1,日志的归属
1,MySql 服务器:
- Binary Log
- Error Log
-
2,InnoDB:
Redo Log
-
3,Bin Log 的增量同步
1,LSN(Log Sequence Number)日志序列号
LSN 实际就是对应日志文件的偏移量:新的 LSN = 旧的 LSN + 写入的日志的大小
日志文件刷新后, LSN 不会重置1,查看 LSN
SHOW ENGINE INNODB STATUS
2,LSN 参数
Log Sequence Number:当前系统 LSN 最大值,新的事务日志将会在此基础省生成新的 LSN
- Log Flushed Up To:当前已经写入日志文件的 LSN
- Pages Flushed Up To:当前最旧的脏页数据对应的 LSN,写 Checkpoint 的时候直接将此 LSN 写入日志文件
Last Checkpoiunt At:当前已经写入 Checkpoint 的 LSN
3,集群的主从复制
1,主从复制的优点
横向扩展解决方案 - 在多个从站之间分配负载以提高性能。在此环境中,所有写入和更新都必须在主服务器上进行。但是,读取可以在一个或多个从设备上进行。该模型可以提高写入性能(因为主设备专用于更新),同时显着提高了越来越多的从设备的读取速度。
- 数据安全性 - 因为数据被复制到从站,并且从站可以暂停复制过程,所以可以在从站上运行备份服务而不会破坏相应的主数据。
- 分析 - 可以在主服务器上创建实时数据,而信息分析可以在从服务器上进行,而不会影响主服务器的性能。
- 远程数据分发 - 您可以使用复制为远程站点创建数据的本地副本,而无需永久访问主服务器。
2,主从复制的原理
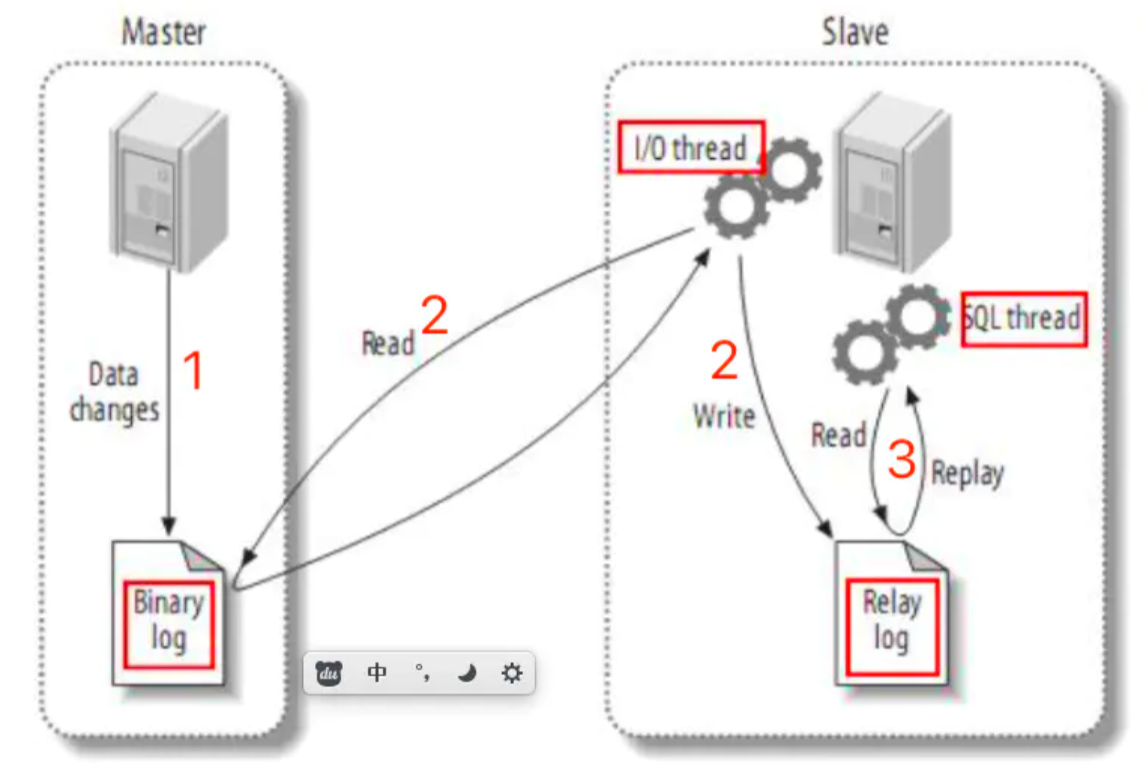
- 主服务器负责写,从服务器负责读
- 数据写到主服务器后,会一并记录日志到主服务器的 BinLog
- 从服务器开启一个 IO 线程不断读取主服务器的 BinLog 并持久化到本地的 RelayLog 中
- 从服务器开启一个 SQL 执行线程将 RelayLog 中的日志在本地数据库中进行复刻,最终实现主从服务器的数据一致性
3,主从复制的延迟问题
- 主服务器和从服务器之间一般是局域网内,或者是拉的专线,所以网络传输不是性能瓶颈!
