数据库中间件的作用
在数据库集群模式下,让开发像操作单机单库单表一样,来操作数据库的读写。数据访问中间件主要解决两个问题:读写分离和分库分表。其中读写分离主要解决了读能力的水平扩展,而分库分表则解决了写能力的水平扩展。
数据库中间件的实现方式
实现方式:一种是代理数据库(代表有Mycat),另一种是代理数据源(代表有阿里tddl,大众点评zebra)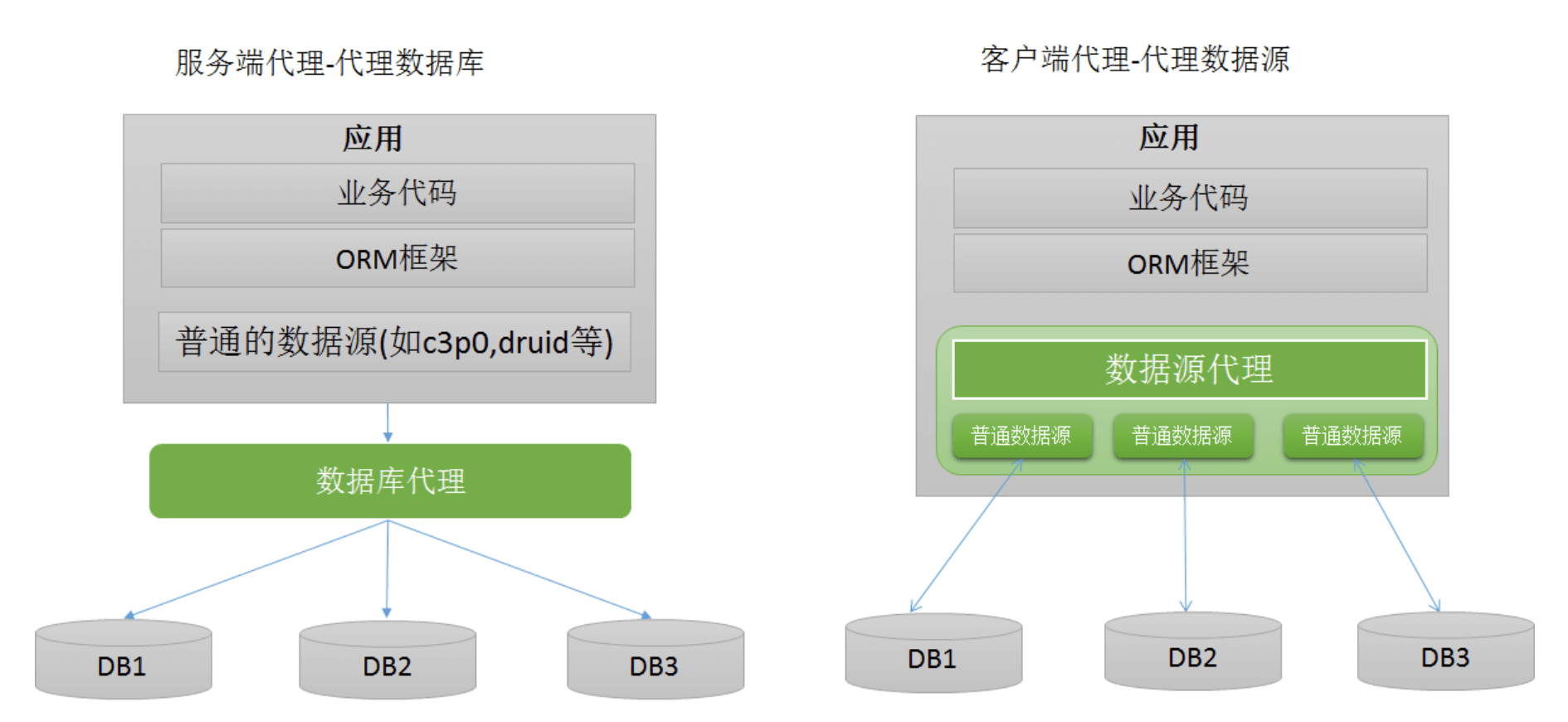
实现方案对比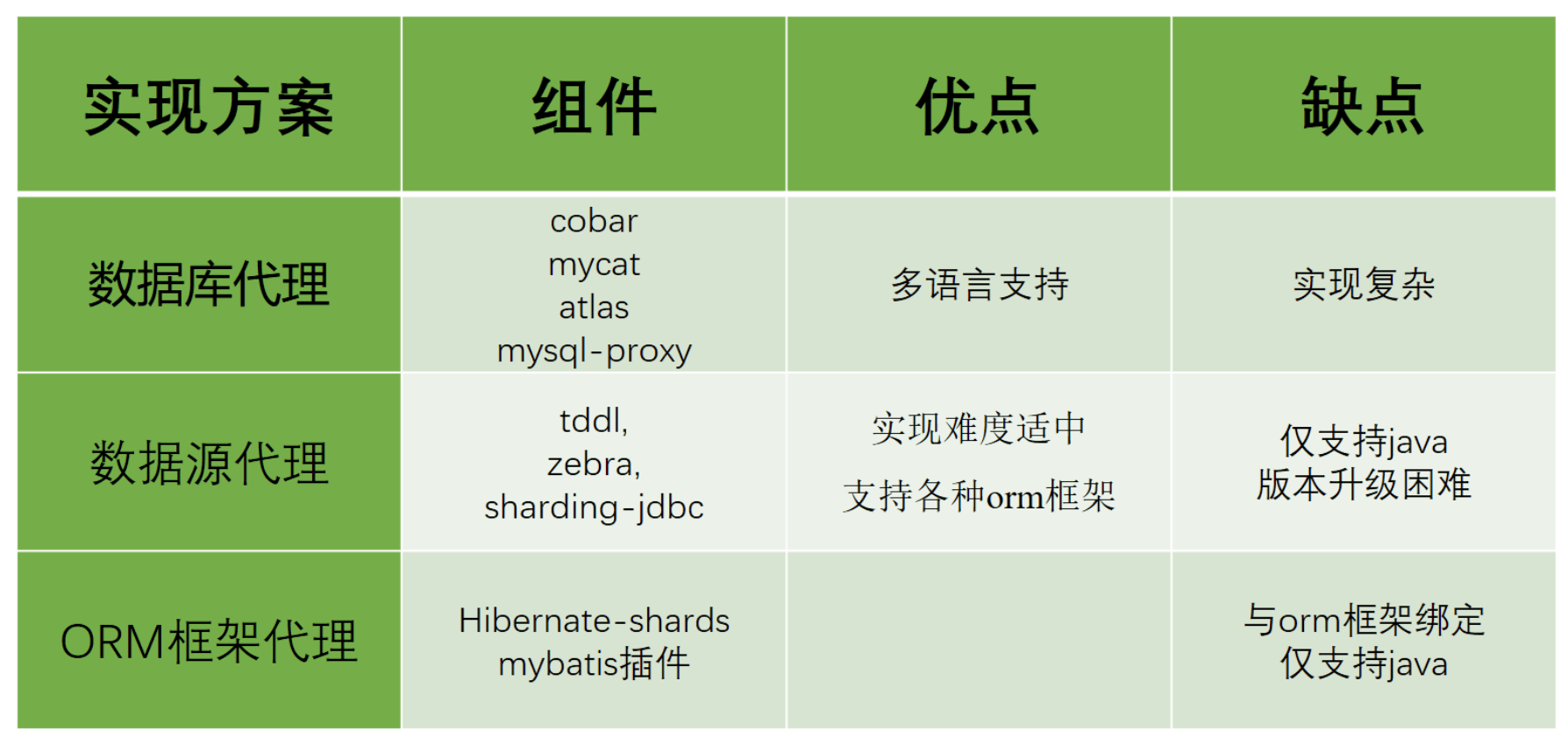
读写分离
