第一天
excel格式
自定义格式:根据格式代码规则撰写格式规则
占位符:代替输入内容
常见占位符:
数字:0
文本:@
条件格式
图标集
数据条
色阶
数据透视表
汇总方式
按行/列汇总
按父行/父列汇总
按父级汇总
总计的百分比
百分比(按某一行)
区分有子类别时,,子类别可以父级总数作为分母,也可以以最高级的总额作为分母。
差异(以某一行为基准,其他行相对其差值)
差异百分比(以某一行为基准,其他行相对其差值的百分比)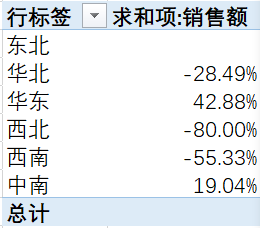
按某一字段汇总
按某一字段汇总的百分比
例子:按年汇总,计算年的累计销售额/累计销售额各项的百分比
第二天
第一天作业
作业1 求学生的3门成绩中,至少有一门成绩大于60分
法1:总人数—3门都不及格的人数
法2:新增一列求3门中最高分的一门(max函数),再统计这一列中小于60分的个数
作业4:
计算月份的季度
if的方法:
IF(B2<4,”第一季度”,IF(B2<7,”第二季度”,IF(B2<10,”第三季度”,”第四季度”)
子弹图
子母饼图
瀑布图
选择性粘贴
粘贴为“链接的图片”,图片显示的是区域的图像内容
累计型指标
累计求和:可以看业务完成进度
如库存
同比:YOY
环比:MOM
目标完成率=当期值/对比值(目标值)
差异=当期值-对比值
针对场景用户
6、用户分类:针对不同类别的用户推出相应措施/实施不同的运营策略
老用户:生日优惠券、新活动/商品通知
(挽留住,刺激消费,提高客单价)
7、引流:不断增加新用户
用户基数足够大的时候,成为了流量
1、卖广告位
2、流量互换
用户生命周期
注册:注册用户和非注册用户(用户id区分)
注册用户数量:对用户id去重计数
非注册用户数量:对订单编号去重计数
流量相关指标
计费方式:
CPM、CPS、CPC
访客数UV(非重复客户数)、浏览量PV(浏览页面总次数)、访问次数Visit(统计会话内,一个会话内用户连续访问多个页面)
平均访问深度:浏览量/访问次数
漏斗图
第三天
作业
计算累加:按某一字段汇总
求环比:差异百分比 按记录日期 上一个
求同比:————————按年 上一个
指标应用
动销率= 有销售行为发生的商品数量 / 总的商品数量
(订单表/销售表里面的商品ID去重计数)(商品信息表里的商品计数)
每个商品的动销率= 每个商品销售的次数/总的销售次数
(每个商品对订单表/销售表的订单ID去重计数)/(对订单表/销售表的订单ID去重计数)
客户的总动销率=有销售行为的客户数量/总客户数量
(销售表的客户ID去重计数)/(客户信息表的客户ID计数)
每个客户的动销率=每个客户的销售次数(销售表对订单ID去重计数)/销售表对订单ID去重计数
统计复购会员数,要计算每个会员的购买次数,先对cus_id和bask_id同时进行去重。(同一单可能会购买不同的物品)
YTD(最近的一年)
YTD带薪病假一般是五天
使用的函数
NETWORKDAYS(date,date):计算两个日期间的法定工作日的天数,
第四天
分析法:帕累托分析、波士顿四象限分析法、树状结构分析法
又称为二八法则,即百分之八十的问题是百分之二十的原因造成的,主要用于找出核心,抓重点。
主要特点:
1、柱形图的数据按数值的降序排列,折线图上的数据有累积百分比数据,并在次坐标轴显示;
2、折线图的起点数值为0%,并且位于柱形图第一个柱子的最左下角;
3、折线图的第二个点位于柱形图第一个柱子的最右上角 ; 4、折线图最后一个点数值为100%,位于整张图形的最右上角
制作步骤
1、制作数据透视表,确定纵轴的指标,在透视表中按横轴的字段进行汇总百分比
2、按纵轴指标降序排列,汇总百分比最小值取0
第五天
制作交互图表看板要点
品类:
品类的销售额、销售利润:用对比类图表
商品的销售额、销售利润、销量:用表格
受季节影响的商品看同比
一般类商品(不受季节影响)看环比
时间维度上的对比
折线图、对比条形图
对于销量、销售额突出的品类,可以再往下以月度的销售额和月份的销售利润
(配合切片器使用)

