MySQL:关系型数据库(每个字段都会约束条件);它数据通过DBMS数据库管理系统最终存放在硬盘上
redis:非关系型数据库;他的数据是存放在内存上的,所以他的访问速度非常快
介绍:redis是一个用C语言写的,开源key-value数据库。和memcached类似
支持存储value数据类型较多
(五大基本数据类型:string hash list set集合 zset有序集合)
高级数据类型:herploglog GEO Bitmaps等等
这些数据类型支持push/pop或者add/remove等操作,并且这些操作都是原子性的,在此基础上,redis支持各种方式的排序,为了保证效率,和memcached一样,数据都是缓存在内存中的,区别在于:redis可以周期性的把更新数据写入磁盘或者追加到记录文件中,并且redisy拥有高可用方案(master-slaver—>sentinel—>redis cluster)
特性:速度快、支持丰富的数据类型、支持事务、丰富的特性
安装方式:
- 二进制安装
- yum包安装:yum install redis -y
rpm -ql redis
/etc/redis-sentinel.conf #redis sentinel哨兵集群的主配置文件
/etc/redis.conf #redis server的主配置文件
/usr/bin/redis-benchmark #redis性能检测工具
/usr/bin/redis-check-aof #AOF文件修复工具
/usr/bin/redis-check-rdb #RDB文件修复工具
/usr/bin/redis-cli #redis客户端工具
/usr/bin/redis-sentinel #redis sentinel服务端工具
/usr/bin/redis-server #redis-server服务端工具
/usr/lib/systemd/system/redis-sentinel.service #redis sentinel守护进程
/usr/lib/systemd/system/redis.service #redis-server守护进程
启动redis服务:redis-server命令
使用方式:
指定redis-server主配置文件(默认/etc/redis.conf)
连接:redis-cli
127.0.0.1:6379>
关闭redis服务:redis-cli shutdown
配置文件:
[root@localhost etc]# cat /etc/redis.conf | grep -Ev “^$|^#”
bind 127.0.0.1 #redis server绑定的IP地址
protected-mode yes #redis-server守护模式启动和关闭
port 6379 #监听的端口号
tcp-backlog 511 #客户端连接(基于TCP协议)的最大数量
timeout 0 #设置客户端连接超时时间,0表示没有超时时间
tcp-keepalive 300 #TCP连接保持时间为300s
daemonize no #是否以守护进程方式在后端启动
supervised no #
pidfile /var/run/redis_6379.pid #PID文件
loglevel notice #日志等级
logfile /var/log/redis/redis.log #日志文件
databases 16 #数据库实际的数量
#配置触发redis的持久化条件
save 900 1
save 300 10
save 60 10000
stop-writes-on-bgsave-error yes #当启用RDB时,最后一次记录文件失败,redis是否停止接收数据
rdbcompression yes #是否对RDB文件进行压缩存储
