1.发布
确定分区
众所周知,Kafka是基于可扩展的分布式架构部署的,一个Topic通常由1~n个Partition构成,那么Producer在发布消息时,如何确定将消息发送到哪一个Partiton?
Kafka中提供了以下的发布策略
- 如果在发消息的时候指定了分区,则消息投递到指定的分区
- 如果没有指定分区,但是消息的key不为空,则基于key的哈希值%总分区数取模运算,选择一个分区
- 如果既没有指定分区,且消息的key也是空,则用轮询的方式选择一个分区
批量压缩与批量发送
在确定了分区后,Producer会将消息发送出去。但实际上,并不是每次调用消息的发送就会直接将消息发送给Broker。
Producer存在一个内置缓存区,消息被发布后会先存入缓存区,在达到一定的时间阈值或者容量阈值后,Kafka会将缓存区中的消息批量压缩,然后批量一起发送出去
在此过程中,涉及到了 两个线程——main 线程和 Sender 线程,以及一个线程共享变量——RecordAccumulator。 main 线程将消息发送给 RecordAccumulator,Sender 线程不断从 RecordAccumulator中拉取消息发送到Broker。副本之间数据同步
同步原理
在消息发送到了指定的Partition后,Partition是如何进行消息处理的呢?
为了实现高可用性,Kafka对于每个分片,都采取了副本数据冗余的策略。副本包含1个Leader副本以及0~n个Follow副本。
- Leader副本负责与Producer以及Consumer交互
- Follow副本只负责进行数据的冗余备份,并且在Leader副本宕机时,重新选举出一个新的Leader副本
