1、词语计数器
数据文件格式
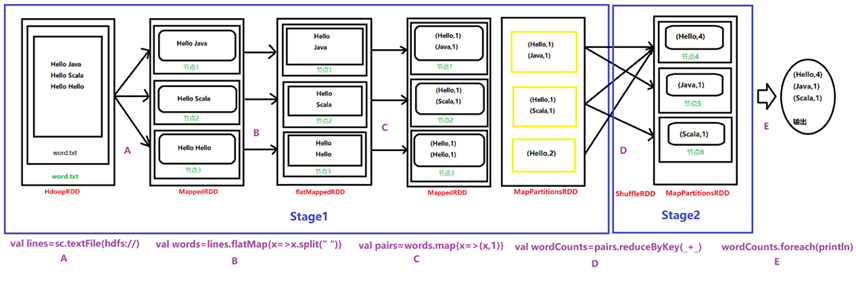
public final class _JavaWordCount {
_private static final _Pattern _SPACE = Pattern.compile(“\s+”);
_public static void _main(String[] args) _throws _Exception {
SparkConf sparkConf = _new _SparkConf()<br /> .setAppName("javaSparkPi")<br /> .setMaster("local")<br /> .set("spark.driver.host", "localhost").set("spark.testing.memory", "21474800000");JavaSparkContext jsc=_new _JavaSparkContext(sparkConf);JavaRDD<String> lines = jsc.textFile("src/main/resources/demo/kdy.txt");<br /> JavaRDD<String> words = lines.flatMap(s -> Arrays._asList_(_SPACE_.split(s)).iterator());JavaPairRDD<String, Integer> ones = words.mapToPair(s -> _new _Tuple2<>(s, 1));JavaPairRDD<String, Integer> counts = ones.reduceByKey((i1, i2) -> i1 + i2);_List_<Tuple2<String, Integer>> output = counts.collect();<br /> _for _(Tuple2<?,?> tuple : output) {<br /> System._out_.println("输出:"+tuple._1() + ": " + tuple._2());<br /> }<br /> jsc.stop();<br /> }<br />}
2、计算pi
//计算pi
public Map
JavaSparkContext javaSparkContext=_new _JavaSparkContext(sparkConf);_if_(jars!=_null_){<br /> javaSparkContext.addJar(jars);<br /> }_Map_<String, Object> result = _new _HashMap<>();_int _n = 100000 * slices;<br /> _List_<Integer> l = _new _ArrayList<>(n);<br /> _for _(_int _i = 0; i < n; i++) {<br /> l.add(i);<br /> }JavaRDD<Integer> dataSet = javaSparkContext.parallelize(l, slices);_int _count = dataSet.map(integer -> {<br /> _double _x = Math._random_() * 2 - 1;<br /> _double _y = Math._random_() * 2 - 1;<br /> _return _(x * x + y * y <= 1) ? 1 : 0;<br /> }).reduce((integer, integer2) -> integer + integer2);System._out_.println("Pi is roughly " + 4.0 * count / n);<br /> result.put("Pi is roughly:" ,4.0 * count / n);javaSparkContext.stop();<br /> _return _result;<br />}
3、topk
public Map
JavaSparkContext javaSparkContext=_new _JavaSparkContext(sparkConf);_if_(jars!=_null_){<br /> javaSparkContext.addJar(jars);<br /> }_Map_<String, Object> result = _new _HashMap<>();_//JavaRDD<String> data = javaSparkContext.textFile("hdfs://mini1:9000/3.txt");//读取hdfs文件<br /> //JavaRDD<String> data = sc.textFile("C:\3.txt");//读取本地文件<br /> //JavaRDD<Object> data = sc.parallelize(new ArrayList<>());//读取内存,将list转化为rdd 这个rdd为空,需要提前存入数据在转化//text.File 按行读取本地文件<br /> _JavaRDD<String> lines = javaSparkContext.textFile(path).cache();System._out_.println();<br /> System._out_.println("-------------------------------------------------------");_//行数<br /> _System._out_.println(lines.count());result.put("总行数",lines.count());JavaRDD<String> words = lines.flatMap(str -> Arrays._asList_(str.split("\\s+")).iterator());System._out_.println();<br /> System._out_.println("-------------------------------------------------------");<br /> System._out_.println(words);JavaPairRDD<String, Integer> ones = words.mapToPair(str -> _new _Tuple2<String, Integer>(str, 1));JavaPairRDD<String, Integer> counts = ones.reduceByKey((Integer i1, Integer i2) -> (i1 + i2));System._out_.println();<br /> System._out_.println("-------------------------------------------------------");<br /> System._out_.println(counts.countByValue());<br /> System._out_.println(counts.countByKey());JavaPairRDD<Integer, String> temp = counts.mapToPair(tuple -> _new _Tuple2<Integer, String>(tuple._2, tuple._1));JavaPairRDD<String, Integer> sorted = temp.sortByKey(_false_).mapToPair(tuple -> _new _Tuple2<String, Integer>(tuple._2, tuple._1));System._out_.println();<br /> System._out_.println("-------------------------------------------------------");<br /> System._out_.println(sorted.count());_<br />_ List_<Tuple2<String, Integer>> output = sorted.top(k,_new _MyComparator());_for _(Tuple2<String, Integer> tuple : output) {<br /> result.put(tuple._1(), tuple._2());<br /> }<br /> javaSparkContext.stop();<br /> _return _result;<br /> }

若有收获,就点个赞吧
0 人点赞