rdbchecksum yes #是否对RDB文件进行数据校验
dbfilename dump.rdb #设置RDB文件名
dir /var/lib/redis #设置RDB文件的存放路径
#redis从服务器及复制相关配置
slave-serve-stale-data yes
slave-read-only yes
repl-diskless-sync no
repl-diskless-sync-delay 5
repl-disable-tcp-nodelay no
slave-priority 100
appendonly no #是否开启AOF持久化功能,默认不开启,只使用RDB持久化
appendfilename “appendonly.aof” #AOF文件名
appendfsync everysec #AOF持久化策略
no-appendfsync-on-rewrite no #在AOF重写或者写入RDB文件时,不执行持久化策略
auto-aof-rewrite-percentage 100 #当前AOF文件超过上一次重写的AOF文件的百分之多少进行重写操作
auto-aof-rewrite-min-size 64mb #AOF文件重写的最小数据量
aof-load-truncated yes #当截断的AOF文件被导入的时候,会自动发布一个log给客户端后才进行load
lua-time-limit 5000 #lua脚本执行的超时时间
slowlog-log-slower-than 10000 #慢日志查询的超时时间
slowlog-max-len 128 #慢日志的最大长度
latency-monitor-threshold 0
notify-keyspace-events “”
#关于数据类型内部编码ziplist的相关配置
hash-max-ziplist-entries 512
hash-max-ziplist-value 64
list-max-ziplist-size -2
list-compress-depth 0
set-max-intset-entries 512
zset-max-ziplist-entries 128
zset-max-ziplist-value 64
hll-sparse-max-bytes 3000
activerehashing yes
#关于客户端输出缓冲区限制的相关配置
client-output-buffer-limit normal 0 0 0
client-output-buffer-limit slave 256mb 64mb 60
client-output-buffer-limit pubsub 32mb 8mb 60
hz 10
aof-rewrite-incremental-fsync yes #AOF重写策略sync是否开启
redis数据类型
字符串
key—-value一一对应
set
127.0.0.1:6379> set k1 v1
OK
get
127.0.0.1:6379> get k1
“v1”
mset
127.0.0.1:6379> mset k1 v1 k2 v2 k3 v3 k4 v4
OK
mget
127.0.0.1:6379> mget k1 k2 k3 k4
1) “v1”
2) “v2”
3) “v3”
4) “v4”
setex
127.0.0.1:6379> setex k5 10 v5
OK
ttl
127.0.0.1:6379> ttl k5
(integer) 7
127.0.0.1:6379> ttl k5
(integer) 4
127.0.0.1:6379> ttl k5
(integer) 3
127.0.0.1:6379> ttl k5
(integer) 1
127.0.0.1:6379> ttl k5
(integer) -2
