通配符
在Linux中用作于匹配文件名,由shell进行解析,如find命令,ls,cp,mv等均可与通配符搭配使用
常用通配符
比如:/tmp/1.txt 2.txt 3.txt
查看/tmp下所有以.txt结尾的文件
ls .txt
:可以匹配零或多个字符
?:匹配任意一个字符,无字数要求
[list]:匹配list中的任意单个元素
[c1-c2]:匹配的是c1-c2中任意单个字符,以范围为匹配标准
[^c1-c2]/[!c1-c2]:不匹配含c1-c2任意单个字符的文件
{string1,string2,……}:匹配{}中任意单个字符串
shell的元字符
/<:重定向
|:管道
=:设置变量
$:获取变量的值
\:转义符
#:注释
&:后台执行命令(命令后加上此符号)
():在子shell中执行命令或运算
{}:函数中执行/变量替换的定界范围
;:命令结束后,忽略其返回结果,继续执行下一个命令
&&:命令结束后,若返回结果为true,则继续执行下一个命令
||:命令结束后,若返回结果为false,则继续执行下一个命令
!:非shell转义符
‘’:硬转义,内部所有shell元字符、通配符都会被关掉
“”:软转义find命令
Linux中实时查找工具,通过遍历指定目录下的文件系统完成文件查找
工作特点:
-精确查找
-实时查找
-查找速度较慢
Usage: find [-H] [-L] [-P] [-Olevel] [-D help|tree|search|stat|rates|opt|exec] [path…] [expression]
find [选项] [路径] [查找条件-处理动作]根据文件名查找:
-name “文件名” 支持通配符
-iname “文件名” 忽略大小写
-regex “PATTERN” 以pattern匹配整个文件路径字符串,而不仅仅是文件名称根据属主和属组查找:
-user “username”:查找属主为指定用户的文件
-group “groupname”:查找属组为指定组的文件
-uid “userid”:查找指定uid的文件
-gid “groupid”:查找指定groupid的文件
-nouser:查找没有属主的文件
-nogroup:查找没有属组的文件通过文件类型查找:
-type TYPE
f/d/l/s/b/c/p
f:普通文件
d:目录文件
l:链接文件(软链接和硬链接)
s:套接字文件
b:块文件
c:字符文件
p:管道文件
注意:由于find会遍历整个路径,因此查找的路径应该尽可能的小
组合条件:
多个匹配条件的组合
与:-a
或:-o
非:-not
():使用小括号将组合条件括起来,注意括号要与条件用空格隔开
find /tmp ( -user root -a -name fastab )
根据文件大小来查找:
-size [+|-]N[bcwkMG]
[bcwkMG] 文件大小的单位
-size +10G :查找文件大小大于10G的文件
根据时间戳查找:
天:
-atime:
-ctime:
-mtime:可加+|-N天,默认为+,+表示N天前,-表示N天内
分钟:
-amin:
-cmin:
-mmin:
根据权限查找:
-perm [+|-] MODE
MODE:精确权限匹配(-rwx-w-rw-),可用726
/MODE:任何一类对象的权限中只要能一个对象匹配即可
-MODE:每一类对象都需要同时拥有指定的权限标准,仅需拥有,无需全局匹配
两种方式:
-perm 644
-perm /u=rw,g=r,o=r或-perm +u=rw,g=w,o=w
处理动作:
-print:默认处理动作,显示至屏幕
-ls:对查找到的文件执行类‘ls -l’命令
-delete:删除查找到的文件
-fls 文件路径:查找到的所有文件的长格式信息保存至指定文件中
-ok command {}\;
-exec command {}\;
-对所有查找到文件执行command命令
-ok 每次执行都会进行提示
{}:代表所有查找到的文件本身,将所有文件一次性传到内存中执行命令
xargs command:类似于-ok ,但是每查找到一个文件就传到内存执行一次命令,相当于栈的操作,减少内存的开销,防止一次-ok一次查找到的文件大小过大,一次性传入内存会撑爆内存
练习
1.查找/var/目录下属主为root,且属组为mail的所有文件或目录
2.查找/user/目录下属主不为root,bin,或Hadoop的所有文件或目录
3.查找/etc/目录下最近一周内被访问的所有文件和目录
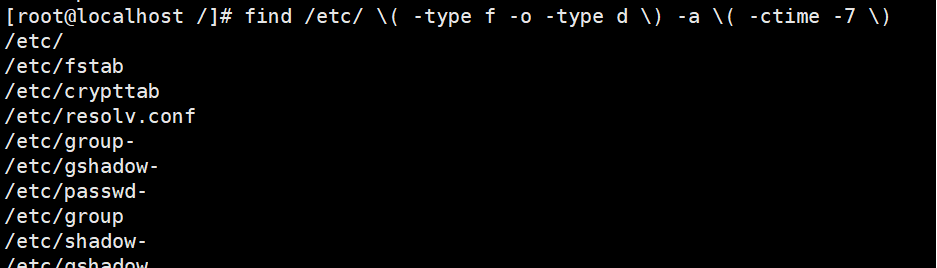
4.查找/etc/目录下大于1 M且文件类型为F的所有文件和目录
5.查找/etc/init.d目录下,所有用户都有执行权限,且其他用户拥有读权限

正则表达式
是用来匹配字符串的,针对文本内容的过滤工具里所必须的
比如vim、grep、awk、sed等工具都会使用到正则表达式(后三个及文本三剑客)
基本的正则表达式
字符匹配
.:任意单个字符
[]:匹配指定范围内任意单个字符
