1.什么是消息引擎
在了解kafka之前,首先要了解什么叫消息引擎(或者说消息队列、消息中间件)。最通俗的说法,A系统发送消息到消息引擎,B系统通过消息引擎获取到A系统发送的消息,对消息进行业务逻辑处理
从上述描述可以看出,通过消息引擎,可以实现系统业务之间的异步解耦。同时在流量峰值时,下游系统依然可以按照常规效率消费消息,进而实现了所谓了请求流量削峰填谷,提高系统的健壮性。
消息引擎的含义就是:系统通过消息引擎传递语义明确的序列化消息,进而实现以松耦合的形式传递数据的功能
2.消息的传递模式
点对点
顾名思义,一个发送者对应一个消费者,同时消息引擎以推的形式将消息推送给消费者,以一种一对一的形式进行消息的发送与接收。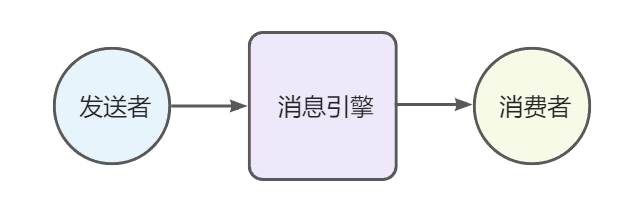
发布/订阅
与点对点不同,发布订阅模式存在一个叫做主题的逻辑概念。多个发送者可以将消息发送到同一个主题,
同时一个主题也可以由多个消费者消费,并且消费者是以拉数据的形式获取消息。以一种多对多的形式进行消息的发送与接收。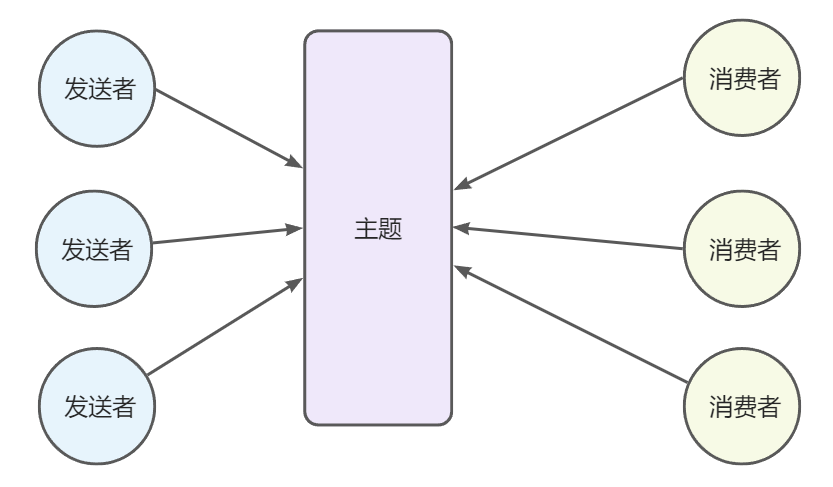
3.什么是Kafka
kafka是一种高吞吐量、分布式、基于发布/订阅的消息引擎系统,最初由Linkedin公司开发,使用Scala语言和Java编写,目前是Apache的开源项目。
但是kafka又不仅仅是一个消息引擎,同时也是一个超高吞吐量的流式处理平台
4.Kafka中的核心概念
服务端
Broker