127.0.0.1:6379> get k5
(nil)
setnx 判断键是否存在,存在返回0,不存在返回1并操作
127.0.0.1:6379> setnx k1 v11
(integer) 0
127.0.0.1:6379> setnx k11 v11
(integer) 1
incr #加一
127.0.0.1:6379> incr k1
(integer) 11
decr #减1
127.0.0.1:6379> decr k1
(integer) 10
incrby
127.0.0.1:6379> incrby k1 100
(integer) 110
decrby
127.0.0.1:6379> decrby k1 50
(integer) 60
strlen
字符串应用场景:
缓存功能:加速读写和降低后端压力的作用
计数:视频播放次数等
共享session:分布式web服务器需要将用户的session信息保存在各自的服务器中
限速:限制用户每分钟获取验证码的频率
hash
hset
127.0.0.1:6379> hset user1 name zhangsan
(integer) 1
127.0.0.1:6379> hset user1 age 1
(integer) 1
127.0.0.1:6379> hset user1 sex m
(integer) 1
hget
127.0.0.1:6379> hget user1 name
“zhangsan”
127.0.0.1:6379> hget user1 age
“1”
127.0.0.1:6379> hget user1 sex
“m”
hdel
127.0.0.1:6379> hdel user1 name
(integer) 1
127.0.0.1:6379> hget user1 name
(nil)
hexists
127.0.0.1:6379> hexists user1 name
(integer) 0
127.0.0.1:6379> hexists user1 age
(integer) 1
hgetall
127.0.0.1:6379> hgetall user1
1) “age”
2) “1”
3) “sex”
4) “m”
hkeys
127.0.0.1:6379> hkeys user1
1) “age”
2) “sex”
hlen
127.0.0.1:6379> hlen user1
(integer) 2
list
lpush #从列表的头部压入数据
127.0.0.1:6379> lpush list1 a b c d e f
(integer) 6
lpushx #先判断列表是否存在,不存在则不做操作
lindex #列出指定位置的值
127.0.0.1:6379> lindex list1 0
“d”
lrange #列出列表的值
127.0.0.1:6379> lrange list1 0 -1
1) “d”
2) “c”
3) “b”
lset #修改列表中某个位置的值
127.0.0.1:6379> lset list1 0 D
OK
lpop #弹出头元素
127.0.0.1:6379> lpop list1
“f”
127.0.0.1:6379> lpop list1
“e”
rpop #弹出尾元素
127.0.0.1:6379> rpop list1
“a”
rpush #从列表的尾部压入数据
列表使用场景:
- 消息队列:redis的lpush+rpop可以实现阻塞队列
-
集合
sadd #将元素添加到集合中
127.0.0.1:6379> sadd set1 1 2 3 4 5 6 7
(integer) 7
sdiff #差集
sinter #交集
sunion #并集
smembers #遍历集合的所有元素