[^]:匹配指定范围外任意单个字符
[:alnum:]:字母和数字字符
[:alpha:]:字母字符
[:ascii:]:ASCII字符
[:blank:]:空格或制表符
[:cntrl:]:ASCII控制字符
[:digit:]:数字
[:graph:]:非控制字符、非空格字符
[:lower:]:小写字母
[:upper:]:大写字母
[:print:]:可打印字符
[:punct:]:标点符号字符
[:space:]:空白字符,包括垂直制表符
[:xdigit:]:十六进制字符
次数匹配
:匹配前面的字符任意次数
.:匹配任意长度的字符
\?:匹配前面的字符0次或1次,只对前面的一个字符生效
+:匹配前面的字符至少一次,只对前面的一个字符生效
{m}:匹配前面的字符m次
{m,n}:匹配前面的字符至少m次,至多n次
{0,n}:匹配前面的字符至多n次
{m,}:匹配前面的字符至少m次
位置锚定
^:行首锚定,用于模式的最左侧
$:行尾锚定,用于模式的最右侧
^parttern$:用户模式匹配整行内容,parttern及整行内容
^$:空行
\<或\b:词首锚定,用于单词模式的最左侧
>或\b:词尾锚定,用于单词模式的最右侧
\
分组
将一个或多个字符捆绑在一起当作一个字符
分组—>次数
(ab){4}
引用
分组括号中的模式匹配到的内容会被正则表达式引擎记录到内部变量中,这些变量的命令方式为:
(ab)+(xy)*
\1:代表ab分组
\2:表示xy分组
嵌套分组时,最里边的为分组1,依次往外,外面的分组包含里边的分组的内容
扩展正则表达式
区别:
将次数匹配、位置锚定和分组中的\去掉了
|:或
grep -E:让grep支持扩展到正则表达式
文本三剑客
grep:文本过滤器
常用选项
-corol=auto:对匹配到的内容着色显示
-v:显示不能被pattern匹配到的行
-i:忽略大小写字符
-o:仅显示匹配到的字符
-q:静默模式,不输出任何信息
-A #:after,匹配模式内容的后#行
-B #:before,匹配模式内容的前#行
-C #:centext,匹配模式内容的前后各#行
-E:使用ere(扩展的正则表达式)等同于egrep
<>:单词锚定
^$:行首行尾锚定
练习题
- 显示/proc/meminfo文件中以大小写s开头的行
grep -i “^s” /proc/meminfo
grep “^[Ss]” /proc/meminfo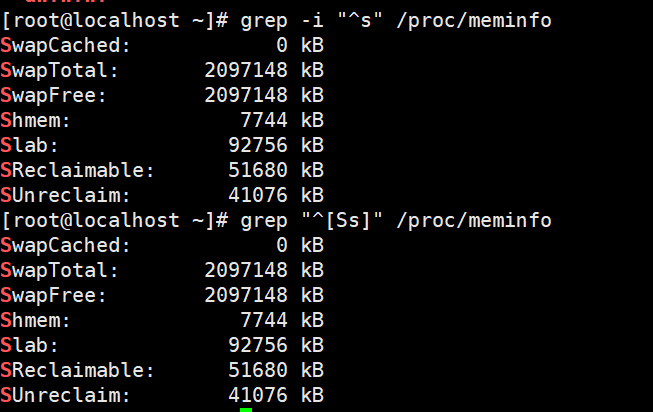
2. 显示/etc/passwd/文件中不以/bin/bash结尾的行
grep -v “/bin/bash$” /etc/passwd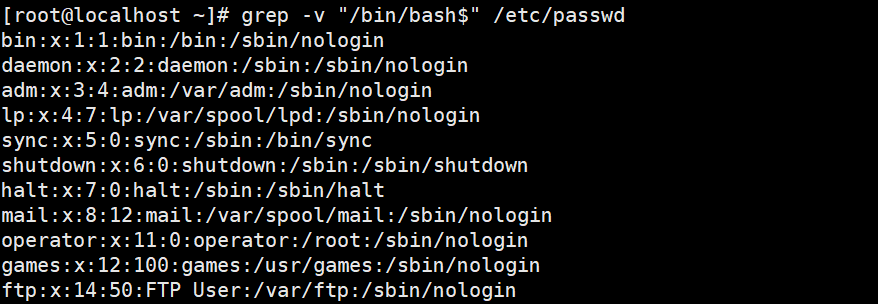
3. 如果root用户存在,显示其默认的shell程序
id root > /dev/null && grep “^root+“ /etc/passwd | cut -d: -f7
4. 找出/etc/passwd中的两位或三位数字
grep “\<[0-9]{2,3}>“ /etc/passwd
grep -E “\<[0-9]{2,3}>“ /etc/passwd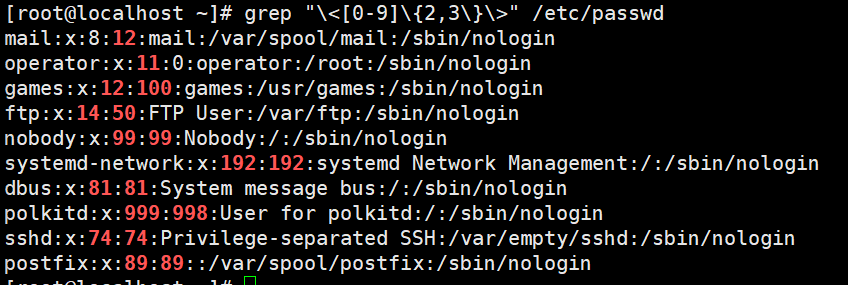
5. 显示/etc/grub2.cfg文件中,至少以1个空白字符开头的且后面不存在空白字符的行
6. 显示/etc/passwd用户名和shell名相同的行
bash bash
nologin nologin
grep -E “^\<([[:alnum:]]+)>.*\1$” /etc/passwd
注意:需要整个单词匹配时需要对这个单词进行锚定
sed:文本编辑工具
stream ediot 文本流编辑器,sed是一个“非交互式”的面向字符流的编辑器,能够同时处理多个文件,多行的内容,可以不对原文件改动,把整个文件输入到屏幕,可以把只匹配到的模式内容输入到屏幕上,还可以对原文件改动,但是不输出到屏幕上
格式语法
sed用法
命令格式:sed [option] ‘sed command’ filename
脚本格式:sed -f [option] ‘sed scripts’ filename
sed scripts指的是sed的动作脚本
常用选项:
-n:只打印模式匹配到的行
-e:直接在命令行模式上进行sed编辑
-f:将sed的动作写在另一个文件内,用-f filename执行filename内的sed动作
-r:支持扩展表达式
-i:直接修改文件内容
查询文件的方式:
-使用行号和行范围
x:行号,sed -n ‘xp’ filename可以打印指定的行
x,y:从x行到y行 sed -n ‘x,yp’ filename
x,y!:x行到y行之外的内容
/pattern:查询包含模式的行,sed -n ‘/pattern/p’ filename
pattern时可以使用正则表达式进行查询包含的内容
/pattern/,/pattern/:查询包含两个模式的行