同期群分析
按照初始行为发生时间划分的群体
作用:衡量指定对象组在某一段时期内的持续性行为差异
同期群:相同业务背景下,受到相同环境影响的用户群
例:某校某专业2016级应届毕业生&某校某专业2017级应届毕业生
某平台2月1日新注册用户&某平台2月2日新注册用户
同期群分析:量化行为指标,分析不同群体的该指标随时间的变化情况
RFM分析模型
帮助企业判断哪些用户有异动,是否有流失的预兆,从而增加相应的运营措施
维度选择
Recency :最近一次消费,基于当前时点,统计用户最近一次消费时点和当前时点的时间差。(距离上次消费时间越短越好)
Frequency :消费频次,指定时间区间内统计用户的购买次数。(越多越好)
Money:消费金额,指定时间区间内统计用户的消费总金额。(越多越好)
维度下分类
实现步骤
1、获取RFM三个维度的原始数据
2、定义RFM的评估模型与判断阈值
3、数据处理,获取RFM的值
4、参照评估模型与判断阈值,对用户进行分层
5、针对不同层级用户制定运营策略
第六天
价值模型
用户价值分层
选择维度如消费额、消费次数、对用户分层,得到不同的用户类型
25%分位和75%分位
QUARTILE()
超市业务模型
1、客户id
2、订单id
3、产品id
4、产品类目
5、品牌id
6、订单金额
7、数量
8、时间
——————————
高品质用户判断模型实践:
不同品质要求
高净值(订单金额高
表1:商品类目价格表(品牌、价格)
对商品进行分类(高价格商品、低价格商品)
表2
客户订单 商品最高金额
维度
商品:品质关联商品价格、商品品牌
客户:消费次数、订单平均金额、购买的商品均价
时间段:一年内/半年内/季度/月
商品单价 (四分法)25% 75%
消费商品均价
—————————
计算留存率
同类群分析法
分类用户是哪个月新增的(一月、二月、三月……)
以及计算他们这些群体后续每个月的金额/数据
商业报告撰写注意点

报告撰写
报告的数据源:一份静态的表格数据
分析内容:业务点(什么问题、什么原因导致的,选一个点描述)
报告的载体:word/ppt
报告的阅读者:关注点
报告的框架:总分总、总分、分总、业务流程(结合业务维度,
第七天
业务:事;范围小、主营业务(能做的业务);时效性;特殊性
财务:钱;范围大;滞后性;标准统一
财务三表通用分析方法
结构分析:看占比、构成的分析、占比大小代表这个部分对于集体的影响程度如何,找到权重大的对象重点分析,大类别下科目
图表:饼图、环形图、堆积图、旭日图、瀑布图
趋势分析:单一指标在不同时段下的趋势变化情况
比较分析:行业间不同企业的指标对比、单一指标不同时间下的对比、多指标间的业务逻辑对比
第八天
业务理解 – 数据分析 – 报表 – 报告 – 决策 – 行为
数据敏感性: 结果 – 原因 – 影响 – 措施
第九天
开源信息集
https://data.stats.gov.cn/
http://www.tjcn.org/
数据类型、数据分类
分类型数据:众数
(不惟一性)
无众数
一个众数
多于一个众数
(区别于频数)
数据型数据:中位数(四分位的特殊情况)、平均数
ARIMA 商业
LSTM人工智能
支持向量机
实现二分类
就能实现多分类
人脸识别(14亿分类)
线性分类
非线性分类
四分位数

特殊情况处理
重复值
缺失值
异常值
编码值
平均数
平方
算术:简单平均数(样本平均数、总体平均数)、加权平均数
加权平均数
组中值乘以权重(频数除以频数合计值)
几何平均数
众数、中位数、平均数的关系
左偏分布
对称分布
右偏分布
离散程度的度量
度量数据的离散程度/波动性
业务中度量的是风险(波动性有多大)
波动性越大,风险越大
分类数据:异众比率
不是众数的那些数的比率
顺序数据:四分位差
上四分位数与下四分位数之差
衡量中位数的代表性(范围越大越弱)
数值型数据:方差和标准差
极差(max-min,范围/值域)
平均差(离差)
样本与中心点(均值)的平均距离有多长
方差 计算的就是这个距离的平方
开根号得到标准差
自由度:一组数据中可以自由取值的个数
有1000人,先告诉平均值、再告诉999人的身高,那么剩下的那个人的身高也确定了。
数据标准化处理:
1、0-1标准化 min max标准化(Xi-min)/(max-min)
其他区间(a,b):(Xi-min)/(max-min)(b-a)+ a
2、Z-score标准化
标准分数(标准化值):数据点到均值的差值是标准差的多少倍 Zi= (Xi — X(均值))/ S(标准差)
3、单位化(把数据空间中的所有数据点都映射到一个标准球上,向量长度都变为一)

