前言
响应式编程
响应式编程是一个令人振奋的编程方式。不要被响应式这个词吓到,其实这个概念并没有那么难理解,实际上,很可能你早已经无意中使用了响应式编程的思想。
如果你使用过Excel的公式功能,你就已经应用过响应式编程。
如图: 演示使用Excel来统计员工工资,在Excel表格中,选中E2这个格子,在公式部分输入=,然后用鼠标选中B2到D2的格子,就完成了一次响应式编程。之后,无论我在B2到D2中填写什么数字,E2这个格子里的数值都会自动变为B2到D8所有格子的数值之和,换句话说,E2能够对这些格子的数值变化作出响应。
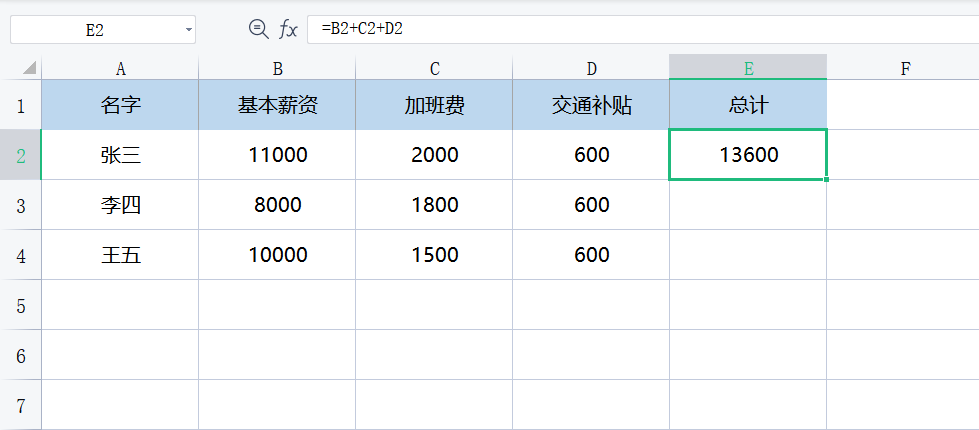
响应式编程就是这么简单的一个概念,这个Excel的例子虽然简单,但是却体现了响应式编程的很多重要思想。程序的输入可看作一个数据流,在这个Excel表格中,输入就是用户在B2到D2格子中填充的数值,用户这个填充动作是完全不可预料的,可能先填B2,也可能先填C2,用户还可能反复修改D2格子里的数值;无论用户用何种方式操作,可以看作一个数据流,这个流中的一个元素,是对某个格子的数值修改,这个程序都一视同仁,一样能够处理。
响应式编程的这些特点如此自然,就算不是程序员也可以用Excel来创造具有计算能力的表格。当然,真正的响应式编程要比Excel复杂得多 接下来,我们就来介绍响应式编程世界里知名度最高的框架Reactive Extension(Rx)。
Reactive Extension
Reactive Extension,也叫ReactiveX,或者简称Rx,指的是实践响应式编程的一套工具。
Rx官网: http://reactivex.io/
Rx的概念最初由微软公司实现并开源,也就是Rx.NET,因为Rx带来的编程方式大大改进了异步编程模型,在.NET之后,众多开发者在其他平台和语言上也实现了Rx的类库。可见,Rx其实是一个大家族,在这个大家族中,还有用Java实现的RxJava,用C++实现的RxCpp,用Ruby实现的Rx.rb,用Python实现的RxPy,当然,还有这个大家族中最年长的Rx.NET。在本章节我们介绍的是RxJS,也就是Rx的JavaScript语言实现。
这些语言并没有天生对响应式编程支持,所以,才需要引入Reactive Extension 思想,为这些语言增加响应式方面的功能扩展。
Rx(包括RxJS)诞生的主要目的虽然是解决异步处理的问题,但并不表示Rx不适合同步的数据处理,实际上,使用RxJS之后大部分代码不需要关心自己是被同步执行还是异步执行,所以处理起来会更加简单。
Rxjs 响应式编程的优势
RxJS这套模型并不是闭门造车臆想出来的概念,这套模型已经被证明很成功,这是因为它具备下面这些特点:
- 数据流抽象了很多现实问题。
- 擅长处理异步操作。
- 把复杂问题分解成简单问题的组合。
现实应用中,很多问题都可以抽象为数据流的问题来解决:以网页应用的前端领域为例,网页DOM的事件,可以看作为数据流;通过WebSocket获得的服务器端推送消息可以看作是数据流;同样,通过AJAX获得服务器端的数据资源也可以看作是数据流,虽然这个数据流中可能只有一个数据;网页的动画显示当然更可以看作是一个数据流。正因为网页应用中众多问题其实就是数据流的问题,所以用RxJS来解决才如此得心应手。
RxJS擅长处理异步操作,因为它对数据采用“推”的处理方式,当一个数据产生的时候,被推送给对应的处理函数,这个处理函数不用关心数据是同步产生的还是异步产生的,这样就把开发者从命令式异步处理的枷锁中解放了出来。
