中文官方文档学习链接:http://spark.apachecn.org/#/
外文官方文档:http://spark.apache.org/docs/latest/quick-start.html
java APi:http://spark.apache.org/docs/latest/api/java/index.html
1、概述
Apache Spark? 是一个快速的,用于海量数据处理的通用引擎。
2、本地快速运行一个单词计数器
(对于给定的一个文档,计算每个词语出现的次数)
初始化一个springboot 项目或者maven项目
1、以快速创建springboot项目为例,打开快速构建springboot项目的链接
命名项目名称,选择java版本8 添加lombok依赖和web依赖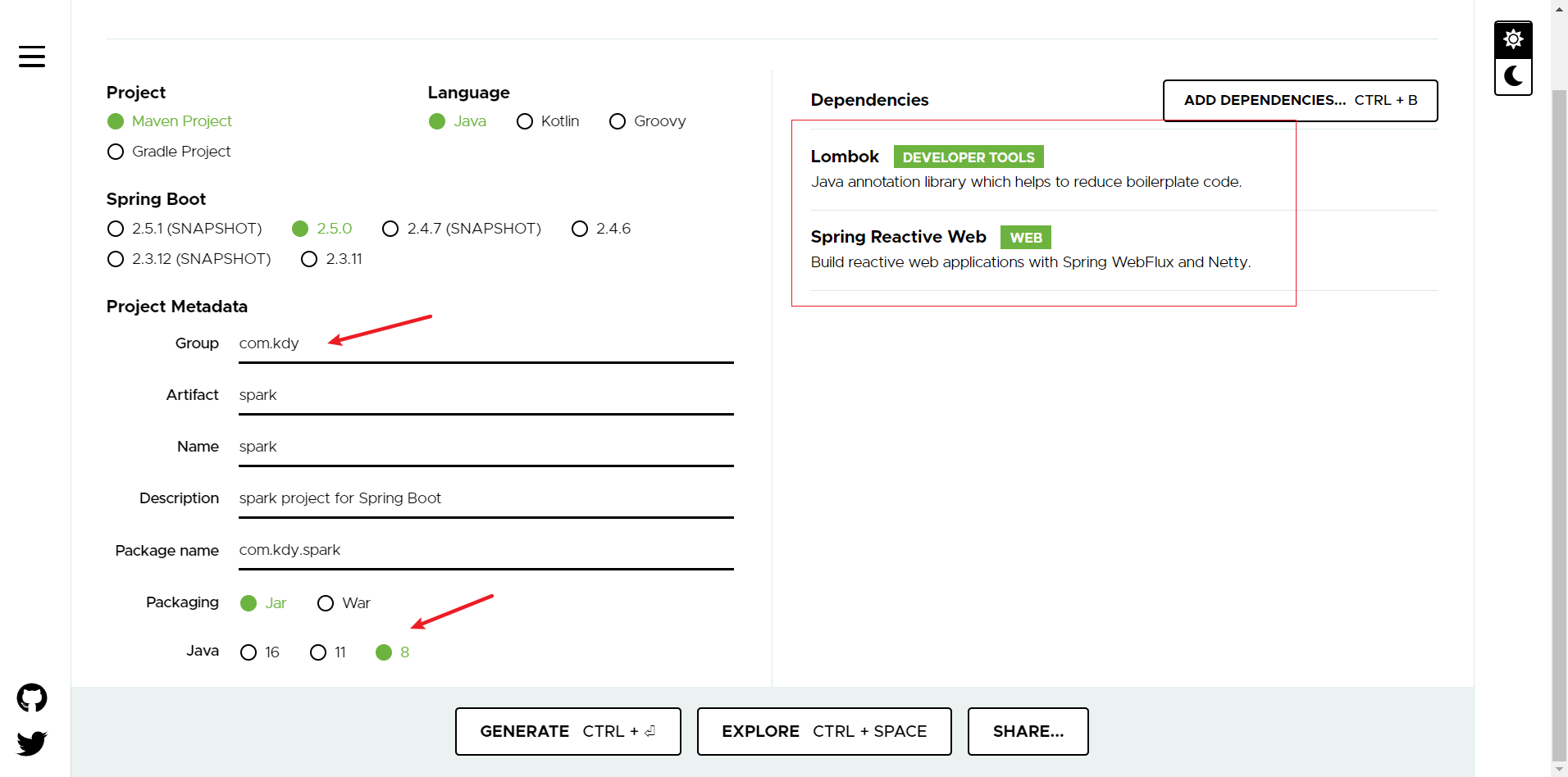
2、用idea 打开项目,项目会自动下载依赖,等待依赖下载完成,检查项目的jdk配置是否是1.8即可 ,点击运行,成功则初始化项目成功
检查项目的jdk版本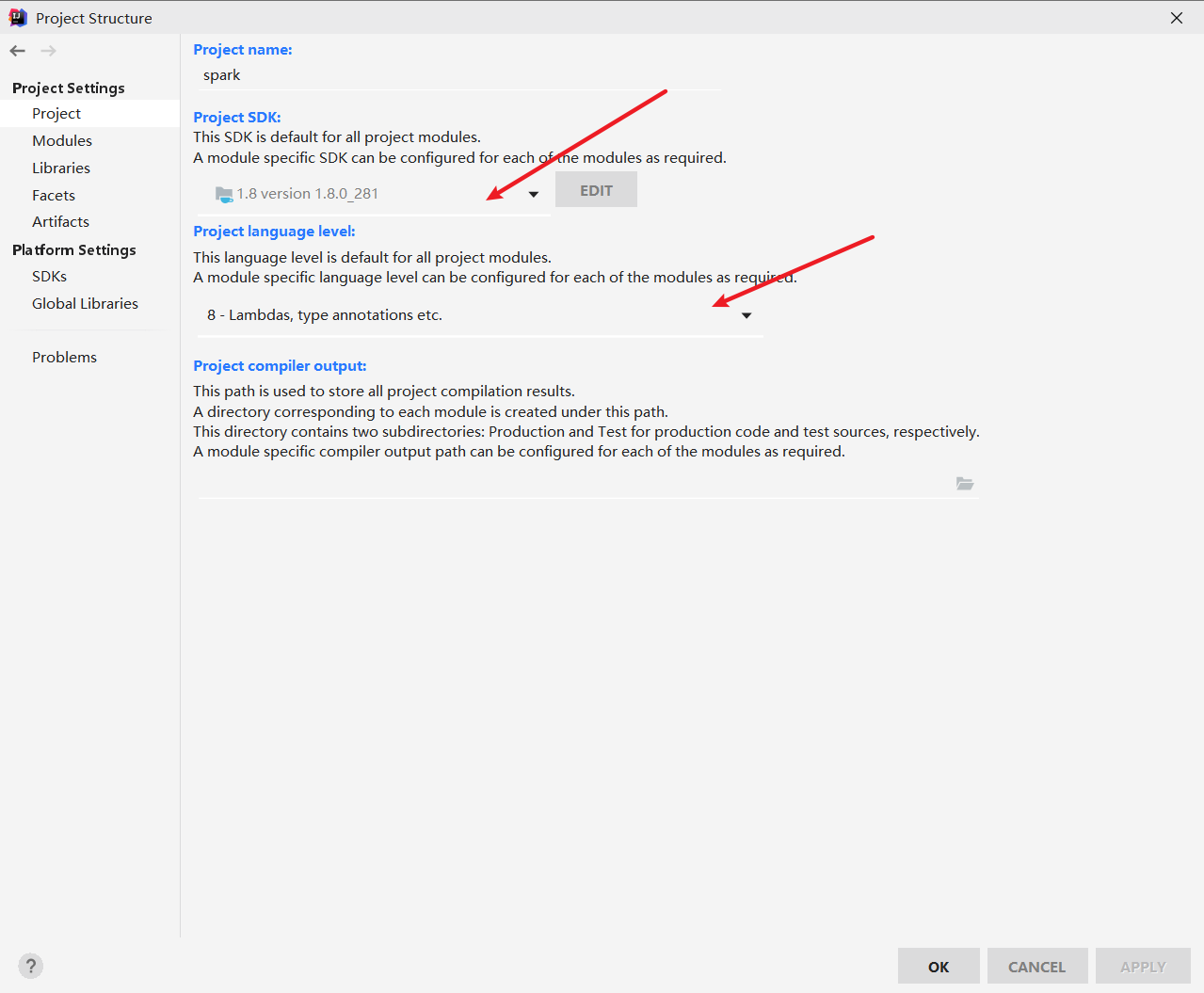
运行成功的界面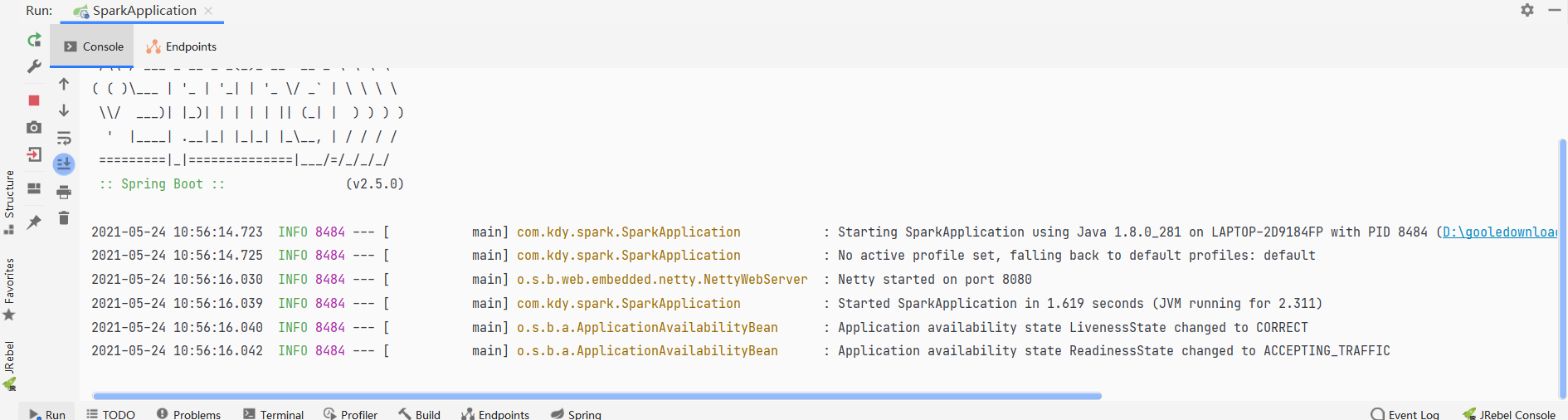
3、导入spark依赖和scala依赖
直接将pom文件下的
以下包括springboot web依赖、lombok依赖、slf4j依赖、spark核心依赖、scala依赖、swagger图形界面化依赖
_
4、创建一个examples包 复制以下代码,右击examples 粘贴会自动创建类
_import _org.apache.spark.SparkConf;
_import _org.apache.spark.api.java.JavaPairRDD;
_import _org.apache.spark.api.java.JavaRDD;
_import _org.apache.spark.api.java.JavaSparkContext;
_import _scala.Tuple2;
import _java.util.Arrays;
_import _java.util._List;
_import _java.util.regex.Pattern;