在Procuder将消息发布到对应的Partiton后,Partition的Leader Replication首先进行数据的写入,并且Follow Replication会定期从Leader Replication拉取最新的数据,进行消息数据的同步
ISR
Kafka如何确定所有Follow副本数据同步完成呢?
一个Topic的每个Partition都维护了一个ISR列表,其中包括所有与Leader副本保持同步的Follow副本,以及Leader副本本身
并且通过replica.lag.time.max.ms参数,来指定当Follow副本与Leader副本的最大失联时间,超过这个时间,Follow副本就会被踢出ISR。被踢出的Follow副本,当消息同步进度与Leader副本一致时,又会重新加入到ISR中
因此可以通过ISR获取到当前Partition所有可用的Follow副本以及Leader副本
ACK
经过上述步骤,消息已经写入到了对应的分区,那么,Producer如何确定消息已经准确发布到了对应的Partition呢?
Kafka可以指定Producer的ack参数来进行消息发布确认机制的选择,ack参数包含三个枚举值
- 0:Producer发送消息后,即可认为消息发布成功,无需等待Partition的Leader副本返回发布成功确认消息
- 1:Producer发送消息后,需要等待Partition的Leader副本返回发布成功确认消息后,才认为消息发布成功。而Leader副本本身消息写入成功后,即会将发布成功确认消息反馈给Producer
-1(ALL):Producer发送消息后,需要等待Partition的Leader副本返回发布成功确认消息后,才认为消息发布成功。而Leader副本需要确认ISR中所有Follow副本都已同步完成,才会将发布成功确认消息反馈给Producer