/pattern/,x:x行前查询包含模式的行
x,/pattern/:x行后查询包含模式的行
编辑命令
常用选项
p:打印匹配到的行(-n)sed -n ‘10p’ fstab
=:显示文件行号
a\:在指定行后添加新文本内容 sed -e ‘10a\line1 after’ fstab
i\:在指定行前添加新文本内容 sed -i ‘10i\line1 before’ fstab
c\:用新文本内容替换定义文本 sed -i ‘10c\line1 new’
d:可以删除指定行 sed -i ‘10d’ fstab
w filename:写文本到另一个文件中 sed -n ‘10w /tmp/10.txt’ fstab
r filename:从另一个文件读文本内容
s///:替换
替换标记
g:行内全局替换
p:显示替换成功的行
w:将替换成功的结果保存至指定文件
q: 第一个模式匹配后立即退出
{}: 在定位航执行的命令组,用逗号分割
g: 将模式2粘贴到/pattern n/
最常用于-取消注释行:
sed ‘1,10s@^#(.)$@\1@g’ 1.txt
^#+(.)$ —-> 查询内容:所有#开头的行
\1 替换的内容 (.*)
练习题
- 显示/etc/passwd文件中位于第偶数行的用户的用户名
sed -n ‘n;p’ /etc/passwd | cut -d: -f1
2. 为/tmp/1.txt 文件中前三行的行首加#号。
sed -i ‘1,3s@(^.)@#\1@g’ /tmp/grub.conf
1,3s@(^.)@#\1@gawk:文本报告生成器
文本报告生成器,相对于过滤工具grep,编辑工具sed,awk可以数据分析并生成报告,简单来说awk将文本内容逐行读入,以空格为默认分隔符进行切片,切开的部分再进行各种分析处理使用方法
[root@localhost ~]# awk —help
Usage: awk [POSIX or GNU style options] -f progfile [—] file …
Usage: awk [POSIX or GNU style options] [—] ‘program’ file …
命令模式
脚本模式
常用选项:
-F:指定分隔符
-v:指定用户自定义变量
-f:从脚本文件中读取awk命令
pattern:
模式可以是一下任意一种:
正则表达式(* 0次或多次 ?0次或1次 + 1次或多次)
关系表达式:使用运算符进行操作,可以是字符串或者数字比较测试
模式匹配表达式:用运算符~(匹配)和!~(不匹配)
begin语句块、pattern语句块、end语句块
action:
操作由一个或多个命令、函数、表达式组成,之间由换行符或分号隔开,主要部分是变量或数组赋值,输出命令,内置函数,流程控制语句awk常见用法
[root@localhost ~]# awk -F: ‘{print $7}’ /etc/passwd/
[root@localhost ~]# awk -F: ‘$4==1000 {print $1}’ /etc/passwd
$4==1000:关系表达式
[root@localhost ~]# awk -F: -v a=3 ‘{print $a+$3}’ /etc/passwd
print $a+$3—>print $3+$3
[root@localhost ~]# awk -F: ‘BEGIN{print”—————“}{printf “username:%-16s\tuserid:%-16s\n”,$1,$4}END{print”—————end——-“}’ /etc/passwd
awk运算符
关系运算符:(== != >= <= > <)
算数运算符:+ - / ++ —
赋值运算符:= += -= /= %= *=
逻辑运算符: || &&
正则运算符: ~(匹配) !~(不匹配)
内置变量
FILENAME:文件名称
NR:行号
NF:行数
$0:整行数据
ARGC:命令行参数个数
ARGV:命令行参数排序
FNR:浏览文件的记录
FS:设置输入分隔符,等价于-F选项
RS:控制记录分隔符
OFS:输出域分隔符
ORS:输出记录分隔符
ENVIRON:支持队列中系统环境变量的使用
条件判断及循环
if(条件)action(动作)
if(条件) action1 else action2
for(i=1;i
while(condition) action
break:结束整个循环
continue:结束本次循环
数组
数组使用的语法格式:array_name[index]=value
删除数组:delete array_name[index]
多维数组:二维、三维……
函数(自行了解)
系统资源管理
Linux包管理器—RPM
RPM管理:安装软件包的工具
rpm —help
Usage: rpm [OPTION…]
常用使用方式:
rpm -ivh package_file
-i:install安装
-v:打印调试信息
-h:包如果没有破解,则打印50个破折号
常用参数:
—test:测试安装,但不真正执行安装过程:dry run模式
—nodeps:忽略依赖关系
—replacepkgs:重新安装
—nosignature:不检查来源合法性
—nodigest:不检查包的完整性
—noscipts:不执行程序包脚本程序
升级:
常用方式:
rpm -Uvh packeage_file
rpm -Fvh packeage_file
-U:upgrade packages
-F:upgrade package#旧安装包如果存在才进行升级操作
查询:
-q [query oprions]
-a:查询所有软件包
-l:查看指定的程序文件安装后生成的所有文件
-f:查询指定的文件由那个程序包安装生成
—whatprovides:查询指定的CAP包是由哪个包所提供的
—changelog:查询rpm包的changelog
—whatrequires:查询指定的CAP包是被哪个包所依赖
-c:查询程序的配置文件
-i:information
-d:查询程序的文档
-R:查询指定的程序包所依赖的CAP包
—script:查询程序包自带的脚本片段
—provides:列出指定程序包所提供的CAP包
rpm -qa 软件名#查询软件包
卸载:
rpm -e package_file
校验:
常用方式:
rpm -V package_file
-nofiledigest don’t verify digest of files #不去验证包的完整性
-nofiles don’t verify files in package # 不去验证包的文件
-nodeps don’t verify package dependencies # 不去验证包的依赖
-noscript don’t execute verify scr # 不去验证包的来演合法性
205 rpm -qa mariadb
206 rpm -ql mariadb-5.5.60-1.el7_5.x86_64
219 rpm —whatprovides ifconfig
220 rpm -q —whatprovides ifconfig
222 rpm -q -c mariadb
223 rpm -q —scripts mariadb
224 rpm -qi mariadb
225 rpm -qd mariadb
226 rpm -q —whatrequires mariadb
227 rpm -qR mariadb
RPM包管理器:依赖性
yum管理:自动解决包的依赖性
YUM仓库—服务端
阿里源
163源
搜狐源
……
自建
YUM客户端
配置文件:
/etc/yum.conf:为所有仓库提供公共配置
/etc/yum.repos.d/*.repo:为仓库的指定提供配置
仓库的指向定义
[root@node1 ~]# cat /etc/yum.repos.d/CentOS-Base.repo
[base] # 仓库ID
name=CentOS-$releasever - Base - mirrors.aliyun.com # 仓库名称
failovermethod=priority
baseurl=http://mirrors.aliyun.com/centos/$releasever/os/$basearch/ # 镜像的源列表地址
http://mirrors.aliyuncs.com/centos/$releasever/os/$basearch/
http://mirrors.cloud.aliyuncs.com/centos/$releasever/os/$basearch/
gpgcheck=1 # gpg秘密验证 1: 验证 2:不验证
gpgkey=http://mirrors.aliyun.com/centos/RPM-GPG-KEY-CentOS-7 # gpg密钥文件地址
enabled=0 # 0:不开启 1:启用
常见变量说明
$releasever:当前OS的发行版本的主版本号
$basearch: 基础平台
$arch: 平台架构
常用命令
[root@node1 ~]# yum —help
Loaded plugins: fastestmirror
Usage: yum [options] COMMAND
显示仓库列表
yum repolist [all|enabled|disabled]
all:所有
enabled:开启
disabled:未开启
显示程序包
yum list [all|glob_exp1]
all: 所有程序包
global: 通配符表达式
yum available —> 可用的程序包
升级程序包:
yum update package(s)
check-update Check for available package updates # 检查可用升级
降级程序包
yum downgrade package(s)
卸载程序包
yum remove | erase package(s)
查看程序包information
yum info [..]