public final class _JavaWordCount {
_private static final _Pattern _SPACE = Pattern.compile(“\s+”);
_public static void _main(String[] args) _throws _Exception {
SparkConf sparkConf = _new _SparkConf()<br /> .setAppName("javaSparkPi")<br /> .setMaster("local")<br /> .set("spark.driver.host", "localhost").set("spark.testing.memory", "21474800000");JavaSparkContext jsc=_new _JavaSparkContext(sparkConf);JavaRDD<String> lines = jsc.textFile("src/main/resources/demo/kdy.txt");JavaRDD<String> words = lines.flatMap(s -> Arrays._asList_(_SPACE_.split(s)).iterator());JavaPairRDD<String, Integer> ones = words.mapToPair(s -> _new _Tuple2<>(s, 1));JavaPairRDD<String, Integer> counts = ones.reduceByKey((i1, i2) -> i1 + i2);_List_<Tuple2<String, Integer>> output = counts.collect();<br /> _for _(Tuple2<?,?> tuple : output) {<br /> System._out_.println("输出:"+tuple._1() + ": " + tuple._2());<br /> }<br /> jsc.stop();<br /> }<br />}
3、计算pi
(用概率的方式计算圆周率)
选择examples包,复制以下代码,右击examples 粘贴会自动创建类
_/*