Rxjs 运行环境
在软件项目中引入RxJS,有两种常用方法:第一种方法是使用npm包,适合于使用npm管理库的项目,这样不光让RxJS可以用于网页,还可应用于服务器端代码;第二个方法,直接用script标签导入包含RxJS的JavaScript资源文件,这种方法只适用于网页。
1.npm 安装
如果使用npm管理软件项目,导入RxJS直接通过npm install命令就可以完成,在项目代码目录下运行下面的命令:
npm install rxjs
使用ES6的import语法导入v7版的Rx对象,代码如下:
import Rx from "rxjs";
安装了RxJS的npm包之后,就可以在对应的项目代码中导入相应功能:
import {Observable} from "rxjs";
引入 Rxjs URL
在网页应用中,还可以通过script标签直接导入RxJS,通常script标签的src属性为一个内容分发网络(Content Delivery Network, CDN)上的URL, CDN通过在互联网中分布很多节点,让最终用户的浏览器能够从最近的节点获取资源,从而提供快速的内容访问。CDN通常用来提供静态数据,比如JavaScript文件和图片资源,所以适合RxJS这种纯JavaScript静态资源的发布。
你可以像下面这样引用,对应URL总是会跳转到最新版本的RxJS内容。
<script src='https://unpkg.com/rxjs/bundles/Rx.min.js'></script>
使用公共CDN还有一个好处,就是可以充分利用浏览器的缓存机制,如果用户在访问你的网页应用之前访问过其他网站,而且那些网站也使用了一样的CDN静态资源,那么浏览器可以直接从本地缓存中获取这些资源,省去了下载时间。
不过,从CDN获取RxJS也有缺点,那就是RxJS要下载就要全部下载,没办法根据应用的需要定制。实际项目中,如果不会使用很多RxJS的功能,建议还是避免导入全部RxJS的做法,使用npm导入然后利用打包工具组合/Tree-Shaking的能力,这样更加容易控制整个项目的体积。
Observable和Observer
要理解RxJS,先要理解两个最重要的概念:Observable和Observer。
顾名思义,Observable就是“可以被观察的对象”即“可被观察者”,而Observer就是“观察者”,连接两者的桥梁就是Observable对象的函数subscribe。
RxJS中的数据流就是Observable对象,Observable实现了下面两种设计模式:
- 观察者模式(Observer Pattern)
- 迭代器模式(Iterator Pattern)
大家要注意了任何一种模式,指的都是解决某一个特定类型问题的套路和方法。现实世界的问题复杂多变,往往不是靠单独一种模式能够解决的,更需要的是多种模式的组合,RxJS的Observable就是观察者模式和迭代器模式的组合。
接下来,先分别介绍两种模式,然后看这两种模式结合在一起产生的强大力量。
观察者模式
观察者模式要解决的问题,就是在一个持续产生事件的系统中,如何分割功能,让不同模块只需要处理一部分逻辑,这种分而治之的思想是基本的系统设计概念,当然,“分” 很容易,关键是如何 “治”。
观察者模式对“治”这个问题提的解决方法是这样,将逻辑分为发布者(Publisher)和观察者(Observer),其中发布者只管负责产生事件,它会通知所有注册挂上号的观察者,而不关心这些观察者如何处理这些事件,相对的,观察者可以被注册上某个发布者,只管接收到事件之后就处理,而不关心这些数据是如何产生的。