不是对称分布时:切比雪夫不等式
需要对比离散程度:离散系数
公式:Vs=S/X(平均)
偏态

峰态

矩阵运算
ctrl+shift+enter(区域性的计算)
例子:
transpose转置: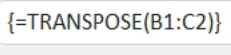
A^(-1)也可以实现转置
矩阵相乘
第十天
置信区间计算
临界值计算:
norm.inv()
第十一天
关系型表结构数据
以字段或记录作为数据的引用、操作及计算的基本单位的数据
字段:整列数
记录:整行信息
维度:业务角度
度量:业务行为结果(一般是数值字段,方便求和)
特征:
以字段或记录作为数据的引用、操作及计算的基本单位的数据
第一行为标题行、第二行以后称为记录 、字段名不能重名、一个字段只能有一种数据类型
所有字段记录行数相同
主键
物理意义:
一张表中有且只有一个主键
单字段主键
多字段联合主键
非空不重复
定位记录行、字段名+主键值定位具体数值
多以“xxID”、“xxNo”、“xx编号”等名称命名
业务意义:
表的业务记录单位,在一个数据表中的所有非主键字段都要围绕主键展开
事实表和维度表
维度表:只包含维度信息的表(没有描述发生的行为)
事实表:既包含维度信息又包含度量信息的表
E-R图
将不同表中的字段信息合并到同一个表中使用,多表连接的鸟瞰图
三种连接模式
星型模式:一个事实表和多个维度表相连
雪花模式:维度表与维度表相连,进行维度的拓展
星座模式:多个事实表共用某些维度表
表与表连接:
方向性:左连接(以左边的表作为公共字段)、右连接(以右边的表作为公共字段)、内连接(不存在主附关系,两边都有的项才会匹配上)
(如果匹配到有多行值会匹拓展成多行)
主附性:左连接以左表为主表,右连接以右表为主表,内连接不存在主附关系
对应关系
一表、多表
1对多
1表出维度多表出度量 对
多表出维度1表出度量 错
跨表分析总结:
1. 两表连接用公共字段下不重复项一致时不考虑方向性,都可以
2. 分析时要保证某个字段的完整性,就以包含该字段下最完整取值的表为主表
3. 方向性决定主附关系,左连接左表为主表,右连接右表为主表,内连接没有主附关系
4. 1对1可以统计正确结果,多对多尽量避免使用,多对多结果会出现数据翻倍
5. 1对多(多对1),1表出维度,多表出度量可以统计出正确的结果
ETL功能
将数据从数据源端经过抽取(extract)、清洗转换(transform)之后加载到数据仓库
E—抽取:创建于不同数据源间的连接关系,对这些数据源中的数据进行“引用”
T—清洗转换:
(1)清洗的主要任务是筛选过滤不完整、错误及重复的记录
(2)对“粒度”不一致的数据进行转换
(3)对业务规则不一致的数据进行转换
L—加载:将抽取出来的数据经过清洗与转换后加载到数据仓库中进行存储与使用
OLAP技术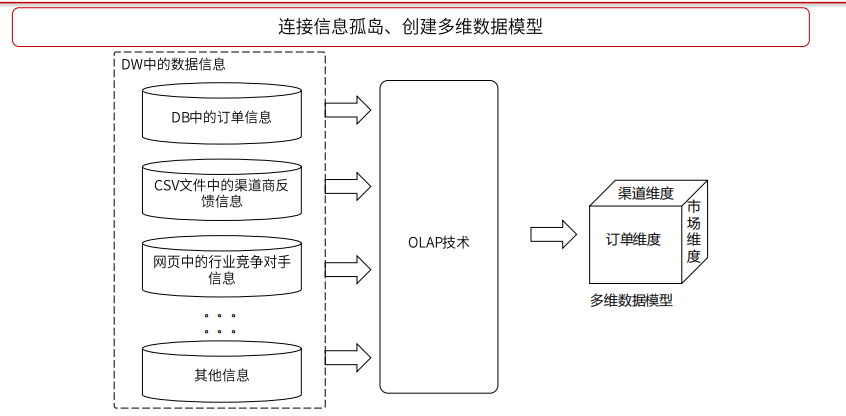
Power Query

