1、Storm简介
Storm是Twitter开源的分布式实时大数据处理框架,最早开源于github,从0.9.1版本之后,归于Apache社区,被业界称为实时版Hadoop。随着越来越多的场景对Hadoop的MapReduce高延迟无法容忍,比如网站统计、推荐系统、预警系统、金融系统(高频交易、股票)等等,大数据实时处理解决方案(流计算)的应用日趋广泛,目前已是分布式技术领域最新爆发点,而Storm更是流计算技术中的佼佼者和主流。
2、Storm与hadoop对比
大部分读者应该都是在了解了hadoop的基础后,才研究storm。因此个人觉得通过比对的方式,读者可能更容易理解Storm与Hadoop的区别以及Storm的应用场景。
2.1 应用场景对比
Storm: 分布式实时计算,强调实时性,常用于实时性要求较高的地方
Hadoop:分布式批处理计算,强调批处理,常用于对已经在的大量数据挖掘、分析
具体来说,Hadoop擅长于分析统计大批量的数据,在hadoop权威指南中,指出:MapReduce的设计目标是服务于那些只需要数分钟或者数小时既可以完成的作业。例如有这样的案例,美国国家气候中心使用hadoop分析统计1901年到2001年的气象数据,统计出气温最高的年份。实际上这里已经体现出了hadoop处理数据的一个特点:对于已经存在的大量数据进行统计分析。这种特性注定了hadoop是高延迟的,即使我们在几秒中内可以算出结果,但是还是不够实时。假设我们要将统计分析的结果直接显示给数以千万计的普通用户,普通用户是无法忍受几秒中后才得到返回结果的。但是这并不是说hadoop没用,对于公司的运营人来说,这个时间是可以忍受的。例如本人所在公司目前每天大概收集1亿条的用户行为数据,每天晚上都会由定时hadoop任务来分析统计这些数据,运营人员基本上都是第二天来看结果。当然,案例并不止这一个。目前本人所在公司的云计算管理中心调度接近2000个hadoop任务。
而storm同样是一个大数据处理框架,与hadoop不同的是,storm不是批量处理已经存在的大量数据,而是实时计算每一条数据。例如,一个促销活动,假设首页上有100种商品,同时有几亿用户访问。运营者就需要实时统计每种商品的点击率,如果在一段时间内,某种商品的访问量太低,就应该使用其他商品替换这个商品。因为在促销中,首页上的商品位置资源是比较稀缺的,如果一个商品长时间没多少人访问,应该让更有价值的商品来放在这个位置上。而因为用户量太大,商品太多,可能几分钟内就能产生几亿甚至几十亿的点击数据。如果让hadoop来处理的话,批量处理这些数据的时间较长,可能几分钟甚至更长时间才能算出结果。这明显是不合适的。如果我们使用是storm的话,就可以实时的统计出最新点击率,从而不会让一个没人访问的产品在一个重要的位置上占据过长时间。
总结:hadoop和storm擅长处理的方面不同。经常在网上看到一些对于大数据处理框架到底是使用hadoop还是storm的讨论,个人认为这要根据实际情况而定,如果需要分析统计大量的数据,且对实时性要求不高就使用hadoop;如果实时要求高,且数据量大的话,还是要使用storm。本人有一个理解,有点片面,但在某种程度上也反应了一些问题:hadoop更像是为公司运营管理人员服务的大数据框架,因为这类用户为了查看统计数据通常是可以忍受高延迟的;storm更像是为普通用户服务的大数据框架,因为我们通常会使用storm计算出的实时数据,及时的展现给用户不同的信息,从而影响用户的行为。之所以说片面,是因为storm并不完全只对普通用户服务,对于一些比较重要的数据,可能公司运营者也想看到实时数据,例如双11大屏幕上显示的实时成交额,可能与普通用户无关,但是运营者非常关心,可能也会使用storm来做实时统计。
2、主从结构对比
目前分布式处理框架最主流的就是master/slave架构,master负责任务的接受与分配,slave负责任务的执行。storm和hadoop都不例外。不同的是:
hadoop着重于计算和数据存储,storm只着重于计算。那么区别在什么地方呢?
