1,简单的优化案例
- 监控 SQL
- 监控数据库连接数量
- 数据库及表的设计问题
- 优化索引
- 优化 SQL 语句
- 设置 MySql 的相关参数
-
2,单表优化
总结:
1,尽量满足最左匹配
where,group by 的有效索引字段拼接起来尽量满足最左匹配
2,索引需要逐步优化,不可能一步到位
3,将含 in 的范围查询字段放到 where 子句的最后面(因为 in 可能会导致索引失效)
3,多表优化
总结:
1,小表驱动大表
2,给频繁使用的字段加索引
对于左外连接,给左表的字段加索引
-
4,避免索引失效
1,避免复合索引失效(最左匹配)
1,对于复合索引(a,b,c),尽量满足最左匹配
使用 a,b,c,生效
- 使用 a,b,生效
- 使用 a,生效
- 使用 b,c,其中(b,c)失效
- 使用 b,其中(b,c)失效
-
2,不能使用不等于(!= <>)或判空(is null,is not null),否则自身及右侧全部失效
3,尽量满足所有复合索引(复合索引都用到)
4,不要使用 or 关键字
2,不要在索引上进行操作(计算,函数,类型转换)
3,尽量使用索引覆盖,避免回表
4,模糊查询(like)不要以 % 开头
如果必须要使用 like ‘%xx%’,那么可以使用索引覆盖来弥补部分性能



5,不要使用类型转换(显式/隐式)
5,其他的优化方法
1,小表驱动大表
优化方法:
如果主查询的数据集大,则用 in
- 如果子查询的数据集大,则用 exists
- 表连接的话,小表在前,大表在后








2,order by 优化
优化 using-filesort,有两种算法
- 双路排序(MySql 4.1 之前),即两次 IO,扫描两次磁盘(第一次从磁盘只读取排序字段,第二次扫描读取其他字段)
- 第一次从磁盘读取要 ORDER 的字段
- 然后在 buffer 缓冲区进行排序
- 第二次按照排序好的字段从磁盘读出要 SELECT 的字段
- 单路排序(MySql 4.1 之后),单次 IO(一次读取全部字段),单路排序会有隐患,不一定就是单次 IO
- 如果数据量过大, buffer 缓冲区无法进行一次性读取并排序,只能多次分片读取
- 比双路排序占用更多的 buffer 缓冲区
- 可以设置 buffer 缓冲区大小来满足单路排序(max_length_for_sort_data),如果该值太低,MySql会自动从单路排序切换至双路排序
优化方法:
- 选择使用单路还是双路排序,并调整 buffer 大小
- 避免 SELECT *,只查询需要的字段即可
- 复合索引不要跨列使用,避免 using-filesort
-
3,SQL 慢查询日志
MySql 提供的一种日志纪录,用于记录响应时间超过阈值的 SQL 语句(long_query_time)
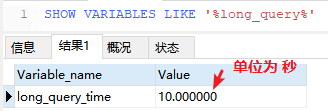
默认关闭,开发时打开,上线时关闭1,检查是否开启了慢查询日志
2,开启慢查询日志:
临时开启,在内存中开启
SET GLOBAL slow_query_log = 1;--设置后重启 mysql 服务
永久开启,修改 mysql 配置文件

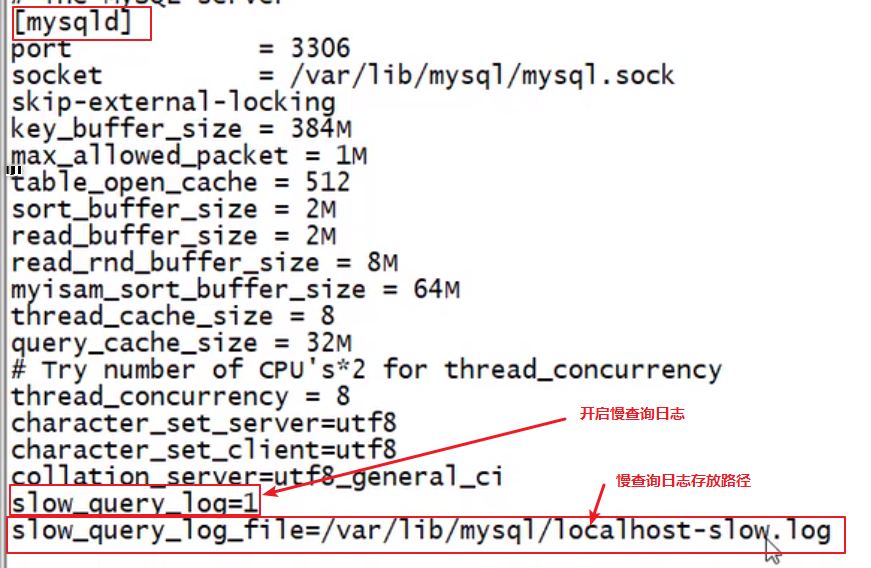
3,设置慢查询时间阈值
临时设置阈值
SET GLOBAL long_query_time = 5;--单位为秒--设置后重新登录生效
永久设置阈值

4,查询超过阈值的 SQL 数量
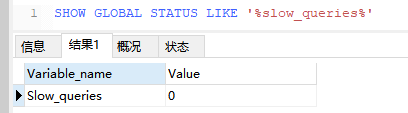
5,通过 MySqlDumpSlow 工具查看慢 SQL
可以通过一些过滤条件,快速查找和定位慢 SQL
mysqldumpslow --helps:排序方法r:逆序l:锁定时间g:正则匹配模式
获取返回记录条数最多的三个 SQL
mysqldumpslow -s r -t 3 /xx.log--其中最后面为 log 文件
获取访问次数最多的三个 SQL
mysqldumpslow -s c -t 3 /xx.log--其中最后面为 log 文件
按照时间排序,获取前 10 条包含 left join 的 SQL
mysqldumpslow -s t -t 10 -g "left join" /xx.log--其中最后面为 log 文件
4,分析海量数据
1,Profiles
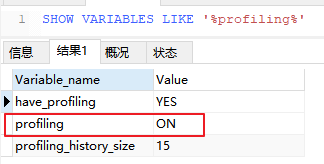
1,查看 Profiles 是否开启
2,开启 Profiles
SET profiling = ON;
3,查看 Profiles

缺点:-
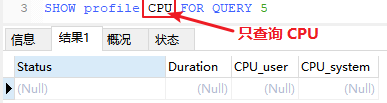
4,查看 SQL 详细的 Profiles
2,全局查询日志,记录开启后的所有 SQL(耗费性能)
1,查看全局查询日志是否开启
2,开启全局查询日志
SET GLOBAL general_log = 1;--开启全局查询日志SET GLOBAL log_output = 'table';--表示日志记录到表里而不是文件里SET GLOBAL log_output = 'file';--表示日志记录到文件里
3,查询日志(存储在 mysql.general_log 表中)
SELECT * FROM mysql.general.log




若有收获,就点个赞吧
0 人点赞
