1.项目地址
https://github.com/GuardFTC/Kafka-test.git
2.前言
在Springboot 多线程消费者内容中,我们了解到,当消费者端基于多线程处理消息时,出现了消息的乱序现象。实际上,为了实现Kafka消息的顺序消费,无论是Producer,Broker,Consumer都需要做出相应的处理
以下实现都是基于Kafka一些常见问题中的理论实现
3.Topic单分区方案
适用场景
Broker
从broker角度,为了实现消息的顺序性,必须要确保的就是一类有序消息存储到同一分区。因为Kafka可以确保一个Partition有序,但是整个Topic无法保证有序性
因此,我们创建Topic时,指定当前Topic只有一个Partition即可
创建Topic
如图,创建一个名为order-message-topic-v1的Topic,并指定分区数=1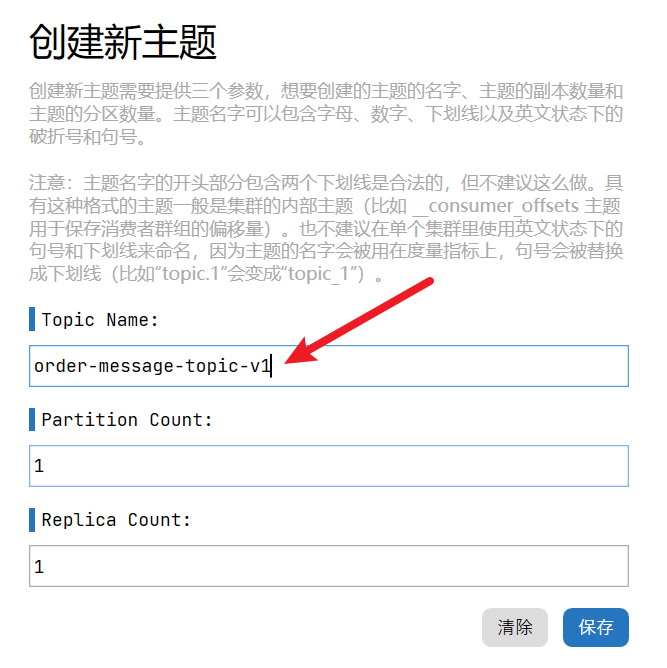
Producer
从Producer角度,需要确保的就是,避免因为异常重试机制,导致的消息重发乱序
因此Producer需开启幂等配置(enable.idempotence: true),yml配置如下
#服务器配置server:port: 8086#spring配置spring:kafka:bootstrap-servers: 120.48.107.224:9092producer:acks: -1key-serializer: org.apache.kafka.common.serialization.StringSerializervalue-serializer: org.apache.kafka.common.serialization.StringSerializerretries: 3properties:enable.idempotence: true
代码示例
如下,循环发送0~99共100条消息,并且发送时无需指定Partition或Key
期望是消费者顺序打印0~99
package com.ftc.ordermessage;import com.ftc.ordermessage.config.KafkaSendCallBackForString;import org.junit.jupiter.api.Test;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.boot.test.context.SpringBootTest;import org.springframework.kafka.core.KafkaTemplate;@SpringBootTestclass ProducerTests {@Autowiredprivate KafkaTemplate<String, String> kafkaTemplate;@Autowiredprivate KafkaSendCallBackForString kafkaSendCallBackForString;@Testvoid sendOrderMessageV1() {//1.循环发送消息for (int i = 0; i < 100; i++) {//2.发送消息kafkaTemplate.send("order-message-topic-v1", i + "").addCallback(kafkaSendCallBackForString);}}}
Consumer
从Consumer角度出发,避免因为多线程导致的,消息顺序拉取,但是消息没有被顺序执行。
而且因为是一类有序消息,所以也无需采用多线程的方案