hadoop:在hadoop中,由于同时着重于计算和存储,同时存在两个master/slave机制。数据计算使用的使用的是MapReduce框架,master节点称之为JobTracker,slave节点称之为TaskTracker。数据存储使用的是HDFS,master节点称之为NameNode,slave节点称之为DataNode。
Storm:由于Storm只着重于计算,因此只有一套计算的master/slave机制。master称之为Nimbus,slave称之为supervisor。对应的是hadoop的分布式计算框架mapreduce,以下是二者的对比。下图列出了二者在计算架构上的对比:
3、任务工作方式对比
在Hadoop中,一个MapReduce任务我们称之为一个job,在storm中,一个任务我们称之为Topology。
Hadoop中,Mapreduce Job提交之后,任务执行完成之后就会自动结束。
Storm中,一个Topology会一直运行下去,这是因为Storm是一个实时计算平台,需要不断的处理最新的记录,计算出最新的结果,因此当然不能停止。
4、集群组织方式对比
在Hadoop中,集群中的每个节点是通过配置文件指定的。
storm采用了另外一种方式,通过zookeeper来指定集群的节点。具体来说,每个storm节点在启动的时候都会连接zookeeper,将自己的ip和端口等信息写入zookeeper中。这样每个节点只要读取指定目录下的数据,既可以感知集群中其他节点的存在。如下: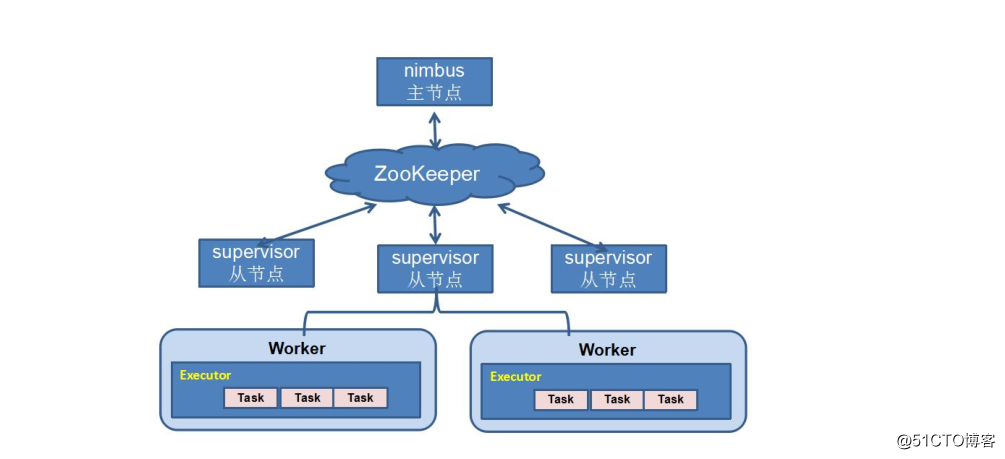
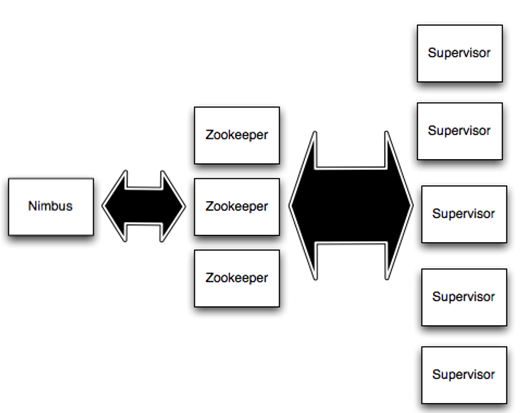
在后面,我们将会详细的介绍Storm是如何使用Zookeeper的。
storm运行流程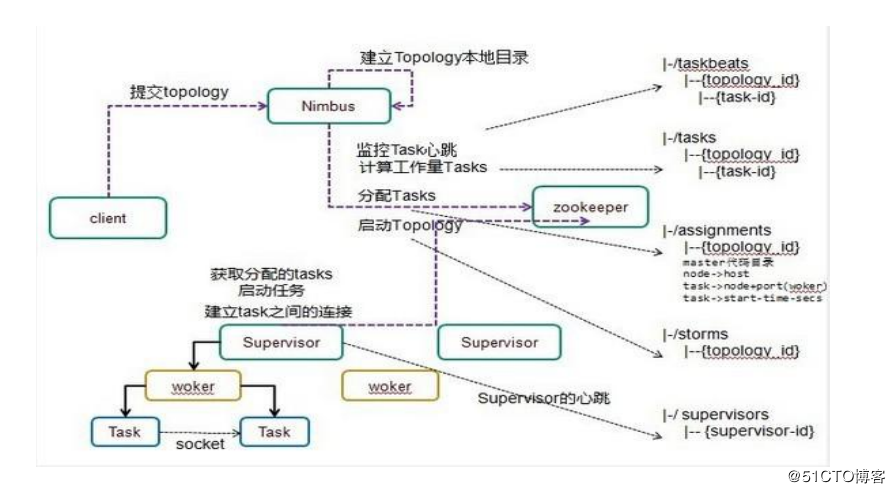
3、Strom分布式安装部署
1、安装java环境
yum安装jdk1.8(openjdk)
# 安装前先检查系统中是否已安装jdk,如有,应先删除rpm -qa |grep javarpm -qa |grep jdkrpm -qa |grep gcj# 如检测到,可使得以下命令删除原有的jdkrpm -qa | grep java | xargs rpm -e --nodeps# 查看可供安装的1.8版本yum list java-1.8*# 安装jdkyum -y install java-1.8.0-openjdk*# 验证java -version
2、安装Zookeeper
本教程选择安装 zookeeper 最新稳定版(3.4.6),下载地址:http://mirrors.cnnic.cn/apache/zookeeper/stable/ 或 http://mirror.bit.edu.cn/apache/zookeeper/stable/ (打开网页,点击 Projects 下的 “zookeeper-3.4.6.tar.gz” 进行下载)。
下载后执行如下命令进行安装 zookeeper(将命令中 3.4.6 改为你下载的版本):
sudo tar -zxf ~/下载/zookeeper-3.4.6.tar.gz -C /usr/local
cd /usr/local
sudo mv zookeeper-* zookeeper
sudo chown -R hadoop ./zookeeper # 此处的hadoop为你的用户名
接着执行如下命令进行zookeeper配置:
cd /usr/local/zookeeper
mkdir tmp
cp ./conf/zoo_sample.cfg ./conf/zoo.cfg
vim ./conf/zoo.cfg
将当中的 dataDir=/tmp/zookeeper 更改为 dataDir=/usr/local/zookeeper/tmp 。接着执行:
./bin/zkServer.sh start
若显示如下图则表示启动成功(显示 “Starting zookeeper … STARTED”):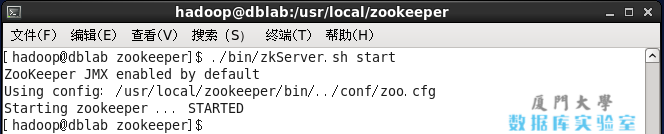
3、安装Storm
本教程所使用的版本为 Storm 0.9.6 ,下载地址http://www.apache.org/dyn/closer.lua/storm/apache-storm-0.9.6/apache-storm-0.9.6.tar.gz。
下载后执行如下命令进行安装Storm:
sudo tar -zxf ~/下载/apache-storm-0.9.6.tar.gz -C /usr/local
