1 Spark 运行模式
1.1 Local
1.2 StandLone
1.3 Yarn
企业级常用
2、spark集群搭建(StandLone)
服务器集群
三个集群 一个是master 两个是work
系统:centos7
master 10.10.2.103 /root/spark
work 10.10.2.101 /root/spark
work 10.10.2.102 /root/spark
根据用户名和密码用xshell7 登录三台服务器
目前最新的是spark-3.1.1-bin-hadoop2.7.tgz
下载地址:https://spark.apache.org/downloads.html
(演示用的是spark-3.0.0-bin-hadoop2.7.tgz)
通过xftp7上传到三台服务器
解压
tar -zxvf spark-3.0.0-bin-hadoop2.7.tgz
sbin : 项目启动脚本
bin: 模块启动脚本
conf:配置文件
进入配置文件
slaves.template (主从节点设置,里面放的是从节点ip)
复制并改名
cp slaves.template slaves
cp spark-env.sh.template spark-env.sh
配置spark-env.sh
文末追加java_home
每个java_home 要与实际路径一致
export JAVA_HOME=/usr/java/jdk1.8.0_211export SPARK_MASTER_HOST=10.10.2.103export SPARK_MASTER_PORT=7077
配置slaves
文末去掉locahost 添加两个work节点的ip
10.10.2.101
10.10.2.102
复制文件 到其他两个服务器
主节点上启动 进入sbin 启动脚本 ./start-all.sh
然后输入密码即可
jps 查看 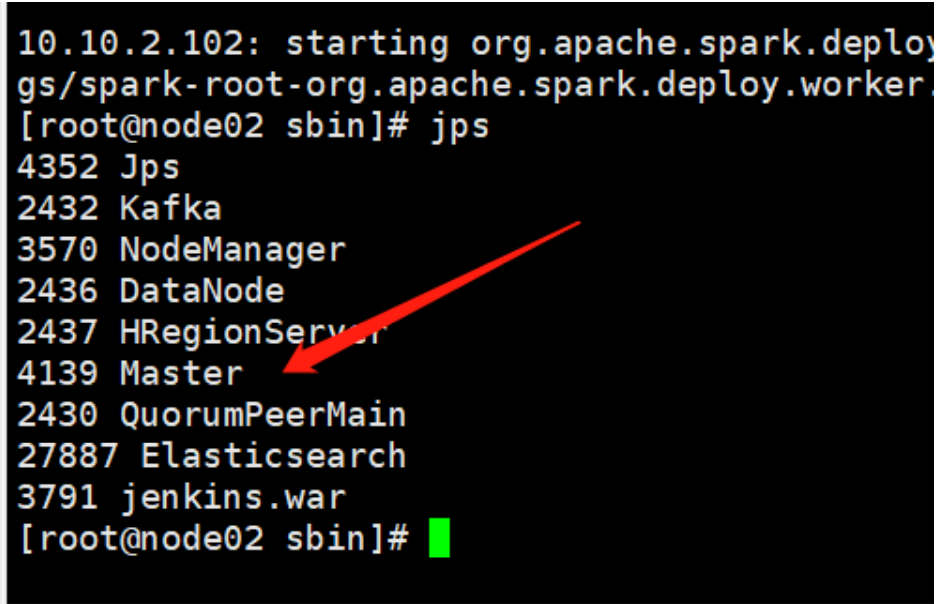
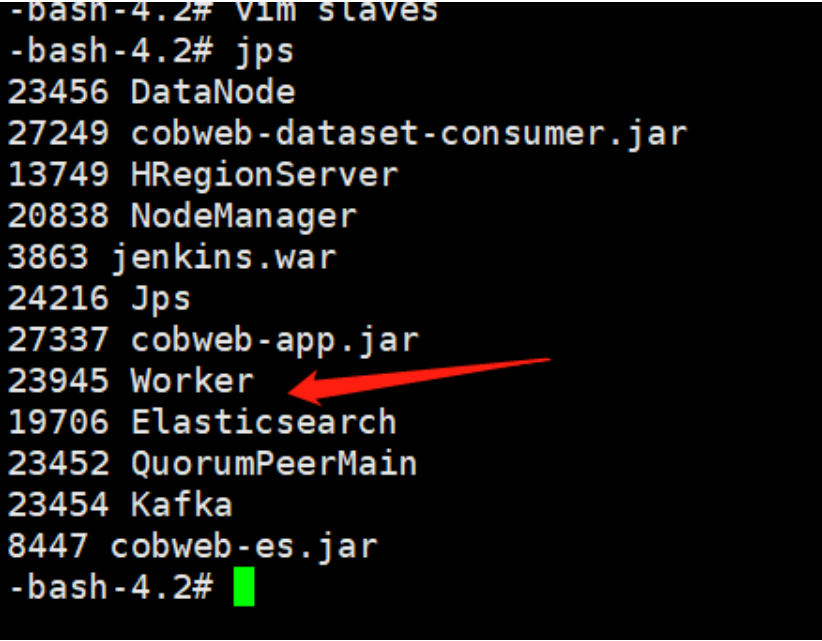
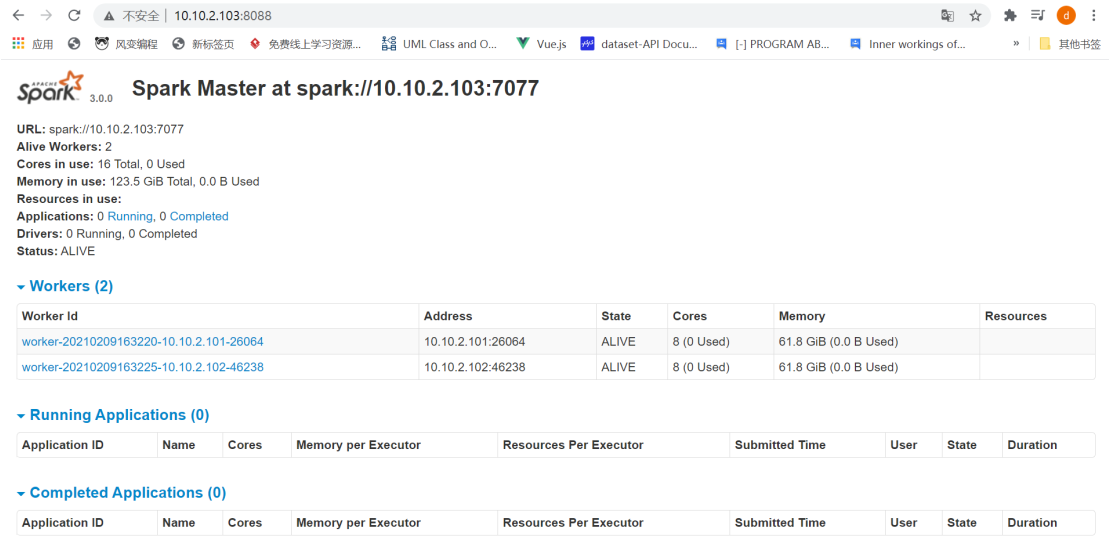
UI界面 默认8080 一般会有别的应用把8080占用
10.10.2.103:8080
修改端口 sbin 目录下 start_master.sh
10.10.2.103:8088 

若有收获,就点个赞吧
0 人点赞
