- 1,查询语法
- 2,执行计划的属性
- 1,id:编号
- 2,select_type:查询类型
- 3,table:查询的表
- 4,type:索引类型,类型
- 1,system:只有一条数据的系统表或衍生表只有一条数据的主查询,很难出现,可以忽略
- 2,const:仅仅能查到一条数据的 SQL,且使用了主键或者唯一索引时才有效(因为只有这样数据才是一条)
- 3,eq_ref:使用唯一索引扫描,对于每个索引键的查询,返回匹配唯一行数据(有且只有一个,不能大于 1 也不能为 0),即两个表的数据是一对一的,这样才能保证筛选之后不会出现没关联到(0)或者关联了多个数据(大于 1)
- 4,ref:和 eq_ref 类似,但使用非唯一索引扫描,不是非要满足唯一行数据的条件
- 5,fulltext:使用到了全文索引
- 6,ref_or_null:
- 7,index_merge:索引合并,对多个索引分别进行条件扫描,然后将它们各自的结果进行合并(intersect/union)
- 8,unique_subquery:一个索引查找函数,它完全取代子查询以获得更好的效率,子查询的查询字段必须是唯一索引
- 9,index_subquery:和 unique_subquery 一样,但是子查询的字段不一定是唯一索引
- 10,range:检索指定范围的行,也就是 where 后面是一个范围条件(between and,> < <= >=,in 有时候会失效)
- 11,index:查询所有索引的数据
- 12,ALL:查询所有具体的数据(全表扫描)
- 13,总结
- 5,possible_keys:预测用到的索引
- 6,key:实际使用的索引
- 7,key_len:实际使用索引的长度
- 8,ref:表之间的引用
- 9,rows:通过索引查询到的数据量
- 10,Extra:额外的信息
MySql 的优化器回干扰我们的 SQL 执行过程,所以需要查看 SQL 的执行计划(explain)来清楚 MySql 是怎么执行我们的 SQL 的
1,查询语法
EXPLAIN + SQL语句EXPLAIN SELECT * FROM 表名
2,执行计划的属性

1,id:编号
1,id 相同
id 值相同,表示从上往下依次执行(表关联时,先查小表再查大表)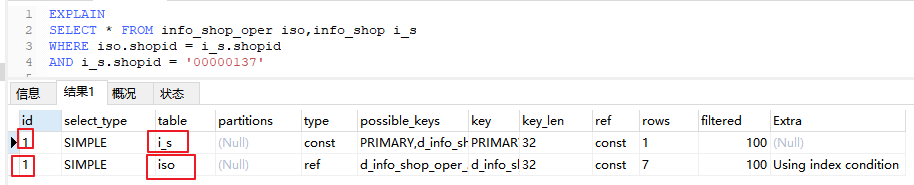
如上图,两个计划 id 相同,表示从上向下执行,即先查 Info_shop 再查 info_shop_oper,从两个表的数据量也能看出先查小表再查大表
2,id 不同
id 值不同,值越大越优先查询(嵌套子查询时,先查内层再查外层)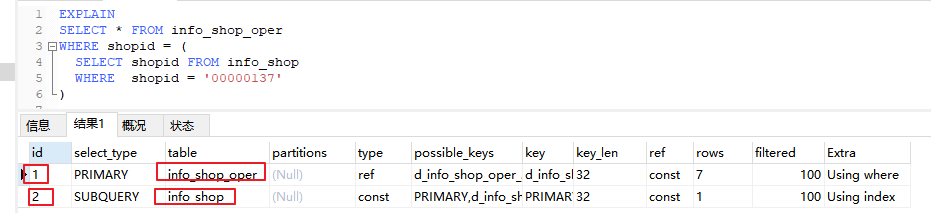
如上图,两个计划 id 不同,先查询 id 大的,即 Info_shop 表,且 info_shop 是子查询,所以能证明 id 越大先执行,而且先执行子查询
将子查询的 = 改成 in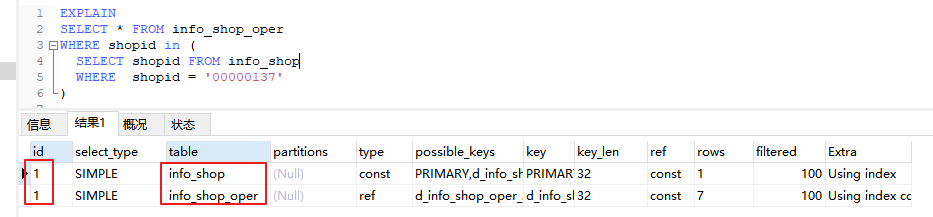
可以看到,id 相同了,按照 id 相同理论,从上向下执行,所以还是先执行子查询内的 info_shop 表
2,select_type:查询类型
1,PRIMARY(主查询)
2,SUBQUERY(子查询)
3,SIMPLE(简单查询)
4,DERIVED & UNION & UNION RESULT(衍生查询)
使用到了临时表的查询,包含以下情况
- 在 from 子查询中只有一张表
- 在 from 子查询中,如果 table1 连接了 table2,那么 table1 就是 DERIVED,table2 就是 UNION
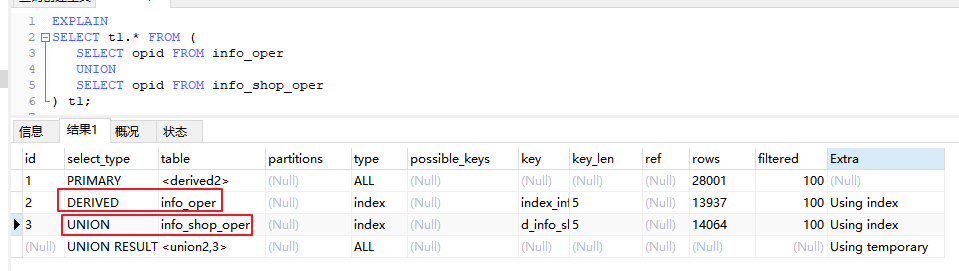
UNION RESULT 表明是哪些结果的合并,如上例
3,table:查询的表
4,type:索引类型,类型
表示了效率的高低,效率的高低排行如下:
system > const > eq_ref > ref > range > index > all
1,system:只有一条数据的系统表或衍生表只有一条数据的主查询,很难出现,可以忽略
2,const:仅仅能查到一条数据的 SQL,且使用了主键或者唯一索引时才有效(因为只有这样数据才是一条)