读写分离的优势是能够避免单点故障,同时能够进行负载均衡,读能力可以进行水平扩展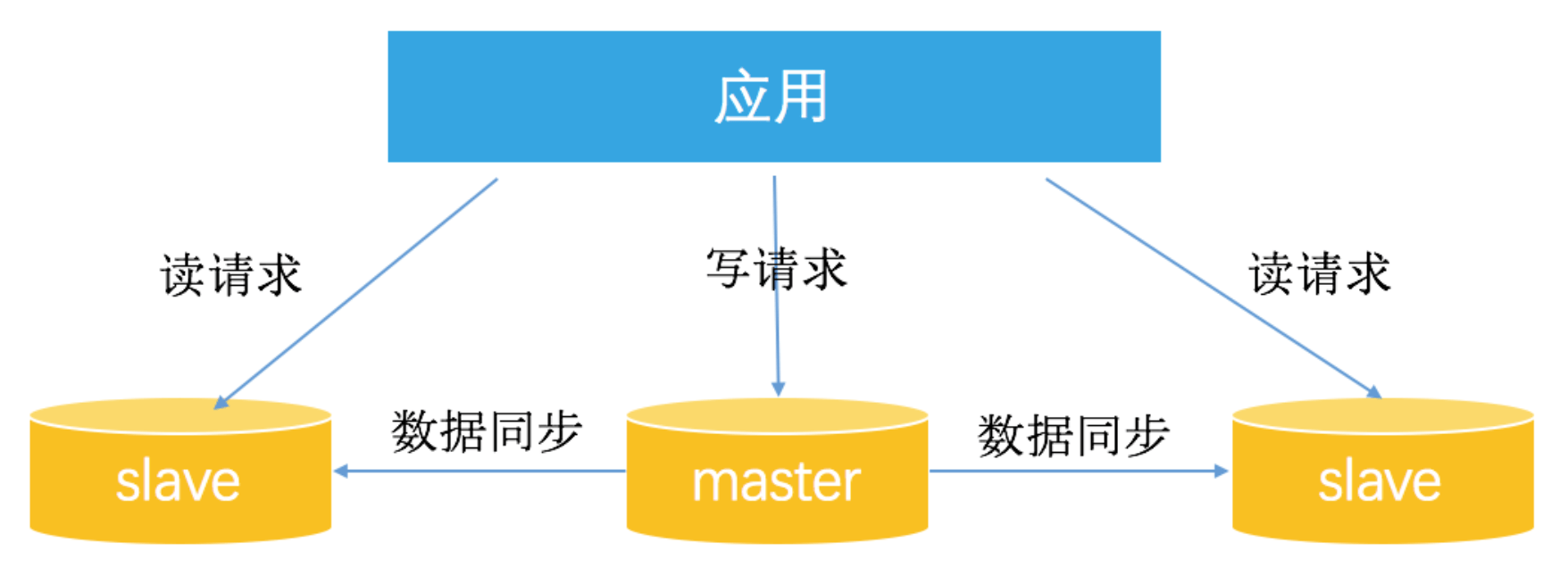
读写分离的挑战
SQL类型判断
主从延时
主从同步之间可能存在同步延时而造成数据不一致,对于部分一致性较高的应用,可以指定某些读请求强制走主库(强制走主库走两种实现方式:一种是在SQL上加特殊标记,另一种是在SQL查询前后加入特定的语句利用线程上下文来实现)
事务处理
如果一个事务中包括读和写,使用读写分离会导致请求到不同的库上,一般做法是事务内部的请求都走一个库,利用jdbc的事务在本地完成事务
高可用
- 新增slave。当新增slave之后,需要将请求能转发到该slave上