分区内部是如何写入的
Segment
试想一下,Kafka支持的吞吐量极高,每个Partition存储的消息量极高,如果每个Partition都有一个日志文件构成,那么当进行偏移量消息检索时,文件越大,线性扫描效率就越低。对于追求高吞吐量的Kafka来说,很明显真是不合理的
为了解决这个问题,Partiton采用了分段存储的方案,
每个Partition为一个文件夹,文件夹命名格式:{topic}-number,其中number从0开始递增。而每个Partition文件夹下存储的真正数据文件,就是Segment
每个Partition由多个Segment构成,Producer生产的消息会顺序写入Segment。当一个Segment文件超过指定大小后,就会生成新的Segment命名方式
Segment的命名方式:partition的第一个Segment从0开始标记,第二个Segment以第一个Segment结束的偏移量开始标记,文件名前缀全长20,空值以0补位
示例如下:第一个Segment文件,结尾偏移量为1234:00000000000000000000
- 第二个Segment文件,结尾偏移量为4567:00000000000000001234
- 第二个Segment文件,结尾偏移量为8910:00000000000000004567
-
文件组成
Segment文件并不是一个文件。而是由3个文件构成
.index:基于偏移量的索引文件,并且是以稀疏索引的形式进行消息索引,也就是说,并不是每一个消息都有对应的索引,而是每隔几个消息生成一个索引。索引的格式为offset-address。即消息在当前Segment的偏移量-物理偏移地址。
