多表查询
重点:外链接语法
单表查询
条件语句:
where ……
关系逻辑
like
分组groud by
对分组后的记录进行过滤having
排序:order by
限制多少条记录,默认是0到N:limit
交叉查询:不使用任何的匹配条件,生成结果符合笛卡尔积
内连接:只连接匹配的行
关键字:inner join
*外连接
左连接:优先显示左边全部记录
关键字:
右连接:优先显示右表全部记录
关键字:
全外连接:显示左右两个表的全部记录
关键字:union
子查询
- 热备份:数据库硬盘+内存中的数据
-
按照备份后文件的内容
逻辑备份:备份后的文件内容可读,一般内容是SQL语句
-
按照备份数据的内容
完全备份:对数据库进行一个完整的备份
- 增量备份:在上次的完全备份基础上对更新的数据进行备份
日志备份:二进制日志备份—>当数据库宕机之后进行数据恢复的依据
冷备份:备份MySQL数据库的frm文件,共享表空间、独立表空间文件(*.ibd)
优点:
备份简单,只要拷贝相关文件即可
- 备份文件易于在不同操作系统,不同MySQL版本上进行恢复
- 备份相当简单,只需要把文件恢复到指定位置即可
- 恢复速度快,不需要执行任何sql语句,也不需要重建索引
缺点:
- 冷备份文件通常比逻辑文件大很多
- 不是总可以轻易跨平台
逻辑备份
- mysqldump(不能导出视图)
视图:数据库中的虚拟表,只用于查询操作
语法:
示例:
单库备份
多库备份
快照备份:LVM技术中的快照功能
—>对逻辑卷进行备份(某个时间点的数据内容)
—>对数据逻辑卷进行快照
事务
把数据库从一种一致性状态转换为另一种一致性状态,来保证数据库的完整性
主要用于处理操作量大,复杂高的数据
在MySQL中,只有使用了innodb数据库引擎的数据库或表才支持事务
事务处理可以用来维护数据库的完整性,保证成批的SQL语句要么全部执行或全部不执行
第一种情况:全部执行—>事务提交
第二种情况:全部不执行—事务回滚
事务主要用于管理insert,update,delete语句,
一般来说,事务一般要满足四个条件,我们称之为ACID
A:原子性,事务必须是执行任务的最小原子单位,事务要么成功,要么撤回
C:一致性,事务把数据库从一个一致性状态转换成另一个一致性状态
I:隔离性,每个事务之间是隔离的
D:持久性:事务一旦执行,其结果是永久的
数据库引擎以插件形式存在
隔离等级:4个
read uncommitted(未提交读):一般会出现“脏读”的现象
read committed(提交读):能够解决“脏读”现象,一般会出现“幻读”现象
repeatable read(可重复读):能够解决“幻读”现象
serializable(可串行化读)
锁
行级锁