cd /usr/local
sudo mv apache-storm-0.9.6 storm
sudo chown -R hadoop ./storm # 此处的hadoop为你的用户名
接着执行如下命令进行Storm配置:
cd /usr/local/storm
vim ./conf/storm.yaml
修改其中的 storm.zookeeper.servers 和 nimbus.host 两个配置项,即取消掉注释且都修改值为 127.0.0.1(我们只需要在单机上运行),如下图所示。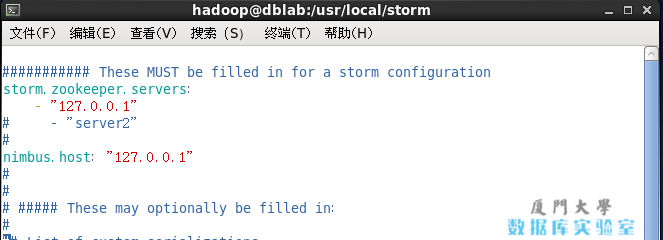 Storm配置
Storm配置
简单配置后就可以启动 Storm 了。执行如下命令启动 nimbus 后台进程:
./bin/storm nimbus
若启动成功则显示如下图内容: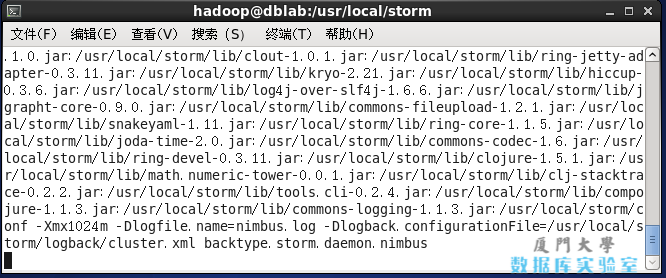 开启Storm nimbus进程
开启Storm nimbus进程
启动 nimbus 后,终端被该进程占用了,不能再继续执行其他命令了。因此我们需要另外开启一个终端,然后执行如下命令启动 supervisor 后台进程:
# 需要另外开启一个终端
/usr/local/storm/bin/storm supervisor
4、Springboot与Storm整合
1、导入依赖
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-core</artifactId>
<version>0.9.3</version>
<scope>provided</scope>
</dependency>
2、Spout.open方法实现
@Override
public void open(Map map, TopologyContext topologyContext, SpoutOutputCollector spoutOutputCollector) {
//启动Springboot应用
SpringStormApplication.run();
this.map = map;
this.topologyContext = topologyContext;
this.spoutOutputCollector = spoutOutputCollector;
}
3、Bolt.prepare方法实现
@Override
public void prepare(Map map, TopologyContext topologyContext, OutputCollector outputCollector) {
//启动Springboot应用
SpringStormApplication.run();
this.map = map;
this.topologyContext = topologyContext;
this.outputCollector = outputCollector;
}
4、springApplication启动类
@SpringBootApplication
@ComponentScan(value = "com.xxx.storm")
public class SpringStormApplication {
/**
* 非工程启动入口,所以不用main方法
* 加上synchronized的作用是由于storm在启动多个bolt线程实例时,如果Springboot用到Apollo分布式配置,会报ConcurrentModificationException错误
* 详见:https://github.com/ctripcorp/apollo/issues/1658
* @param args
*/
public synchronized static void run(String ...args) {
SpringApplication app = new SpringApplication(SpringStormApplication.class);
//我们并不需要web servlet功能,所以设置为WebApplicationType.NONE
app.setWebApplicationType(WebApplicationType.NONE);
//忽略掉banner输出
app.setBannerMode(Banner.Mode.OFF);
//忽略Spring启动信息日志
app.setLogStartupInfo(false);
app.run(args);