在RxJS的世界中,Observable对象就是一个发布者,通过Observable对象的subscribe函数,可以把这个发布者和某个观察者(Observer)连接起来。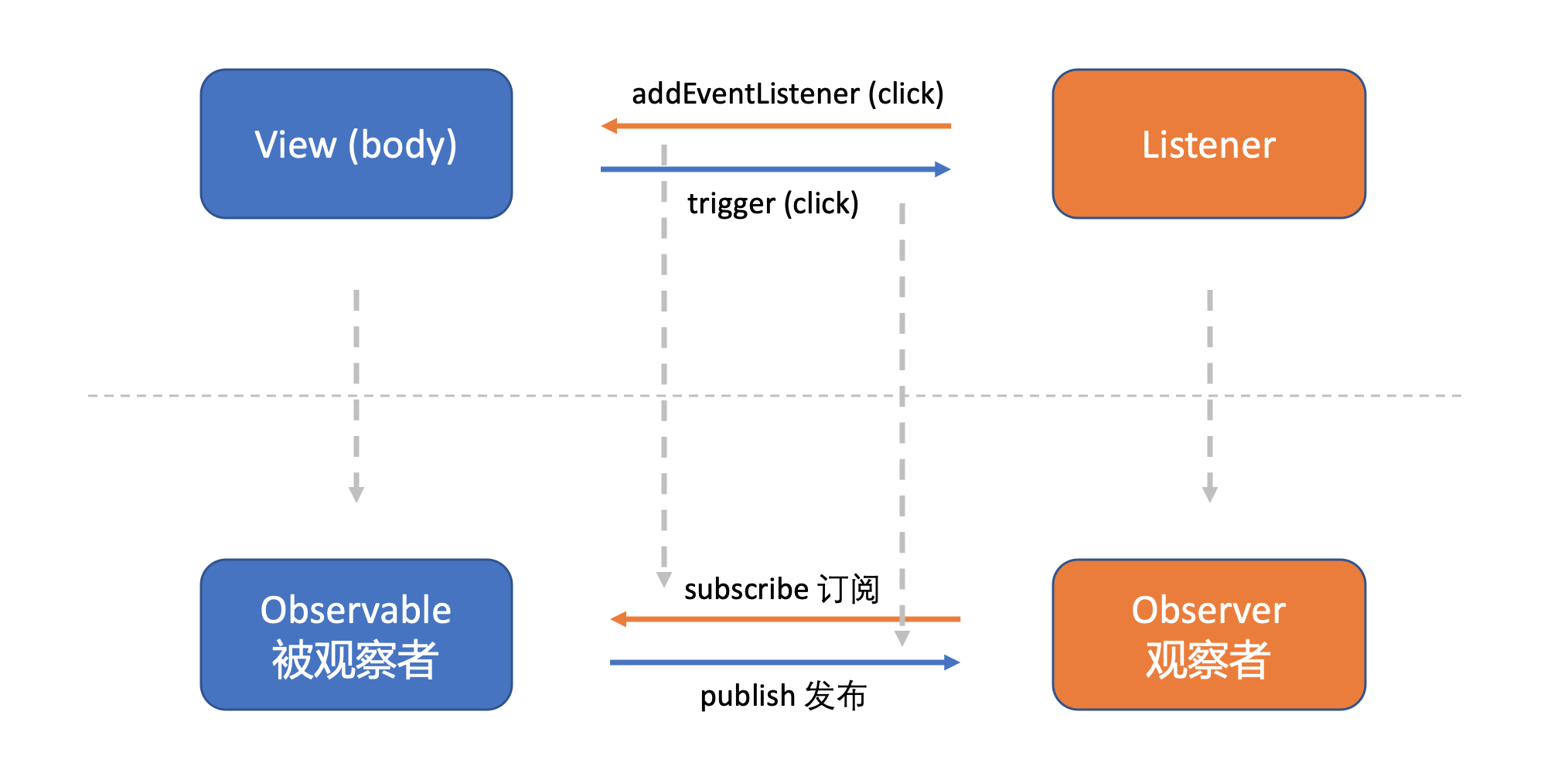
观察者模式带来的好处很明显,这个模式中的两方都可以专心做一件事,而且可以任意组合,也就是说,复杂的问题被分解成三个小问题:
- 如何产生事件,这是发布者的责任,在RxJS中是Observable对象的工作。
- 如何响应事件,这是观察者的责任,在RxJS中由subscribe的参数来决定。
- 什么样的发布者关联什么样的观察者,也就是何时调用subscribe。
迭代器模式
迭代器指的是能够遍历一个数据集合的对象,因为数据集合的实现方式很多,可以是一个数组,也可以是一个树形结构,也可以是一个单向链表……迭代器的作用就是提供一个通用的接口,让使用者完全不用关心这个数据集合的具体实现方式。
迭代器另一个容易理解的名字叫游标,就像是一个移动的指针一样,从集合中一个元素移到另一个元素,完成对整个集合的遍历。
设计模式的实现方式很多,但是不管对应的函数如何命名,通常都应该包含这样几个函数:
- getCurrent,获取当前被游标所指向的元素。
- next,将游标移动到下一个元素,调用这个函数之后,getCurrent获得的元素就会不同。
- isDone,判断是否已经遍历完所有的元素。
const iterator = getIterator();while(iterator.isDone()){console.log(iterator.getCurrent());iterator.next();}
然而,在使用RxJS的过程中绝对看不到类似这样的代码,实际上,你都看不到上面所说的三个函数,因为,上面所说的是”拉”式的迭代器实现,而RxJS实现的是”推”式的迭代器实现。
在编程的世界中,所谓“拉”(pull)或者“推”(push),都是从数据消费者角度的描述,比如,在网页应用中,如果是网页主动通过AJAX请求从服务器获取数据,这是“拉”,如果网页和服务器建立了websocket通道,然后,不需要网页主动请求,服务器都可以通过websocket通道推送数据到网页中,这是 “推”。
在RxJS中,作为迭代器的使用者,并不需要主动去从Observable中“拉”数据,而是只要subscribe上Observable对象之后,自然就能够收到消息的推送,这就是观察者模式和迭代器两种模式结合的强大之处。
创造Observable
学习RxJS一定要了解核心概念Observable,每个Observable对象,代表的就是在一段时间范围内发生的一系列事件。
我们已经讲了很多理论,是时候看看真正的代码了,下面的代码创造和使用了一个简单的Observable对象:
import { Observable } from "rxjs";const source = new Observable(subscriber => {subscriber.next(1);subscriber.next(2);subscriber.next(3);});source.subscribe({next(x) {console.log('got value ' + x);}});
这段代码依次输出最小的三个正整数,结果如下:
123