- 主服务器写入 BinLog 和从服务器获取 BinLog 以及从服务器记录 RelayLog 都是线性写的,所以速度很快,这也不是性能瓶颈!
- 瓶颈一:SQL 线程持久化数据时不是线性写的!,假如 RelayLog 中有两条连续的 SQL ,一个更新磁盘块 1 的数据,一个更新磁盘块 100 的数据,那么 SQL 线程就要耗费时间去寻找物理地址来持久化!
- 瓶颈二:因为瓶颈一的原因,导致 SQL 线程持久化的速度跟不上 IO 线程写 RelayLog 的速度,将会造成 RelayLog 日志堆积
瓶颈三:MySql 的低版本 IO 线程和 SQL 线程都只有一个,所以必须要开多线程(MTS):
从库的性能比主库差,从库的资源不足影响从库数据同步的效率
- 由于从库负责读,而实际上大部分的 SQL 操作都是读,所以当读请求过大会占用从库的大量 CPU 资源,导致无法分出更多的资源去同步数据
- 大事务的执行(**无解,只能避免写大事务**),如果主库有一个日志执行了 10 分钟,那么就要等待 10 分钟后才写入 BinLog,那么这时候就已经有了 10 分钟的数据延迟了,更不用说从库还要耗费时间同步日志并持久化数据
- 所有日志的写都是顺序写的,但从库读取日志并持久化是随机的,需要不断寻址耗费时间
- 从库再同步数据的时候,SQL 线程可能会和其他正常的查询线程抢占锁,造成延迟
- 当主库的 TPS 并发非常高时,产生的 DDL 数量超过了一个线程所能承受的范围,也有可能会造成延时
-
5,解决主从复制的延迟(多线程并行复制)
1,问题一:操作同一行的事务日志可以轮询来分发给不同的 worker 吗?
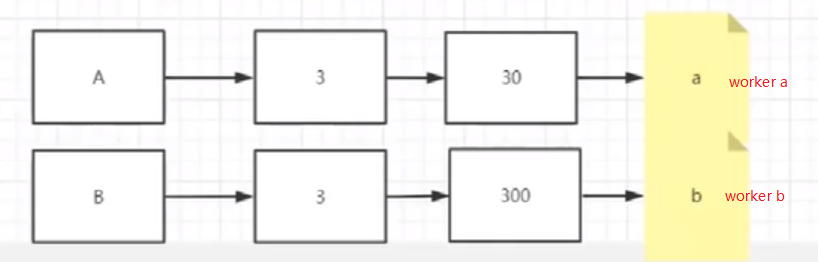
不能,因为无法保证每个线程的执行顺序,会造成不同事务的最终数据的不一致性2,问题二:同一个事务内的日志可以轮询分发给不同的 worker 吗?