排他锁:针对update,insert,delete等操作会加上排他锁
共享锁:针对select操作,不同事物可以同时读同一份数据
索引管理
功能
唯一索引
主键索引primary key:加速查找+约束条件(不能为空且不能重复)
唯一索引unique;加速查找+约束条件(不能重复)
联合索引
primary key(id,name):联合主键索引
unique(id,name):联合唯一索引
index(id,name):联合普通索引
索引类型:
我们可以在创建上述索引的时候,为其制定索引类型,主要分三类:
- btree类型索引:b+树 数据结构:层数越多,数据量指数级增长越快(innodb默认支持它)
- hash类型索引:查询单条记录快,范围查询比较慢
- 全文索引
不同的查询引擎支持的索引类型不一样
innodb存储引擎:支持事务,支持行级别锁定,支持B+TREE,full text;hash等索引
树:类似于树状结构的存储方式
节点:根节点,叶子节点,非叶子节点(存储的数据都会处于一个节点上)
度数:每个节点的子节点数
深度
层数
二叉树:每个节点最多只有两个子节点
二叉查询数:每个树(子树)的根节点:它的值大于左子树,小于等于右子树
二叉树以第一个插入的数据作为根节点,当后续插入的数据为递增时就会相当于生成一个数据链表,不利于索引的查询
平衡树:一般来说,子节点的高度差不能超过1,目的是为了减少遍历的次数,因为层数越多,我们查询的次数就越多
Btree:是平衡树演变过来的,但并不是二叉树,是一个绝对平衡树,保证所有的叶子节点在同一高度;M阶树
- 左子树的所有值小于根节点,右子树的所有值大于根节点
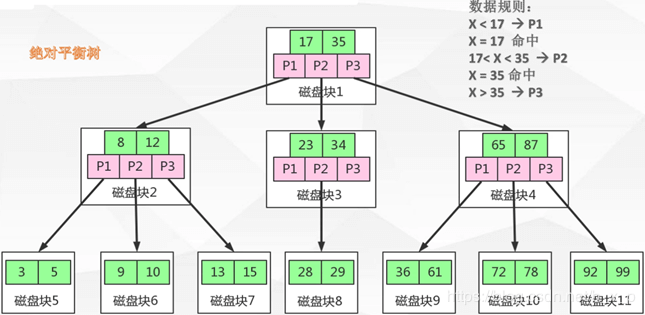
上图为一个2-3树(每个节点存储2个关键字,有3路),多路平衡查找树也就是多叉的意思,从上图中可以看出,每个节点保存的关键字的个数和路数关系为:
关键字个数 = 路数 – 1
数据库中:索引和数据是存放在数据页中,数据页在磁盘中—>每次根据索引查找数据时会进行磁盘IO操作(每查找到一个数据就进行一次IO直到找到目标数据)
Btree减少了层数,极大的减少了磁盘IO 的操作次数,减少系统开销
B+tree:由Btree演变过来
ps:数据通过innodb存储时,割分成数据段,数据段再变成分区,分区里有多个数据页,数据页存放在存储介质上
非叶子节点存放KEY,叶子节点存放KEY+数据的对应
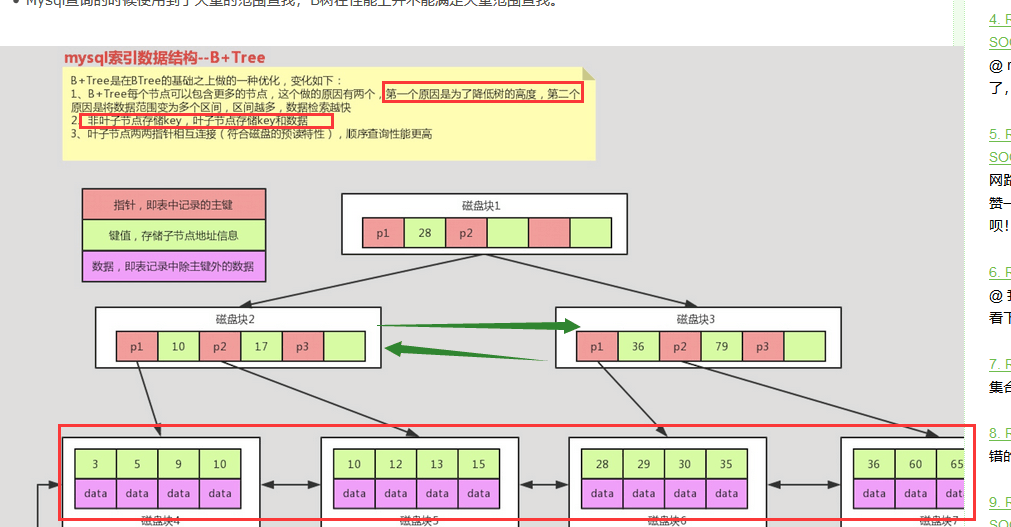
一个数据段:最多4个分区,每个分区默认64个页,每个页的大小默认为16K
Btree的K-V存放在同一个数据页上,所以能够大大减少磁盘
key和页和数据的关系?