让我们来分析这段代码:
第一步,导入了Observable类。
第二步,给Observable构造函数传入了一个回调函数,这个回调函数完全决定了Observable对象的行为。回调函数接受一个名为subscriber的参数,函数体内,调用参数subscriber的next函数,把数据 “推” 给observer。
第三步,调用Observable构造函数,产生一个名为source的数据流对象。
第四步,通过调用source.subscribe方法将观察者对象和source关联起来。
什么是观察者对象?
在上面的代码中,source.subscribe传入的对象就是观察者对象。
创建Observable实例也就是创建一个“发布者”,一个 “观察者” 调用某个Observable实例的subscribe函数,对应的onSubscribe函数就会被调用,subscribe函数中的参数对象就是 “观察者” 对象 ,Observable函数中的回调就可以任意操作 “观察者” 对象。
这个过程,就等于在这个Observable对象上挂了号,以后当这个Observable对象产生数据时,观察者就会获得通知。
在RxJS中,Observable是一个特殊类,它接受一个处理观察者的回调函数,而source.subscribe的参数对象就是一个普通的对象,没有什么神奇之处,对它的要求就一个它必须包含一个名为next的属性,这个属性的值是一个函数,用于接收被 “推” 过来的数据。
这里你要注意了:
调用source.subscribe函数传入的对象成为了source的”观察者”。就在subscribe函数被调用的过程中,Observable构造函数中的回调函数会被调用,这时候,Observable构造函数中的回调函数中的参数subscriber所代表的就是观察者(source.subscribe函数传入的对象),但并不是(source.subscribe函数传入的对象)对象本身。
RxJS会对观察者做一个包装,在这里,subscriber 对象实际上是(source.subscribe函数传入的对象)的一个包装,所以二者并不完全一样,可以把subscriber 理解为观察者的一个代理,对subscriber 的所有函数调用都会转移到(source.subscribe函数传入的对象)的同名函数上去。
在Observable构造函数的回调函数中,连续调用subscriber.next函数三次,实际上也就是调用了(source.subscribe函数传入的对象)的next函数三次,而(source.subscribe函数传入的对象)的next函数所做的就是把传入参数输出,所以,最后产生了连续的三个正整数输出。
从上面的程序执行过程可以看出,单独一个Observable对象,或者单独一个观察者对象,都完成不了什么任务。Observable对象就像一台只会产生数据的机器,观察者对象则是一台只会处理数据的机器,不把这两台机器连接起来,什么都不会发生,Observable的逻辑和观察者对象的逻辑都不会执行,只有两者通过subscribe连接起来之后,才能让这两台机器运转起来。只为输出一串正整数,写了这么多代码,显得有点高射炮打蚊子,接下来,就让RxJS来解决更加复杂一点的问题。
跨越时间的Observable
在上一节的代码例子中,Observable是不间断地推送出一串正整数,也可以让推送每个正整数之间有一定的时间间隔。需要考虑的是,如何增加类似“一秒钟间隔” 逻辑,或者说,这个逻辑放在哪一部分更合适?
