- 2 为什么需要spring cloud
- 3 Spring cloud概述
- 4 Spring Cloud Alibaba概述
- 5 Nacos Discovery
- 6 RestTemplate
- 7 Ribbon
- 7.6 自定义Ribbon的负载均衡规则
- 8 Feign
- 9 Sentinel
- 9.1 雪崩效用
- 9.2 服务容错
- 9.3 引入sentinel
- 9.4 流量控制
- 9.4.1 控制模式
- 9.10 对Feign以及RestTemplate的支持
- 10.2 rotue(路由)
- 10.3 Prendicate(谓词工厂)
- 10.4 filter
- AddRequestHeaderGatewayFilterFactory
- AddRequestParameterGatewayFilterFactory
- AddResponseHeaderGatewayFilterFactory
- DedupeResponseHeaderGatewayFilterFactory
- PrefixPathGatewayFilterFactory
- PreserveHostHeaderGatewayFilterFactory
- RequestRateLimiterGatewayFilterFactory
- RedirectToGatewayFilterFactory
- RemoveRequestHeaderGatewayFilterFactory
- RemoveResponseHeaderGatewayFilterFactory
- RewritePathGatewayFilterFactory
- RewriteResponseHeaderGatewayFilterFactory
- SaveSessionGatewayFilterFactory
- SetPathGatewayFilterFactory
- SetResponseHeaderGatewayFilterFactory
- SetStatusGatewayFilterFactory
- StripPrefixGatewayFilterFactory
- RetryGatewayFilterFactory
- RequestSizeGatewayFilterFactory
- 10.5 自定义过滤器
- 1 异常类处理
- 11 JWT
- 11 分布式锁
- 12 RocketMQ(消息队列)
2 为什么需要spring cloud
2.1 Monolith(单体应用)架构
2.1.1 什么是单体应用
回想一下我们所开发的服务是什么样子的。通常情况下,这个服务所对应的代码由多个项目(idea)所组成,各个项目会根据自身所提供功能的不同具有一个明确的边界。在编译时,这些项目将被打包成为一个个JAR包,并最终合并在一起形成一个WAR包。接下来,我们需要将该WAR包上传到Web容器中,解压该WAR包,并重新启动服务器。在执行完这一系列操作之后,我们对服务的编译及部署就已经完成了。这种将所有的代码及功能都包含在一个WAR包中的项目组织方式被称为Monolith。
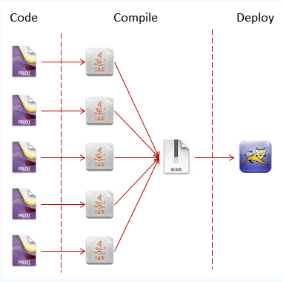
最终部署的时候只有一份war包,其他的以jar包的方式依赖来.
2.1.2 缺点
在项目很小的情况下这种单体应用比较简单,但是随着项目越变越大,代码越来越多。就会存在以下缺点。
1. 编译难,部署难,测试难
代码量变多,更改一行代码,也需花大量时间编译,部署前要编译打包,解压等所以部署难,部署完了还要测试所以测试难。
2. 技术选择难
在变得越来越大的同时,我们的应用所使用的技术也会变得越来越多。这些技术有些是不兼容的,就比如在一个项目中大范围地混合使用C++和Java几乎是不可能的事情。在这种情况下,我们就需要抛弃对某些不兼容技术的使用,而选择一种不是那么适合的技术来实现特定的功能。
3. 扩展难
按照Monolith组织的代码将只产生一个包含了所有功能的WAR包,因此在对服务的容量进行扩展的时候,我们只能选择重复地部署这些WAR包来扩展服务能力,而不是仅仅扩展出现系统瓶颈的组成。
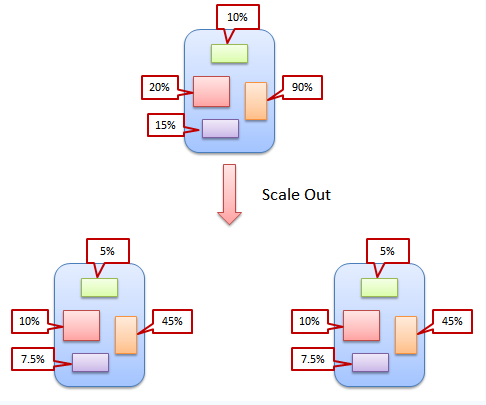
是这种扩展方式极大地浪费了资源。就以上图所展示的情况为例:在一个服务中,某个组成的负载已经达到了90%,也就是到了不得不对服务能力进行扩容的时候了。而同一服务的其它三个组成的负载还没有到其处理能力的20%。由于Monolith服务中的各个组成是打包在同一个WAR包中的,因此通过添加一个额外的服务实例虽然可以将需要扩容的组成的负载降低到了45%,但是也使得其它各组成的利用率更为低下。<br /> 单体应用中多个模块的负载不均衡,我们扩容高负载的时候,也把低负载的模块也扩容,极大浪费了资源。
2.2 MicroService(微服务)架构
2.2.1 什么是MicroService架构
微服务架构是一种架构模式,它提倡将单一应用程序划分成一组小的服务,服务之间互相协调、互相配合,为用户提供最终价值。每个服务运行在其独立的进程中,服务与服务间采用轻量级的通信机制互相沟通(通常是基于HTTP的RESTful API)。每个服务都围绕着具体业务进行构建,并且能够被独立地部署到生产环境、类生产环境等。另外,应尽量避免统一的、集中式的服务管理机制,对具体的一个服务而言,应根据业务上下文,选择合适的语言、工具对其进行构建。<br /> 微服务是一种架构风格,一个大型复杂软件应用由一个或多个微服务组成。系统中的各个微服务可被独立部署,各个微服务之间是松耦合的。每个微服务仅关注于完成一件任务并很好地完成该任务。在所有情况下,每个任务代表着一个小的业务能力。<br /> 微服务就是把一个单体项目,拆分为多个微服务,每个微服务可以独立技术选型,独立开发,独立部署,独立运维.并且多个服务相互协调,相互配合,最终完成用户的价值。
2.2.2 优势
1. 复杂度可控:<br /> 在将应用分解的同时,规避了原本复杂度无止境的积累。每一个微服务专注于单一功能,并通过定义良好的接口清晰表述服务边界。由于体积小、复杂度低,每个微服务可由一个小规模开发团队完全掌控,易于保持高可维护性和开发效率。<br /> 2. 独立部署:<br /> 由于微服务具备独立的运行进程,所以每个微服务也可以独立部署。当某个微服务发生变更时无需编译、部署整个应用。由微服务组成的应用相当于具备一系列可并行的发布流程,使得发布更加高效,同时降低对生产环境所造成的风险,最终缩短应用交付周期。<br /> 3. 技术选型灵活:<br /> 微服务架构下,技术选型是去中心化的。每个团队可以根据自身服务的需求和行业发展的现状,自由选择最 适合的技术栈。由于每个微服务相对简单,故需要对技术栈进行升级时所面临的风险就较低,甚至完全重构一个微服务也是可行的。<br /> 4. 容错:<br /> 当某一组件发生故障时,在单一进程的传统架构下,故障很有可能在进程内扩散,形成应用全局性的不可用。在微服务架构下,故障会被隔离在单个服务中。若设计良好,其他服务可通过重试、平稳退化等机制实现应用层面的容错。<br /> 5. 扩展:<br /> 单块架构应用也可以实现横向扩展,就是将整个应用完整的复制到不同的节点。当应用的不同组件在扩展需求上存在差异时,微服务架构便体现出其灵活性,因为每个服务可以根据实际需求独立进行扩展。<br />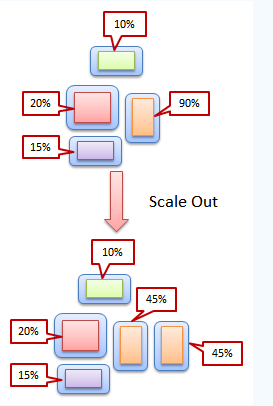
2.3 microSrvice使用场景
2.3.1 选择依据
是否所有项目都适用呢?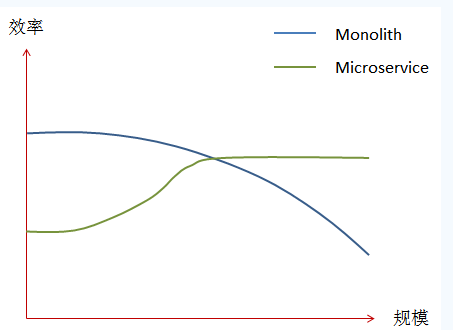
从上图中可以看到,在刚开始的阶段,使用Microservice架构模式开发应用的效率明显低于Monolith。但是随着应用规模的增大,基于Microservice架构模式的开发效率将明显上升,而基于Monolith模式开发的效率将逐步下降。
这是因为Microservice是一个架构模式,而不是一个特定的技术解决方案。其并不会将开发中的各个难点全部转移,而只是允许通过更为合适的技术来适当简化单个子服务的开发,或者绕过开发中可能遇到的部分难点。但是为了支持各个子服务的运行,我们还需要创建一系列公共服务。这些公共服务需要在编写第一个子服务的同时进行。这是导致Microservice架构模式在开发初期会具有较低效率的一个原因。
然而使用特定技术并不会绕过开发中所能遇到的所有难点。由于在Microservice架构中,各个子服务都集中精力处理本身的业务逻辑,而所有的公共功能都交由公共服务来完成,因此公共服务在保持和各个子服务的松耦合性的同时还需要提供一个足够通用的,能够在一定程度上满足所有当前和未来子服务要求的解决方案。而这也是导致Microservice架构模式在开发初期会具有较低效率的另外一个原因。
而在开发的后期,随着Monolith模式中应用的功能逐渐变大,增加一个新的功能会影响到该应用中的很多地方,因此其开发效率会越来越差。反过来,由于Microservice架构模式中的各个子服务所依赖的公共服务已经完成,而且子服务本身可以选择适合自己的实现技术,因此子服务的实现通常只需要关注自身的业务逻辑即可。这也是Microservice架构模式在后期具有较高效率的原因。
当我们再次通过Microservice架构模式搭建应用的时候,其在开发时的效率劣势也将消失,原因就是因为在前一次基于Microservice架构模式开发的时候,我们已经创建过一次公共服务,因此在这个新的应用中,我们将这些公共服务拿来并稍事改动即可。
2.3.2 选型
单体应用架构:中小型项目(功能相对较少) crm 物流 库存管理等<br /> 微服务架构:大型项目(功能比较多) 商城 erp等
2.4 MicroService技术实现
MicroService 是一种架构的理念,提出了微服务的设计原则,从理论为具体的技术落地提供了指导思想。Java中可以使用传统ssm ssj等架构,当然更加推荐Springboot。可以基于Spring Boot快速开发单个微服务。由于微服务架构中存在多个微服务,那么如何管理和协调这些服务呢?就需要服务治理框架,而springcloud就是是一个基于Spring Boot实现的服务治理工具包。
2.5 小结
相较于单体应用这个架构模式,微服务架构更加适用于大型项目,虽然刚开始成本高,但是随着项目开展成本会变得越来越低。并且微服务只是一种架构思想,具体可以通过springboot快速开发一个单一服务,但是多个服务协调管理,就需要服务治理框架springcloud等。<br />1, 什么是微服务架构?<br />2, 微服务架构与单体架构的区别?