- .log:真正的消息持久化文件,消息是以顺序写的形式写入到.log文件中。每次查找时,可以先根据消费者偏移量找到对应的Segment.index文件,然后通过.index文件去对应的.log文件中获取真实的消息数据
- .timeindex:基于时间戳的索引文件,具体干啥的没找到相关的文档。吐槽一下,csdn上劣质文档真的太多了
例如:对于索引的第2条信息,代表其对应log文件的偏移量=3,物理地址偏移量=348,全局Partition的偏移量为170410+3 = 170417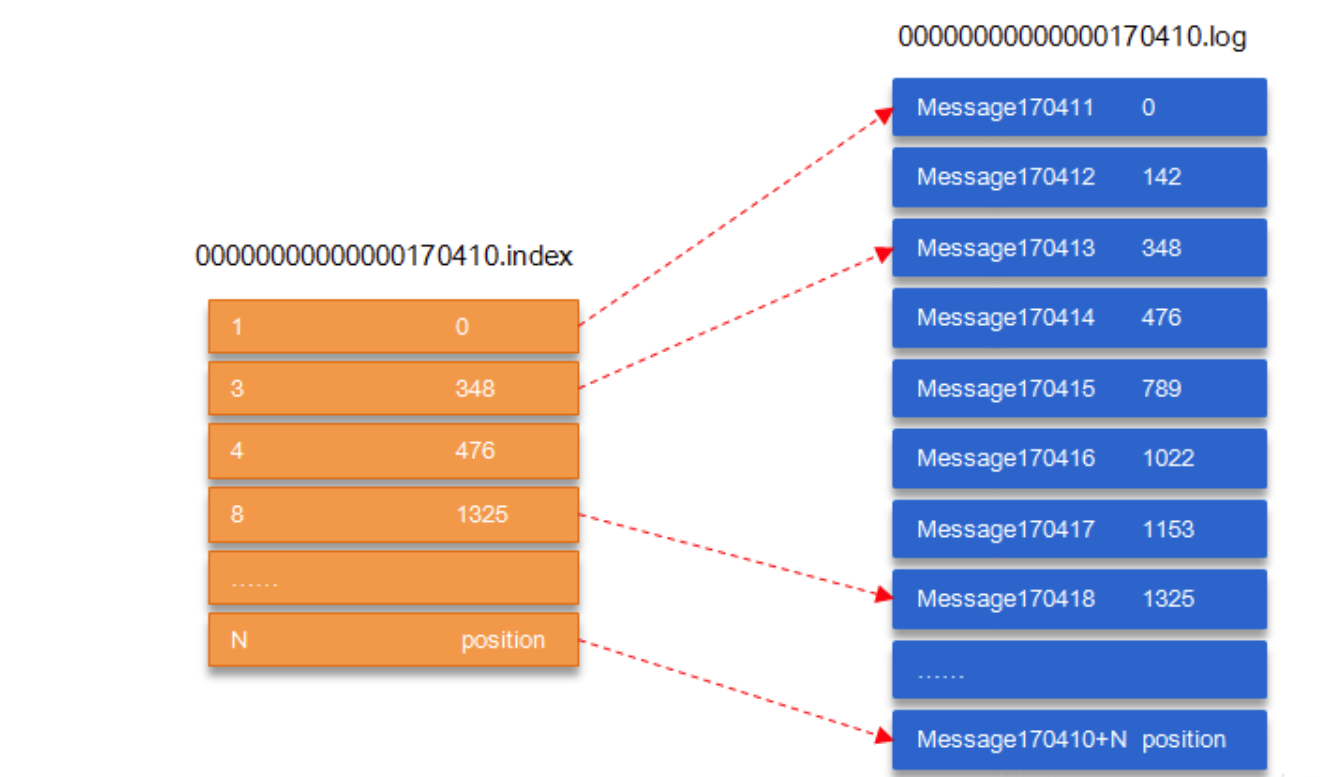
如何确定消息消费完
每条消息都具有固定的物理结构,包括:offset(8 Bytes)、消息体的大小(4 Bytes)等字段。可以通过消息体的大小,来确定读取到哪里时当前消息读取完毕
Segment文件何时删除
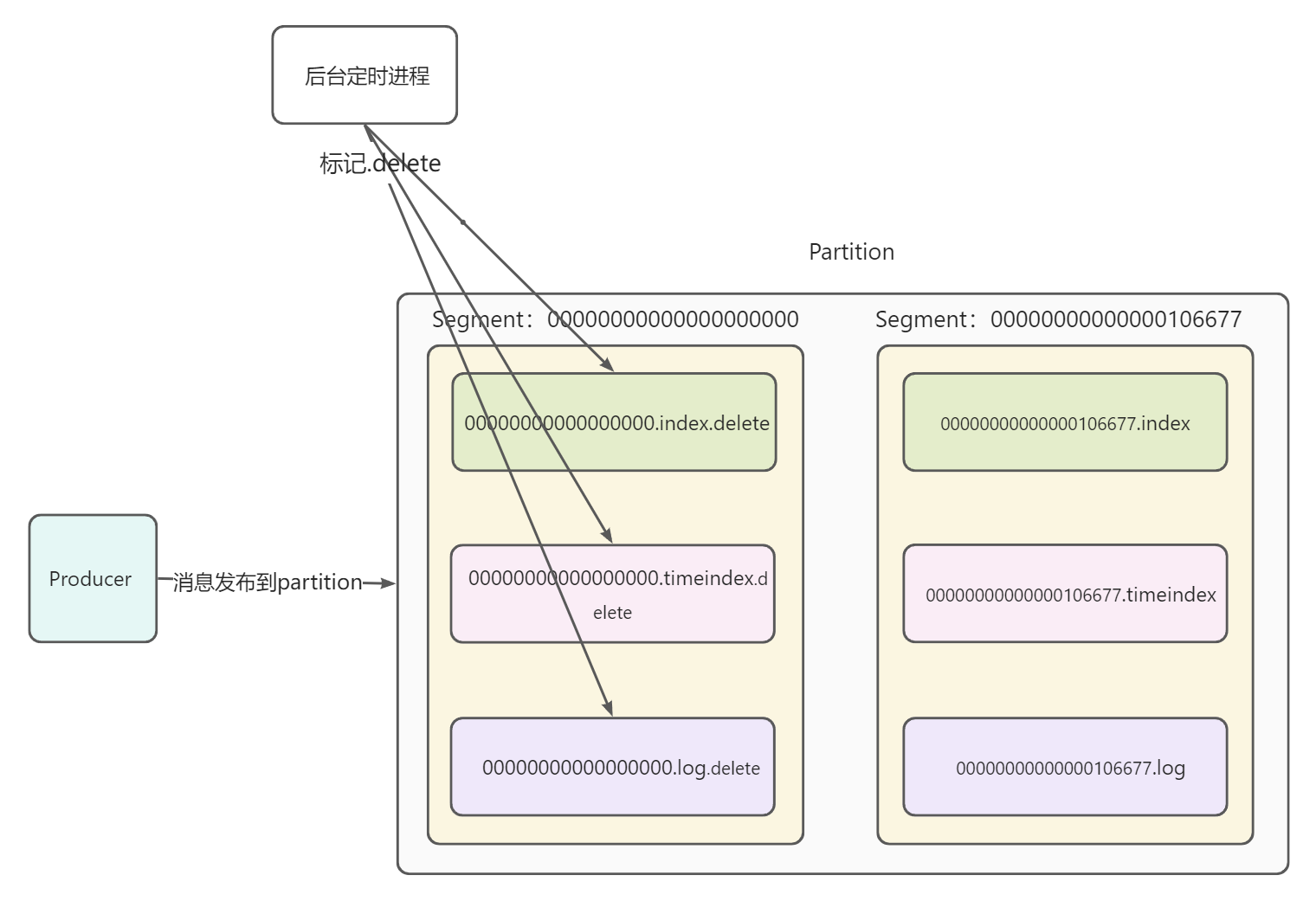
Kafka会定时扫描非Active状态的Segment,将该文件时间和设置的topic过期时间、以及当前服务器时间进行对比,如果发现过期就会将该Segment文件(具体包括一个log文件和两个index文件)打上.deleted 的标记
最后Kafka中会有专门的删除日志的定时任务过来扫描,发现.deleted文件就会将其从磁盘上删除,释放磁盘空间,至此Kafka过期消息删除完成。
相关配置
- log.segment.bytes:指定一个Segment的大小,默认为1G
log.index.interval.bytes:指定了在.log文件写入多少数据,就要在.index文件写一条索引,默认是4KB,即写4kb的数据然后在索引里写1条索引。