根据观察者模式,代码分成Observable和观察者两个部分,这个“时间间隔” 放在哪个部分更合适?
观察者是被 “推” 数据的,在执行过程中处于被动地位,所以,控制节奏的事情,还是应该交给Observable来做,Observable既然能够 “推” 数据,那同时负责推送数据的节奏,天经地义,完全合理。
RxJS的Observable也完全支持这样的功能,我们只需要修改回调的函数,代码如下:
import { Observable } from "rxjs";const source = new Observable(subscriber => {let n = 1;const handle = setInterval(()=>{subscriber.next(n++);if(n>3){clearInterval(handle);}},1000);});source.subscribe({next(x) {console.log('got value ' + x);}});
我们重新运行代码,依然是输出1、2、3三个正整数,但是每次输出之间都间隔一秒钟。
能够实现这种效果,是因为回调函数可以完全控制何时调用subscriber参数的next函数(source.subscribe函数传入的代理对象),我们利用setInterval每隔一秒钟调用一次next,同时让n变量递增,当增加超过3时,就取消掉setInterval,于是就达到了在每个推送数据之间有时间间隔的目的。
这个例子虽然简单,但是展现了Observable的一个重要功能:推送数据可以有时间间隔。Observable这样的时间特性使得异步操作十分容易,因为对于观察者对象,只需要被动接受推送数据来处理,而不用关心数据何时产生。
资源释放问题
上述的Observable都只产生有限的数据,其实Observable可以产生无限多的数据。比如我们将代码改造成这样:
import { Observable } from "rxjs";const source = new Observable(subscriber => {let n = 1;const handle = setInterval(()=>{subscriber.next(n++);},1000);});source.subscribe({next(x) {console.log('got value ' + x);}});
运行程序,每隔一秒钟,命令行中输入一个递增的正整数运行程序,1、2、3…程序的运行不会停止,直到我们在命令行中强行终止这个程序。
可见,Observable对象中吐出来的数据可以是无穷的。
假如我们不中断这个程序,让它一直运行下去,这个程序也不会消耗更多的内存,这是因为Observable对象每次只吐出一个数据,然后这个数据就被Observer消化处理了,不会存在数据的堆积。
这种操作方式,和把所有数据堆积到一个数组中,然后挨个处理数组中元素很不一样,如果使用数组,内存的消耗就随数组大小改变。
现实中有的数据流就是这样永无止境,或者说,在程序运行过程中不会终止,比如,把网页中一个元素click事件理解为一个数据流,在这个网页关闭或者跳转到其他页面之前,这个数据流是一直存在的。
当然,还有一些数据流会终止的,比如,我们只想获得前3个正整数,那么,在Observable对象吐出1、2、3之后,这个数据流就应该终止了。不过,Observable对象如果只是停止吐出数据,也只不过不再调用next函数推送数据,并不能给予Observer一个终止信号,Observer依然时刻准备着接收Observable的推送数据,相关的资源也不会被释放,所以,为了让Observer明确知道这个数据流已经不会再有新数据产生了,还需要一个宣称Observable对象已经完结的方式。
注意:Observable对象调用观察者next传递出数据的动作 我们把此行为作称为形象一点的”吐出”。
Observable完结 / 资源释放
调用Observer的next只能表达 “这是现在要推送的数据”, next没法表达 “已经没有更多数据了”,所以,为了让Observable有机会告诉观察者 “已经没有更多数据了”,需要有另外一种通信机制,在RxJS中,实现这种通信机制用的就是观察者的complete函数。
我们修改上面代码中的source.subscribe函数中参数对象(观察者),如下所示:
source.subscribe({next(x) {console.log('got value ' + x);},complete(){console.log("no more data");}});
增加了complete这样一个字段,这个字段的值是一个函数,这个函数没有传入参数,函数的工作是在命令行上输出一个No More Data字符串,代表我们希望在数据流里没有更多内容时所作的动作。
所以,接下来我们修改回调函数,代码如下:
import { Observable } from "rxjs";const source = new Observable(subscriber => {let n = 1;const handle = setInterval(()=>{subscriber.next(n++);if(n>3){clearInterval(handle);subscriber.complete();}},1000);});source.subscribe({next(x) {console.log('got value ' + x);},complete(){console.log("no more data");}});
在取消掉setInterval的效果之后,立刻调用了参数observer的complete函数,和next函数一样,对subscriber的complete函数调用最终会触发观察者的complete函数调用。