3 Spring cloud概述
Spring cloud是一个基于Spring Boot实现的服务治理工具包,在微服务架构中用于管理和协调服务的。Spring Cloud是一系列框架的有序集合。它利用Spring Boot的开发便利性巧妙地简化了分布式系统基础设施的开发,如服务发现注册、配置中心、消息总线、负载均衡、断路器、数据监控等,都可以用Spring Boot的开发风格做到一键启动和部署。Spring并没有重复制造轮子,它只是将目前各家公司开发的比较成熟、经得起实际考验的服务框架组合起来,通过Spring Boot风格进行再封装屏蔽掉了复杂的配置和实现原理,最终给开发者留出了一套简单易懂、易部署和易维护的分布式系统开发工具包。
4 Spring Cloud Alibaba概述
Spring Cloud Alibaba 致力于提供微服务开发的一站式解决方案。此项目包含开发分布式应用微服务的必需组件,方便开发者通过 Spring Cloud 编程模型轻松使用这些组件来开发分布式应用服务。
4.1 主要功能
- 服务限流降级:默认支持 WebServlet、WebFlux, OpenFeign、RestTemplate、Spring Cloud Gateway, Zuul, Dubbo 和 RocketMQ 限流降级功能的接入,可以在运行时通过控制台实时修改限流降级规则,还支持查看限流降级 Metrics 监控。
- 服务注册与发现:适配 Spring Cloud 服务注册与发现标准,默认集成了 Ribbon 的支持。
- 分布式配置管理:支持分布式系统中的外部化配置,配置更改时自动刷新。
- 消息驱动能力:基于 Spring Cloud Stream 为微服务应用构建消息驱动能力。
- 分布式事务:使用 @GlobalTransactional 注解, 高效并且对业务零侵入地解决分布式事务问题。
- 阿里云对象存储:阿里云提供的海量、安全、低成本、高可靠的云存储服务。支持在任何应用、任何时间、任何地点存储和访问任意类型的数据。
- 分布式任务调度:提供秒级、精准、高可靠、高可用的定时(基于 Cron 表达式)任务调度服务。同时提供分布式的任务执行模型,如网格任务。网格任务支持海量子任务均匀分配到所有 Worker(schedulerx-client)上执行。
阿里云短信服务:覆盖全球的短信服务,友好、高效、智能的互联化通讯能力,帮助企业迅速搭建客户触达通道。
4.2 组件
Sentinel:把流量作为切入点,从流量控制、熔断降级、系统负载保护等多个维度保护服务的稳定性。
- Nacos:一个更易于构建云原生应用的动态服务发现、配置管理和服务管理平台。
- RocketMQ:一款开源的分布式消息系统,基于高可用分布式集群技术,提供低延时的、高可靠的消息发布与订阅服务。
- Dubbo:Apache Dubbo™ 是一款高性能 Java RPC 框架。
- Seata:阿里巴巴开源产品,一个易于使用的高性能微服务分布式事务解决方案。
- Alibaba Cloud ACM:一款在分布式架构环境中对应用配置进行集中管理和推送的应用配置中心产品。
- Alibaba Cloud OSS: 阿里云对象存储服务(Object Storage Service,简称 OSS),是阿里云提供的海量、安全、低成本、高可靠的云存储服务。您可以在任何应用、任何时间、任何地点存储和访问任意类型的数据。
- Alibaba Cloud SchedulerX: 阿里中间件团队开发的一款分布式任务调度产品,提供秒级、精准、高可靠、高可用的定时(基于 Cron 表达式)任务调度服务。
Alibaba Cloud SMS: 覆盖全球的短信服务,友好、高效、智能的互联化通讯能力,帮助企业迅速搭建客户触达通道。
4.3 构建cloud项目
创建maven项目。。。
- 在pom文件引入
<!-- 规定springboot版本 --><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>${spring.boot.version}</version><relativePath /></parent><properties><spring.cloud.alibaba.version>2.2.3.RELEASE</spring.cloud.alibaba.version><spring.cloud.version>Hoxton.SR8</spring.cloud.version><spring.boot.version>2.3.2.RELEASE</spring.boot.version><java.version>1.8</java.version></properties><dependencyManagement><dependencies><!-- 规定alibaba的版本 --><dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-alibaba-dependencies</artifactId><version>${spring.cloud.alibaba.version}</version><type>pom</type><scope>import</scope></dependency><!-- 规定cloud的版本 --><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-dependencies</artifactId><version>${spring.cloud.version}</version><type>pom</type><scope>import</scope></dependency></dependencies></dependencyManagement>
5 Nacos Discovery
5.1 nacos Discovery简介
服务发现是微服务架构体系中最关键的组件之一。如果尝试着用手动的方式来给每一个客户端来配置所有服务提供者的服务列表是一件非常困难的事,而且也不利于服务的动态扩缩容。Nacos Discovery 可以让你将服务自动注册到 Nacos 服务端并且能够动态感知和刷新某个服务实例的服务列表。除此之外,Nacos Discovery 也将服务实例自身的一些元数据信息-例如 host,port,健康检查URL,主页等-注册到 Nacos 。
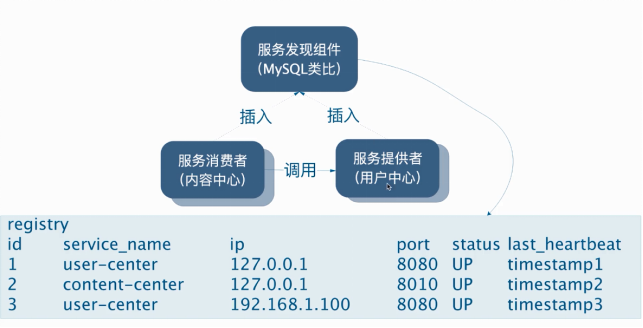
- 服务注册
微服务需要把信息注册到nacos注册中心,并保持心跳连接,nacos维护所有服务的信息列表,并且可以动态的感知服务的健康状态及时剔除失效的实例。 服务发现
服务注册到注册中心后,服务的消费者就可以进行服务发现的流程了,消费者可以直接向注册中心发送获取某个服务实例的请求,这种情况下注册中心将返回所有可用的服务实例给消费者。另一种方法就是服务的消费者向注册中心订阅某个服务,并提交一个监听器,当注册中心中服务发生变更时,监听器会收到通知,这时消费者更新本地的服务实例列表,以保证所有的服务均是可用的。5.2 使用nacos
下载nacos: https://github.com/alibaba/nacos/releases
如果启动时集群模式需要配置集群才能成功,也可以直接在启动文件里面去修改成单机模式启动- 进入bin目录,双击startup.cmd启动
- 通过http://localhost:8848/nacos进行访问(账号密码都是nacos)
导包:
<dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId></dependency>
服务注册:
在yml配置文件添加配置如下:spring: application: #自定义服务名 name: user-server cloud: nacos: discovery: #nacos服务地址 server-addr: localhost:88485.3 服务发现的领域模型(命名空间、组、集群、实例)
领域模型是用来对注册到nacos上面的微服务进行隔离以及逻辑划分。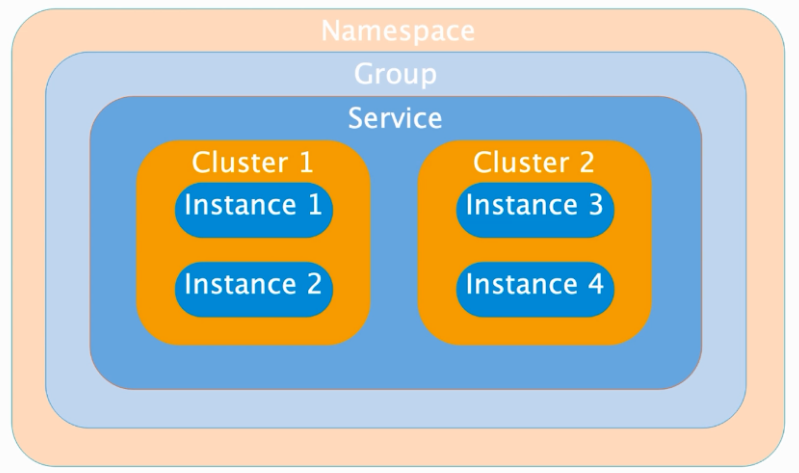
配置如下:cloud: nacos: discovery: server-addr: localhost:8848 #命名空间,值是nacos服务创建的唯一key namespace: 541a64ac-65af-41e9-8a66-115dda2285a1 #组 group: 1 #集群 cluster-name: SH5.3 NacosDiscoveryProperties
该对象是一个nacos的信息对象,在ioc容器里面,可以直接注入使用,通过该对象可以获取到当前服务的所有信息,包括领域模型里面的数据。
@Autowired private NacosDiscoveryProperties nacosDiscoveryProperties;5.4 NacosServiceManager
在高版本的nacos里面(比如1.8)一部分关于服务注册查询等管理对象的获取使用从NacosDiscoveryProperties对象里面抽取了出来形成了NacosServiceManager对象,我们对服务的一些操作或则服务注册核心对象的获取都可以通过该对象来得到。
@Autowired private NacosServiceManager nacosServiceManager;5.5 NamingService
这是nacos的服务注册与发现对象,可以通过它来进行服务的注册以及服务查询,查询提供了一些负载均衡算法,比如通过权重进行服务发现。该对象针对版本不一样可以通过NacosDiscoveryProperties或则NacosServiceManager对象来进行获取。
6 RestTemplate
RestTemplate是一个http客户端,通过它能够在java端发起http请求。可以用它来进行服务间的调用。
获取RestTemplate对象,可以new也可以放入容器
@Configuration public class BaseConfig { @Bean public RestTemplate getRestTemplate() { RestTemplate rs = new RestTemplate(); return rs; } }访问服务:
@Autowired RestTemplate rt; String value = rt.getForObject("http://ip:port/user/findUser", String.class);7 Ribbon
7.1 Ribbon是什么