Kafka服务实例,即一个 Kafka 集群由多个 Broker 组成,Broker 负责接收和处理客户端发送过来的请求,以及对消息进行持久化。通常不同的Broker部署在不同的服务器上,这样可以实现Kafka集群的高可用性
Topic
主题,Kafka中最重要的概念。是一种逻辑概念,在逻辑上将消息进行业务区分。生产者和消费者通过发布/订阅不同的主题来进行消息的发布和订阅。实际应用中常用与不同业务的区分
Partition
分区,主题是逻辑概念,分区可以理解为物理概念。可以类比MongoDB或ElasticSearch中的分片,是分布式高可用系统必备的一个功能。一个主题通常由多个Partition构成,同时每个Partition都分布在不同的Broker上。需要注意的是,Kafka中的分区是从0开始标记的
Replication
副本,与MongoDB或ElasticSearch一样,Kafka中对于每个分区,同样支持副本集。Kafka 定义了两类副本
- 领导者副本(Leader Replica):与客户端程序进行交互,对外提供服务。有且只有一个
追随者副本(Follower Replica):被动地追随领导者副本,不能与外界进行交互,只起到一个数据冗余的功能。可以有0到n个
Offset
位移,Kafka中消息是顺序持久化的。即使消息被消费,也不会删除消息。消息的消费进度是通过偏移量,也就是Offset控制的
Offset大致分为两种分区Offset:指的是消息写入到主题的某个分区之后,所对应的位置。每个消息对应不变的偏移量,偏移量是递增的。同样的,偏移量也是从0开始
消费者Offset:指的是消费者对于当前分区消息的消费进度标识,用于记录当前消费者消费到了哪条消息。不同的消费者对应不同分区的偏移量也不同。