127.0.0.1:6379> smembers set1
1) “1”
2) “2”
3) “3”
4) “4”
5) “5”
6) “6”
7) “7”
spop #随机移除集合的元素
127.0.0.1:6379> spop set1
“1”
127.0.0.1:6379> spop set1
“6”
srem #移除集合的指定元素
127.0.0.1:6379> smembers set1
1) “2”
2) “3”
3) “4”
4) “5”
5) “7”
127.0.0.1:6379> srem set1 4
(integer) 1
127.0.0.1:6379> smembers set1
1) “2”
2) “3”
3) “5”
4) “7”
使用场景: 标签:一个用户喜欢娱乐和体育,另一个用户喜欢历史和新闻,有这些数据就可以得到喜欢同一个标签的用户
注意:用户和标签的关系维护应该在一个事务内执行,防止部分命令失败造成的数据不一致
有序集合
zadd
127.0.0.1:6379> zadd page 10 google.com
(integer) 1
127.0.0.1:6379> zadd page 9 baidu.com
(integer) 1
127.0.0.1:6379> zadd page 8 bing.com 7 ing.com
(integer) 2
zrange
127.0.0.1:6379> zrange page 0 -1 withscores
1) “ing.com”
2) “7”
3) “bing.com”
4) “8”
5) “baidu.com”
6) “9”
7) “google.com”
8) “10”
127.0.0.1:6379> zrange page 0 -1
1) “ing.com”
2) “bing.com”
3) “baidu.com”
4) “google.com”
zcount
127.0.0.1:6379> zcount page 8 10
(integer) 3
zcard
127.0.0.1:6379> zcard page
(integer) 4
zrank
127.0.0.1:6379> zrank page ing.com
(integer) 0
127.0.0.1:6379> zrank page baidu.com
(integer) 2
应用场景:
排行榜系统:点赞用户前10名等
redis高级数据类型
hyperloglog-统计集合的基数(数量)
一种基数算法,实际数据类型为字符串类型,利用极小的内存空间完成独立总数的统计
hyperloglog内存占用特别小,但是存在错误率,选型满足以下两个条件即可:
- 只为计算独立总数,不需要获取单条数据
- 可以容忍一定误差率
127.0.0.1:6379> pfadd database redis mysql mongodb
(integer) 1
127.0.0.1:6379> pfcount database
(integer) 3
127.0.0.1:6379> pfadd nosql redis mysql memcached
(integer) 1
127.0.0.1:6379> pfmerge nosql database
OK
127.0.0.1:6379> pfcount database
(integer) 3
127.0.0.1:6379> pfcount nosql
(integer) 4
GEO地理位置
地理信息定位功能,支持存储地理位置信息来实现诸如附近位置,摇一摇这类依赖于地理位置信息的功能
127.0.0.1:6379>geoadd sicily 107.363247 22.41597 me
127.0.0.1:6379> geoadd sicily 108.395622 28.007929 pig