查看指定的特性(可以是某个文件)是有哪个程序包提供的
yum provides | whatprovides feature(s)
net-tools —> ifconfig
构建缓存
yum makecache
清理缓存
yum clean [all | package …]
搜索
yum search string(s)..
以指定的关键字搜索程序包名及其summary信息
查看yum相关历史
yum history [info | list | package-list|summary …..]
常用选项:
-y:自动回答yes
yum install net-tools -y
-q:静默模式(无输出信息)
—nogpgcheck:禁止进行gpgcheck(仓库定义配置进行配置)
—disablerepo=repoid 临时的禁止此处指定的repo
—enablerepo=repoid 临时启用此处指定的repo
—noplugins:禁止所有插件
Linux磁盘管理
基础知识
一切皆文件:open(),read(),write(),close()
块设备: b 存取单位为-块 硬盘
字符设备:c 存取单位为-字符
设备文件: 关联至一个设备驱动程序,进而能够与之对应硬件设备进行通信
设备号码
主设备号,标识设备类型
次设备号,标识同一类型下的不同设备
硬盘的接口类型
并行
IDE: 133MB/s
SCSI: 640MB/s
串行
SATA: 6Gbps
SAS:6Gbps
USB: 480M/s
磁盘设备命名
IDE:/dev/hba .
SCSI、SATA、SAS…/dev/sda …..
不同设备:a-z sda sdb …
同一设备上的不同分区:1,2,3, sda1 sda2
分区方式
MBR:使用32位表示扇形数,分区不超过2T,按柱面进行分区,4个主分区(3个主分区和1个扩展分区(N个逻辑分区))
GPT:支持128个分区,使用64位,使用128位UUID号去表示磁盘和分区
分区管理类命令:fdisk,parted
fdisk命令:对于一块磁盘来说最多管理15个分区
fdisk: invalid option — ‘-‘
Usage:
fdisk [options]
fdisk [options] -l
fdisk -s
在进行改变分区操作的时候
子命令管理
a toggle a bootable flag
b edit bsd disklabel # 编辑bsd磁盘标签
c toggle the dos compatibility flag
d delete a partition # 删除一个分区
g create a new empty GPT partition table
G create an IRIX (SGI) partition table
l list known partition types # 列出所有分区ID
m print this menu # 打印菜单
n add a new partition # 创建一个新分区
o create a new empty DOS partition table
p print the partition table # 打印分区表
q quit without saving changes # 直接退出
s create a new empty Sun disklabel
t change a partition’s system id # 改变磁盘分区类型
u change display/entry units
v verify the partition table
w write table to disk and exit # 写入磁盘并退出
x extra functionality (experts only)
如果需要调整磁盘分区类型:寻找分区类型名对应的ID号 l —> t 选择分区,选择分区类型ID号—> w 保存退出
parted命令
注意:parted的任何操作都是实时生效的,所以要小心使用
查看内核是否已经识别新的分区:cat /proc/partitions
通知内核重新读取磁盘分区表:
partx -a /dev/DEVICE
partprobe [/dev/DEVICE]
创建磁盘分区的过程:
1. fdisk /dev/DEVICE
2. n 创建新分区
3. t 改变分区类型
4. w 保存退出
5. partprobe /dev/DEVICe 通知内核重新读取磁盘分区表
6. 查看分区表
Linux文件系统
基础知识
Linux的文件系统:ext2,3,4 xfs,btrfs,reiserfs,jfs……
swap:交换分区
光盘:iso9660
window:fat32 ntfs
unix: FFS UFS JFS2
网络文件系统:nfs CIFS
级群文件系统: GFS2 OCF2^
分布式文件系统:ceph ,Glusterfs,moosefs……
分类
-根据是否支持journal功能
日志型文件系统:ex3,4 xfs..
