) 56(84) bytes of data.
64 bytes from 10.239.2.3: icmp_seq=1 ttl=64 time=0.122 ms
64 bytes from 10.239.2.3: icmp_seq=2 ttl=64 time=0.104 ms
容器访问外网
# 获取百度ip地址
$ ping baidu.com
PING baidu.com (39.156.69.79) 56(84) bytes of data.
64 bytes from 39.156.69.79 (39.156.69.79): icmp_seq=1 ttl=63 time=41.9 ms
# 容器ping百度ip地址
ip netns exec container1 ping 220.181.38.148
ip netns exec container1 ping 39.156.69.79
PING 39.156.69.79 (39.156.69.79) 56(84) bytes of data.
--- 39.156.69.79 ping statistics ---
15 packets transmitted, 0 received, 100% packet loss, time 559ms
容器访问容器网络
$ ip netns exec container1 ping 10.239.2.1
PING 10.239.2.1 (10.239.2.1) 56(84) bytes of data.
64 bytes from 10.239.2.1: icmp_seq=1 ttl=64 time=0.133 ms
64 bytes from 10.239.2.1: icmp_seq=2 ttl=64 time=0.162 ms
64 bytes from 10.239.2.1: icmp_seq=3 ttl=64 time=0.141 ms
64 bytes from 10.239.2.1: icmp_seq=4 ttl=64 time=0.116 ms
64 bytes from 10.239.2.1: icmp_seq=5 ttl=64 time=0.172 ms
参考

若有收获,就点个赞吧
0 人点赞