(integer) 1
127.0.0.1:6379> geodist sicily me pig
“630578.2896”
127.0.0.1:6379> geodist sicily me pig km
“630.5783”
127.0.0.1:6379> georadius sicily 107 22 100 km
1) “me”
127.0.0.1:6379> geopos sicily me
1) 1) “107.36324518918991089”
2) “22.41597006212879251”
127.0.0.1:6379> georadiusbymember sicily me 100 km
1) “me”
127.0.0.1:6379> geohash sicily me you
1) “w7ure0ew2z0”
2) “wkvtsy4xm20”
位图bitmaps
bitmaps想象成一个以位为单位的数组,数组的每个单元只能存储0和1,数组的下标在bitmaps中叫做偏移量
127.0.0.1:6379> setbit 2020-04-01 1 1
(integer) 0
127.0.0.1:6379> setbit 2020-04-01 1 1
(integer) 1
127.0.0.1:6379> setbit 2020-04-01 3 1
(integer) 0
127.0.0.1:6379> setbit 2020-04-01 5 1
(integer) 0
127.0.0.1:6379> getbit 2020-04-01 2
(integer) 0
127.0.0.1:6379> getbit 2020-04-01 3
(integer) 1
127.0.0.1:6379> bitcount 2020-04-01
(integer) 3
127.0.0.1:6379> setbit 2020-04-02 3 1
(integer) 0
127.0.0.1:6379> bitop and 2020-04-01 2020-04-02
(integer) 1
订阅发布
发送消息:publish chatroom “hello”
接收消息:subscribe chatroom
其他命令
exist
redis持久化:RDB和AOF
RDB持久化
把内存中的数据集快照写入磁盘当中,也就是snapshot快照(数据库中所有的键值数据),恢复时是将快照文件直接读到内存中即可
RDB触发方式
手动触发:save命令()(已经被丢弃,因为会造成严重的堵塞)——->bgsave命令()
为什么SAVE命令被丢弃? save命令执行一个同步保存操作,会阻塞其他客户端的请求
自动触发:主配置文件中的save字段(调用bgsave命令进行rdb快照操作)
RDB执行流程
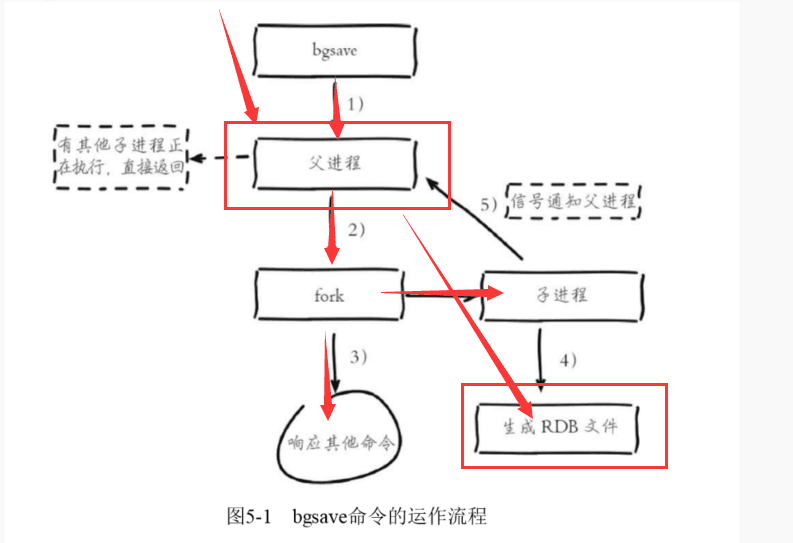
- 执行bgsave命令,判断当前是否有其他子进程正在执行任务;如果有,则直接返回
- 如果没有则父进程会fork()一个子进程——>会发生毫秒级别的堵塞(很小)
- 当父进程创建完子进程之后,父进程继续响应客户端请求
- 子进程负责生成RDB文件的任务
- 当子进程完成任务之后,通知父进程即可
RDB的文件处理
保存:RDB文件保存在dir配置指定的目录下通过配置文件的方式,在redis服务启动中: 若redis服务已经启动,支持动态修改保存配置:
压缩:redis默认采用LZF算法对生成的RDB文件做压缩处理,压缩后的文件远远小于内存大小,默认开启
检验:如果redis加载损坏的RDB文件时,会拒绝启动(redis-check-dump工具检测RDB文件获取错误报告)
恢复:将备份文件(dump.rdb)移动到redis安装目录dir配置指定的启动服务即可,因为redis会自动加载文件数据到内存中
