增删选查
- 查看数据库:show databases;
- 创建数据库:create database 数据库名称;
数据库名称不能与SQL关键字相同,也不能重复 命名规则:字符(中文/英文)、数字(不能出现在首位)和_(不能单独使用),不需要加引号
- 选择使用数据库:use 数据库名称;
- 删除数据库:drop database 数据库名称
常用约束条件
主键约束(Primary key)
- 每个表只能有一个主键
- 主键值须非空不重复
- 可设置单字段主键,也可设置多字段联合主键(联合主键中多个字段的取值完全相同时,才违反主键约束)
- 添加主键约束:
create table
唯一约束(unqiue)
- 指定字段的取值不能重复,可以为空,但只能出现一个空值(不能有相同的值)
- 添加唯一约束:
create table <表名> (<字段名1><字段类型1>unique,……<字段名n><字段类型n>);
create table <表名>(<字段名1><字段类型1,……<字段名n><字段类型n>,
[constraint 唯一约束名] unique (字段名1[,字段名2…字段名n]));
自动增长列(auto_increment)
- 指定字段的取值自动生成,默认从1开始,每增加一条记录,该字段的取值会加1
- 只适用于整数型,配合主键一起使用
- 创建自动增长约束:
create table <表名>(<字段名1><字段类型1> primary key auto_increment,…<字段名n><字段类型n>);
非空约束(not null)
- 字段的值不能为空
- 创建非空约束:
create table <表名>(<字段名1><字段类型1> not null,…<字段名n><字段类型n>);
默认约束(default)
- 如果新插入一条记录时没有为该字段赋值,系统会自动为这个字段赋值为默认约束设定的值
- 创建默认约束:
create table <表名>(<字段名1><字段类型1> default value,…<字段名n><字段类型n>);
外键约束(foreign key)
在一张表中执行数据插入、更新、删除等操作时,DBMS都会跟另一张表进行对照。
- 某一表中某字段的值依赖于另一表中某字段的值
- 创建外键约束:
create table <表名>(<字段名1><字段类型1,……<字段名n><字段类型n>,
[constraint 外键约束名] foreign key (字段名) references<主表>(字段));
(例如:有学生表和成绩表两张表,在输入成绩的时候,先对照成绩表,确定是否有这个学生)
学生表:
成绩表: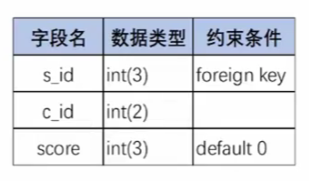
— 创建带有约束条件的表
学生表:create table student(s_id int primary key auto_increment,s_name varchar(10) unique,s_birth date not null,s_sex varchar(10) default '未知');
成绩表:create table sc(
s_id int,
c_id int,
score int,
foreign key(s_id) references student(s_id)
);
show tables;
desc student;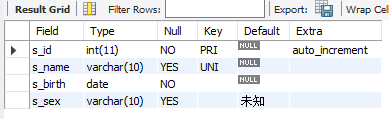