运行这个程序,可以看到输出结果为。
123no more data
如上面的代码可见,观察者对象的complete何时被调用,完全看Observable的行为,如果Observable不主动调用complete, Observer即使准备好了complete函数,也不会发生任何事情,和数据一样,完结信号也是由Observable “推” 给观察者的。
错误处理
Observable 和 观察者的交流,除了用next传递数据,用complete表示 “没有更多数据”,还需要一种表示“出错了”的方式。
理想情况下,Observable只管生产数据给观察者来消耗,但是,难免有时候Observable会遇到了异常情况,而且这种异常情况不是Observable自己能够处理并恢复正常的,Observable在这时候没法再正常工作了,就需要通知对应的Observer发生了这个异常情况,如果只是简单地调用complete, Observer只会知道“没有更多数据”,却不知道没有更多数据的原因是因为遭遇了异常,所以,我们还要在Observable和Observer的交流渠道中增加一个新的函数error。
修改代码来展示error的功能,代码如下:
import { Observable } from "rxjs";const source = new Observable(subscriber => {subscriber.next(1);subscriber.error("error");subscriber.complete();});source.subscribe({next(x) {console.log('got value ' + x);},error(e){console.log(e);},complete(){console.log("no more data");}});
这段代码的执行结果如下:
1error
在回调函数中,通过调用next函数给观察者推送了一个数据1,接着,error函数给观察者推送了一个错误信息,在这里错误信息是一个字符串”error”,被观察者对象的error处理函数输出。
值得注意的是,在调动subscriber.error函数之后,紧接着调用了subscriber.complete,却没有引发观察者对象的complete函数调用,这是为什么呢?
在RxJS中,一个Observable对象只有一种终结状态,要么是完结(complete),要么是出错(error),一旦进入出错状态,这个Observable对象也就终结了,再不会调用对应Observer的next函数,也不会再调用Observer的complete函数;同样,如果一个Observable对象进入了完结状态,也不能再调用Observer的next和error。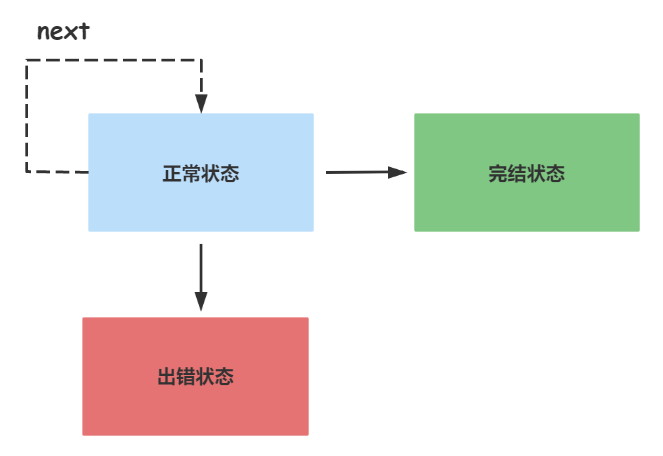
Observable对象状态流转图
在前面已经介绍过,回调函数的参数subscriber并不是传给subscribe的参数对象,而是对subscribe的参数对象的包装,所以,即使在subscriber.error被调用之后强行调用subscriber.complete,也不会真正调用到subscribe的参数(观察者)对象的complete函数。
退订Observable
现在已经了解了Observable和观察者之间如何建立关系,两者之间除了要通过subscribe建立关系,有时候还需要断开两者的关系,例如,观察者只需要监听一个Observable对象三秒钟时间,三秒钟之后就不关心这Observable对象的任何事件了,这时候怎么办呢?
这就涉及一个 “退订”(unsubscribe)的概念。
在之前的例子中,回调函数并没有返回任何结果,其实,回调函数可以返回一个对象,对象上可以有一个unsubscribe函数,顾名思义,代表的就是和subscribe “订阅” 相反的动作,也就是退订。
import { Observable } from "rxjs";const source = new Observable(subscriber => {let n = 1;const handle = setInterval(()=>{subscriber.next(n++);},1000);return {unsubscribe:()=>{clearInterval(handle);}}});const subScription= source.subscribe({next(x) {console.log('got value ' + x);}});setTimeout(()=>{subScription.unsubscribe();},3500);
这次,回调函数有返回结果,返回结果是一个对象,其中包含一个unsubscibe字段,这个unsubscribe字段的值是另一个函数,调用了clearInterval来清除setInterval产生的效果。
在上面的代码中,subscribe函数的返回结果存为变量subScription,在完成subscribe的3.5秒钟之后,调用了subscription上的unsubscribe函数,也就是在3.5秒之后做退订的动作。
程序的执行结果是每隔一秒钟输出一个递增的正整数,在输出了1、2、3之后,unsubcribe函数被调用,Observable对象source就再也不会产生新的数据了,输出结束,这是一个完整的 “订阅” 和 “退订” 过程。
创建同步数据流
同步数据流,或者说同步Observable对象,需要关心的就是:
- 产生哪些数据。
- 数据之间的先后顺序如何。
对于同步数据流,数据之间的时间间隔不存在,所以不需要考虑时间方面的问题。
of:列举数据
利用of这个操作符可以轻松创建指定数据集合的Observable对象。
什么是操作符?