注意:rdb启动时载入时的文件名称及路径
停止RDB持久化
有的情况下,我们只想利用redis缓存功能,那么这时候最好停掉RDB持久化
注释save行的相关参数
#config set dbfilename rdb1.rdb
#config set dir /tmp/
手动停用:bgsave “”
RDB的优点
- 我们加载rdb文件到数据库内存中的效率会提升,RDB恢复比AOF方式要快(RDB文件进行压缩处理)
RDB文件代表的是数据库某个时间点的数据集快照,适合全量备份及容灾的场景
RDB的缺点
无法做到实时/秒级实体化,因为每次bgsave都会让主进程fork()出一个子进程;
- RDB文件使用二进制格式保存,随着版本演进,可能存在rdb文件不兼容;
- 在一定时间间隔做一次备份,如果redis意外down掉,就会丢失最后一次快照所有修改;
ps:属于重量级操作(内存中的数据被克隆了一份,大致2倍的膨胀性需要考虑),频繁执行成本过高(影响性能)
copy-on-write:写时复制技术,采用共享内存的方式交由子进程完成RDB文件生成任务;
当主进程接收到客户端的更新操作,会将要修改的数据集copy一份到新开辟的内存中,等待子进程完成任务之后,将新内存中的更新后的数据同步到原内存中
AOF持久化
AOF持久化方式是通过保存redis服务器所执行的更新命令来记录数据库状态
AOF触发方式
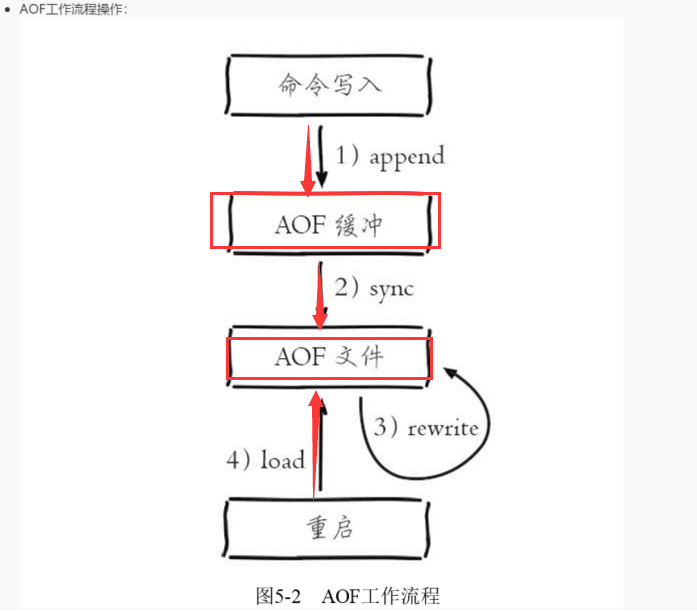
- 所有的写入命令会追加到aof_buf(缓冲区)中
- AOF缓冲区根据策略向磁盘做同步操作
- 随着AOF文件越来越大,需要定期对AOF文件进行重写,达到压缩目的
-
AOF缓存策略
同步文件,redis提供多种AOF缓冲区同步文件策略,由appendfsync控制
always:调用系统fsync操作同步到AOF文件,完成后线程返回
- everysec:调用write操作,完成后线程返回;fsync同步文件操作由专门线程每秒调用一次(重点)
no:调用write操作,不对AOF文件做fsync同步,同步硬盘操作由操作系统负责,通常同步周期最长10s
AOF重写流程
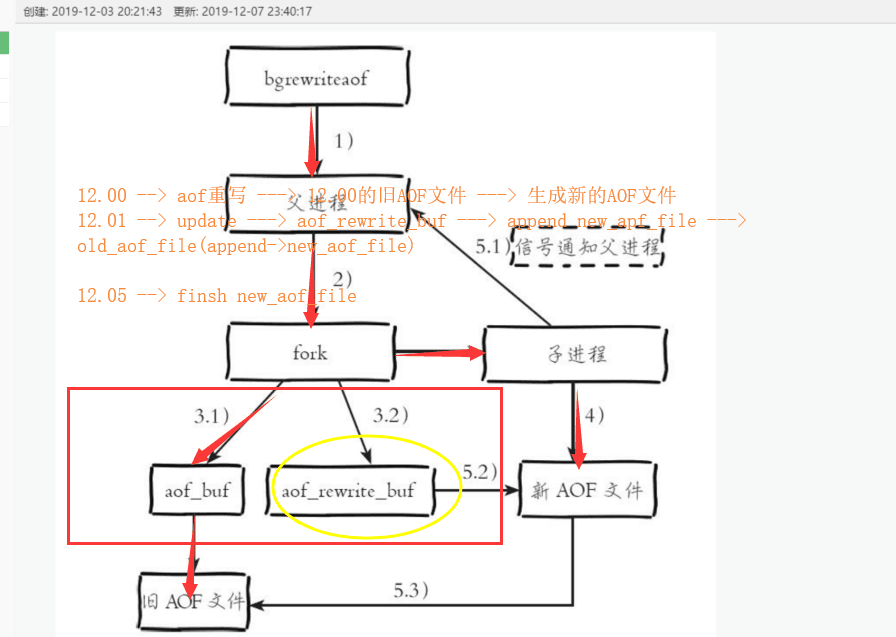
执行AOF重写请求
- 当前进程正在执行AOF重写,此次请求不执行
- 当前进程正在执行bgsave操作,重写命令延迟到bgsave命令完成之后再执行
- 父进程执行fork创建子进程,开销等同于bgsave过程
- fork操作完成以后,继续相应其他的命令,所有修改命令依然写入AOF缓冲区并根据appendfsync策略同步到硬盘
- 由fork操作运行写时复制技术,父进程依然响应命令,redis使用AOF重写缓冲区保存这部分新数据,防止新的AOF生成期间丢失这部分数据
- 子进程根据内存快照,按照命令合并规则写入到新的AOF文件中,每次批量写入硬盘数据量aof-rewrite-increamental-fsync控制,默认为32MB,防止单次磁盘数据过多造成硬盘堵塞
- 新AOF文件写入完成后,子进程发送信号给父进程,父进程更新统计信息
- 父进程把AOF重写缓冲区的数据写入到新的AOF文件
-
AOF优点
能够实现秒级或者实时实体化存储,使用默认的同步策略,redis最多就是丢失(1+1(判断机制等待1s))s数据
AOF文件使用追加命令的形式进行构造,所以可读性强,能够针对文件本身进行恢复
AOF缺点
具有相同数据的redis,AOF文件体积会大于RDB
- 在redis负载比较高的情况下,RDB比AOF具有更好的性能保障
- RDB使用快照的方式相对于AOF追加命令的方式来说,理论上更加健壮
备份及恢复
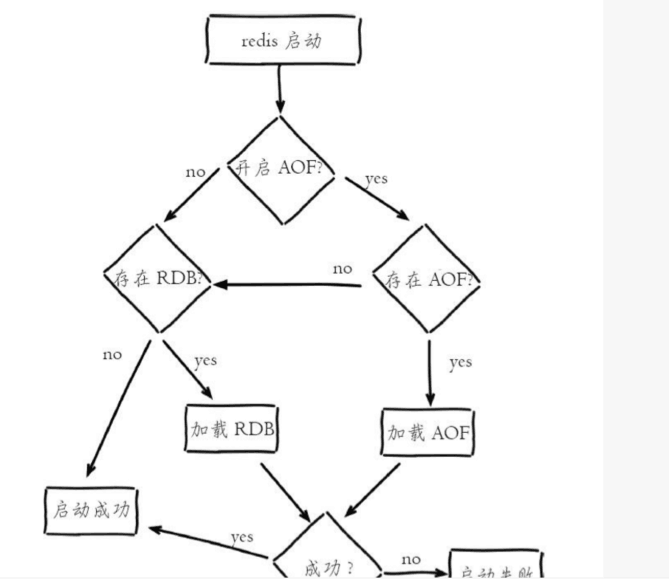
redis服务如何加载持久化文件?
