1.导读
从网络结构本身的角度出发,可以从深度(ResNet)、宽度(WideResNet)、基数(ResNeXt)和注意力(SENet)四个维度来提升卷积神经网络的性能。一般来说,网络越深,所提取到的特征就越抽象;网络越宽,其特征就越丰富;基数越大,越能发挥每个卷积核独特的作用;而注意力则是一种能强化重要信息抑制非重要性息的方法。
作者从频域角度切入,弥补了现有通道注意力方法中特征信息不足的缺点,将GAP推广到一种更为一般的表示形式,即2维的离散余弦变换DCT,通过引入更多的频率分量来充分的利用信息。对于每个特征通道图,本质上我们可以将其视为输入图片在不同卷积核上所对应的不同分量,类似于时频变化,相对于我们用卷积操作对输入信号(图片)进行傅里叶变换,从而将原始的输入分解为不同卷积核上的信号分量。
2.前情回顾
注意力机制,本质是一种通过网络学习出的一组权重系数,并以“动态加权”的方式来强调我们所感兴趣的区域,同时抑制不相关背景区域的机制。可分为两大类:
强注意力:是一种随机的预测,其强调的是动态变化,即能够通过基于梯度下降法的神经网络训练所获得,应用相对广泛
软注意力:按照不同维度(如通道、空间、时间 、类别等)出发
目前主流的注意力机制可以分为以下三种:通道注意力、空间注意力以及自注意力(Self-attention)
通道注意力:
通道注意力旨在显示的建模出不同通道(特征图)之间的相关性,通过网络学习的方式来自动获取到每个特征通道的重要程度。代表作:
SE-Net:通过特征重标定的方式来自适应地调整通道之间的特征响应
SK-Net:受Inception-block和SE-block共同启发,从多尺度特征表征的角度考虑,通过引入多个卷积核分支来学习出不同尺度下的特征图注意力,让网络能够更加侧重于重要的尺度特征
ECA-Net:利用1维的稀疏卷积操作来优化SE模块中涉及到的全连接层操作来大幅降低参数量并保持相当的性能
空间注意力:
空间注意力旨在提升关键区域的特征表达,将原始图片中的空间信息通过空间转换模块,变换到另一个空间中并保留关键信息,为每个位置生成权重掩膜(mask)并加权输出,从而增强感兴趣的特定目标区域,同时弱化不相关的背景区域。代表作:CBAM。
自注意力:
自注意力是注意力机制的一种变体,其目的是为了减少对外部信息的依赖,尽可能地利用特征内部固有的信息进行注意力的交互。一般的自注意力流程都是通过将原始特征图映射为三个向量分支,即Query、Key和Value。首先,计算Q和K的相关性权重矩阵系数;其次,通过软操作对权重矩阵进行归一化;最后再将权重系数叠加到V上,以实现全局上下文信息的建模。
3.论文解读
1.动机
通常来说,由于有限的计算资源开销,类似通道注意力机制这种通过网络学习的方式来获取权重函数需要对每个通道的标量进行计算,而全卷平均池化操作由于其易用性和高效性无疑是最佳的选择。尽管如此,但存在一个潜在的问题是GAP无法很好地捕获丰富的输入模式信息,因此在处理不同的输入时缺乏特征多样性。因此,也出现了一个自然而然的问题,即均值信息是否足以代表通道注意力中不同的特征通道。作者从三个角度分析:
- 首先,从特征通道本身的角度出发,不同特征表征不同的信息,而GAP操作,即“平均”操作会极大的抑制特征的这种多样性;