图示
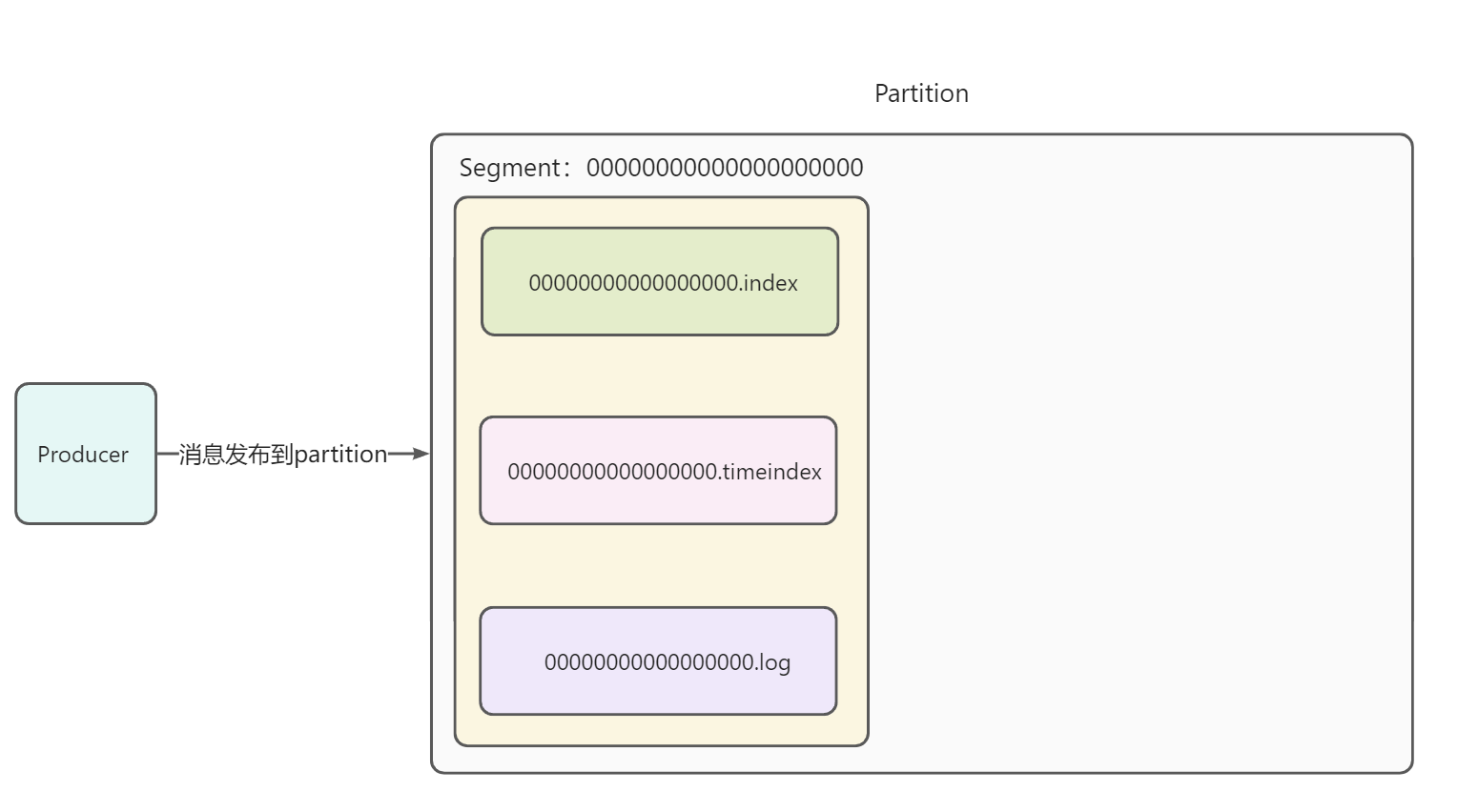
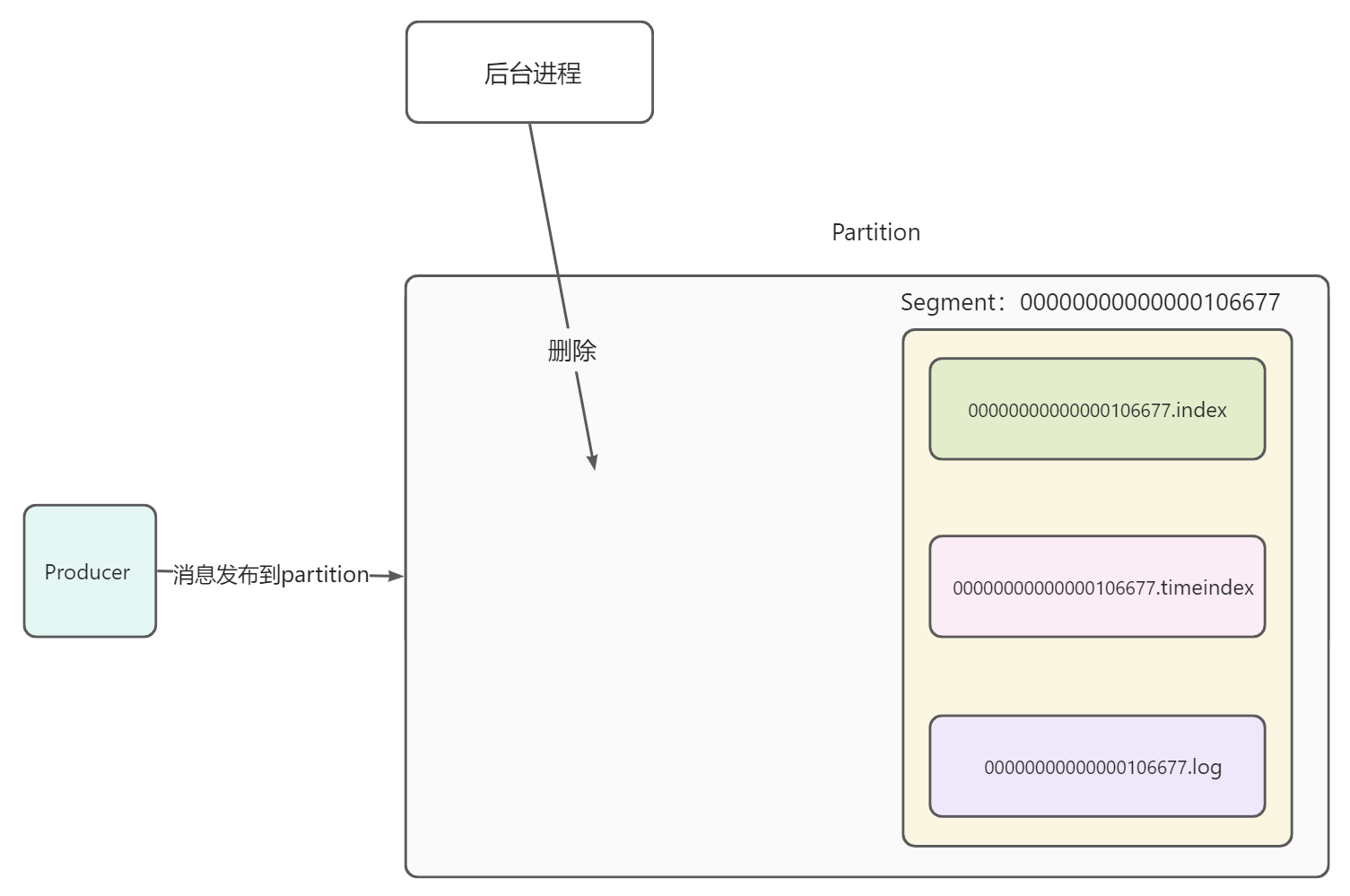
假设当前Producer正在向Topic的一个分区中发布消息。如下图,分区中生成了一个Segment,一个Segment中包含.index、.timeindex、.log三种文件,并且第一个Segment以0开始命名
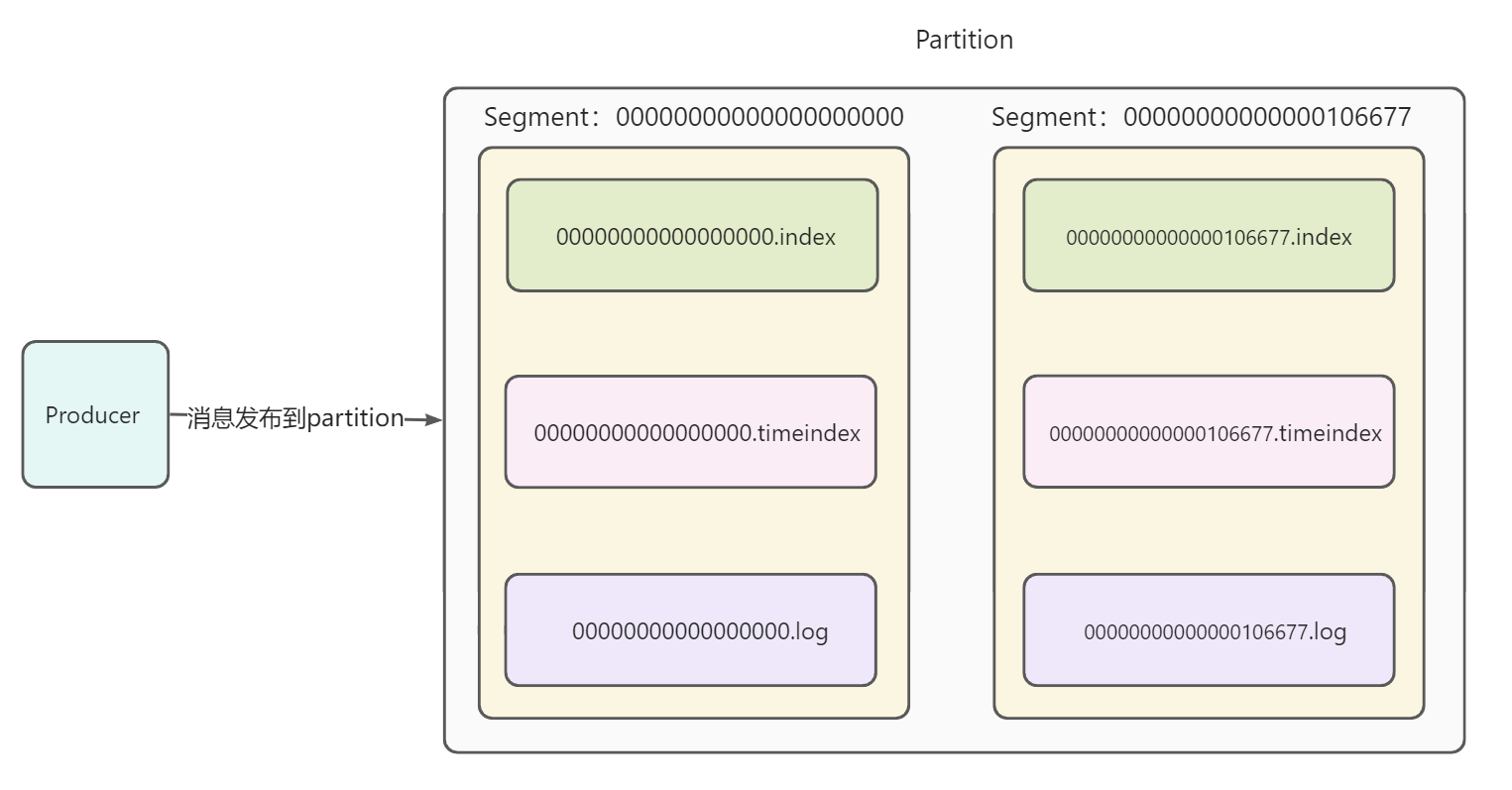
- 随着时间的推移,第一个Segment的大小已经达到阈值,并且第一个Segment的最大偏移量为106677。此时新建一个Segment,以106677开始命名
- 随着时间继续推移,第一个Segment被消费完。并被定时任务扫描发现是已过期的Segment,随后其内部文件被标记为.delete
- 时间继续推移,后台进程扫描被.delete标记的segment,找到了第一个segment,并将其删除,释放存储空间
2.消费
消费者组的分配原理
Kafka中,存在着消费者组的概念,多个消费者共同构成一个消费者组,消费一个Topic。并且遵循以下原理
- 不专门指定Partition的情况下,一个消费者组中的消费者,分别对应Topic中的一个到多个Partition。并且,同一个消费者组中的消费者,不能同时消费同一条消息
- 不同消费者组的消费者,可以同时消费同一条消息
- 有一种特殊情况,相同消费者组的两个消费者,都指定了同一个Partition消费,此时这两个消费者是可以同时消费同一条消息的
那么,消费者对于Partition的分配,遵循那些原理呢?接下来开始进行说明