非日志型文件系统:ext2,vfat
文件系统的组成部分
内核中的模块: ext4,xfs,vfat
用户空间的管理工具:mkfs,ext4,xfs,vfat…
Linux虚拟文件系统:VFS
mkfs命令
[root@localhost ~]# mkfs -help
Usage:
mkfs [options] [-t
-t:指定文件类型:ext4,xfs,btrfs,vfat
mkfs.FILE_TYPE
mkfs -t ext4 —>mkfs.ext4
为分区创建文件系统:mkfs.ext4
ext系列文件系统的专用管理工具:mke2fs
mke2fs —help
mke2fs: invalid option — ‘-‘
Usage: mke2fs
[-c|-l filename] [-b block-size] [-C cluster-size]
[-i bytes-per-inode] [-I inode-size] [-J journal-options]
[-G flex-group-size] [-N number-of-inodes]
[-m reserved-blocks-percentage] [-o creator-os]
[-g blocks-per-group] [-L volume-label] [-M last-mounted-directory]
[-O feature[,…]] [-r fs-revision] [-E extended-option[,…]]
[-t fs-type] [-T usage-type ] [-U UUID] [-jnqvDFKSV] device [blocks-count]
常用选项:
-t:指定文件类型,ext2,3,4
-b:指定块大小{1024,2048,4096}k
-L:指定卷标
-j:相当于 -t ext3
mkfs -t ext3 —> mkfs.ext3 —> mke2fs -t ext3 —> mke2fs -j
-i:为数据空间中每多少个字节创建inode;此大小不应该小于block的大小
-n:指定为数据空间中创建多少个inode
-m:为管理人员预留的空间占据的百分比
-o feature(s)……:启动指定特性
-O feature(s)……:关闭指定特性
mkswap:创建交换分区(默认为swap类型)
[root@localhost ~]# mkswap —help
Usage:
mkswap [options] device [size]
Options:
-c, —check check bad blocks before creating the swap area#检查是否有坏块
-f, —force allow swap size area be larger than device
-p, —pagesize SIZE specify page size in bytes
-L, —label LABEL specify label
-v, —swapversion NUM specify swap-space version number
-U, —uuid UUID specify the uuid to use #磁盘分区拥有文件系统后的唯一标识
-V, —version output version information and exit
-h, —help display this help and exit
ps:需要提前将分区类型调整为ID号82
82 Linux swap
分区方式:GPT MBR
分区类型: Linux swap Linux Linux LVM …..
文件系统类型:ext2,3,4 xfs btrfs …
其他工具
blkid命令:查看块设备的属性信息
e2lable命令:管理ext系列文件系统的label(标签)
[root@localhost ~]# blkid —help
blkid: invalid option — ‘-‘
blkid from util-linux 2.23.2 (libblkid 2.23.0, 25-Apr-2013)
文件系统检测工具:fsck,e2fsck
fsck命令:
fsck.FS_TYPE
-t:FS_TYPE
-a:自动修改错误
-r:交互式修复错误
注意:FS_TYPE:必须要和分区上已经拥有的文件系统保持一致
e2fsck命令:ext文件系统专用检测修复命令
[root@localhost ~]# e2fsck —help
e2fsck: invalid option — ‘-‘
Usage: e2fsck [-panyrcdfvtDFV] [-b superblock] [-B blocksize]
[-I inode_buffer_blocks] [-P process_inode_size]
[-l|-L bad_blocks_file] [-C fd] [-j external_journal]
[-E extended-options] device
-p Automatic repair (no questions)
-n Make no changes to the filesystem
-y Assume “yes” to all questions