- 其次,从频率角度分析,GAP等价与离散余弦变换(DCT)的最低频率分量。因此,如果仅使用GAP,显然会忽略掉许多其他有用的频率分量;
- 最后,以CBAM论文中提出的观点去支撑论证,即单纯的使用GAP不足以表达特征原有的丰富信息。
2.贡献
- 证明了GAP是DCT的特例。在此基础上,将GAP推广到频域中,并提出了多光谱通道注意力框架——FcaNet;
- 通过探讨使用不同数量的频率分量及其不同组合的影响,提出了选择频率分量的两步准则;
- 广泛的实验表明,该方法在ImageNet和COCO数据集上均达到了最佳水平。在以ResNet-50为骨干网络的基础上,同时在相同参数量和计算量的情况下,所提出方法在ImageNet上的Top-1精度方面可以比SENet高出1.8%;
所提出方法不仅有效还非常简单,只需在现有的通道注意力实现中修改一行代码即可
3.方法
1.通道注意力和离散余弦变换回顾
通道注意力:
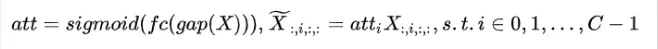
- 离散余弦变换:

这里 为DCT的频谱,
为DCT的频谱, 表示输入,L为输入分量的长度。此外,二维的DCT可以表示为:
表示输入,L为输入分量的长度。此外,二维的DCT可以表示为:
2D-DCT
同样的,这里h和w分别表示输入分量的高度和宽度,后面半部分为对应的DCT权重。相应的,我们可以写出它的逆变换:
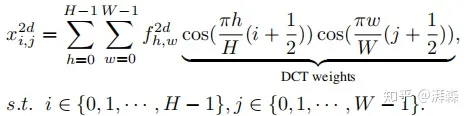
Inverse 2D-DCT
为简化运算和便于叙述,作者后面移除了一些归一化因子常量。从以上公式可以看出GAP是现有通道注意力方法的预处理方式;而DCT可以看作是输入的加权和,其中余弦部分表示其对应的权重。因此,我们可以将GAP这种均值运算当做是输入的最简单频谱,如上所述,仅使用单个GAP不足以表征所有的特征信息,作者下面便引入了多光谱通道注意力的方法。
DCT实际上的作用便是获得更好的频域能量聚集度,说白了就是将图像中相对重要的信息凝聚在一起,最简单的理解就是可以聚焦。
作者到这里就结束了,当然根据求和的可分性准则,我们也可以将2维DCT改写成如下形式: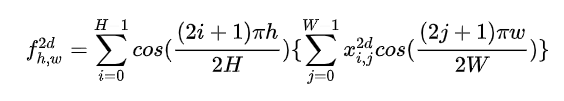
更一般我们还能写成矩阵相乘形式:
,其中 P 为变换系数矩阵。
2.多光谱通道注意力框架的推导及频率分量的选取准则
作者首先抛出了一个定理:GAP是2维DCT的特例,其结果与2维DCT的最低频率分量成比例。
假设2维DCT中的h和w为0,则可以推导出以下式子:
注:cos(0) = 1. 上述左式为2维DCT的最低频率分量,可以看出它与GAP是成正比关系的。证明了这点以后,接下来要考虑的事情便是如何将其他频率分量整合到通道注意力机制当中。根据上述公式,我们将2维DCT的逆变换重写以下形式: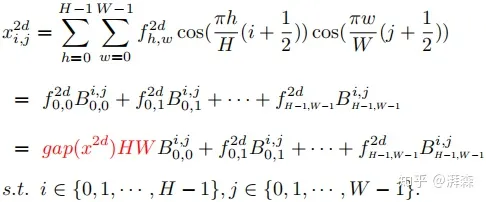
这里 B 表示的是频率分量,也可以理解为DCT的权重分量。根据上述公式,我们很自然地将图像特征分解为不同频率分量的组合。可以看出,GAP操作仅利用到了其中的一个频率分量。
Illustration of existing channel attention and multi-spectral channel attention.