数据定义语言
修改数据表
- 修改表名:alter table 原表名 rename 新表名;
alter table student rename stu;
- 修改字段名:alter table 表名 change 原字段名 新字段名 数据类型 [自增/非空/默认] [字段位置];(数据类型改不改都要写上,约束条件不写的话就没有了)
alter table stu change s_sex s_gender varchar(10) default"未知";desc stu;
(s_sex 变为了 s_gender)
- 修改字段类型:alter table 表名 modify 字段名 新数据类型 [自增/非空/默认] [字段位置];(可选是否修改[自增/非空/默认] 这三种限制,但是唯一约束(unqiue)这里不改变,原来有的话仍是存在。
alter table stu modify s_name varchar(5) ;desc stu;
s_name的数据类型由 varchar(10) 变为 varchar(5)
修改字段的排列位置:
alter table 表名 modify 字段名 数据类型 [自增/非空/默认] first;
(数据类型的限制 [自增/非空/默认]不填的话,默认无限制)alter table stu modify s_birth date first;desc stu;
alter table 表名 modify 要排序的字段名 数据类型 [自增/非空/默认] after 参照字段;
alter table stu modify s_birth date not null after s_gender;desc stu;
(s_birth 数据是日期类型,在s_gender后面一行,且非空)添加字段:alter table 表名 add 新字段名 数据类型 [自增/非空/默认] [字段位置];(不指定添加到哪一列是,默认添加到最后一列)
alter table stu add address varchar(100);desc stu;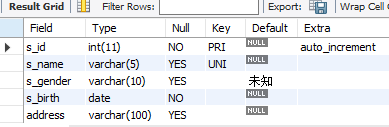
- 删除字段:alter table 表名 drop 字段名 ;
alter table stu drop address;
数据操作语言
添加数据
字段名与字段值得个数、顺序和数据类型必须一一对应(有空值也要把空值标出)
- 指定字段名插入: insert into 表名(字段名1[,字段名2,…]) values(字段值 1[,字段值 2,…]);
insert into stu(s_name,s_id,s_birth,s_gender) values('赵雷' , 1 , '1990-01-01','男');desc stu;
- 不指定字段名插入:需要为表中每一个字段指定值,且值的顺序须和数据表中字段顺序相同 insert into 表名 values(字段值 1[,字段值 2,…])
alter table stu modify s_gender varchar(10) default"未知" after s_birth;insert into stu values(5 , '周梅' , '1991-12-01' , '女'),(6 , '吴兰' , '1992-03-01' , null),(7 , '郑竹' , '1992-04-21' , '女'),(8 , '王菊' , '1990-01-20' , '女');
- 批量导入:为了安全起见,MySQL8.0默认不允许客户端从本地载入文件,因此需要在安全路径下导入 查看安全路径:show variables like ‘%secure%’
load data infile "C:/ProgramData/MySQL/MySQL Server 8.0/Uploads/sc.csv"into table scfields terminated by ','(指定分隔符为逗号)ignore 1 lines;(第一行为字段名,不导入)select * from sc; — 查询导入数据内容
将数据文件放在安全路径下,并复制路径(路径中不能有中文,并且要将‘\’改为‘\’或‘/’) load data infile ‘文件路径’into table 表名 [fields terminated by ‘,’ ignore 1 lines];
更新数据
update 表名 set 字段名1=字段值1[, 字段名2=字段值2[,…]][ where 更新条件];
删除数据
- delete from 表名[ where 删除条件];
delete from sc where s_id=1;
- truncate 表名;(与delete from 表名一样,都是删除表中全部数据,保留表结构)
- delete和truncate的区别:
delete可以添加where子句删除表中部分数据,truncate只能删除表中全部数据 delete删除表中数据保留表结构,truncate直接把表删除(drop table)然后再创建一张新表 (create table),执行速度比delete快
数据查询语言
查询结果是临时存储在内存中的虚拟结果集
- 查询指定列:select 字段1[,字段2,…] from 表名;
- 查询所有列:select * from 表名;
- 别名的设置:select 字段名 [as] 列别名 from 原表名 [[as] 表别名];
select *,score>=60 as 是否及格 from sc;
命名规则:字符(中文/英文)、数字和_,当别名中有空格或为纯数字时需要加引号
- 查询不重复的记录:select distinct 字段名[,字段名2,…] from 表名;
select distinct score from sc;
多个字段去重时,distinct关键字必须位于第一个字段前
多个字段完全一样的情况下,才会过滤
- 条件查询:select 字段1[,字段2,…] from 表名 where 筛选条件;
select * from sc where score>=60 and score<=80;
- 空值查询:select 字段1[,字段2,…] from 表名 where 空值字段 is [not] null;
null空值是特殊的未知值,它不属于任何一种数据类型,跟任何类型的数据进行运算,运算结果也都为nullselect * from stu where s_gender is null;select * from stu where s_gender is not null;
注意:不能用 xx= null 的表述,因为空值无法比较。
- 模糊查询: select 字段1[,字段2,…] from 表名 where 字段 [not] like 通配符;
模糊查询只能用于字符串类型的字段 select* from stu where s_name like '李%';(姓李的)select* from stu where s_name like '_菊%';(姓名为x菊的)select* from stu where s_name like '%风';(姓名为x风的)select* from stu where s_name not like '%风%';(姓名中包含“风”)
百分号(%)通配符:匹配0个或多个字符
下划线(_)通配符:匹配一个字符
单表查询
- 查询结果排序:select 字段1[,字段2,…] from 表名 order by 字段1[ 排序方向,字段2 排序方向,…];
指定排序方向:asc升序,desc降序(没有指定排序方向时,默认是asc升序)
select * from sc order by score asc;
- 多字段排序时,先按第一个字段排序,第一个字段值相同时再按第二个字段排序
如果第一个字段值都是唯一的,则不会按照第二个字段排序
select * from sc order by s_id,score desc,s_id;
- 限制查询结果数量:select 字段1[,字段2,…] from 表名 limit [偏移量,] 行数;
select * from sc order by score desc limit 5;
— 从第五行之后开始返回(第六行开始)select * from sc order by score desc limit 5,5;
limit接受一个或两个数字参数,参数必须是一个整数常量
第一个参数指定第一个返回记录行的偏移量,第二个参数指定返回记录行的最大数目
如果只给定一个参数,表示返回最大的记录行数目
初始记录行的偏移量是0(而不是1)
- 分组查询:select 字段1,[字段2,…] from 表名[where 查询条件] group by 分组字段1,[分组字段2,…];
select sum(score),avg(score),min(score),count(*) from sc;
— 去除重复值select sum(score),avg(score),min(score),count(distinct s_id) from sc;
字段值相同的为一组,对每个组内的多条记录进行聚合运算
- 常用的聚合函数:所有的聚合函数都会忽略null空值 | 聚合函数 | 说明 | | —- | —- | | SUM() | 对一个数值字段求和 | | AVG() | 对一个数值字段求平均值 | | MAX() | 对一个数值或日期时间字段求最大值 | | MIN() | 对一个数值或日期时间字段求最小值 | | COUNT() | 对一个或多个字段计数 |
count()函数运用
可以对单个字段进行计数,也可以对多个字段(按联合计算,不是对每一个非空值字段求和)进行计数。select count(sal) from emp;select count(*) from emp;(对所有字段进行计算,只有这个表中这一行所有的字段都不为空值就算有效计数)
结合distinct使用select count(distinct comm) from emp;
- 分组后筛选:
select 字段1[,字段2,…] from 表名[ where 筛选条件][ group by 分组字段] having 筛选条件;
(having子句支持where子句中所有的 运算符)select s_id, avg(score) from sc <br />group by s_id <br />having avg(score>=80);
- where 与 having 的区别:
where子句作用于表,having子句作用于组。
where条件查询的作用域是针对数据表进行筛选,而having条件查询则是对分组结果进行过滤
where在分组聚合计算之前筛选行,而having 在分组聚合之后筛选分组,因此where子句不能使用聚合函数
select语句书写顺序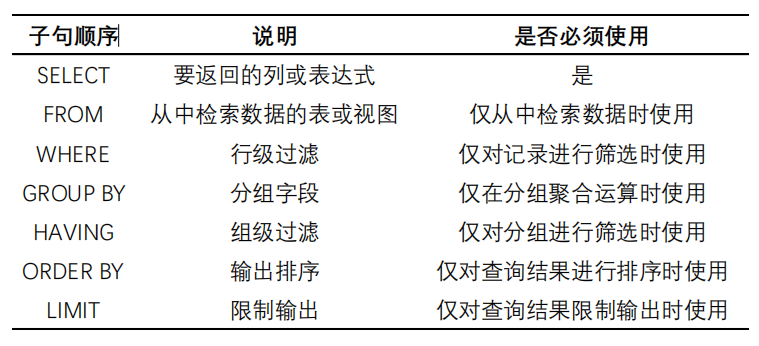
where子句中不能使用聚合函数(如 avg()),聚合函数在group by的步骤中执行的。
select语句执行顺序
多表查询
多表查询
通过不同表中具有相同意义的关键字段,将多个表进行横向连接,查询不同表中的字段息
连接方式
• 内连接和外连接(左连接和右连接)
内连接:只连接两张表中满足条件的记录
多表连接的结果通过三个属性决定
• 方向性:在外连接中写在前边的表为左表、写在后边的表为右表
• 主附关系:主表要出所有的数据范围,附表与主表无匹配项时标记为null,内连接时无主附表之分
• 对应关系:关键字段中有重复值的表为多表,没有重复值的表为一表