}
}
5、工具类
@Component
public class BeanUtils implements ApplicationContextAware {
private static ApplicationContext applicationContext = null;
@Override
public void setApplicationContext(ApplicationContext applicationContext) throws BeansException {
if (BeanUtils.applicationContext == null) {
BeanUtils.applicationContext = applicationContext;
}
}
public static ApplicationContext getApplicationContext() {
return applicationContext;
}
public static Object getBean(String name) {
return getApplicationContext().getBean(name);
}
public static <T> T getBean(Class<T> clazz) {
return getApplicationContext().getBean(clazz);
}
public static <T> T getBean(String name, Class<T> clazz) {
return getApplicationContext().getBean(name, clazz);
}
}
在FilterBolt的execute方法中获取Spring bean
@Override public void execute(Tuple tuple) { FilterService filterService = (FilterService) BeanUtils.getBean("filterService"); filterService.deleteAll(); }定义FilterService类,这时候我们就可以使用Spring的相关注解,自动注入,Spring Jpa等功能了。
@Service public class FilterService { @Autowired UserRepository userRepository; public void deleteAll() { userRepository.deleteAll(); } }使用maven-shade-plugin打包注意的问题
因为springboot有自己的打包插件,如果使用maven-shade-plugin需要将spring-boot-maven-plugin作为依赖引入,另外spring-boot-starter-parent需要使用dependencyManagement引入。
parent部分替换如下:<dependencyManagement> <dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-dependencies</artifactId> <version>2.1.0.RELEASE</version> <type>pom</type> <scope>import</scope> </dependency> </dependencies> </dependencyManagement>build如下:
<build> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <version>3.8.0</version> <configuration> <encoding>UTF-8</encoding> <source>1.8</source> <target>1.8</target> </configuration> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-jar-plugin</artifactId> <version>2.6</version> <configuration> <archive> <manifest> <addClasspath>true</addClasspath> <classpathPrefix>lib/</classpathPrefix> <mainClass>com.xxx.storm.pointer.XdPointerTopology</mainClass> </manifest> </archive> </configuration> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-shade-plugin</artifactId> <version>3.1.1</version> <dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-maven-plugin</artifactId> <version>2.1.0.RELEASE</version> </dependency> </dependencies> <configuration> <keepDependenciesWithProvidedScope>true</keepDependenciesWithProvidedScope> <createDependencyReducedPom>true</createDependencyReducedPom> <filters> <filter> <artifact>*:*</artifact> <excludes> <exclude>META-INF/*.SF</exclude> <exclude>META-INF/*.DSA</exclude> <exclude>META-INF/*.RSA</exclude> </excludes> </filter> </filters> <artifactSet> <excludes> <exclude>com.xxx.storm:xxx-storm</exclude> <exclude>org.slf4j:slf4j-api</exclude> <exclude>javax.mail:javax.mail-api</exclude> <exclude>org.apache.storm:storm-core</exclude> <exclude>org.apache.storm:storm-kafka</exclude> <exclude>org.apache.logging.log4j:log4j-slf4j-impl</exclude> </excludes> </artifactSet> </configuration> <executions> <execution> <phase>package</phase> <goals> <goal>shade</goal> </goals> <configuration> <transformers> <transformer implementation="org.apache.maven.plugins.shade.resource.AppendingTransformer"> <resource>META-INF/spring.handlers</resource> </transformer> <transformer implementation="org.springframework.boot.maven.PropertiesMergingResourceTransformer"> <resource>META-INF/spring.factories</resource> </transformer> <transformer implementation="org.apache.maven.plugins.shade.resource.AppendingTransformer"> <resource>META-INF/spring.schemas</resource> </transformer> <transformer implementation="org.apache.maven.plugins.shade.resource.ServicesResourceTransformer" /> <transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer"> <mainClass>com.xxx.storm.pointer.XdPointerTopology</mainClass> </transformer> </transformers> </configuration> </execution> </executions> </plugin> </plugins> </build>注意:META-INF/spring.* 文件不需要我们创建,这是springboot包内部的文件,这里只是需要显示的引入进来。
OK,完美整合!

若有收获,就点个赞吧
0 人点赞