横向合并
将不同表中的字段信息合并到同一个表中使用
通过公共字段匹配:拥有相同记录值得字段
左表与右表:连接命令左侧得表为左表,右侧的表为右表
连接方向:决定表的主附关系,主要使用“左连接”\“右连接”\“内连接”
对应关系:决定连接结果行数是对应项乘积的结果
纵向合并
多表中记录信息合并到同一个表中进行使用
字段个数相同
相同位置字段的数据类型相同
去重合并与全合并
筛选:维度汇总度量的能力
分组依据:维度
指标/聚合:度量、汇总规则
非关系型表结构


第十二天
Power Query 表达式Let
“let” 表达式封装一组要计算、分配名称的值,然后在“in”语句后面的后续表达式中使用
例子:
let
Source = Text.Proper(“hello world)
in
Source
Text.Proper(“hello world)计算为“Hello World”
结构化数据—列表
列表:列表就是数组,列表没有字段名,用序号来识别不同元素
结构化数据—记录
记录用来定义字段和给字段赋值,一个字段由字段名以及字段内的值组成,字段名是唯一的文本值,是字段的标识符。字段名可以不用引号引用,字段名有两种表达形式:
>不加” “的表达形式、例如OrderID
>加#和””的表达形式、例如#Today’s data is:”
记录中的内容写在[ ]括号内,[ ]括号同样用于在记录中取特定字段的值。
例子:
表(table)
由行列数据构成的,结合了记录与列表的优点,有字段又有多行记录。
隐式字段表:
第一行:字段名,第二个{}里的是表的内容
显式字段表
字段名用type table=[],包含数据类型
数据结构嵌套
例1:复合数据结构的列表
要提取”Fishing rod”,在source后加:{3}[Item],source的列表里有4项,”Fishing rod”在第4项的[Item]里
例2:包含子列表的记录
要提取”Fishing rod”,在source后加:[Orders]{0}[Item], Orders是source的子列表。
列表用{}创建,获取里面的值在列表后面加{}
记录用[]创建,获取字段取值在记录后面加[],里面输入对应的字段名称
表用()创建,获取某一行记录在表后加{},里面输入行号(从0开始)
M函数查询
高级编辑器中输入 #shared
是由结构名和功能性名组合在一起的
Record.ToTable()函数 将record转为表格(表结构)
身份证号码例子
身份证号码数导入后数据类型是int64
无法直接通过获取指定位数的数字来获取出生日期和性别。所以先将数据类型转换为文本。
例子:爬取空气质量数据信息
city 作为text 参数传输
信息开放平台:
高德开放平台:lbs.amap.com
运用它的【web服务API】-【地理/逆地理编码】获取具体地址的经度和纬度
第十三天
多维数据模型
又叫多维数据集、立方体,指的是相互间通过某种联系被关联在一起的不同类别的数据集合。