不同的数据分析工具支持的表连接方式
Oracle/sql server/Tableau/Python:内连接(inner join)、左连接(left join)、右连接(right join)、全连接(full join)
MySQL:内连接(inner join)、左连接(left join)、右连接(right join)
Power BI:内连接、左连接、右连接、全连接、左反连接、右反连接
笛卡尔积连接:
例:有a表和b表,用a表的每一条记录与b表的每一条记录连接,尤其是在两表没有相同的连接字段时,先采用笛卡尔积连接。再从另一张表,限制筛选条件。
自连接:
通过别名,将同一张表视为多张表,即是将两张相同的表连接,如果一张表中有可以对应的两个字段。
多于两个表的连接:
例子:a inner join bon……inner c on……
联合查询
把多条select语句的查询结果合并为一个结果集。
合并查询:
- 被合并的结果集中字段的个数、顺序和数据类型必须完全一致
union去重:select 字段1[,字段2,…] from 表名 union select 字段1[,字段2,…] from 表名;
union all不去重:select 字段1[,字段2,…] from 表名 union all select 字段1[,字段2,…] from 表名;
子查询
一个select语句中包含另一个或多个完整的select语句。
子查询分类
• 标量子查询:返回的结果是一个数据(单行单列)
• 行子查询:返回的结果是一行(单行多列)
• 列子查询:返回的结果是一列(多行单列)
• 表子查询:返回的结果是一张表(多行多列)
子查询出现的位置
• 出现在select子句中:将子查询返回结果作为主查询的一个字段或者计算值(标量子查询、列子查询)
• 出现在where/having子句中:将子查询返回的结果作为主查询的条件(标量子查询、行子查询、列子查询、表子查询)
• 出现在from或join子句中:将子查询返回的结果作为主查询的一个表(标量子查询、行子查询、列子查询、表子查询)
必须添加表别名,如果需要引用表子查询中的计算字段,必须添加列别名才可以引用

分组合并函数
GROUP_CONCAT([distinct] str [order by str asc/desc] [separator])
将group by产生的同一个分组中的值连接起来,返回一个字符串结果。
示例:查询每个部门的员工姓名

[separator]:可选择使用哪个符合作为分隔符
表子查询
例子:面试题德邦物流

一个查询中不能有两个group by 函数,所以使用表子查询,对分组后的结果再分组。

若有收获,就点个赞吧
0 人点赞