- AOF持久化开启且存在AOF文件时,优先加载AOF文件
- AOF关闭或者AOF文件不存在时,加载RDB文件
- 加载AOF/RDB文件成功后,redis启动成功
- AOF/RDB文件存在错误时,redis启动失败
复制原理
复制方式
全量复制:redis全量复制发生slave节点初始化节点阶段,这时候slave需要将master上所有数据都复制一份,这样来保证数据的一致性,步骤:
- slave服务器连接master服务器,发送sync命令
- master服务器收到sync命令之后,开始执行bgsave命令生成RDB文件
- master服务器完成bgsave命令之后,向slave服务器发送rdb快照文件
- slave服务器接收到RDB快照文件后,丢弃所有旧数据,载入RDB文件
- master在生成rdb文件及发送rdb文件的过程中,会继续响应客户端的请求,所有更新操作会记录到缓冲区中,当RDB文件发送完成后,将缓冲区中的这些命令发送给slave服务器
- slave服务器执行master发送的缓冲区,完成复制操作
增量(部分)复制:slave初始化后开始正常工作,此时master服务器发生的更新操作同步到slave服务器的过程
增量复制过程主要是master服务器每执行一个写命令就会向slave服务器发送相同的命令,slave接受并执行
以上也是redis主从架构的复制原理
缺点:
- master服务器出现问题,就不能提供服务了,需要人工修改配置将slave服务器提升为master服务器
- 主从复制,master服务器成为写操作的瓶颈
- 单机节点的存储能力有限
部署redis主从架构
通过配置文件方式
节点规划
master:127.0.0.1 6380
slave1: 127.0.0.1 6381
slave2: 127.0.0.1 6382
建议:因为我们这里是测试环境,在同一台物理机上,生产环境肯定要部署在不用的物理机上
[root@localhost ~]# cat redis.sh
#!/bin/bash
mkdir /usr/local/redis/{data,conf,log} -pv
cat << EOF > /usr/local/redis/conf/redis6380.conf
bind 127.0.0.1
port 6380
daemonize yes
pidfile /usr/local/redis/redis_6380.pid
loglevel notice
logfile /usr/local/redis/log/redis_6380.log
dir /usr/local/redis/data/
EOF
cat << EOF > /usr/local/redis/conf/redis6381.conf
bind 127.0.0.1
port 6381
daemonize yes
pidfile /usr/local/redis/redis_6381.pid
loglevel notice
logfile /usr/local/redis/redis_6381.log
dir /usr/local/redis/data/
slaveof 127.0.0.1 6380
EOF
cat << EOF > /usr/local/redis/conf/redis6382.conf
bind 127.0.0.1
port 6382
daemonize yes
pidfile /usr/local/redis/redis_6382.pid
loglevel notice
logfile /usr/local/redis/redis_5382.log
dir /usr/local/redis/data/
slaveof 127.0.0.1 6380
EOF
redis-server /usr/local/redis/conf/redis6380.conf
redis-server /usr/local/redis/conf/redis6381.conf
redis-server /usr/local/redis/conf/redis6382.conf
哨兵模式
- 解决主从复制的缺点
- 当主节点发生故障的时候,由redis sentinel自动完成故障的发现和转移,并且通知给应用方,实现高可用
工作原理:
- 每个哨兵会向其他哨兵、主服务器、从服务器定时发送消息,以确认对方是否还活着,如果发现对方在指定时间内没有回应,则暂时认为对方已经挂了;若哨兵群中的多数哨兵认为该节点挂了,才真正认为彻底下线
主观下线:某个哨兵发现master挂掉了,就认为master暂时下线
客观下线:如果整个哨兵群的多数发现master挂掉了,就认为master真正下线
客观下线只针对:发现挂掉的节点是master
发现master挂掉之后,通过一定的算法,从剩下的slave节点中选取一台提升为master服务,然后自动修改相关配置
哨兵的数量一般大于等于3个,并且为奇数