上图为原始SE模块与作者所提出的MCA模块对比示意图。上面提到,为了引入更多的信息,作者建议使用2维的DCT来融合多个频率分量,包括最低的频率分量,即GAP。具体操作流程为:首先,将输入X 按通道维度划分为n部分,其中n必须能被通道数整除。对于每个部分,分配相应的二维DCT频率分量,其结果可作为通道注意力的预处理结果(类似于GAP):
紧接着,我们可以将各部分的频率分量合并起来:
这里, 即为多光谱分量。因此,整个MCA框架可以表示如下:
即为多光谱分量。因此,整个MCA框架可以表示如下: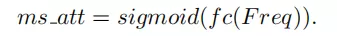
接下来阐述下频率分量的选取标准。对于每一部分 ,关键在于频率分量指数[u, v]的选择。对于空间尺寸为
,关键在于频率分量指数[u, v]的选择。对于空间尺寸为 的每个通道特征,我们可以利用2维的DCT将其分解为
的每个通道特征,我们可以利用2维的DCT将其分解为  个频率分量,于是总的频率分量应该为
个频率分量,于是总的频率分量应该为 。举个例子,以ResNet-50骨干网络的输出为例,
。举个例子,以ResNet-50骨干网络的输出为例, 可以达到2048。因此,测试所有组合计算代价是非常昂贵的也没有必要,作者在这里给出了一种两步准则来选择MCA模块中的频率分量。其主要思想是:
可以达到2048。因此,测试所有组合计算代价是非常昂贵的也没有必要,作者在这里给出了一种两步准则来选择MCA模块中的频率分量。其主要思想是:
- 第一步先分别计算出通道注意力中每个频率分量的结果;
- 第二步再根据做的结果筛选出Top-k个性能最佳的频率分量。
3.方法的有效性讨论、复杂度分析以及代码的实现
- 方法的有效性讨论
上述我们分析了现有的通道注意力方法使用GAP作为预处理方式,实际上是丢掉了除最低的频率分量的其他频率分量信息。作者在频域上推广了此方法,在MCA框架中自然地嵌入了更多的频率分量信息。之前有不少的工作也证明了CNN中存在着许多冗余的特征,比如Ghost-Net和OctaveConv等,所以当两个通道特征存在高度的相对性时,GAP操作会得到相似的结果。然而,在MCA框架中,由于不同的频率分量包含不同的信息,因此可以从冗余通道中提取更多的信息。
- 复杂度分析
作者从参数两和计算量两方面分析了所提出方法的复杂度。首先,由于2维DCT操作涉及到的权重是通过预先计算出来的一组常数,因此相比于原始的通道注意力方法如SE而言,没有引入额外的参数量。其次,计算量方面MCA仅仅比SE高出了略微的代价,可以忽略不计。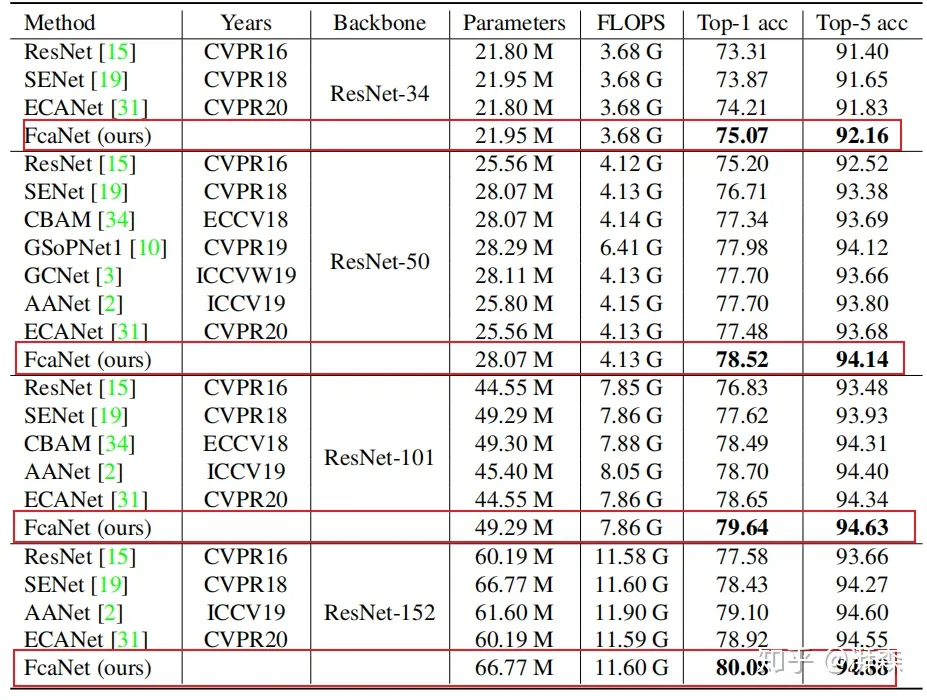
Comparison of different attention methods on ImageNet.