-c Check for bad blocks and add them to the badblock list
-f Force checking even if filesystem is marked clean
-v Be verbose
-b superblock Use alternative superblock
-B blocksize Force blocksize when looking for superblock
-j external_journal Set location of the external journal
-l bad_blocks_file Add to badblocks list
-L bad_blocks_file Set badblocks list
常用参数:
-p:自动修复
-f:强制修复
-y:自动回答yes
-c:检查是否存在块 坏块
Linux文件系统挂载
挂载:将一个设备(通常是存储设备)挂接到另一个已经存在的目录上
-我们要访问存储设备中的文化,必须将文件所在的分区挂载到一个已经存在的目录撒谎给你
卸载:解除关联关系的过程
注意:挂载点下的所有原文件在挂载完成后会隐藏掉,所以通常情况下保证挂载点为空
挂载方法:mount命令
[root@localhost /]# mount —help
Usage:
mount [-lhV]
mount -a [options]
mount [options] [—source]
mount [options]
mount
常用方式:
mount :显示当前系统上已经挂载的所有设备
mount -a:挂载/etc/fstab文件中定义好的挂载方式
/etc/fstab文件时系统启动后自动挂载的配置文件
mount [option]
device:挂载设备
设备文件:/dev/sdb1
卷标:-L “label”
UUID:-U “uuid”
伪文件系统名称:/proc/sysfs……
常用选项:
-t:指明要挂载设备上的文件系统类型
-r:readonly,以只读方式挂载
-w:读写方式挂载
-n:不更新/etc/mtab
-L “label”:以卷标指定挂载设备
-U “UUID”:以UUID指定挂载设备
-B:绑定目录到另一个目录上
注意:查看内核追踪到的已挂载的所有设备,cat /proc/mounts
如果我们使用-o参数挂载时,可以去定义挂载文件系统的选项
-o,—option comma-separated list of mount options
async:异步模式
sync:同步模式
atime/moatime:包含目录和文件
diratime/modiratime:目录的访问时间戳
auto/noauto:是否自动挂载
exec/noexec:是否支持将文件系统上的应用程序运行为进程
dev/nodev:是否支持在此文件系统上使用设备文件
suid/nouid:是否支持在此文件系统上使用uid标识
remount:重新挂载
ro
rw
user/nouser:是否允许普通用户挂载此设备
acl:启用此文件系统上的acl功能
注意:以上多个选项可以同时使用,彼此之间需要使用逗号进行分隔
默认挂载选项:defaults
rw,suid,dev,exec,auto,nouser,async
卸载:umount
交换分区操作(Linux下虚拟内存分区,当物理内存使用完后交换分区充当一个虚拟内存来使用,起到缓冲的作用,但速度比物理内存慢得多)
-启用交换分区:swpon
-a:激活所有的交换分区
-p:指明优先级
-关闭交换分区:swpoff(临时关闭)
-a:关闭所有的交换分区
sysctl -p 让系统立即生效
永久关闭:
相关命令:
free命令:查看内存空间使用状态
-m:以MB为单位
-g:以GB为单位
total used free shared buff/cache available
总量 使用量 空闲量 共享 buff/cache使用量 可用量
buff/cache占用内存非常多,导致可用量变少
1.buff/cache的区别
2.如何解决
df命令:文件系统空间占用信息的查看工具
-h
-i
-p:以posix兼容的格式输出
du命令:查看某目录总体空间占比
du [option] dir
-h
-s
dd命令:常用于测试磁盘的IO速度
dd if=/dev/zero of=/dev/null
if:源
of:目的
/dev/zero:吐零机
/dev/null:数据黑洞
bs=#:指定复制单元大小
count=#:指定多个bs
磁盘拷贝:dd if=/dev/sda of=/dev/sdb
备份MBR(主引导记录):dd if=/dev/sda of=/tmp/mbr.bak bs= count=
RAID技术
-RAID:磁盘阵列(Redundant arrays of independent drives)
优点:
提高磁盘IO能力:磁盘并行读写
提高耐用性:磁盘冗余来实现
RAID0 RAID1 RAID5
实现方式
级别:将多块硬盘组织在一起进行的工作方式
硬RAID:通过硬件支持RAID工作方式
外接式磁盘阵列:通过扩展卡提供适配器功能
内解释RAID:主板上集成了RAID控制
软RAID:通过软件的方式模拟RAID(在实际生产环境中意义不大)
级别:
RAID0
读写性能提升