RangeAssignor
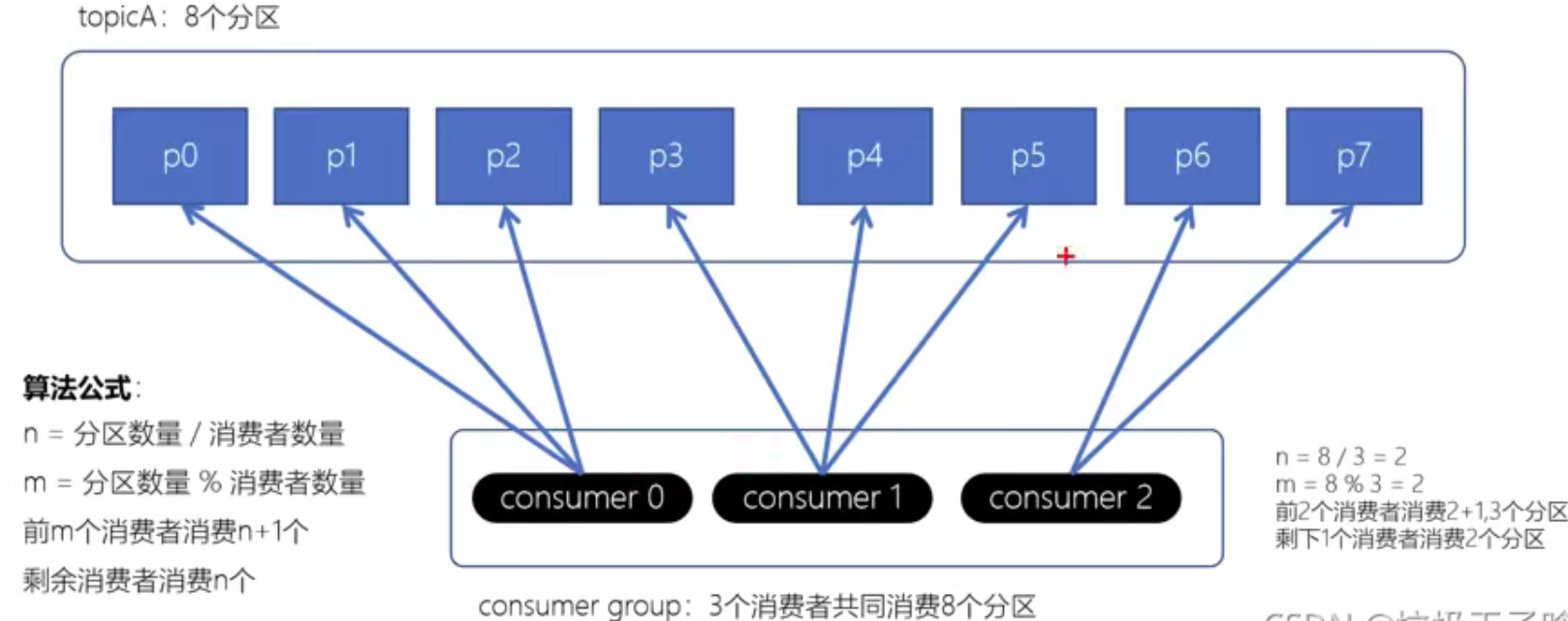
如图,RangeAssignor策略的原理是,对于每个Topic,按照消费者总数和分区总数进行整除运算来获得一个跨度,然后将分区按照跨度进行平均分配,以保证分区尽可能均匀地分配给所有的消费者。
RangeAssignor是以主题为基础进行分配的
消费者组只消费一个主题的话是可以均匀分布的,但如果消费多个主题,就容易造成分区间数据差距增大
RoundRobinAssignor
RoundRobinAssignor策略的原理是将消费组内所有消费者,以及消费者所订阅的所有topic的partition按照字典序排序,然后通过轮询方式逐个将分区以此分配给每个消费者。
RoundRobinAssignor策略是以消费者组为基础进行分配的
如果消费者组只是消费单个主题的话,效果和range分配策略消费单个主题效果是一样都能够做到均衡分布,或者说如果这个消费者组的消费者订阅的主题全都是一样的,那么也会均匀分布。
同理,如果是消费者组消费多个主题而且组中的消费者各个订阅的主题都不完全一样,就会出现消费不均匀的现象
StickyAssignor
StickyAssignor的消费遵循以下原理
- 分区的分配要尽可能的均匀
- 分区的分配尽可能的与上次分配的保持相同
- 当两者发生冲突时,第一个目标优先于第二个目标
鉴于这两个目标,StickyAssignor策略的具体实现要比RangeAssignor和RoundRobinAssignor这两种分配策略要复杂很多
消费者偏移量的提交机制
概念
Kafka与常规的消息队列不同,Kafka中的消息是持久化的,也就是说,消息不会随着被消费而删除。那么在Kafka中,如何确定每一个消费者的消费进度呢?