- 代码实现
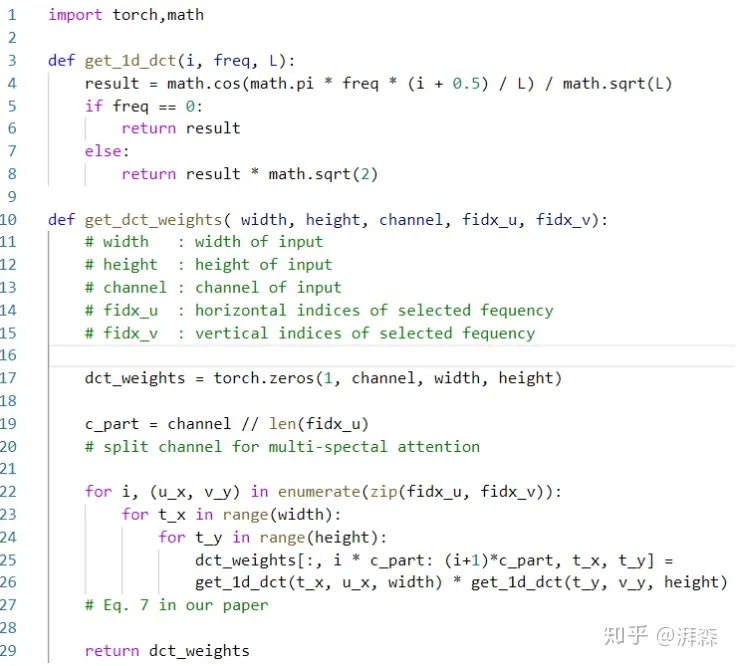
2维DCT可以看作是输入的加权和,因此,可以通过简单地元素乘法以及求和运算来实现:
4.实验
1.消融实验
- 单个频率分量的有效性
为了研究不同频率分量对信道注意的影响,每次只使用一个单独的频率分量。考虑到ImageNet上最小的特征图大小为7×7,作者这里将整个2维的DCT频率空间划分为7×7部分,这样的话共有49组实验。为了加快实验速度,首先训练了一个100个epoch标准ResNet-20网络作为基准模型。然后再将通道注意力添加到具有不同频率分量的基准模型中,以验证其效果。随后,基于同样的实验设置,以0.02的学习率对添加后的模型进行20轮的训练微调。
Top-1 accuracies on ImageNet using different frequencycomponents in channel attention individually.
实验结果如上所述,可以看出,当[u, v]分量为[0, 0]时,效果时最好的,对应SE-Net的GAP操作,同时也验证了DNN偏好低频信息的结论。虽然如此,但结果也表明了其他频率分量对网络也是有贡献的,这意味着我们可以将这些信息嵌入进去。
- 频率分量个数对性能的影响
在获得每个频率分量性能后,第二步是确定MCA模块所选择的最佳频率分量数。为了简单起见,作者选取了Top-k最高性能的频率成分,其中k可以是1、2、4、8、16或32等2的倍数。
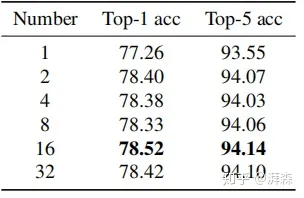
从实验结果可以看出,所有应用了多光谱的结果都要比单纯的GAP(对应Number=1)提高不少,实验的最佳效果是N=16,即选择了16个频率分量,不过其他整体相差也不大。
2.与其他SOTA模型对比
作者在分类、检测和分割任务上与其他主流的通道注意力模型进行了比较:
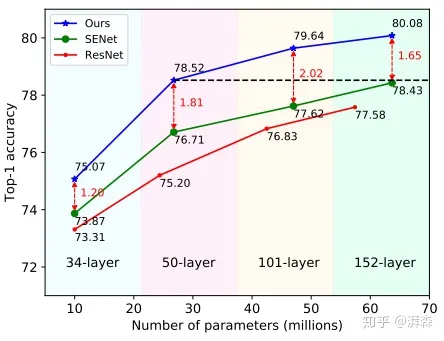
- 在分类任务上分别以ResNet-34, ResNet-50, ResNet-101, and ResNet-152四个骨干分支进行测试,结果显示Fca-Net在不同骨干网络上的TOP-1精度分别优于SE-NET 1.20%、1.81%、2.02%和1.65%。同时,在计算代价非常小的前提下,性能也优于GSOPNET。