客户端
Producer
Consumer
Consumer Group
消费者组,多个消费者可以组成一个消费者组,消费同一个topic中的数据,这样就可以基于发布订阅模式,来实现点对点。同时一个消费者对应一个到多个partition,多个消费者同时消费多个partition,实现了kafka的超高吞吐量
并且,Kafka还支持不同消费者组同时消费同一条消息Rebalance
重平衡机制,当消费者组中某个消费者因为某些原因宕机以后,该消费者对应的分区就空闲了,此时同组中的其他消费者会自动分配到该分区继续消费,这一过程成为Rebalance。这是Kafka消费者端实现高可用的一个关键特性
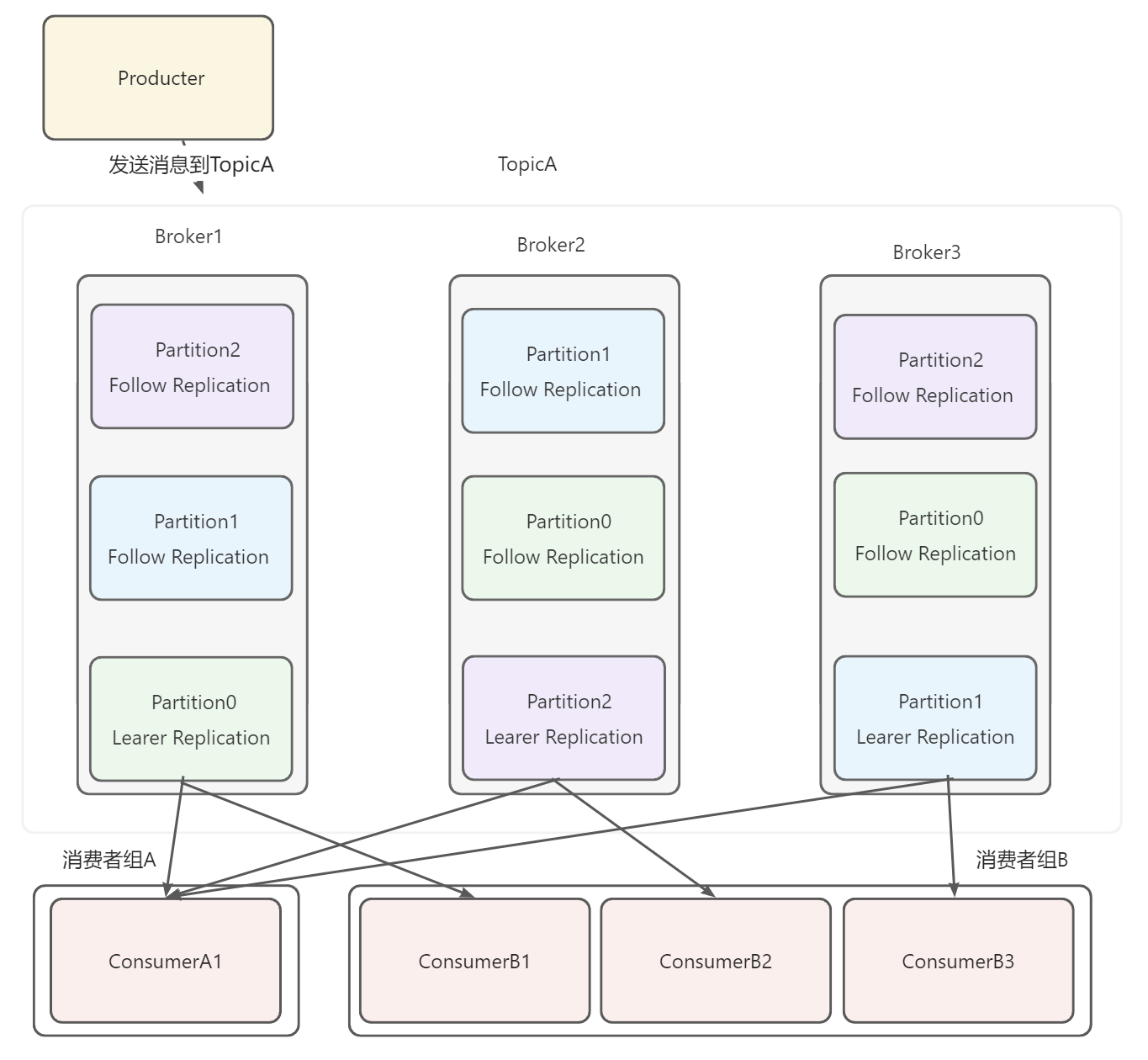
图示
假设指定当前Topic包含3个Partition,每个Partition包含3个Replication。1个Leader Replication,2个Follow Replication
5.Kafka的特点
高吞吐、低延迟:Kafka的特点就是消息的收发非常迅速,每秒可以处理几十万条消息,最低延迟可以低至几毫秒
- 高伸缩:与ElasticSearch或MongoDB一样,Kafka也是基于分布式部署,并且每个分区也都对应相应的副本集
- 持久性:Kafka 能够允许数据的持久化存储,消息被持久化到磁盘,并支持数据备份防止数据丢失
- 容错性:允许集群中的节点失败,某个节点宕机,Kafka 集群能够正常工作
-
6.Kafka的使用场景