Ribbon是Netflix发布的云中间层服务开源项目,主要功能是提供客户端(消费者方)负载均衡算法。Ribbon客户端组件提供一系列完善的配置项,如,连接超时,重试等。简单的说,Ribbon是一个客户端负载均衡器,我们可以在配置文件中列出loadBalancer后面所有的机器,Ribbon会自动的帮助你基于某种规则(如简单轮询,随机连接等)去连接这些机器,我们也很容易使用Ribbon实现自定义的负载均衡算法。
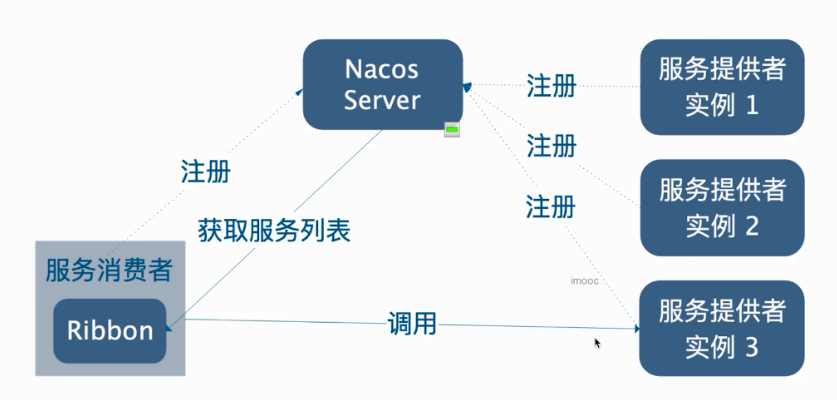
7.2 RestTemplate在访问服务的时候加入负载均衡
@Bean
@LoadBalanced //加上该注解就会集成负载均衡
public RestTemplate rt() {
return new RestTemplate();
}
//负载均衡访问:
String value = rt.getForObject("http://注册到nacos的服务名/user/findUser", String.class);
- 负载均衡是什么?有什么意义?
负载均衡就是优化资源使用,最大吞吐量,最小化响应时间并且避免任何单一资源的过载。
- cloud里面谁来做负载均衡(LoadBlancedClient)
7.3 Ribbon内置的负载均衡策略
| 规则名称 | 特点 | | —- | —- | | AvailabilityFilteringRule | 过滤掉一直连接失败的被标记为circuit tripped的后端Server,并过滤掉那些高并发的后端Server或则使用一个AvailabilityPredicate来包含过滤Server的逻辑,其实就是检查status里面记录的各个Server的运行状态 | | BestAvailableRule | 选择一个最小的并发请求的Server,逐个考察Server,如果Server被tripped了,则跳过 | | RandomRule | 随机选择一个Server | | RetryRule | 对选定的负载均衡策略机上重试机制,在一个配置时间段内当选择Server不成功,则一直尝试使用subRule的方式选择一个可用的Server | | RoundRobinRule | 轮询选择,轮询index,选择index对应位置的Server | | WeightedResponseTimeRule | 根据响应时间加权,响应时间越长,权重越小,被选中的可能性越低 | | ZoneAvoidanceRule | 符合判断Server所Zone的性能和Server的可用性选择Server,在没有Zone的环境下,类似于轮询(RoundRobinRule) |
7.4 Ribbon的配置接口(了解)
| 接口 | 配置 | 默认值 |
|---|---|---|
| IClientConfig | 读取配置 | DefaultClientConfigImpl |
| IRule | 负载均衡规则,选择实例 | ZoneAvoidanceRule |
| IPing | 筛选掉ping不通的实例 | DummyPing |
| ServerList | 交给Ribbon的实例列表 | Ribbon:ConfigurationBasedServerList Spring Cloud Alibaba:NacosServerList |
| ServerListFilter | 过滤掉不符合条件的实例 | ZonePreferenceServerListFilter |
| ILoadBalancer | Ribbon的入口 | ZoneAwareLoadBalancer |
| ServerListUpdater | 更新交给Ribbon的List的策略 | PollingServerListUpdater |
7.5 Ribbon基础配置
Ribbon有两种配置方式,一是java代码配置,一种是属性配置。
代码配置如下:
@Configuration
public class RibbonConfig {
//添加负载均衡策略对象
@Bean
public IRule createIRule() {
return new WeightRule();
}
}
把上面的配置类用到主配置上面:
@Configuration
//全局配置
@RibbonClients(defaultConfiguration = RibbonConfig.class)
//局部配置
@RibbonClient(value = "服务名",configuration = RibbonConfig.class)
public class BaseConfig {
}
yml配置
users: <—其他项目项目名—>
ribbon:
NFLoadBalancerClassName: com.netfilx.loadbalancer.ConfigurationBasedServerList
<clientName>.ribbon:
NFLoadBalancerClassName: ILoadBalancer实现类
NFLoadBalancerRuleClassName: IRule实现类
NFLoadBalancerPingClassName: IPing实现类
NIWSServerListClassName: ServerList实现类
NIWSServerListFilterClassName: ServerListFilter实现类
7.6 自定义Ribbon的负载均衡规则
自定义类实现IRule接口或则继承AbstractLoadBalancerRule
public class WeightRule extends AbstractLoadBalancerRule {
//自身信息对象
@Autowired
private NacosDiscoveryProperties nacosDiscoveryProperties;
//nacos服务管理对象
@Autowired
private NacosServiceManager nsm;
@Override
public Server choose(Object key) {
//获取需要访问的服务名
BaseLoadBalancer ilb = (BaseLoadBalancer)this.getLoadBalancer();
String name = ilb.getName();
//获取自身的clusterName
String clusterName = nacosDiscoveryProperties.getClusterName();
//获取nacos服务发现对象
NamingService ns = nsm.getNamingService(nacosDiscoveryProperties.getNacosProperties());
try {
//获取所有的需要访问的服务节点
List<Instance> insts = ns.getAllInstances(name);
//过滤出相同集群的节点
List<Instance> clusterInstances = insts.stream().filter(x -> {
if(StringUtils.isNotEmpty(clusterName) && StringUtils.isNotEmpty(x.getClusterName())) {
if(clusterName.equals(x.getClusterName())) return true;
}
return false;
}).collect(Collectors.toList());
insts = clusterInstances != null && clusterInstances.size() > 0 ? clusterInstances:insts;
//通过权重算法获取该服务的一个实例
Instance instance = MyBalancer.getHostByRandomWeight(insts);
return new NacosServer(instance);
} catch (NacosException e) {
e.printStackTrace();
return null;
}
}
@Override
public void initWithNiwsConfig(IClientConfig clientConfig) {
}
//拉取权重调用算法
static class MyBalancer extends Balancer {
public static Instance getHostByRandomWeight(List<Instance> hosts) {
return Balancer.getHostByRandomWeight(hosts);
}
}
}
8 Feign
8.1 Feign概述
运行流程:
(1)在开发微服务时,会在主程序入口添加@EnableFeignClients注解开启对Feign Client扫描加载处理。根据Feign Client的开发规范,定义接口并加@FeignClient注解。
(2)当程序启动时,会进行包扫描,扫描所有@FeignClient注解的类,并将这些信息注入Spring IoC容器中。
(3)然后又RequestTemplate生成Request,然后把这个Request交给client处理,这里指的Client可以是JDK原生的URLConnection、Apache的Http Client,也可以是Okhttp。最后Client被封装到LoadBalanceClient类,这个类结合Ribbon负载均衡发起服务之间的调用。
原理:当定义的Feign接口中的方法并调用时,通过JDK的代理方式,来生成具体的RequestTemplate。当生成代理时,Feign会为每个接口方法创建一个RequestTemplate对象,该对象封装了HTTP请求需要的全部信息,如请求参数名、请求方法等信息都在这个过程中确定。
前面的可以发现当我们通过RestTemplate调用其它服务的API时,所需要的参数须在请求的URL中进行拼接,如果参数少的话或许我们还可以忍受,一旦有多个参数的话,这时拼接请求字符串就会效率低下。<br /> Feign是一个声明式的Web Service客户端,它的目的就是让Web Service调用更加简单。Feign提供了HTTP请求的模板,通过编写简单的接口和插入注解,就可以定义好HTTP请求的参数、格式、地址等信息。而Feign则会完全代理HTTP请求,我们只需要像调用方法一样调用它就可以完成服务请求及相关处理。Feign整合了Ribbon和Sentinel(关于Sentinel我们后面再讲),可以让我们不再需要显式地使用这两个组件<br />Feign具有如下特性:
- 可插拔的注解支持,包括Feign注解和JAX-RS注解;
- 支持可插拔的HTTP编码器和解码器;