缺点:redis对于在线扩容比较困难,并且在集群容量达到上限时在线扩容会非常复杂
解决方案:redis cluster分布式解决方案
[root@localhost ~]# cat shaobing.sh
#!/bin/bash
cat << EOF > /usr/local/redis/conf/redis-sentinel-26378.conf
port 26378
daemonize yes
dir “/tmp”
sentinel monitor mymaster 127.0.0.1 6380 1
sentinel down-after-milliseconds mymaster 6000
sentinel failover-timeout mymaster 18000
logfile “/usr/local/redis/log/sentinel.log.26378”
EOF
cat << EOF > /usr/local/redis/conf/redis-sentinel-26379.conf
port 26379
daemonize yes
dir “/tmp”
sentinel monitor mymaster 127.0.0.1 6380 1
sentinel down-after-milliseconds mymaster 6000
sentinel failover-timeout mymaster 18000
logfile “/usr/local/redis/log/sentinel.log.26379”
EOF
cat << EOF > /usr/local/redis/conf/redis-sentinel-26380.conf
port 26380
daemonize yes
dir “/tmp”
sentinel monitor mymaster 127.0.0.1 6380 1
sentinel down-after-milliseconds mymaster 6000
sentinel failover-timeout mymaster 18000
logfile “/usr/local/redis/log/sentinel.log.26380”
EOF
redis-sentinel /usr/local/redis/conf/redis-sentinel-26378.conf
redis-sentinel /usr/local/redis/conf/redis-sentinel-26379.conf
redis-sentinel /usr/local/redis/conf/redis-sentinel-26380.conf
redis cluster分布式解决方案
redis的哨兵模式已经能够实现高可用,读写分离等应用场景,但是每台redis节点上都存储着相同的数据,这样对于内存来说是浪费的,redis3.0上加入了cluster模式,实现redis分布式存储,也就是说每台redis节点上存储不用的数据
工作原理:
- 数据对象保存到redis之前经过CRC16哈希到一个node上
- 每个node平均分配slot段,对应着0-16378,slot不能够重复也不能缺失,否则会导致重复存储或无法存储
分布式存储最需要的就是数据该如何平衡存储
redis使用的技术叫做虚拟槽(slot段)
- node之间相互监听,一旦有node退出或者加入,会按照slot为单位做数据的迁移工作
比如node1下线,redis会把node1上负责slot段,平均分摊给node2和node3
缺点:
- 每个node承担着相互监听,高并发数据写入,高并发数据读出,数据分布式存储
优点:
- 将redis的写操作分摊到多个节点上,提供写的并发能力,扩容简单并且数据是分布式存储的
cluster部署实验
二进制安装redis5.0版本
[root@localhost redis-cluster]# cat cluster.sh
#!/bin/bash
mkdir /usr/local/redis-cluster/redis{7000..7005} -pv
touch /usr/local/redis-cluster/redis{7000..7005}/redis.conf
for i in {7000..7005};
do
cat << EOF > /usr/local/redis-cluster/redis$i/redis.conf
daemonize yes
port $i
cluster-enabled yes
cluster-config-file /usr/local/redis-cluster/redis$i/nodes-$i.conf
cluster-node-timeout 5000
appendonly yes
EOF
redis-server /usr/local/redis-cluster/redis$i/redis.conf
done

若有收获,就点个赞吧
0 人点赞