消息队列:,Kafka有更好的吞吐量,内置的分区,冗余及容错性,这让Kafka成为了一个很好的大规模消息处理应用的解决方案。
- 行为追踪:Kafka的另一个应用场景是跟踪用户浏览页面、搜索及其他行为,以发布-订阅的模式实时记录到对应的topic里。那么这些结果被订阅者拿到后,就可以做进一步的实时处理,或实时监控
- 日志收集:Kafka 的基本概念来源于提交日志,比如我们可以把数据库的更新发送到 Kafka 上,用来记录数据库的更新时间,通过kafka以统一接口服务的方式开放给各种consumer,例如Hadoop、Hbase、Solr等。
- 流式处理:流式处理是有一个能够提供多种应用程序的领域。
限流削峰:Kafka 多用于互联网领域某一时刻请求特别多的情况下,可以把请求写入Kafka 中,避免直接请求后端程序导致服务崩溃。
7.Kafka的核心API
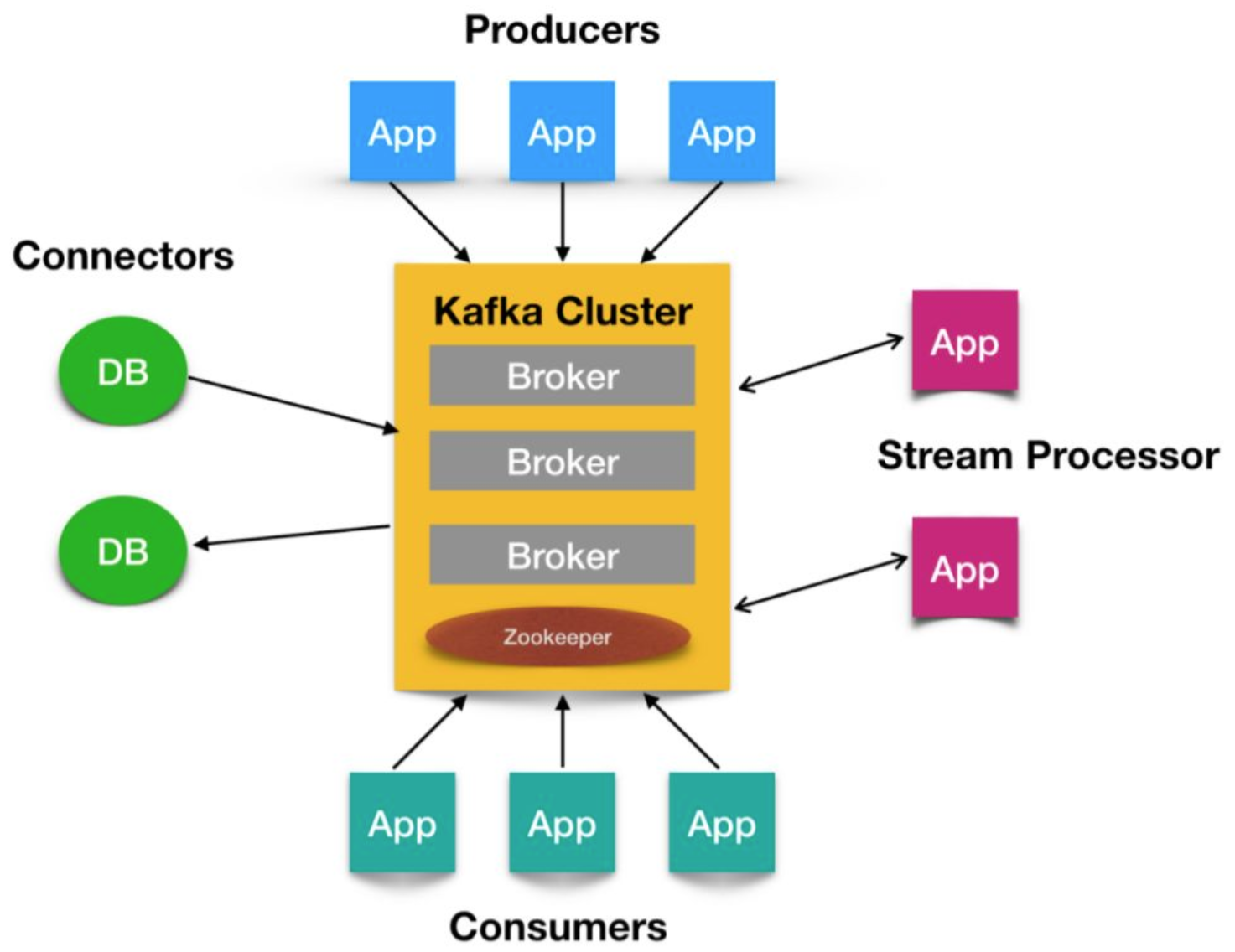
如图所示,共包括4种核心APIProducer API:它允许应用程序向一个或多个 topics 上发送消息记录
- Consumer API:允许应用程序订阅一个或多个 topics 并处理为其生成的记录流
- Streams API:它允许应用程序作为流处理器,从一个或多个主题中消费输入流并为其生成输出流,有效的将输入流转换为输出流。
- Connector API:它允许构建和运行将 Kafka 主题连接到现有应用程序或数据系统的可用生产者和消费者。例如,关系数据库的连接器可能会捕获对表的所有更改

若有收获,就点个赞吧
0 人点赞