消费者组里面的消费者数量可以为多个,也可以为一个,最终通过Rebalance机制,可以保证某个时刻只有一个消费者在消费当前消息
代码示例
import org.apache.kafka.clients.consumer.ConsumerRecord;import org.springframework.kafka.annotation.KafkaListener;import org.springframework.stereotype.Component;/*** @author: 冯铁城 [17615007230@163.com]* @date: 2022-09-13 10:01:26* @describe: 顺序消息消费者V1*/@Componentpublic class OrderMessageConsumerV1 {@KafkaListener(topics = {"order-message-topic-v1"}, groupId = "${spring.kafka.consumer.group-id}")public void listenerN1(ConsumerRecord<String, String> record) {System.out.println("receive message N1:" + record.value());}@KafkaListener(topics = {"order-message-topic-v1"}, groupId = "${spring.kafka.consumer.group-id}")public void listenerN2(ConsumerRecord<String, String> record) {System.out.println("receive message N2:" + record.value());}}
验证
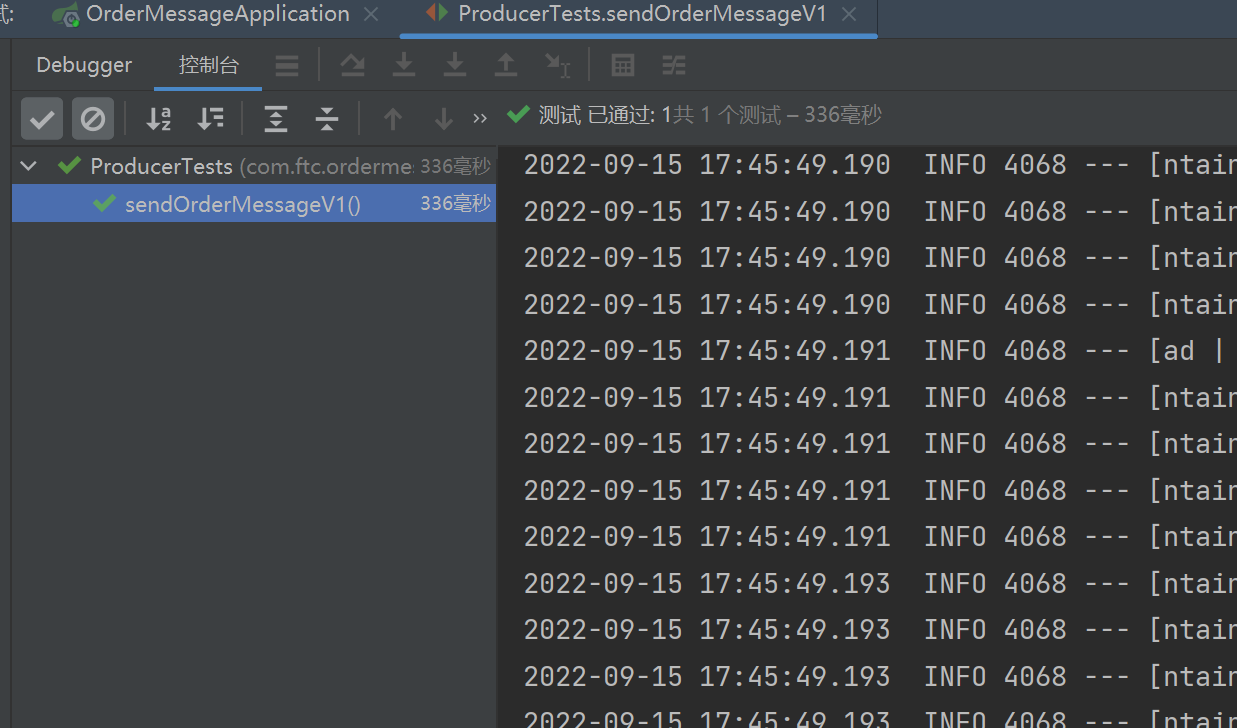
Producer
Consumer
如图,本次消息由ConsumerN1处理,因为是单线程处理,所以实现了消息的顺序消费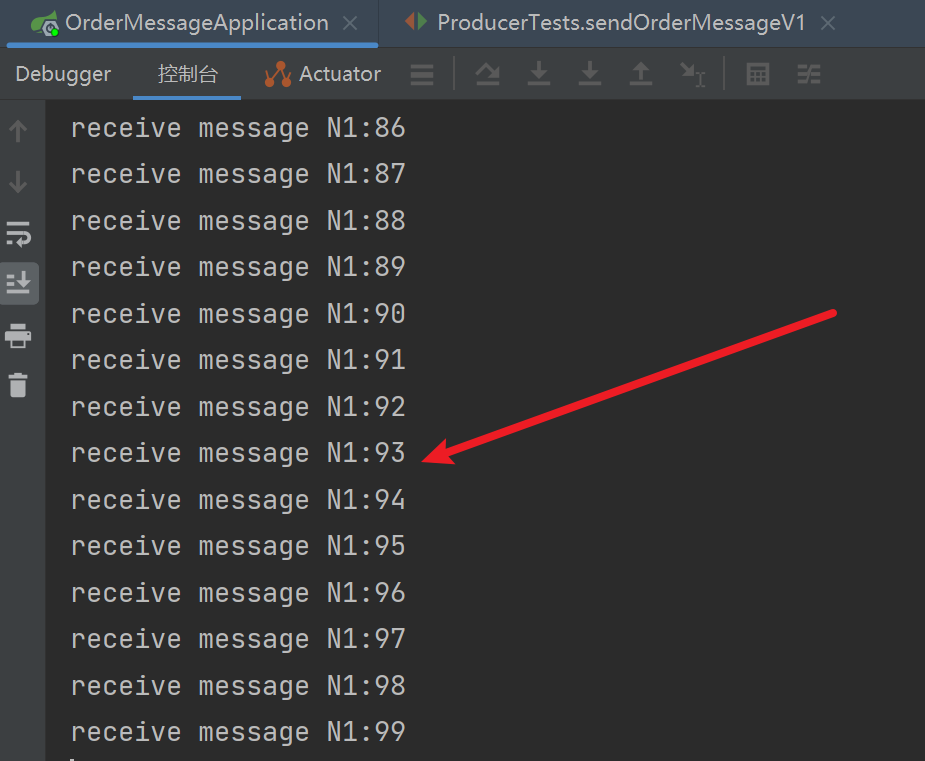
4.Topic多分区方案
适用场景
项目中有多类需要被有序处理的消息,为了避免多类消息拥堵在一个Partition中,采用多Partition方案
Broker
创建Topic
如下,创建一个名为order-message-topic-v2的Topic,并指定分区数=3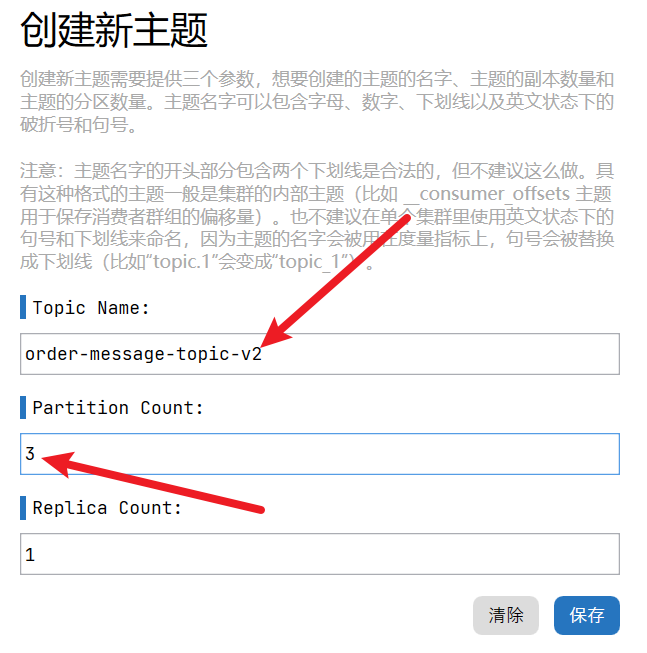
Producer
多分区时,除了开启Producer幂等,在发送消息时,还需要指定不同类型消息的Key,每种类型的消息对应一个Key,
Kafka会通过Hash(Key)%总分区数来确定该消息要被发布到哪个分区,因此,实际上最终一类有序消息还是会被持久化到一个Partition
代码示例
我们设置2类有序消息,
- 0~99的数字消息,key=Integer
- a~z的字母消息,key=CHARACTER ```java import com.ftc.ordermessage.config.KafkaSendCallBackForString; import org.junit.jupiter.api.Test; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.boot.test.context.SpringBootTest; import org.springframework.kafka.core.KafkaTemplate;