Kafka中采用了消费者偏移量机制,来记录消费者具体消费到了当前分区的第几个消息。在早期版本中,是通过Zookeeper来记录消费者偏移量。后来Kafka进行了优化,将消费者偏移量记录到了名称为_consumer_offsets的内置主题中
为什么需要消费者偏移量
因为Kafka中存在消费者组的概念,如果消费者组中,某个消费者突然宕机,此时Kafka的Rebalance机制会重新将分区分配给新的消费者
那么对于新的消费者,必然要知道宕机的消费者消费到了哪里,再以此为基础继续消费,不然就会出现重复消费的现象。消费者偏移量就是用来解决这个问题的
消费者偏移量记录了,一个消费者对于一个主题的一个分区的消费进度
提交机制
了解了消费者偏移量的相关知识后,接下来要了解一个知识点。消费者在什么时候?用什么方式?提交的消费者偏移量,不同的提交方式会带来什么样不同的问题?
自动提交
Kafka默认的消费者偏移量提交机制。可以通过auto.commit.interval.ms参数来设置自动提交频率,单位为ms,即多少ms提交一次消费者偏移量
自动提交会带来的问题
如果在消费者消费完成,并且在还未提交偏移量时发生宕机,那么此时就会出现重复消费现象,需要从自动提交频率、消费者幂等性处理两个角度考虑解决这个问题
手动同步提交
可以通过enable.auto.commit=false来将自动提交修改为手动提交。其中手动同步提交机制,可以保证偏移量一定会提交成功,如果提交失败,会不断重试,直到成功。并且在提交过程中,消费者进程一直阻塞,直到提交成功为止
手动同步提交会带来的问题
- 直到提交成功,消费者进程一直阻塞,会导致吞吐量下降