3,eq_ref:使用唯一索引扫描,对于每个索引键的查询,返回匹配唯一行数据(有且只有一个,不能大于 1 也不能为 0),即两个表的数据是一对一的,这样才能保证筛选之后不会出现没关联到(0)或者关联了多个数据(大于 1)

4,ref:和 eq_ref 类似,但使用非唯一索引扫描,不是非要满足唯一行数据的条件

5,fulltext:使用到了全文索引
6,ref_or_null:
7,index_merge:索引合并,对多个索引分别进行条件扫描,然后将它们各自的结果进行合并(intersect/union)
1,union(并集)
 sect
sect
2, intersect(交集)
3,sort union(排序并集)

8,unique_subquery:一个索引查找函数,它完全取代子查询以获得更好的效率,子查询的查询字段必须是唯一索引
value IN (SELECT primary_key FROM single_table WHERE some_expr)
9,index_subquery:和 unique_subquery 一样,但是子查询的字段不一定是唯一索引
value IN (SELECT key_column FROM single_table WHERE some_expr)
10,range:检索指定范围的行,也就是 where 后面是一个范围条件(between and,> < <= >=,in 有时候会失效)



11,index:查询所有索引的数据


12,ALL:查询所有具体的数据(全表扫描)


13,总结
- system/const:结果只有一条数据
- eq_ref:结果是多条,但是每条数据是唯一的
-
5,possible_keys:预测用到的索引
6,key:实际使用的索引
7,key_len:实际使用索引的长度
用户判断复合索引是否被完全使用
utf8 一个字符最长 3 个字节
- utf8mb4 一个字符最长 4 个字节
- MySql 使用 1 个字节表示是否为空(主键字段不需要)
-
8,ref:表之间的引用
与 type 中的 ref 不同
指明当前表所参照的字段SELECT * FROM table1 t1,table2 t2 WHERE t1.x = t2.x--其中 t2.x 是被参照的字段,可以是常量,如果是常量,那么 ref 就是 const
9,rows:通过索引查询到的数据量
10,Extra:额外的信息
using filesort:表示性能消耗大,需要额外的一次排序(查询),常见于 order by 语句中
- 对于单索引,如果排序和筛选是同一个字段,那么不会出现 using filesort,反之会出现
- 对于复合索引,如果 where 和 order by 不满足最左匹配,就会出现 using filesort
- using temporary:表示性能消耗大,表示用到了临时表,一般出现在 group by 语句中
- using index:即索引覆盖,要查询的数据存在于索引文件里,即不需要回表,会对 possible_keys 和 key 造成影响
- 如果没有 where 子句,则索引只在 key 中
- 如果有 where 子句,则索引出现在 key 和 possible_keys 中
- using where:即回表查询,要查询的数据不存在于 where 子句中的索引字段,要先在索引里面定位到数据,然后在别的索引里面查找具体的数据
- impossible where:where 子句永远为 false




- using join buffer:连接缓存,当连接的数据多次使用时,MySql 会开启连接数据缓存

若有收获,就点个赞吧
0 人点赞