任何一种Rx的实现,都包含一个操作符的集合,这是ReactiveExtension的重要组成部分。RxJS作为JavaScript语言的Rx实现,当然也不例外。
如果要给操作符一个定义,可以这么描述:一个操作符是返回一个Observable对象的函数,不过他们的功能有所不同有的是创建型/转化型/过滤型/合并型/错误处理类型….
比如,为了产生包含三个正整数的Observable对象,如果利用Observable的构造函数,需要写一大堆的代码,但是如果使用of,产生数据流的代码可以简化为一行,代码如下:
import { Observable, of } from "rxjs";var source = of(1,2,3);source.subscribe({next(x) {console.log(x);}});
of 有三个参数1、2、3,于是source被订阅时就会吐出三个数据,然后调用观察者的complete函数。
创建异步数据的Observable对象
异步数据流,或者说异步Observable对象,不光要考虑产生什么数据,还要考虑这些数据之间的时间间隔问题,RxJS提供的操作符就是要让开发者在日常尽量不要考虑时间因素。
interval和timer:定时产生数据
到目前为止介绍的创建类操作符产生的数据流都是同步产生数据,一口气把数据传给下游,每个数据之间没有时间间隔,不过,就像官方网站宣传的那样,RxJS的最大的卖点是擅长处理异步操作,也就是擅长处理在一个时间段上间歇性产生数据的数据流,接下来,我们就介绍两种最简单的产生异步数据流的操作符:interval和timer。
在JavaScript中要模拟异步的处理,惯常的做法就是用JavaScript自带的两个函数setInterval和setTimeout,通过指定时间,让一些指令在一段时间之后再执行。可以说,在RxJS中,interval和timer这两个操作符的地位就等同于原生JavaScript中的setInterval和setTimeout。注意,只是说地位等同,功能上并不完全一样,我们接下来就会看到区别。
interval接受一个数值类型的参数,代表产生数据的间隔毫秒数,返回的Observable对象就按照这个时间间隔输出递增的整数序列,从0开始。比如,interval的参数是1000,那么,产生的Observable对象在被订阅之后,在1秒钟的时刻吐出数据0,在2秒钟的时刻吐出数据1,在3秒钟的时刻吐出数据2……对应的实例代码如下:
import { Observable, interval} from "rxjs";var source$1 = interval(1000);source$1.subscribe({next(x) {console.log(x);},complete(){console.log("no more data");}});
输出
01234...
除了有对应于setInterval的interval, RxJS还有对应于setTimeout的名为timer的操作符。timer的第一个参数可以是一个数值,也可以是一个Date类型的对象。如果第一个参数是数值,代表毫秒数,产生的Observable对象在指定毫秒之后会吐出一个数据0,然后立刻完结。
import { Observable, timer} from "rxjs";var source$1 = timer(1000);source$1.subscribe({next(x) {console.log(x);},complete(){console.log("no more data");}});
输出:
0no more data
from:可把一切转化为Observable
from可能是创建类操作符中包容性最强的一个了,因为它接受的参数只要“像”Observable就行,然后根据参数中的数据产生一个真正的Observable对象。“像”Observable的对象很多,一个数组就像Observable,一个不是数组但是“像”数组的对象也算,一个字符串也很像Observable,一个JavaScript中的generator也很像Observable,一个Promise对象也很像,所以,from可以把任何对象都转化为Observable对象。
有了这个操作符我们就可以做很多有意思的事情了。来看….