- slave下线或宕机。slave挂了或下线,需要将其上的请求转发到其他slave
- master宕机。需要将请求转到新的master上
这一部分需要与数据库如MySQL本身的高可用进行配合,将集群的信息生成配置化,并让中间件去监听MySQL集群的变化,来实现新的负载(常见的负载均衡有 轮询、权重等)
读写分离实现
每个SingleDataSource对应一个数据源,连接一个数据库,GroupDataSource则包含多个SingleDataSource,对应一个集群(包含master和slave)。 对于分库分表,则在Group的上层再加一层ShardDataSource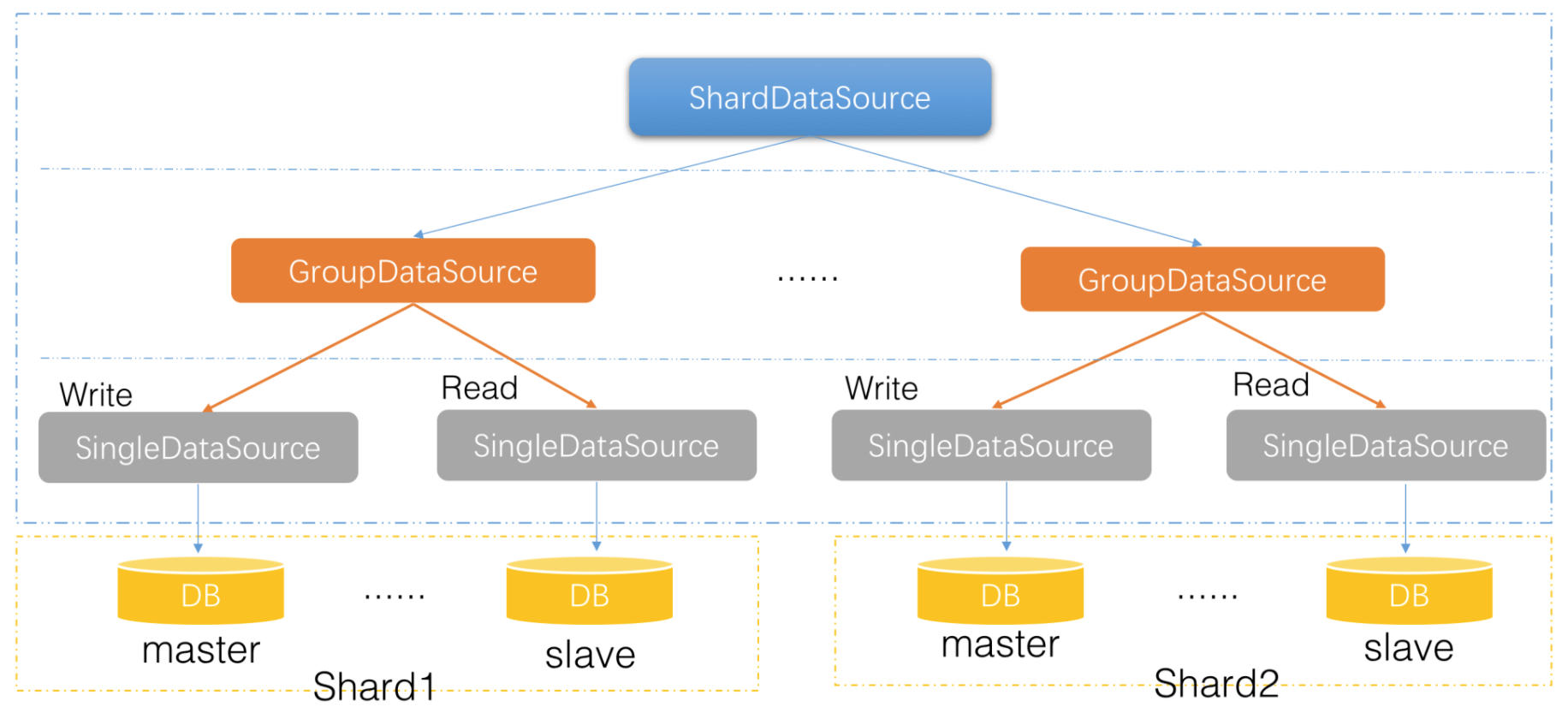