赋予了维度去汇总度量的能力。
双箭头代表的是两个方向都可以筛选。
影响连接汇总的三要素
筛选器方向:分为单向及双向两种、筛选器方向决定维度和度量的出处。
对应关系:一对一、多对一、多对多,决定连接汇总的结果
一对一:主键与主键相连、两表具有相同主键,这种情况几乎不会出现,如果出现物理层面的一对一连接,应结合字段属性确认。
多对多:非主键连接非主键,虽然会出现这种连接情况,但是会造成度量值在求和、计数等常用汇总规则下翻倍,应尽量避免使用多对多的连接关系。
多对一(单向):相邻两表连接时应尽量使用多对一的关系,单向筛选方向时,一表筛选多表。
多对一(双向):相邻两表连接时应尽量使用多对一的关系,双向筛选方向时,多表可以筛选一表,但是筛选方式不同于一表筛选多表的筛选方式。
汇总角色:维度、度量。
相邻两表链接规则说明
T1:
1表内
2一对一,只要可筛选
3一对多,可筛选,无论单双向,1表出维度,多表出度量
T2:
1跨表筛选
2一对多,双向连接,1表出度量,多表出维度
在T2跨表的情况下,值的结果为多表下一表的不同情况的汇总值时,多表连接的一表,一表作为连接桥梁,对另外一个多表进行汇总时,容易出现重复的情况。
子父级关系
维度与公共字段是子父级关系,T2类型可以汇总出正确结果。
DAX表达式
是power pivot 特有的函数集
应用在复杂的汇总规则的编写
新建列、新建度量值
度量值
all函数:忽略某个维度的筛选能力
去重计数:distinctcount函数
时间智能函数
日期辅助表
调用List.Dates函数,输入起始日期、天数、步长。
计算同比、环比时,建立与日期辅助表的关联 。
previousmonth函数
时间点:获取指定时间点对应上月完整月的数据值统计。
时间段:不受后点影响,以时间前点为基准,获取上月完整月的数值统计。
DATEADD函数 DATEADD(
, , )
number_of_intervals 一个整数,指定要添加到 dates 或从 dates 中减去的时间间隔数。 interval 日期偏移的间隔。 interval 的值可以是以下值之一:year、quarter、month、day 返回值 包含单列日期值的表。 备注 dates 参数可以是以下任一项 : ● 对日期/时间列的引用, ● 返回单列日期/时间值的表表达式, ● 定义日期/时间值的单列表的布尔表达式。备注有关对布尔表达式的约束,可查看 CALCULATE 函数主题。 ● 如果为 number_of_intervals 指定了正数,则 dates 中的日期向未来推移;如果指定的数字为负数,则 dates 中的日期向过去推移 。 ● interval 参数是一个枚举,而不是一组字符串;因此不应将值括在引号中 。 此外,在使用值 year、quarter、month 和 day 时应将它们拼写完整。 ● 结果表只包括 dates 列中存在的日期 。 ● 如果当前上下文中的日期未形成连续间隔,函数则会返回错误。 ● 在已计算的列或行级安全性 (RLS) 规则中使用时,不支持在 DirectQuery 模式下使用此函数。 https://docs.microsoft.com/zh-cn/dax/dateadd-function-dax
totalmtd函数
时间点:以指定时间点为基准获取月初至当前日期为值得数值内容。
时间段:以后点为基准,获取后点对应月初至当前日期为止的数值统计。
第十四天
零售案例可视化报表
业务理解
业务背景:根据销售数据指定可读性更高销售看板
业务行为:销售行为
明确数据表
数据收集(本例子中是零售订单数据表
数据处理(标准化
数据分析
指标:销售额、销量、平均单内产品数量、平均订单金额、订单量
维度:年、月、产品类别、城市、国家、产品名称、产品子类别
报表框架:总-分、业务流程(起点-终点)
总:所有年总销售额、所有年总销量、所有年总订单量、平均单内产品数、平均订单金额
各年各月上述指标(同比、环比)
对应年、月指标展现
对应年、月指产品类别、产品子类别标展现 对应年对应月国家、城市指标展现
产品名称上述指标表现 
5W2H方法论
What:做什么?
Why:为什么做?
Who:做给谁?谁做?
When:何时做?什么时机最适宜?
Where:何处?在哪做?
How Much:制作成本是多少?
How to do:怎么做?
针对业务理解
What:分析的是什么?
Why:为什么需要做?
Who:交给谁查阅?
When:时间范围怎么选择?(根据业务特征、数据时效性及可获取性确定数据的时间范围
Where:在哪里使用?(决定数据表现:报表/报告(PDF/PPT)
How Much:制作成本是多少?(确定时间成本、人力成本)
How to do:如何用数据阐述业务问题?(明确业务背景&明确业务行为&明确数据表)
流量案例可视化报表

求环比访客数实操
1、建立空查询,找到 list.dates 函数,确定选取的数据的时间跨度(天数),起始日期。
2、用List.Dates函数生成 时间辅助列,并点击左上角“转到表中”。(后续可以调用 ‘查询1’[column1])
3、新建度量值:环比月访客人数 = CALCULATE(SUM('XX电脑自营旗舰店'[访客数(UV)]),DATEADD('查询1'[Column1],-1,month)),使用DATEADD函数获取,时间辅助表中日期的前一个月对应日期的访客人数,并求和。
第十五天
客户价值案例
连带数:订单内销售的商品种数 或 订单内销量(总销量/订单数)
客单价:客单价(per customer transaction)是指商场(超市)每一个顾客平均购买商品的金额,也即是平均交易金额 (平均每一单的金额)
客单价的计算公式是:
客单价=总金额/总订单数 或 客单价=人均消费/人均订单数
BI中形状地图可在设置中勾选
形状地图下格式刷中可选地图形状,暂无中国的地图,需要通过添加地图文件来处理。
geojson地址:
http://datav.aliyun.com/tools/atlas/
(下载中国地图的JSON文件)
转换为topjson地址:
https://mapshaper.org/
餐饮案例
案例内容:某连锁餐饮店管理者希望将日常餐数据转化为可读性高的数据报表,主要描述各门店一日内的经营情况。

若有收获,就点个赞吧
0 人点赞