- 在检测任务上以Faster-RCNN和Mask-RCNN作为检测器的前提下也显著的优于其他方法。
- 除了目标检测外,作者还在实例分割任务上测试了所提出方法,然而这部分差距不是很明显。
附录
- 不同频率分量组合策略的研究
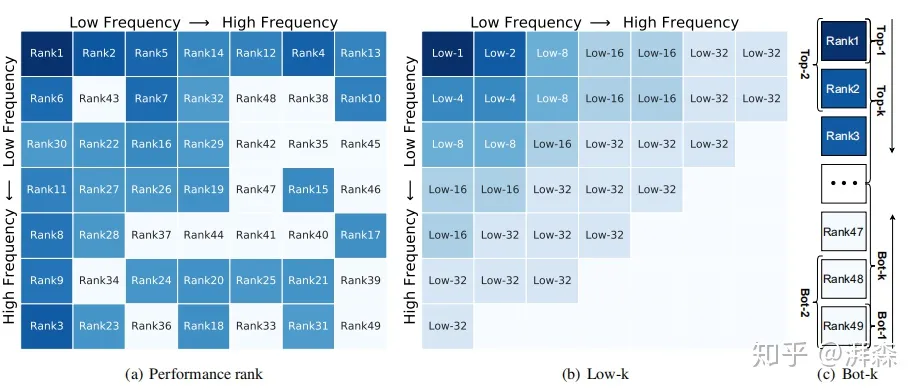
Illustration of different frequency combinations.
在消融实验部分,作者的two-step选择准则中的第二步是选择Top-k个性能表现组好的频率分量。在附录部分,作者还做了两组其他的组合策略,分别是选择如上图(b)左上角所示的所有频率分量,即low-1,low-2,…,low-32;还有一组是选择性能表现最差的Top-k个频率分量:
The results of Low-k combinations and Bot-k combinations.
从实验结果可以看出,Top-k性能最差的频率组合明显低于低频频率分量的组合策略,这也充分验证了低频分量是重要的,即DNN更加关注低频分量。当然,最佳的实验效果还是选择性能表现最好的Top-k个分量。
- 离散余弦变换的可视化
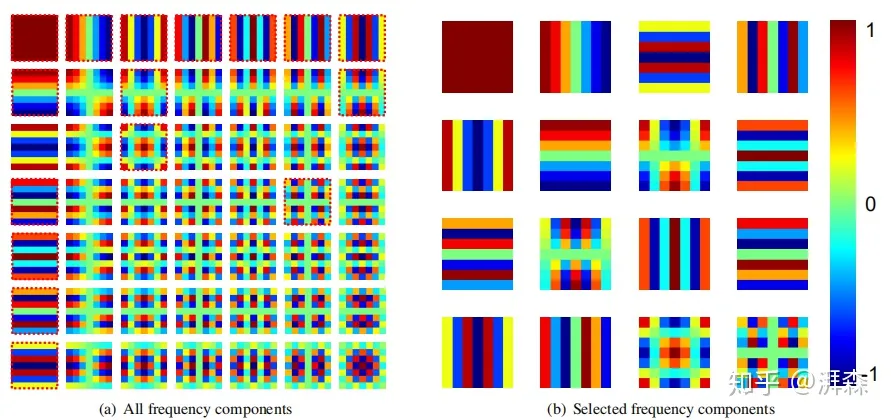
The visualization about DCT basis functions.
**
从上图可以看出,2维DCT的基函数是由规整的水平和垂直余弦波所组成,这些基函数是彼此正交的,与数据无关。此外,根据两步准则所选定的频率分量可以看到,所选择的频率分量通常是低频的。
- DCT的初始化代码
总结
Attention机制的优势有如下三点:参数少、速度快、效果好
很多论文对一些常规操作进行了名词渲染,比如1×1卷积应该叫投影函数(Project function);两个同阶矩阵的相乘可以写成哈达姆积(Hadamard product);求两个矩阵的相似度计算称为亲和(Affinity)计算等等。

若有收获,就点个赞吧
0 人点赞