- 支持Sentinel和它的Fallback;
- 支持Ribbon的负载均衡;
支持HTTP请求和响应的压缩;
这看起来有点像我们springmvc模式的Controller层的RequestMapping映射。这种模式是我们非常喜欢的。Feign是用@FeignClient来映射服务的。
Feign是以接口方式进行调用,而不是通过RestTemplate来调用,feign底层还是ribbon,它进行了封装,让我们调用起来更加happy.总结,就是feign通过一个本地对服务接口的代理,进行对注册到注册中心的服务调用,对于调用者来说,就像调用本地接口一样。8.2 Feign的操作
导包
<dependency> <groupId>org.springframework.cloud</groupId>. </dependency>feign接口编写 ```java @FeignClient(name = “接口对应需要调用的服务名”) public interface UserFeignClient {
@GetMapping("/getUser") public String getUserByNewsId(@RequestParam(required = false) Integer nid); @GetMapping("/test1") public String test1(@RequestParam("p1") String p1, @RequestParam("p2") Integer p2); @GetMapping("/query") public List<UserDto> query(@SpringQueryMap/*表单参数注解*/ UserDto user); @PostMapping("/queryJson") public UserDto queryJson(@RequestBody UserDto user); @GetMapping("/list") public List<UserDto> list(); @GetMapping("/getById/{id}") public UserDto getById(@PathVariable Integer id);}
//启动类写上 @EnableFeignClient
3. 调用
```java
@Autowired
private UserFeignClient userFeignClient;
UserDto user = userFeignClient.getById(1);
8.3 Feign的配置
8.3.1 Java配置
编写配置类
@Configuration public class FeignConfig { //Feign的日志级别配置 @Bean public Level createLevel() { return Level.FULL; } }在主配置类指定
@FeignClient(configuration = FeignConfig.class) public class BaseConfig {}8.3.2 属性配置
feign: client: config: default: #这里可以换成服务名进行局部配置 logger-level: full httpclient: enabled: true #开启httpclient连接池配置 max-connections: 200 max-connections-per-route: 50 connection-timeout: 2000009 Sentinel
9.1 雪崩效用
服务雪崩效应是一种因“服务提供者的不可用”(原因)导致“服务调用者不可用”(结果),并将不可用逐渐放大的现象。如下图所示:
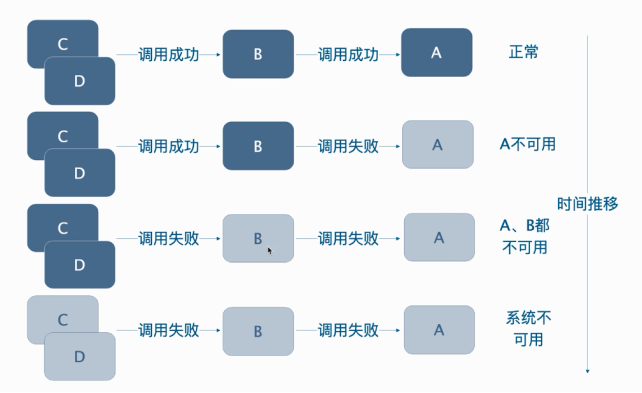
9.2 服务容错
我们没办法预防雪崩效应的发生,只能尽可能的去做好容错。容错就是提供服务不可用的一种处理方式,避免雪崩。常见的服务容错的机制如下:
- 超时
超时模式,是一种最常见的容错模式,常见的有设置网络连接超时时间,一次RPC的响应超时时间等。在分布式服务调用的场景中,它主要解决了当依赖服务出现建立网络连接或响应延迟,不用无限等待的问题,调用方可以根据事先设计的超时时间中断调用,及时释放关键资源,如Web容器的连接数,数据库连接数等,避免整个系统资源耗尽出现拒绝对外提供服务这种情况。 - 限流
限流是指在一段时间内,定义某个客户或应用可以接收或处理多少个请求的技术。例如,通过限流,你可以过滤掉产生流量峰值的客户和微服务,或者可以确保你的应用程序在自动扩展(Auto Scaling)失效前都不会出现过载的情况。你还可以阻止较低优先级的流量,以便为关键事务提供足够的资源。 - 断路器
当在短时间内多次发生指定类型的错误,断路器会开启。开启的断路器可以拒绝接下来更多的请求 – 就像防止真实的电子流动一样。断路器通常在一定时间后关闭,以便为底层服务提供足够的空间来恢复。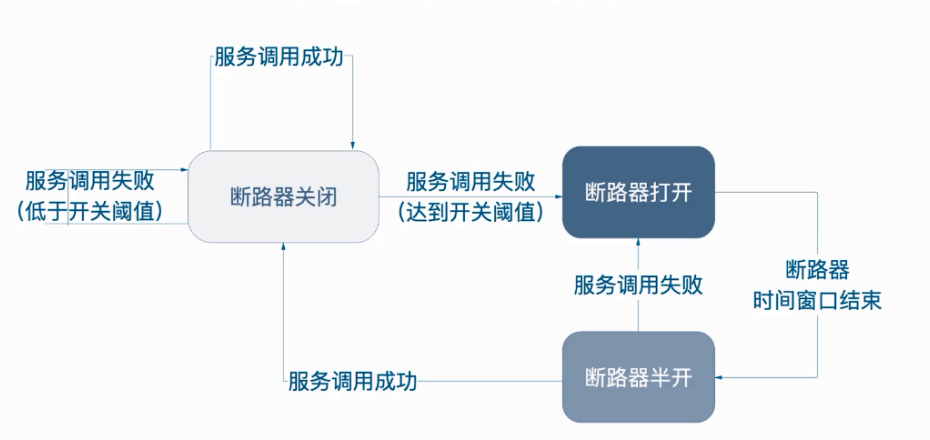
仓壁模式
在工业领域中,常使用舱壁将划分为几个部分,以便在有某部分船体发生破裂时,其他部分依然能密封安然无恙。舱壁的概念也可以在软件开发中用于隔离资源。通过使用舱壁模式,我们可以保护有限的资源不被用尽。例如,如果我们有两种类型的操作的话,它们都是和同一个数据库实例进行通信,并且数据据库限制连接数,这时我们可以使用两个连接池而不是使用一个共享的连接池。由于这种客户端和资源分离,超时或过度使用池的操作不会令所有其他操作失效。泰坦尼克号沉没的主要原因之一是其舱壁设计失败,水可以通过上面的甲板倒在舱壁的顶部,最后整个船淹没。9.3 引入sentinel
Sentinel 是面向分布式服务架构的轻量级流量控制产品,主要以流量为切入点,从流量控制、熔断降级、系统负载保护等多个维度来帮助您保护服务的稳定性。
导包
<dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-sentinel</artifactId> </dependency>下载控制台
https://github.com/alibaba/Sentinel/releases
下载下来是一个jar包 直接通过 java命令启动配置跟控制台的通信
spring: cloud: sentinel: transport: dashboard: localhost:8080 #控制台地址注意:有些版本 sentinel包引入进来后数据响应会转换成xml,需要去掉一个依赖
<groupId>com.fasterxml.jackson.dataformat</groupId> <artifactId>jackson-dataformat-xml</artifactId>9.4 流量控制
9.4.1 控制模式
直接: 针对资源自己直接进行流量控制
- 关联: 监控关联资源的流量情况来对自身资源进行限制
链路: 对资源内部调用的资源进行入口来源的限制
注意: 链路的支持需要设置sentinel的url关闭聚合,在某些版本(1.7.2+)提供了属性来关闭spring: cloud: sentinel: web-context-unify: false #关闭聚合-
9.4.2 控制效果
快速失败: 达到阀值之后直接抛异常。
- Warm Up: 当流量在某一瞬间很大的时候,它不会让流量立即到达阀值,而是进过一段时间慢慢的预热增长。
排队通过:请求达到阀值进行匀速排队通过。 ```java @GetMapping(“/one”) public void one(){
System.out.println(userFeignClient.setOne());}
@GetMapping(“/addRule”) public String addRule(){
ArrayList<FlowRule> rules = new ArrayList<>(); FlowRule rule=new FlowRule(); rule.setResource("/one"); rule.setGrade(RuleConstant.FLOW_GRADE_QPS); rule.setCount(2);//设置每秒访问次数的阈值 rules.add(rule); FlowRuleManager.loadRules(rules); return "wu";}
<a name="02587456"></a>
## 9.5 降级策略
1. RT: 平均响应时间,当 1s 内持续进入 N 个请求,对应时刻的平均响应时间(秒级)均超过阈值(count,以 ms 为单位),那么在接下的时间窗口(DegradeRule 中的 timeWindow,以 s 为单 位)之内,对这个方法的调用都会自动地熔断(抛出 DegradeException)。
1. 异常比例: 通过每秒的异常总数计算比例。
1. 异常数量:
<a name="e1caf271"></a>
## 9.6 热点参数
热点参数是对调用接口时候传入某个参数进行流控,这种方式需要设置[@SentinelResource ](/SentinelResource )
<a name="6cc72ccd"></a>
## 9.7 集群流控(了解)
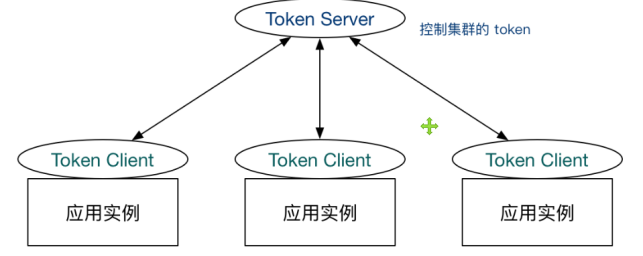
集群流控中共有两种身份:<br />Token Client:集群流控客户端,用于向所属 Token Server 通信请求 token。集群限流服务端会返回给客户端结果,决定是否限流。Token Server:即集群流控服务端,处理来自 Token Client 的请求,根据配置的集群规则判断是否应该发放 token(是否允许通过)。
<a name="b3ae5a6d"></a>
## 9.8 三大接口
1. BlockExceptionHandler: 提供sentinel异常处理,Sentinel流控有默认的处理程序,可以通过实现该接口覆盖。
```java
@Component
public class MyUrlBlockHandler implements BlockExceptionHandler{
@Override
public void handle(HttpServletRequest request, HttpServletResponse response, BlockException e)
throws Exception {
System.out.println(e.getClass().getName());
response.setContentType("application/json;charset=utf8");
response.setCharacterEncoding("utf-8");
response.getWriter().write("{\"msg\":\"被流控了\"}");