不能**,因为无法保证每个线程的执行顺序,会造成事务内的最终数据的不一致性**
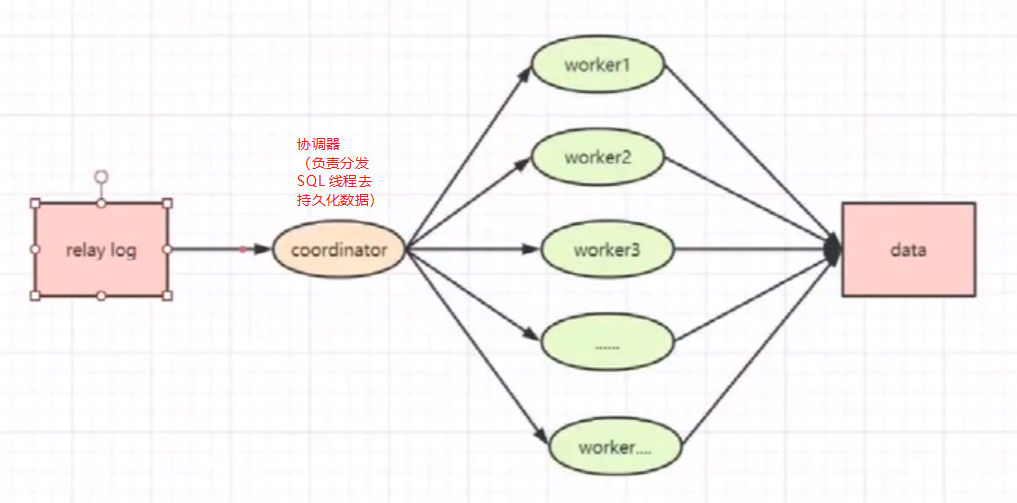
6,多线程同步的规则
更新同一行的多个事务日志必须要分发给同一个 worker 去执行(解决问题一)
同一个事务内的日志必须要分给同一个 worker 去执行,不能分开(解决问题二)
7,主从复制的粒度(库,表,行)
粒度设置:slave_parallel_type
5.6 默认是库级复制
- 5.7 默认是行级复制
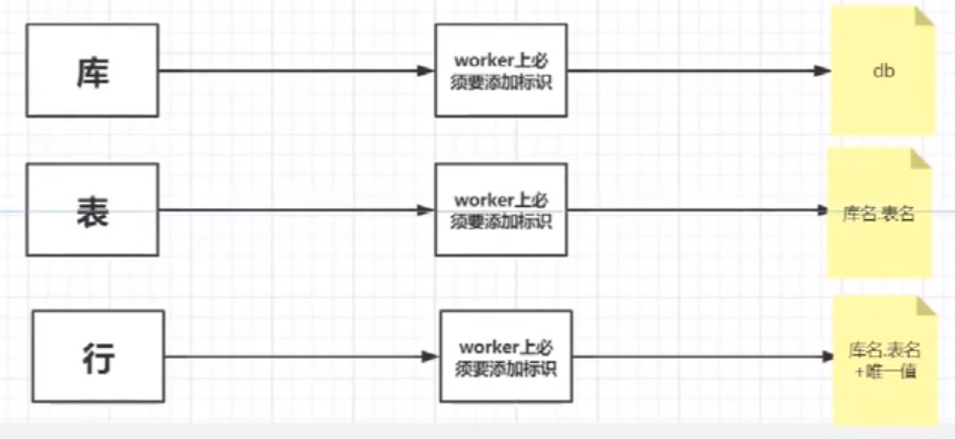
1,库级
2,表级
3,行级
8,5.7 行级采用的并行复制策略(二阶段提交)
为了保证 Crash-Safe,MySql 实行了二阶段提交,将写日志分为 Prepare 和 Commit 两个阶段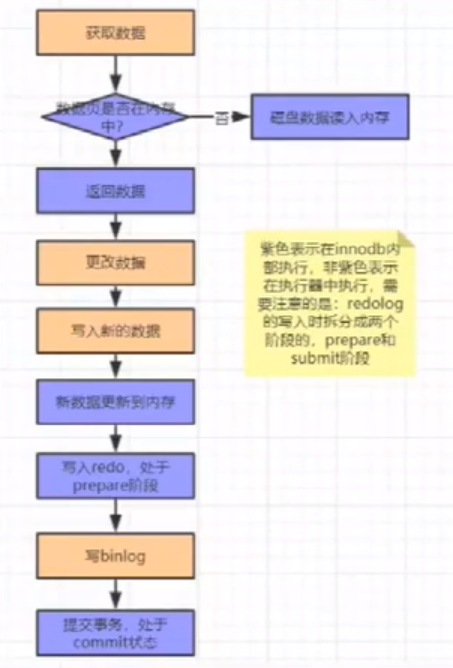
执行流程如下:
- 执行器先从引擎找到数据,如果在内存中直接返回,否则去查询并返回
- 执行器拿到数据之后先修改数据,然后调用引擎接口写入数据
- 引擎将数据更新到内存,同时将数据写入 Redo Log,此时处于 Prepare 阶段,并通知执行器执行完成,随时可以操作
- 执行器生成这个操作的 Binary Log
- 执行器调用引擎的事务提交接口,引擎把刚刚写完的 Redo Log 改成 Commit 状态,更新完毕
1,先写 Redo Log 再写 Bin Log 的问题
假设在写了 Redo Log 还没有写 Bin Log 的时候,数据库宕机了,因为 Redo Log 是 InnoDB 引擎层的,所以数据库重启也可以将数据恢复,所以主库是可以靠 Redo Log 恢复这部分数据的,但是 Bin Log 没有记录这部分数据,导致从库同步数据或者主库恢复数据时无法获取这部分数据,导致数据一致性出现问题。2,先写 Bin Log 再写 Redo Log 的问题
假设在写了 Bin Log 还没有写 Redo Log 的时候,数据宕机了,事务失效,主库重启后不会也无法通过 Redo Log 恢复丢失的数据,但是 Bin Log 却记录到了这些本应该不存在的数据,并供从库进行数据同步,导致数据一致性出现问题3,为什么使用二阶段提交就可以防止以上问题
因为在宕机后进行数据恢复时是结合 Redo Log 和 Bin Log 一起来恢复的
- 假如宕机重启后处于 Prepare 状态,但没有写 Bin Log,所以只需要回滚 Redo Log 就行
- 假如宕机重启后处于 Prepare 状态,但写了 Bin Log,只需要提交 Redo Log 就行
4,并行复制策略的思想
- 同时处于 Prepare 状态的事务,在从库执行是可以并行的
- 处于 Prepare 状态的事务,与处于 Commit 状态的事务之间,在从库上执行也是可以并行的,
基于这样的处理机制,我们可以将大部分的日志处于 Prepare 的状态,因此可以设置
- binlog_group_commit_sync_dely 参数,表示延迟多少微妙后才调用 fsync()