可用空间:Nmin(N指磁盘数量,min指最小的磁盘大小)
无冗余特性(一份数据被写在多个磁盘中,磁盘的损坏会导致数据的完整性收到破坏)和容错特性
磁盘数量:2+
RAID1
读性能提升,但是写性能略微下降(数据写入需在所有磁盘上写入完整的数据内容,因此每块磁盘上都有数据的完整内容,提升读性能,降低写性能)
可用空间:1min(min指真正写入的那块磁盘大小)
拥有冗余特性:最多坏一个盘(每块磁盘上都有完整数据内容,损坏其中一块不会影响数据的完整性)
磁盘数量:2+
RAID4
读性能提升,但是写性能略微下降
可用空间:Nmin(排除校验盘)
拥有冗余特性:最多坏一个盘(通过专门的校验盘)
磁盘数量:2+
RAID5
读写性能提升
可用空间:N-1 min
拥有冗余特性:最多坏一个盘(一块盘上都有校验数据,通过其他盘的校验数据,可以将损坏的磁盘的数据恢复)
磁盘数量:4+
RAID6
读写性能提升
可用空间:N-2 min
拥有冗余特性:最多坏两个盘(两盘上都有校验数据,通过其他盘的校验数据,可以将损坏的磁盘的数据恢复)
磁盘数量:4+
RAID01:先做RAID0再做RAID1(先写入数据再进行备份)
读写性能提升
可用空间:Nmin /2
拥有冗余特性:最多坏一个盘
磁盘数量:4+
(同颜色的为一组磁盘)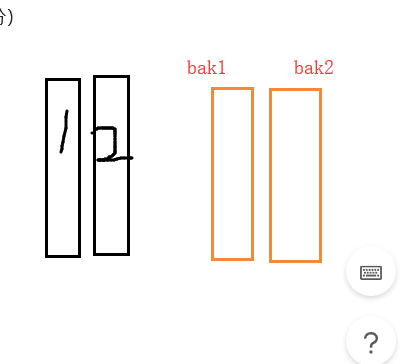
RAID10:先做RAID1再做RAID0(先备份再恢复数据)
读写性能提升
可用空间:N*min /2
拥有冗余特性:最多一块盘
磁盘数量:4+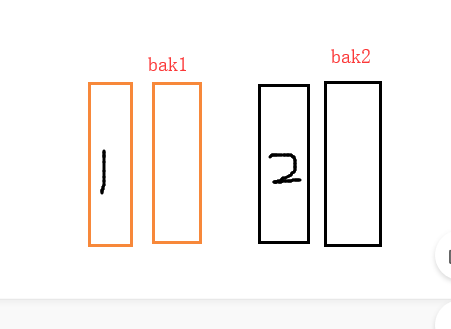
LVM2(Linux volume manager)
lvm逻辑卷管理,在物理设备上进行一层抽象,允许生成逻辑存储卷,相对于物理存储卷来说管理会更加灵活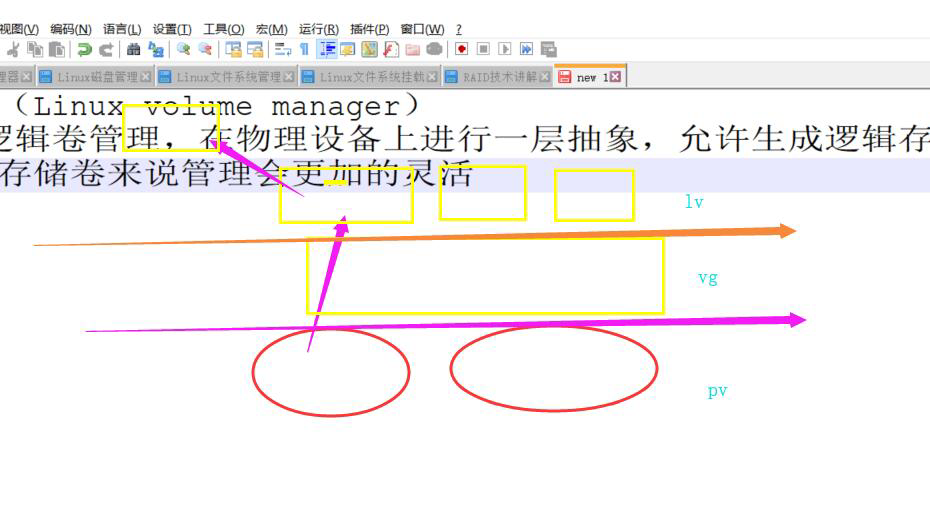
LVM将存储进行虚拟化,不受限于物理存储,不需要卸载文件系统再进行调整卷大小或数据迁移
优点:
灵活
拥有可伸缩的存储池(vg)
在线的数据进行再分配
方便的设备命令
卷快照(snapshot)
基本术语:
物理存储介质(/dev/sda /dev/sdb……)
pv:物理卷,需要将物理存储介质创建为物理卷
vg:卷组,vg是由多个pv组成
lv:逻辑卷,是从相应的vg上创建而来
PE:物理卷被划分为PE的基本单元(默认4MB)
LE:逻辑卷被分为LE的可被寻址的基本单位(同一个卷组中的LE和PE是相同的)
PV管理工具:
pvcreate命令:创建pv
pvcreate
pvs命令:显示PV信息
pvdisplay:显示pv的详细信息
vg管理工具
vgs:显示vg信息
vgdisplay:显示vg详细信息属性
vgcreate:创建vg
vgcreate
vgextend:扩展vg
vgreduce:缩减vg
lv管理工具
lvs
lvdisplay
lvcreate:创建lv
create -L #[mMgGtT] -n NAME
lvremove:删除lv
lvremove /dev/volumeGroupName/lvname
扩展逻辑卷
lvextend -L [#|+][mMgGtT] /dev/VG_NAME/LV_NAME
resizefs /dev/vg_name/lvname #使扩容生效
缩减逻辑卷
umount /dev/VG_NAME/LV_NAME
e2fsck -f /dev/VG_NAME/LV_NAME
lvreduce -L [#|+][mMgGtT] /dev/VG_NAME/LV_NAME
resizefs /dev/VG_NAME/LV_NAME # 让缩减生效
mount
快照:
任意时刻卷中的数据状态
创建快照:lvcreate -L #[mMgGtT] -s -n snapshot_name original_lv_name
创建后的快照可以直接被使用(mount),但是随着源数据量的增加,快照可能会增大
恢复快照:dd of=/path/to/snapshot_name if=/path/to/snapshot.bak
1. 创建一个至少有两个PV组成的大小为20G名为testvg的VG;要求PE大小为16MB,然后在卷组中创建大小为5G的逻辑卷testlv,挂载至/users目录
2. 新建用户eagle,家目录为/users/eagle/,然后切换至centos用户,复制/etc/fstab文件至自己的家目录
3. 扩展testlv至7G,要求eagle用户的文件不能丢失
4. 收缩testlv至3G,要求eagle用户的文件不能丢失
5. 对testlv创建快照,并尝试基于快照备份数据,验证快照的功能
总练习
- 创建一个至少有两个PV组成的大小为20G名为testvg的VG;要求PE大小为16MB,然后在卷组中创建大小为5G的逻辑卷testlv,挂载至/users目录
2. 新建用户eagle,家目录为/users/eagle/,然后切换至centos用户,复制/etc/fstab文件至自己的家目录
3. 扩展testlv至7G,要求eagle用户的文件不能丢失
4. 收缩testlv至3G,要求eagle用户的文件不能丢失
5. 对testlv创建快照,并尝试基于快照备份数据,验证快照的功能

若有收获,就点个赞吧
0 人点赞