@SpringBootTest class ProducerTests {
@Autowiredprivate KafkaTemplate<String, String> kafkaTemplate;@Autowiredprivate KafkaSendCallBackForString kafkaSendCallBackForString;@Testvoid sendOrderMessageV2() {//1.发送数字类型消息for (int i = 0; i < 100; i++) {//2.发送消息kafkaTemplate.send("order-message-topic-v2", "Integer", i + "").addCallback(kafkaSendCallBackForString);}//3.发送字母类型消息for (int i = 0; i < 26; i++) {//4.发送消息kafkaTemplate.send("order-message-topic-v2", "CHARACTER", (char) (97 + i) + "").addCallback(kafkaSendCallBackForString);}}
}
<a name="dAy7Q"></a>### Consumer从Consumer角度出发,因为多类消息存储到了一个Topic中,所以Consumer需要用多线程来处理多类消息,并且每一类消息都由一个线程处理,再结合任务队列,即可实现顺序消费消息<a name="Wi74a"></a>#### 代码示例<a name="lzv7K"></a>##### 创建3个单例线程```javaimport org.springframework.context.annotation.Bean;import org.springframework.context.annotation.Configuration;import org.springframework.scheduling.annotation.EnableAsync;import org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor;import java.util.concurrent.Executor;import java.util.concurrent.ThreadPoolExecutor;/*** @author: 冯铁城 [17615007230@163.com]* @date: 2022-09-13 14:04:56* @describe: 线程池配置*/@Configuration@EnableAsyncpublic class ExecutorConfig {@Bean("kafkaListenerExecutor-1")public Executor singleExecutorNumber1() {return getSingleExecutor(1);}@Bean("kafkaListenerExecutor-2")public Executor singleExecutorNumber2() {return getSingleExecutor(2);}@Bean("kafkaListenerExecutor-3")public Executor singleExecutorNumber3() {return getSingleExecutor(3);}/*** 获取单例线程池** @param number 线程池序号* @return 单例线程池*/private Executor getSingleExecutor(int number) {//1.