key和数据是一对一的关系,一个页上可存放多个key
innodb存储引擎:
聚集(聚簇)索引,默认为我们的主键去以B+tree数据结构存储索引时
简单说就是当主键作为索引时称为聚簇索引
非聚簇索引:除了主键之外,还为别的字段创建索引的时候
区别:
- 聚簇索引:完全符合上面说的B+tree数据结构存储
- 非聚簇索引(也称之为辅助索引),也符合上面说的结构,但是叶子节点不存放数据,存放“标签”,标签指向聚簇索引所在B+tree
ps:标签和KEY是一对一的关系,但标签和B+tree的关系应该是多对一
KEY值在整个数据库中唯一还是尽在某个B+tree中唯一?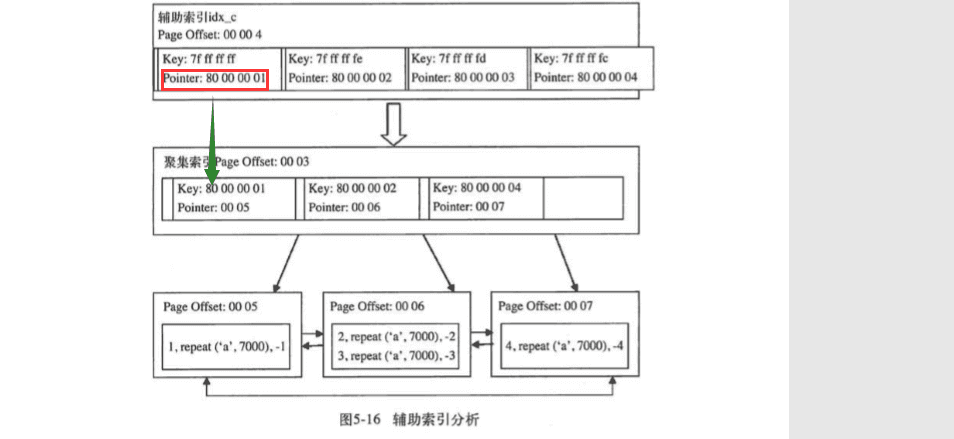
索引管理
创建索引:
- 在创建表的时候,创建索引
- 在已有表上创建索引
- 修改已有表上的索引
查看索引:
删除索引:
- 创建索引的目的是为了加快查询,当我们创建主键的时候就建立了主键索引->聚簇索引;如果没有创建显示的定义主键,innodb存储引擎表会隐形生成一个字段作为主键
- 在表中已经有大量数据的情况下,建立索引会非常慢,并且占用磁盘空间,但是建立完成之后,查询速度会很快
- INNODB表的索引会存放于,ibd文件中
正确使用索引:
并不是说创建索引就一定会加快查询速度,如果想要利用索引提高查询速度,需要遵循以下问题:
- 范围问题:条件中经常出现> < = between and like
- 选择问题:尽量去选择重复度低的字段作为索引;表示字段不重复的比例
- 索引列不能在条件中参与计算,通过函数转换的时候
使用规则:
最左前缀匹配原则:
一般对于组合规则进行范围查找(> < between and等),他会一直向右匹配直到右边范围就停止匹配,有时候即使有索引速度也会慢
其他情况:
- 使用函数,尽量减少使用
- 类型不一致,如果字段是字符串数据类型,传入条件的时候要加“”
- 排序条件作为索引,则select字段必须也是索引字段,否则无法命中索引
- like模糊查询不走索引,最好只用于查询变量;少用between and
注意事项:
- 避免使用select *
- 使用count(*)/count(1)代替count(field)
- 创建表的时候使用char代替varchar
- 表的字段顺序固定长度的字段优先
- 组合索引代替多个单个索引(因为MYSQL每次只能使用一个索引)
- 尽量使用短索引
- 使用连接查询代替子查询
- 连表时注意条件类型需要一致
- 重复少的字段,不适合做索引,比如:性别
mariadb日志及文件
- 查询日志:记录查询操作
- 慢查询日志:记录查询超过指定时长的操作
- 错误日志:记录MySQL启动|关闭|运行产生的一些错误
- 二进制日志
- 中继日志:复制架构中,服务器保存从主服务器的二进制日志中读取到的事件
- 事务日志:事物型存储引起自行管理和使用
- PID文件:当MySQLD再次启动的时候,会载入PID到指定文件中
- socket文件:本地连接MySQL服务器的
复制原理
复制过程:
- 主服务器上任何的更新操作被写入到二进制文件中
- 从服务器的IO线程
- 监测主服务器的二进制日志文件的变化
- 同步主服务器的二进制日志文件到本地的中继日志中
- 从服务器上的SQL线程负责读取和指定中继日志中的SQL语句
应用场景:一主多从会去对应读写分离
— 写操作由主服务器
— 读操作由从服务器
- 假如主服务器上:drop *
要去做备份操作:在从服务器上通过LVM快照进行备份
- 假如主服务器挂掉了,用户不可以进行写入操作
高可用模型:多主架构
任何一台服务器既是主服务器也是从服务器
- 高可用架构:MHA架构

若有收获,就点个赞吧
0 人点赞