利用from来转化数组,实例代码如下:
import { Observable, from} from "rxjs";var source$1 = from([1,2,3]);source$1.subscribe({next(x) {console.log(x);},complete(){console.log("no more data");}});
其中,source$会产生3个数据,也就是from输入数组参数的3个元素:1、2、3。这很好了解,一个数组本身就代表一个数据序列,转换成Observable是很自然的事情。神奇的是,一个对象即使不是数组对象,但只要表现得像是一个数组,一样可以被from转化,下面是示例代码:
import { Observable, from} from "rxjs";function toObservable(){return from(arguments);}var source$1 = toObservable(1,2,3);source$1.subscribe({next(x) {console.log(x);},complete(){console.log("no more data");}});
在JavaScript中,任何一个函数体中都可以通过arguments访问所有的调用参数,arguments其实并不是一个数组,但是它也支持length属性,也支持根据下标访问某个具体的参数,所以表现得“像”是一个数组,一样能够被from处理。
这两次代码输出一致:
1
2
3
no more data
在JavaScript中,任何一个函数体中都可以通过arguments访问所有的调用参数,arguments其实并不是一个数组,但是它也支持length属性,也支持根据下标访问某个具体的参数,所以表现得“像”是一个数组,一样能够被from处理。
import { Observable, from} from "rxjs";
function* generateNumber(max){
for(let i=1; i<max; i++){
yield i;
}
}
var source$1 = from(generateNumber(5));
source$1.subscribe({
next(x) {
console.log(x);
},
complete(){
console.log("no more data");
}
});
在上面的例子中,generateNumber就是一个generator函数,如果迭代读取generateNumber(5)的结果,就会得到1、2、3、4, from就是利用这一点,把generator的结果塞给了产生的Observable对象。
输出结果:
1
2
3
4
no more data
fromPromise:异步处理的交接
如果from的参数是Promise对象,那么这个Promise成功结束,from产生的Observable对象就会吐出Promise成功的结果,并且立刻结束,示例代码如下:
import { Observable, from} from "rxjs";
const promise = Promise.resolve("操作成功");
var source$1 = from(promise);
source$1.subscribe({
next(x) {
console.log(x);
},
complete(){
console.log("no more data");
}
});
Promise对象虽然也支持异步操作,但是它只有一个结果,所以当Promise成功完成的时候,from也知道不会再有新的数据了,所以立刻完结了产生的Observable对象。
输出结果:
操作成功
no more data
Promise对象虽然也支持异步操作,但是它只有一个结果,所以当Promise成功完成的时候,from也知道不会再有新的数据了,所以立刻完结了产生的Observable对象。
import { Observable, from} from "rxjs";
const promise = Promise.reject("操作失败");
var source$1 = from(promise);
source$1.subscribe({
next(x) {
console.log(x);
},
error(x){
console.log(x);
},
complete(){
console.log("no more data");
}
});
当Promise对象以失败而告终的时候,from产生的Observable对象也会立刻产生失败事件。
输出:
操作失败
总结:
到此Rxjs 中异步编程的部分我们就到此结束, 但Rxjs 这个框架的优秀之处不仅于此,如果我们要详细讲到里面的每个知识点甚至我们可以单独去开一个专题课程来研究。
你们可能会疑惑有了回调 有了promise 我们是否还需要通过Rxjs 对异步操作进行处理。答案是肯定的我们先来对比下:
使用promise异步编程的写法
const promise = new Promise((resolve, reject) => {
setTimeout(() => {
resolve('操作成功了');
}, 1000);
});
promise.then(data => {
console.log(data);
});
使用rxjs异步流编程的写法
import { Observable } from 'rxjs';
const stream = new Observable(observer => {
setTimeout(() => {
observer.next('操作成功');
});
});
stream.subscribe(data => {
console.log(data);
});
rxjs可以取消订阅,但是promise却不可以
import { Observable } from 'rxjs';
const stream = new Observable(observer => {
setTimeout(() => {
observer.next('请求成功');
}, 2000);
});
const disposable = stream.subscribe(data => {
console.log(data);
});
setTimeout(() => {
disposable.unsubscribe(); // 取消订阅
}, 1000);
异步多次执行
对于promise的执行是一个状态到另外一个状态后是不可变的,结果要不是resole就是reject,但是不能回退。
在promise中的定时器只执行一次
const promise = new Promise((resolve, reject) => {
setInterval(() => {
resolve('promise成功了');
}, 1000);
});
promise.then(data => {
console.log(data);
});
使用rxjs多次执行
import { Observable } from 'rxjs';
const stream = new Observable(observer => {
let count: number = 0;
setInterval(() => {
observer.next(count++);
}, 1000);
});
const disposable = stream.subscribe(data => {
console.log(data);
});
但最能够体现 rxjs 威力的还是那有大量的异步数据更新,数据之间还互相有依赖关系的大型前端应用。这种场景下,你甚至可以基于 rxjs 设计一整套数据管理的方案。
简单/常规的异步操作场景下我们使用 Promise 以及未来会学到的async 是完全够用的。

若有收获,就点个赞吧
0 人点赞