定义线程池ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();//2.定义核心线程数executor.setCorePoolSize(1);//3.最大线程数executor.setMaxPoolSize(1);//4.设置额外线程存活时间executor.setKeepAliveSeconds(60);//5.队列大小executor.setQueueCapacity(1024);//6.线程池中的线程名前缀executor.setThreadNamePrefix("kafka-listener-" + number + "-");//7.拒绝策略:异常抛出策略executor.setRejectedExecutionHandler(new ThreadPoolExecutor.AbortPolicy());//8.初始化线程池executor.initialize();//9.返回线程池return executor;}}
创建对应3个处理逻辑
import org.apache.kafka.clients.consumer.ConsumerRecord;import org.springframework.scheduling.annotation.Async;import org.springframework.stereotype.Component;/*** @author: 冯铁城 [17615007230@163.com]* @date: 2022-09-13 14:11:38* @describe: 多线程消费者逻辑处理类*/@Componentpublic class ListenerService {@Async("kafkaListenerExecutor-1")public void doSomeThingNumber1(ConsumerRecord<String, String> record) {doSomeThing(record);}@Async("kafkaListenerExecutor-2")public void doSomeThingNumber2(ConsumerRecord<String, String> record) {doSomeThing(record);}@Async("kafkaListenerExecutor-3")public void doSomeThingNumber3(ConsumerRecord<String, String> record) {doSomeThing(record);}/*** 处理业务逻辑** @param record 消息*/private void doSomeThing(ConsumerRecord<String, String> record) {System.out.println(Thread.currentThread().getName() + "线程消费者_监听获取数据:" + record.value());}}
Consumer通过取模法将一类消息交给一个线程