- 手动提交后,先提交后消费,可能会因为提交后消费者宕机,导致消息丢失
手动提交后,先消费后提交,可能会因为消费后消费者宕机,导致消息重复消费
手动异步提交
手动异步提交,采取异步提交的方式,吞吐量相较于同步提交会提高很多,但是可能会出现偏移量提交失败的情况
手动异步提交会带来的问题异步提交,不能保证偏移量一定成功,可能会导致重复消费现象
- 手动提交后,先提交后消费,可能会因为提交后消费者宕机,导致消息丢失
手动提交后,先消费后提交,可能会因为消费后消费者宕机,导致消息重复消费
3.图示
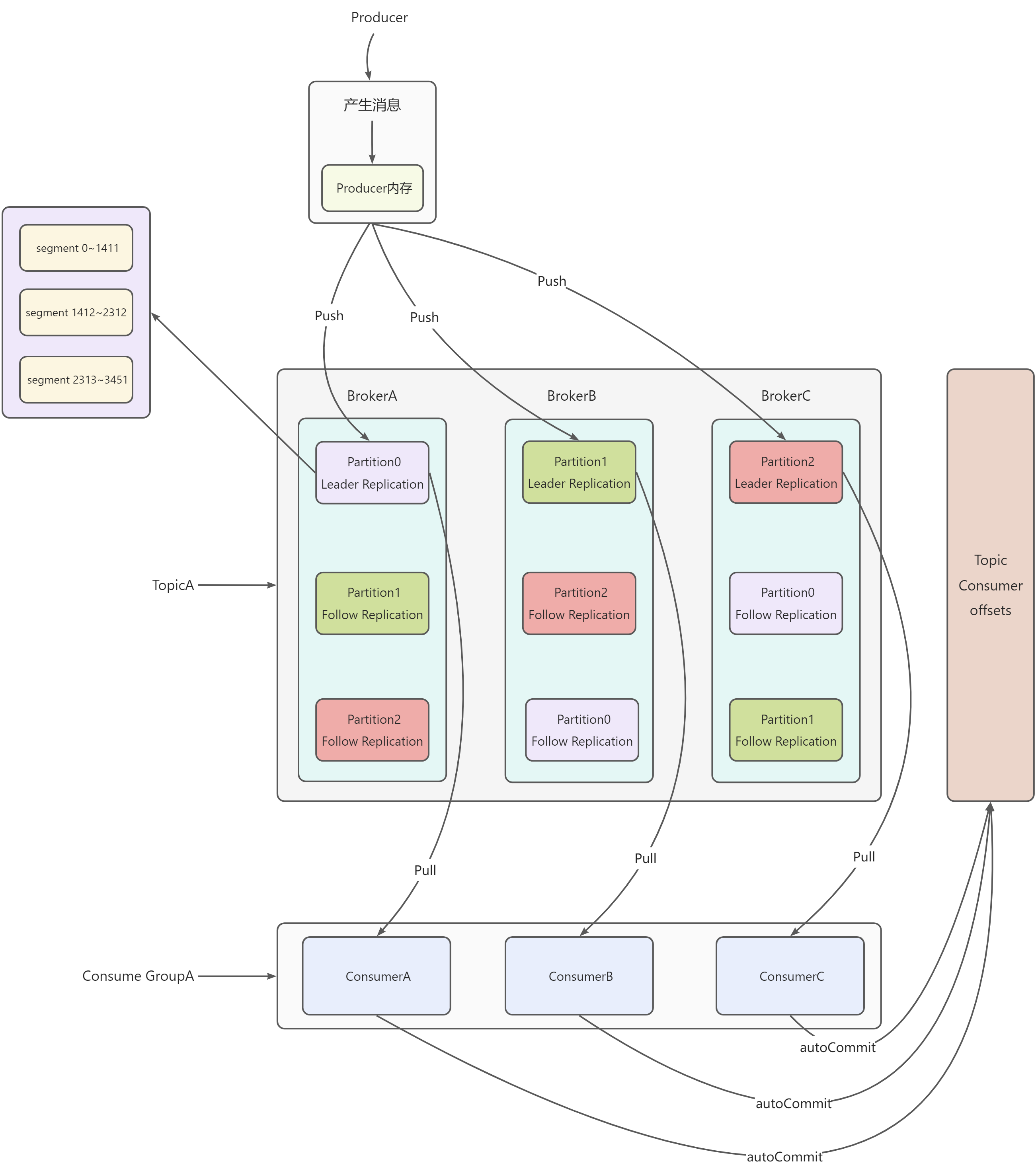
如图所示TopicA包括3个Partition,每个Partition包括3个副本,1个Leader副本,2个Follow副本,每个Partition副本内部都由n个Segment构成
- Leader副本负责与Producer、Consumer交互
- Consumer GroupA包括3个消费者,ConsumerA、ConsumerB、ConsumerC
- Producer生成消息,消息一开始被存储在了Producer内存中
- 在时间或内存达到设定阈值时,通过分区指定算法(指定分区 | Hash(消息key)%分区数 | 轮询),将消息批量Push到Topic的对应分区的Leader副本中
- 每个Leader副本对应的Follow副本会从Leader副本拉取最新的消息进度进行冗余备份
- Consumer GroupA中的每个Consumer都对应消费一个分区,每当分区有一批新的消息时,Consumer批量Pull消息进行消费
- 消费完成后,自动提交消费者偏移量到Consumer offsets内置主题

若有收获,就点个赞吧
0 人点赞