binlog_group_commit_sync_no_delay_count 参数,表示累计多少次以后才调用 fsync()
5,组提交
任何数据要同步到磁盘的时候要经历三个阶段(参考 事务部分的 Redo Log 介绍)
当前进程的内存空间
- 系统的内存空间(OS Buffer)
- 物理磁盘
持久化流程如下:
- 先把数据缓存在进程内存空间
- 把进程内存的数据 write 到系统内存(OS Buffer)
- 内核调用 fsync() 将数据从 OS Buffer 同步到磁盘
因为如果每一条数据都去 fsync 的话,是很耗性能的,所以需要组提交,即多组数据一起提交持久化
1,组提交数据丢失的解决方案(双 1 操作)
因为是在准备好多条数据时一并写入磁盘,所以存在断电导致的大量数据丢失问题
双 1 操作,即为 MySql 的两个参数设置为 1:
- sync_binlog = 1
- innodb_flush_log_at_trx_commit = 1
- Master 数据改变时,会在事务前产生一个 GTID,记录到 BinLog 中
- Slave 通过 IO 线程将 Master 的 BinLog 数据写入到自身的 RelayLog(中继日志)
- Slave 通过 SQL 线程读取 RelayLog 的 GTID,然后对比自身的 BinLog 是否有此记录
- 如果存在该记录,则丢弃掉这次事务
- 如果没有,就执行这次事务,并将其 GTID 记录到自身 BinLog 供下次对比
2,GTID 复制和日志点复制优缺点对比
1,基于日志点复制的优缺点:
优点:
- MySql 最早支持的复制技术,BUG 少
- 对 SQL 查询没有限制
- 故障处理比较容易
缺点:
故障转移时重新获取旧 master 日志点比较困难,基于日志点复制是从 master 的 BinLog 偏移量进行增量同步,如果出现错误,容易造成主从数据不一致
进行故障转移很方便,只需要记录旧 master 最后事务的 GTID 值,假如有 master A,和 Slave B,Slave C,假如 A 宕机了,B 执行了 A 传过来的所有事务,但是 C 没有,这时 C 只需要把最后一次的事务 GTID 传给 B,然后 B 从这个 GTID 开始寻找事务发送给 C,使 C 也能实现数据一致,从而达到自我修复的能力,可以减少事务丢失和故障恢复时间
- Slave 从库不会丢失 Master 的任何修改(开启 log_slave_update)
缺点:
- 只支持事务型引擎(例如 InnoDB)
- 故障转移处理复杂,需要注入空事务
- 不支持 sql_slave_skip_counter(一般用这个来跳过基于 BinLog 主从复制出现的问题)
- 对执行的 SQL 有一定的限制
- 为了保证事务的安全性,CREATE TABLE … SELECT 这样的 SQL 无法使用,且不能使用 CREATE TEMPORARY TABLE 创建临时表,不能使用关联更新事务表和非事务表

若有收获,就点个赞吧
0 人点赞