import com.ftc.ordermessage.service.ListenerService;import lombok.RequiredArgsConstructor;import org.apache.kafka.clients.consumer.ConsumerRecord;import org.springframework.kafka.annotation.KafkaListener;import org.springframework.stereotype.Component;/*** @author: 冯铁城 [17615007230@163.com]* @date: 2022-09-13 10:01:26* @describe: 顺序消息消费者V2*/@Component@RequiredArgsConstructorpublic class OrderMessageConsumerV2 {private final ListenerService listenerService;@KafkaListener(topics = {"order-message-topic-v2"}, groupId = "order-message-group-2")public void listenerN1(ConsumerRecord<String, String> record) {//1.打印消费者信息System.out.println("receive message N1");//2.消费消息consumerMessage(record);}@KafkaListener(topics = {"order-message-topic-v2"}, groupId = "order-message-group-2")public void listenerN2(ConsumerRecord<String, String> record) {//1.打印消费者信息System.out.println("receive message N2");//2.消费消息consumerMessage(record);}@KafkaListener(topics = {"order-message-topic-v2"}, groupId = "order-message-group-2")public void listenerN3(ConsumerRecord<String, String> record) {//1.打印消费者信息System.out.println("receive message N3");//2.消费消息consumerMessage(record);}/*** 消费消息** @param record 消息*/private void consumerMessage(ConsumerRecord<String, String> record) {//1.获取消息KeyString key = record.key();//2.hash(Key)与总线程数取模int number = key.hashCode() % 3;//3.分配消息if (0 == number) {listenerService.doSomeThingNumber1(record);} else if (1 == number) {listenerService.doSomeThingNumber2(record);} else {listenerService.doSomeThingNumber3(record);}}}
验证
Producer
Consumer
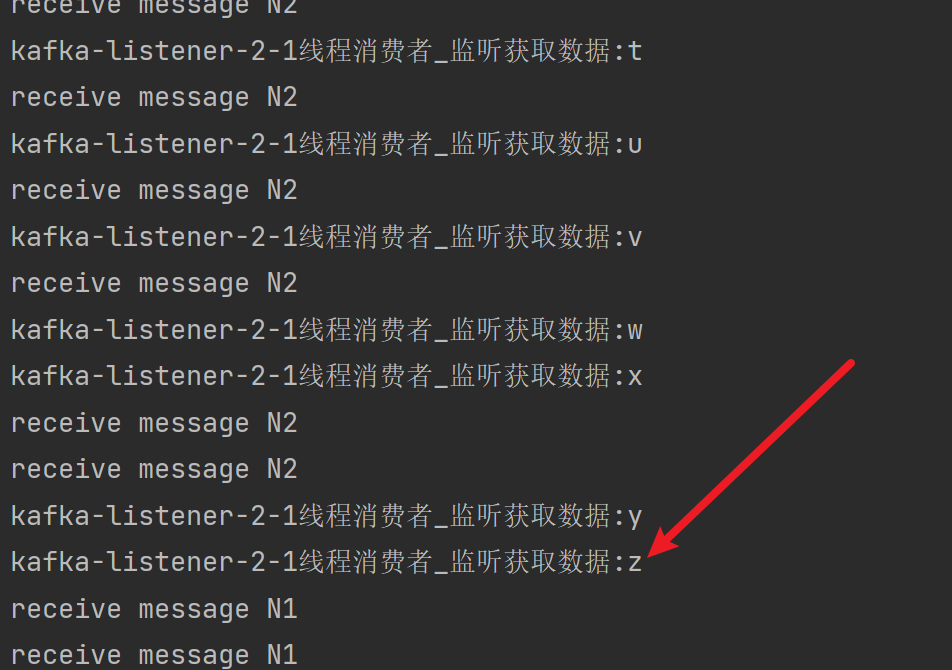
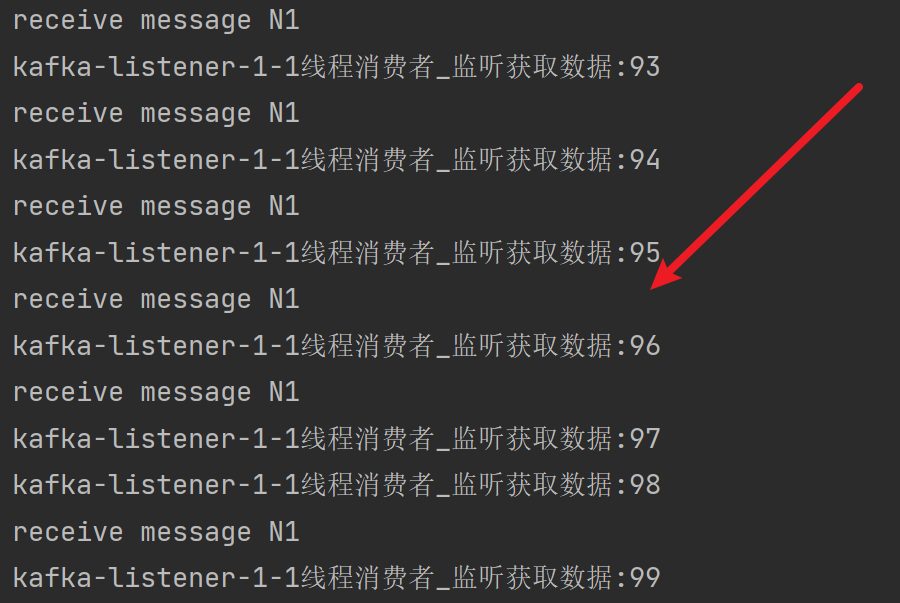
5.总结
综上所述,无论是多分区还是单分区,多线程还是单线程,Kafka确保消息顺序消费的根本原则就是:
- Producer开启幂等,并从业务逻辑上确保不会发送乱序的消息
- Broker确保一类有序消息全部持久化到一个分区
- Consumer确保一个线程处理一类有序消息

若有收获,就点个赞吧
0 人点赞