response.getWriter().flush();
}
}
RequestOriginParser: 请求解析,可以用在正对来源以及黑白名单里面来返回来源数据进行匹配,下面的例子,通过参数Who来携带来源信息,代码中提取来源数据返回 ```java @Component public class MyReqeustParse implements RequestOriginParser {
@Override public String parseOrigin(HttpServletRequest request) {
return request.getParameter("who");}
}
3. UrlCleaner: 重新定义资源,可以从新定义资源埋点的名称,可以用来聚合一些动态的资源名。
<a name="a1d62e4e"></a>
## 9.9 [@SentinelResource ](/SentinelResource )
用于定义需要流控的资源,并提供可选的异常处理和 fallback 配置项,可以通过以下属性关闭掉默认的埋点,关闭 之后就只能通过@SentinelResource来自定义资源,自定义资源需要自己定义流控异常的处理。
```yaml
spring:
cloud:
sentinel:
filter:
enabled: false
下面是一个例子:
@SentinelResource(value = "newsServer", blockHandler = "blackNewsServer", fallback = "fallbackNewsServer")
@GetMapping("/news4")
public String newsServer(String id) { }
public String fallbackNewsServer(String id,Throwable e) {
return "出现异常了....";
}
public String blackNewsServer(String id,BlockException e) {
return "限流或则降级了....";
}
属性解释:
- value: 资源的名称
- blockHandler: 流控异常处理的函数名称
函数访问范围需要是 public,返回类型需要与原方法相匹配,参数类型需要和原方法相匹配,并且最后加一个额外的参数,类型为 BlockException。函数默认需要和原方法在同一个类中。若希望使用其他类的函数,则可以指定 blockHandlerClass 为对应的类的 Class 对象,注意对应的函数必需为 static 函数。 fallback : 异常处理的函数名称
返回值类型必须与原函数返回值类型一致,方法参数列表需要和原函数一致,可以多一个Throwable参数用于接收对应的异常。函数默认需要和原方法在同一个类中。若希望使用其他类的函数,可以指定 fallbackClass 为对应的类的 Class 对象,注意对应的函数必需为 static 函数。9.10 对Feign以及RestTemplate的支持
对Feign的支持
#配置开关: feign: sentinel: enabled: true
//fallback属性用来定义异常处理类
@FeignClient(name="service-provider",fallback=EchoServiceFallback.class,)
public interface EchoService {
@GetMapping("/echo/{str}")
public String echo(@PathVariable("str") String str);
}
//异常处理类实现Feign接口重写所有接口方法的异常之后的处理
class EchoServiceFallback implements EchoService {
@Override
public String echo(@PathVariable("str") String str) {
return "echo fallback";
}
}
- 对RestTemplate的支持
```java
@Bean
@SentinelRestTemplate(blockHandler = “handleException”, blockHandlerClass = ExceptionUtil.class)
public RestTemplate restTemplate() {
}return new RestTemplate();
//blockHandler 属性对应的处理方法 public ClientHttpResponse handleException(HttpRequest request, byte[] body, ClientHttpRequestExecution execution, BlockException exception) { … }
//这是上面blockHandlerClass 属性对应的静态方法类 public class ExceptionUtil { public static ClientHttpResponse handleException(HttpRequest request, byte[] body, ClientHttpRequestExecution execution, BlockException exception) { … } }
<a name="0d8e380f"></a>
## 9.11 通过ahas来进行sentinel的控制(阿里云网站有详细步骤)
<a name="521527d5"></a>
# 10 Gateway
网关是一个Api服务器,是系统的唯一入口。为每个客户端提供一个定制的Restful API。同时它还需要具有一些业务之外的责任:鉴权。静态响应等处理。网关的最主要在作用就是路由的转发 。但是 在我们平时的使用过程中,直接请求http 协议的 api 会存在很多问题。例如:安全问题,流量问题 等等。所以gateway 还需要做一些额外的 事情来保证我们的流程是安全的、可靠的。
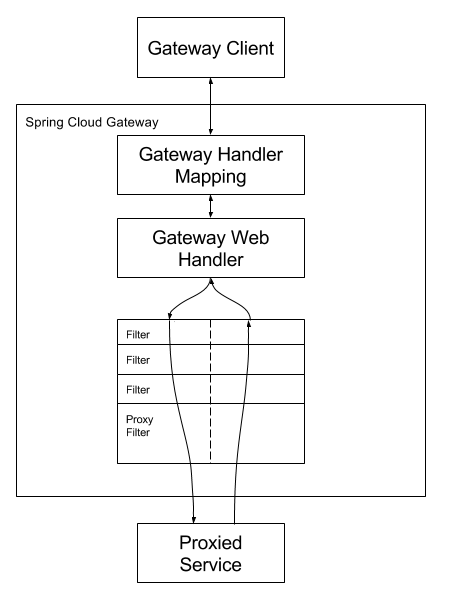<br /> 客户端向Spring Cloud Gateway发出请求。网关处理程序映射确定请求与路由匹配,则将其发送到网关Web处理程序。该处理程序通过特定于请求的过滤器链运行请求。<br />具体流程如下:
1. Gateway Client向Gateway Server发送请求
1. 请求首先会被HttpWebHandlerAdapter进行提取组装成网关上下文
1. 然后网关的上下文会传递到DispatcherHandler,它负责将请求分发给 RoutePredicateHandlerMapping
1. RoutePredicateHandlerMapping负责路由查找,并根据路由断言判断路由是否可用
1. 如果过断言成功,由FilteringWebHandler创建过滤器链并调用
1. 请求会一次经过PreFilter–微服务–PostFilter的方法,最终返回响应
<a name="b0d9faaf"></a>
## 10.1 引入网关
1. 导包
```xml
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-gateway</artifactId>
</dependency>
开启默认路由设置
spring: cloud: gateway: discovery: locator: enabled: true默认路由配置的访问方式:http://网关ip:port/具体服务名/**
10.2 rotue(路由)
路由就是将不同的请求映射到不同的后端集群中,这是网关的核心功能,它由ID,目标URI,谓词集合和过滤器集合定义。
routes: - id: #定义需要路由的服务唯一标识 uri: #定义服务的访问地址,可以是当前nacos上的服务:lb://服务名,也可以上网络服务http:// filters:#定义一组过滤器 - xxx predicates: #定义一组谓词工厂 - Path=/news/**10.3 Prendicate(谓词工厂)
After
spring: cloud: gateway: routes: - id: after_user uri: lb://user-server predicates: # 当且仅当请求时的时间After配置的时间时,才会转发到用户微服务 # 目前配置不会进该路由配置,所以返回404 # 将时间改成 < now的时间,则访问localhost:8040/** -> user-center/** # eg. 访问http://localhost:8040/users/1 -> user-center/users/1 - After=2030-01-20T17:42:47.789-07:00[America/Denver]Before
spring: cloud: gateway: routes: - id: before_user uri: lb://user-server predicates: # 当且仅当请求时的时间Before配置的时间时,才会转发到用户微服务 # 目前配置不会进该路由配置,所以返回404 # 将时间改成 > now的时间,则访问localhost:8040/** -> user-center/** # eg. 访问http://localhost:8040/users/1 -> user-center/users/1 - Before=2018-01-20T17:42:47.789-07:00[America/Denver]Between
spring: cloud: gateway: routes: - id: between_user uri: lb://user-server predicates: # 当且仅当请求时的时间Between配置的时间时,才会转发到用户微服务 # 因此,访问localhost:8040/** -> user-center/** # eg. 访问http://localhost:8040/users/1 -> user-center/users/1 - Between=2017-01-20T17:42:47.789-07:00[America/Denver], 2027-01-21T17:42:47.789-07:00[America/Denver]Cookie