Computes an approximation to pi
Usage: JavaSparkPi [partitions]
/
public final class _JavaSparkPi {
_public static void _main(String[] args) _throws _Exception {
SparkConf sparkConf = _new _SparkConf()<br /> .setAppName("javaSparkPi")<br /> .setMaster("local")<br /> .set("spark.driver.host", "localhost").set("spark.testing.memory", "21474800000");JavaSparkContext jsc=_new _JavaSparkContext(sparkConf);_int _slices = (args.length == 1) ? Integer._parseInt_(args[0]) : 2;<br /> _int _n = 100000 * slices;<br /> _List_<Integer> l = _new _ArrayList<>(n);<br /> _for _(_int _i = 0; i < n; i++) {<br /> l.add(i);<br /> }JavaRDD<Integer> dataSet = jsc.parallelize(l, slices);_int _count = dataSet.map(integer -> {<br /> _double _x = Math._random_() * 2 - 1;<br /> _double _y = Math._random_() * 2 - 1;<br /> _return _(x * x + y * y <= 1) ? 1 : 0;<br /> }).reduce((integer, integer2) -> integer + integer2);System._out_.println("Pi is roughly " + 4.0 * count / n);jsc.stop();<br /> }<br />}

若有收获,就点个赞吧
0 人点赞