分库分表
分库分表的类型
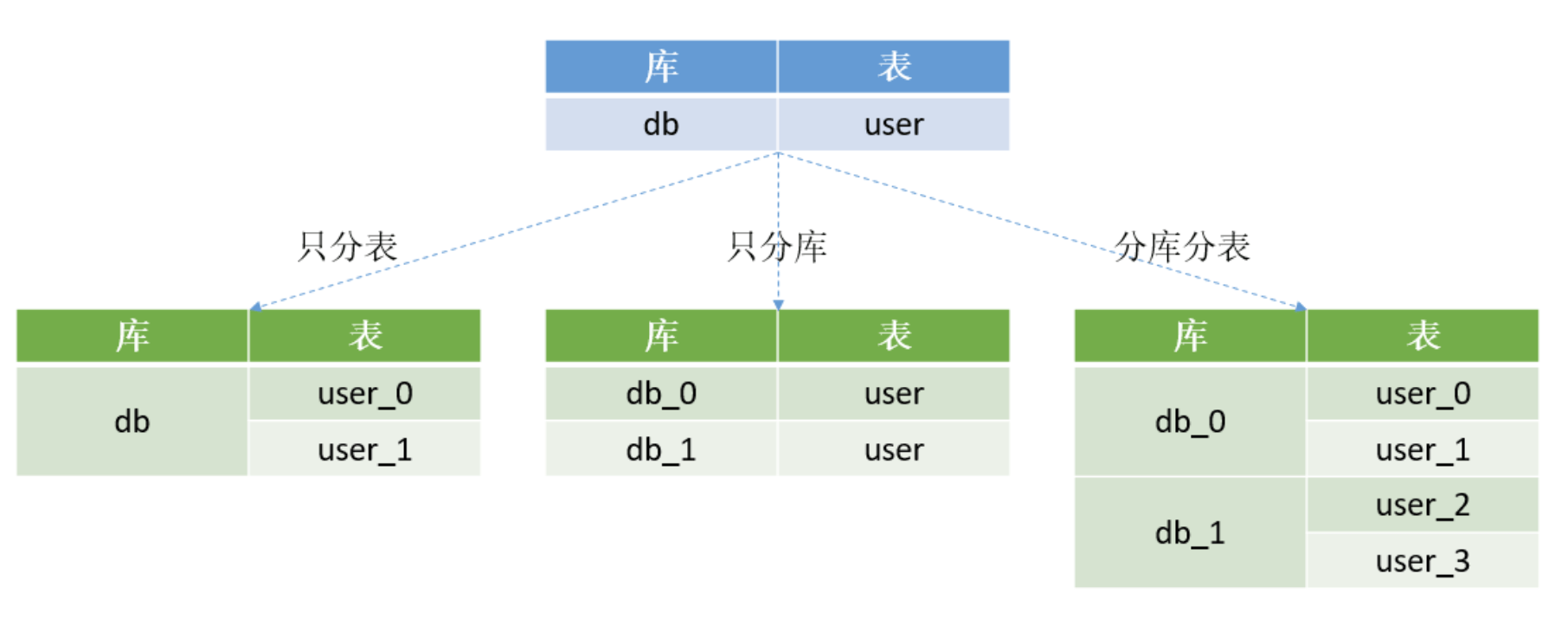
分库分表的好处
分库降低单台机器的负载,提升写入性能
分表提升读写和查询的效率,大表变小表
分库分表的挑战
基本的数据库增删改功能
基本的增删改查可能涉及多个库或多个表,(1)需要对SQL语句进行改写(2)需要对结果集进行合并
分布式id
主键不能再依赖数据库自增的id进行实现,因为可能会有重复的id,需要分布式的唯一id,可以使用美团点评开源的Leaf(取名来自:世界没有任何两片相同的树叶)
分布式事务
当设计到同时对多个库或表的变更时,不能再向主从结构中只操作主库了(因为分库分表之后是操作多个集群,有多个分片主库)
动态扩容
分库分表的实现
一般可以分为垂直拆分和水平拆分,垂直拆分可以解决单行过大导致的数据过大问题,但是不能解决行数过多导致的数据量大的问题。常见的分库分表策略如下:
- 平均进行分配hash(object)%N(适用于简单架构)。
- 按照权重进行分配且均匀轮询。
- 按照业务进行分配。
- 按照一致性hash算法进行分配(适用于集群架构,在集群中节点的添加和删除不会造成数据丢失,方便数据迁移)。
数据源
c3p0、dbcp、druid分布式事务
参考文献
大众点评Zebra

若有收获,就点个赞吧
0 人点赞