spring: cloud: gateway: routes: - id: cookie_user uri: lb://user-server predicates: # 当且仅当带有名为somecookie,并且值符合正则ch.p的Cookie时,才会转发到用户服务 # 如Cookie满足条件,则访问http://localhost:8040/** -> user-center/** # eg. 访问http://localhost:8040/users/1 -> user-center/users/1 - Cookie=somecookie, ch.pHeader
spring: cloud: gateway: routes: - id: header_user uri: lb://user-server predicates: # 当且仅当带有名为X-Request-Id,并且值符合正则\d+的Header时,才会转发到用户服务 # 如Header满足条件,则访问http://localhost:8040/** -> user-center/** # eg. 访问http://localhost:8040/users/1 -> user-center/users/1 - Header=X-Request-Id, \d+Host
spring: cloud: gateway: routes: - id: host_user uri: lb://user-server predicates: # 当且仅当名为Host的Header符合**.somehost.org或**.anotherhost.org时,才会转发用户微服务 # 如Host满足条件,则访问http://localhost:8040/** -> user-center/** # eg. 访问http://localhost:8040/users/1 -> user-center/users/1 - Host=**.somehost.org,**.anotherhost.orgMethod
spring: cloud: gateway: routes: - id: method_user uri: lb://user-server predicates: # 当且仅当HTTP请求方法是GET时,才会转发用户微服务 # 如请求方法满足条件,访问http://localhost:8040/** -> user-center/** # eg. 访问http://localhost:8040/users/1 -> user-center/users/1 - Method=GETPath
spring: cloud: gateway: routes: - id: path_user uri: lb://user-server predicates: # 当且仅当访问路径是/users/*或者/some-path/**,才会转发用户微服务 # segment是一个特殊的占位符,单层路径匹配 # eg. 访问http://localhost:8040/users/1 -> user-center/users/1 - Path=/users/{segment},/some-path/**Query
spring: cloud: gateway: routes: - id: query_user uri: lb://user-server predicates: # 当且仅当请求带有baz的参数,才会转发到用户微服务 # eg. 访问http://localhost:8040/users/1?baz=xx -> user-center的/users/1 - Query=bazRemoteAddr
spring: cloud: gateway: routes: - id: remoteaddr_user uri: lb://user-server predicates: # 当且仅当请求IP是192.168.1.1/24网段,例如192.168.1.10,才会转发到用户微服务 # eg. 访问http://localhost:8040/users/1 -> user-center的/users/1 - RemoteAddr=192.168.1.1/2410.4 filter
过滤器,用来在请求与相应之间做统一的逻辑处理,生命周期有两个层次,一个是请求过来可以过滤,响应回去也可以过滤,过滤器分为全局过滤器以及局部过滤器。
我们可以创建过滤器工厂来定义过滤器而方便配置AddRequestHeaderGatewayFilterFactory
spring: cloud: gateway: routes: - id: add_request_header_route uri: https://example.org filters: #为原始请求添加名为 X-Request-Foo ,值为 Bar 的请求头。 - AddRequestHeader=X-Request-Foo, BarAddRequestParameterGatewayFilterFactory
spring: cloud: gateway: routes: - id: add_request_parameter_route uri: https://example.org filters: #为原始请求添加请求参数 foo=bar - AddRequestParameter=foo, barAddResponseHeaderGatewayFilterFactory
spring: cloud: gateway: routes: - id: add_response_header_route uri: https://example.org filters: #添加名为 X-Request-Foo ,值为 Bar 的响应头。 - AddResponseHeader=X-Response-Foo, BarDedupeResponseHeaderGatewayFilterFactory
spring: cloud: gateway: routes: - id: dedupe_response_header_route uri: https://example.org filters: -DedupeResponseHeader=Access-Control-Allow-Credentials Access-Control-Allow-Origin,RETAIN_FIRSTPrefixPathGatewayFilterFactory
spring: cloud: gateway: routes: - id: prefixpath_route uri: https://example.org filters: #为匹配的路由添加前缀。例如:访问${GATEWAY_URL}/hello 会转发到https://example.org/mypath/hello - PrefixPath=/mypathPreserveHostHeaderGatewayFilterFactory
spring: cloud: gateway: routes: - id: preserve_host_route uri: https://example.org filters: #如果不设置,那么名为 Host 的Header由Http Client控制;如果设置了,那么会设置一个请求属性 #路由过滤器会检查从而去判断是否要发送原始的、名为Host的Header。 - PreserveHostHeaderRequestRateLimiterGatewayFilterFactory
spring: cloud: gateway: routes: - id: requestratelimiter_route uri: https://example.org filters: - name: RequestRateLimiter args: redis-rate-limiter.replenishRate: 10 redis-rate-limiter.burstCapacity: 20RedirectToGatewayFilterFactory
spring: cloud: gateway: routes: - id: prefixpath_route uri: https://example.org filters: # 配置成HTTP状态码, URL的形式 - RedirectTo=302, http://www.itmuch.comRemoveRequestHeaderGatewayFilterFactory
spring: cloud: gateway: routes: - id: removerequestheader_route uri: https://example.org filters: #为原始请求删除名为 X-Request-Foo 的请求头 - RemoveRequestHeader=X-Request-FooRemoveResponseHeaderGatewayFilterFactory
spring: cloud: gateway: routes: - id: removeresponseheader_route uri: https://example.org filters: #删除名为 X-Request-Foo 的响应头 - RemoveResponseHeader=X-Response-FooRewritePathGatewayFilterFactory
spring: cloud: gateway: routes: - id: rewritepath_route uri: https://example.org predicates: - Path=/foo/** filters: # 配置成原始路径正则, 重写后的路径的正则 - RewritePath=/foo/(?<segment>.*), /$\{segment}
重写请求路径。如上配置,访问 /foo/bar 会将路径改为/bar 再转发,也就是会转发到 https://example.org/bar 。需要注意的是,由于YAML语法,需用$\ 替换 $ 。
RewriteResponseHeaderGatewayFilterFactory
spring:
cloud:
gateway:
routes:
- id: rewriteresponseheader_route
uri: https://example.org
filters:
- RewriteResponseHeader=X-Response-Foo, password=[^&]+, password=***
如果名为 X-Response-Foo 的响应头的内容是/42?user=ford&password=omg!what&flag=true,则会被修改为/42?user=ford&password=*&flag=true。
SaveSessionGatewayFilterFactory
spring:
cloud:
gateway:
routes:
- id: save_session
uri: https://example.org
predicates:
- Path=/foo/**
filters:
- SaveSession
在转发到后端微服务请求之前,强制执行 WebSession::save 操作。用在那种像 Spring Session 延迟数据存储(笔者注:数据不是立刻持久化)的,并希望在请求转发前确保session状态保存情况。
如果你将Spring Secutiry于Spring Session集成使用,并想确保安全信息都传到下游机器,你就需要配置这个filter。
SetPathGatewayFilterFactory
spring:
cloud:
gateway:
routes:
- id: setpath_route
uri: https://example.org
predicates:
- Path=/foo/{segment}
filters:
- SetPath=/{segment}
采用路径template参数,通过请求路径的片段的模板化,来达到操作修改路径的母的,运行多个路径 片段模板化。
如上配置,访问${GATEWAY_PATH}/foo/bar ,则对于后端微服务的路径会修改为 /bar 。
SetResponseHeaderGatewayFilterFactory
spring:
cloud:
gateway:
routes:
- id: setresponseheader_route
uri: http://example.org
filters:
- SetResponseHeader=X-Response-Foo, Bar
如果后端服务响应带有名为 X-Response-Foo 的响应头,则将值改为替换成 Bar 。
SetStatusGatewayFilterFactory
spring:
cloud:
gateway:
routes:
- id: setstatusstring_route
uri: http://example.org
filters:
- SetStatus=BAD_REQUEST
- id: setstatusint_route
uri: http://example.org
filters:
- SetStatus=401
修改响应的状态码,值可以是数字,也可以是字符串。但一定要是Spring HttpStatus 枚举类中的值。 如上配置,两种方式都可以返回HTTP状态码401。
StripPrefixGatewayFilterFactory
spring:
cloud:
gateway:
routes:
- id: nameRoot
uri: http://nameservice
predicates:
- Path=/name/**
filters:
- StripPrefix=2
数字表示要截断的路径的数量。如上配置,如果请求的路径为 /name/bar/foo ,则路径会修改为/foo , 也就是会截断2个路径
RetryGatewayFilterFactory
spring:
cloud:
gateway:
routes:
- id: retry_test
uri: http://localhost:8080/flakey
predicates:
- Host=*.retry.com
filters:
- name: Retry
args:
retries: 3
statuses: BAD_GATEWAY
针对不同的响应做重试,可配置如下参数:
retries: 重试次数
statuses: 需要重试的状态码,取值在 org.springframework.http.HttpStatus 中
methods: 需要重试的请求方法,取值在 org.springframework.http.HttpMethod 中
series: HTTP状态码系列,取值在 org.springframework.http.HttpStatus.Series 中
RequestSizeGatewayFilterFactory
spring:
cloud:
gateway:
routes:
- id: request_size_route
uri: http://localhost:8080/upload
predicates:
- Path=/upload
filters:
- name: RequestSize
args:
# 单位字节
maxSize: 5000000
为后端服务设置收到的最大请求包大小。如果请求大小超过设置的值,则返回 413 Payload Too Large ,默认值是5M
10.5 自定义过滤器
全局过滤器:所有的路由都生效。实现GlobalFilter接口,Ordered接口是用来规定执行顺序
@Component public class MyGlobaleFilter implements GlobalFilter ,Ordered{ @Override public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) { System.out.println("========全局拦截器==========="); return chain.filter(exchange); } @Override public int getOrder() { return 1; } }过自定义过滤器工厂来实现局部过滤
//继承父类接口的泛型规定了参数对象类型 @Component public class AuthenticationGatewayFilterFactory extends AbstractGatewayFilterFactory<AuthenticationGatewayFilterFactory.Config> { //构造方法对参数对象进行说明 public AuthenticationGatewayFilterFactory() { super(Config.class); } //用来指定参数的顺序,当前无 @Override public List<String> shortcutFieldOrder() { return Arrays.asList(); } //用来接收参数的类,该过滤器不需要参数 public static class Config {} //创建过滤器对象,能够从config里面获取传递的参数 @Override public GatewayFilter apply(Config config) { return (exchange,chain) -> { System.out.println(“====进入认证过滤器====”); return chain.filter(exchange); }; } }1 异常类处理
11 JWT
son web token (JWT), 是为了在网络应用环境间传递声明而执行的一种基于JSON的开放标准((RFC 7519).该token被设计为紧凑且安全的,特别适用于分布式站点的单点登录(SSO)场景。JWT的声明一般被用来在身份提供者和服务提供者间传递被认证的用户身份信息,以便于从资源服务器获取资源,也可以增加一些额外的其它业务逻辑所必须的声明信息,该token也可直接被用于认证,也可被加密。
11.1 传统的session认证
我们知道,http协议本身是一种无状态的协议,而这就意味着如果用户向我们的应用提供了用户名和密码来进行用户认证,那么下一次请求时,用户还要再一次进行用户认证才行,因为根据http协议,我们并不能知道是哪个用户发出的请求,所以为了让我们的应用能识别是哪个用户发出的请求,我们只能在服务器存储一份用户登录的信息,这份登录信息会在响应时传递给浏览器,告诉其保存为cookie,以便下次请求时发送给我们的应用,这样我们的应用就能识别请求来自哪个用户了,这就是传统的基于session认证。
但是这种基于session的认证使应用本身很难得到扩展,随着不同客户端用户的增加,独立的服务器已无法承载更多的用户,而这时候基于session认证应用的问题就会暴露出来.11.2 基于session认证所显露的问题
Session: 每个用户经过我们的应用认证之后,我们的应用都要在服务端做一次记录,以方便用户下次请求的鉴别,通常而言session都是保存在内存中,而随着认证用户的增多,服务端的开销会明显增大。
- 扩展性: 用户认证之后,服务端做认证记录,如果认证的记录被保存在内存中的话,这意味着用户下次请求还必须要请求在这台服务器上,这样才能拿到授权的资源,这样在分布式的应用上,相应的限制了负载均衡器的能力。这也意味着限制了应用的扩展能力。
CSRF: 因为是基于cookie来进行用户识别的, cookie如果被截获,用户就会很容易受到跨站请求伪造的攻击。
11.3 基于token的鉴权机制
基于token的鉴权机制类似于http协议也是无状态的,它不需要在服务端去保留用户的认证信息或者会话信息。这就意味着基于token认证机制的应用不需要去考虑用户在哪一台服务器登录了,这就为应用的扩展提供了便利。
流程上是这样的:用户使用用户名密码来请求服务器
- 服务器进行验证用户的信息
- 服务器通过验证发送给用户一个token
- 客户端存储token,并在每次请求时附送上这个token值
-
11.4 JWT长什么样?
JWT是由三段信息构成的,将这三段信息文本用.链接一起就构成了Jwt字符串。就像这样:
eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJzdWIiOiIxMjM0NTY3ODkwIiwibmFtZSI6IkpvaG4gRG9lIiwiYWRtaW4iOnRydWV9.TJVA95OrM7E2cBab30RMHrHDcEfxjoYZgeFONFh7HgQ11.5 JWT的构成
第一部分我们称它为头部(header),第二部分我们称其为载荷(payload, 类似于飞机上承载的物品),第三部分是签证(signature).
header
jwt的头部承载两部分信息:
声明类型,这里是jwt
声明加密的算法 通常直接使用 HMAC SHA256
完整的头部就像下面这样的JSON:{ 'typ': 'JWT', 'alg': 'HS256' }然后将头部进行base64加密(该加密是可以对称解密的),构成了第一部分.
eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9playload
载荷就是存放有效信息的地方。这个名字像是特指飞机上承载的货品,这些有效信息包含三个部分:- 标准中注册的声明
iss: jwt签发者
sub: jwt所面向的用户
aud: 接收jwt的一方
exp: jwt的过期时间,这个过期时间必须要大于签发时间
nbf: 定义在什么时间之前,该jwt都是不可用的.
iat: jwt的签发时间
jti: jwt的唯一身份标识,主要用来作为一次性token,从而回避重放攻击。 - 公共的声明
公共的声明可以添加任何的信息,一般添加用户的相关信息或其他业务需要的必要信息.但不建议添加敏感信息,因为该部分在客户端可解密 - 私有的声明
私有声明是提供者和消费者所共同定义的声明,一般不建议存放敏感信息,因为base64是对称解密的,意味着该部分信息可以归类为明文信息。
- 标准中注册的声明
定义一个payload:
{
"sub": "1234567890",
"name": "John Doe",
"admin": true
}
然后将其进行base64加密,得到Jwt的第二部分:
eyJzdWIiOiIxMjM0NTY3ODkwIiwibmFtZSI6IkpvaG4gRG9lIiwiYWRtaW4iOnRydWV9
signature
jwt的第三部分是一个签证信息,这个签证信息由三部分组成:
header (base64后的)
payload (base64后的)
secret: 加盐
这个部分需要base64加密后的header和base64加密后的payload使用.连接组成的字符串,然后通过header中声明的加密方式进行加盐secret组合加密,然后就构成了jwt的第三部分。
将这三部分用.连接成一个完整的字符串,构成了最终的jwt:eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJzdWIiOiIxMjM0NTY3ODkwIiwibmFtZSI6IkpvaG4gRG9lIiwiYWRtaW4iOnRydWV9.TJVA95OrM7E2cBab30RMHrHDcEfxjoYZgeFONFh7HgQ注意:secret是保存在服务器端的,jwt的签发生成也是在服务器端的,secret就是用来进行jwt的签发和jwt的验证,所以,它就是你服务端的私钥,在任何场景都不应该流露出去。一旦客户端得知这个secret, 那就意味着客户端是可以自我签发jwt了。
11.6 JWT总结
优点
· 因为json的通用性,所以JWT是可以进行跨语言支持的,像JAVA,JavaScript,NodeJS,PHP等很多语言都可以使用。
· 因为有了payload部分,所以JWT可以在自身存储一些其他业务逻辑所必要的非敏感信息。
· 便于传输,jwt的构成非常简单,字节占用很小,所以它是非常便于传输的。
· 它不需要在服务端保存会话信息, 所以它易于应用的扩展安全相关
· 不应该在jwt的payload部分存放敏感信息,因为该部分是客户端可解密的部分。
· 保护好secret私钥,该私钥非常重要。
· 如果可以,请使用https协议11.7 使用 JJWT
jjwt是java用来生成以及解析jwt的工具
导包
<dependency> <groupId>io.jsonwebtoken</groupId> <artifactId>jjwt-api</artifactId> <version>0.11.2</version> </dependency> <dependency> <groupId>io.jsonwebtoken</groupId> <artifactId>jjwt-impl</artifactId> <version>0.11.2</version> <scope>runtime</scope> </dependency> <dependency> <groupId>io.jsonwebtoken</groupId> <artifactId>jjwt-jackson</artifactId> <!-- or jjwt-gson if Gson is preferred --> <version>0.11.2</version> <scope>runtime</scope> </dependency>生成与解析 ```java @Component public class JwtUtils { @Value(“${config.jwt.secret}”) private String secret;
@Value(“${config.jwt.expire}”) private Integer expire;
/**
由字符串生成secret; */ private SecretKey generalKey(){ return Keys.hmacShaKeyFor(secret.getBytes()); }
/**
生成Token */ public String createJwt(Map
.setExpiration(new Date(System.currentTimeMillis() + expire * 60 * 1000)) .compact();}
/**
生成Token */ public String createJwt() { return createJwt(null); }
/**
解析Token,获取注册信息 */ public Claims parseJwt(String token) { return Jwts.parserBuilder().setSigningKey(generalKey()).build().parseClaimsJws(token).getBody(); }
/**
获取token失效时间 */ public Date getExpirationDateFromToken(String token) { return parseJwt(token).getExpiration(); }
/**
验证token是否过期失效 */ public boolean isTokenExpired (String token) { Date expirationTime = getExpirationDateFromToken(token); return expirationTime.before(new Date()); }
/**
获取jwt发布时间 */ public long getIssuedAtDateFromToken(String token){ return parseJwt(token).getIssuedAt().getTime(); } public String getSecret() { return secret; }
public void setSecret(String secret) { this.secret = secret; }
public Integer getExpire() { return expire; }
public void setExpire(Integer expire) { this.expire = expire; }
}
配置yml
```xml
config:
jwt:
secret: "qwertyuiopasdfghjklzxcvbnm"
expire: 60
11.8 token在服务间的传递
实际项目的过程当中,前端请求携带token如果在header里面,这里会导致一个问题,在后端第一个服务可以成功提取出token,这个时候该服务有可能还会通过Feign或者RestTemplate去调用另外一个服务,后面的服务也有可能继续发起对其他服务调用,这种情况如果第一个服务部显示的再发请求的时候继续携带token在header里面,后面的服务就取不到token,为了解决这个问题而又不需要每次手动来添加token,我们可以使用Feign以及RestTemplate的拦截器来解决。
Feign的拦截器
@Component public class TokenInterceptor implements RequestInterceptor{ @Override public void apply(RequestTemplate template) { ServletRequestAttributes sra = (ServletRequestAttributes)RequestContextHolder.getRequestAttributes(); String token = sra.getRequest().getHeader("X-Token"); if(token != null && !token.trim().equals("")) template.header("X-Token", token); } }RestTemplate拦截器
@Component public class TokenRestTemplateInterceptor implements ClientHttpRequestInterceptor{ @Override public ClientHttpResponse intercept(HttpRequest request, byte[] body, ClientHttpRequestExecution execution)throws IOException { ServletRequestAttributes sra = (ServletRequestAttributes)RequestContextHolder.getRequestAttributes(); String token = sra.getRequest().getHeader("X-Token"); if(token != null && !token.trim().equals("")) request.getHeaders().add("X-Token", token); return execution.execute(request, body); } } 或者在启动类上面创建 @LoadBalanced @Bean public RestTemplate restTemplate(){ RestTemplate restTemplate=new RestTemplate(); restTemplate.setInterceptors(Collections.singletonList( (request, body, execution) -> { ServletRequestAttributes attributes = (ServletRequestAttributes) RequestContextHolder.currentRequestAttributes(); String token = attributes.getRequest().getHeader("auth_token"); request.getHeaders().set("auth_token", token); return execution.execute(request, body); } )); return restTemplate; }注意:template的拦截器需要手动添加到对象里面:
@Bean @LoadBalanced public RestTemplate getRestTemplate() { RestTemplate rt = new RestTemplate(); rt.setInterceptors(Arrays.asList(new TokenRestTemplateInterceptor())); return rt; }认证流程
客户端保存token和refresh_token,并携带token,请求服务端资源;
服务端判断token是否过期,若没有过期,则解析token获取认证相关信息,认证通过后,将服务器资源返回给客户端;
服务端判断token是否过期,若token已过期,返回token过期提示;
客户端获取token过期提示后,用refresh_token接着继续上一次请求;
服务端判断refresh_token是否过期,若没有过期,则生成新的token和refresh_token,
并返回给客户端,客户端丢弃旧的token,保存新的token;11 分布式锁
什么是分布式锁
我们在开发应用的时候,如果需要对某一个共享数据进行多线程同步访问(增加、减少等)的时候,可以使用锁进行处理,防止在多线程环境下数据表现不一致。如果该应用部署在多个节点上面,我们就不能运用只是在单机上面表现的锁。解决分布式应用下数据一致性问题的锁称为分布式锁。
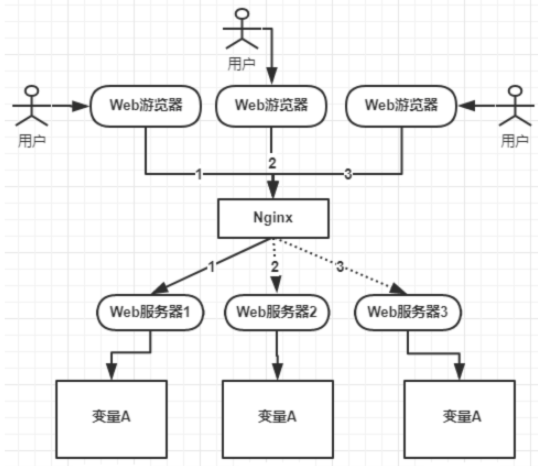
对变量A的操作锁定就需要用到分布式锁常见的实现方案
基于数据库实现分布式锁基于数据库实现分布式锁我们可以有两种方案
- 乐观锁:通过数据的版本号进行判断是否给与操作
- 悲观锁:可以用for update语句数据库自带的排它锁,也可以自行设计逻辑标识,例如创建一个表,给一个字段上唯一约束,加锁就是向该表插入数据,该字段就是锁的标识,同一时间多个请求提交到数据库由于有唯一约束也只会有一个请求数据插入成功,也就代表加锁成功,解锁就是删除数据。
- 基于Redis实现分布式锁
基于Redis实现的锁机制,主要是依赖redis自身的原子操作。可以通过向Redis里面存入一个值来代表加锁,值如果存入成功表示加锁成功,存入的时候如果值已经存在就不能存入,代表加锁失败,解锁就是删除改值。可以给值设置过期时间来防止死锁。 - Zookeeper分布式锁
ZooKeeper是一个为分布式应用提供一致性服务的开源组件,它内部是一个分层的文件系统目录树结构,规定同一个目录下只能有一个唯一文件名。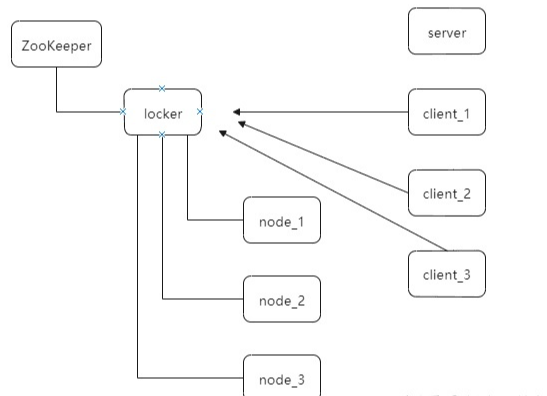
当某客户端要进行逻辑的加锁时,就在zookeeper上的某个指定节点的目录(locker目录)下生成一个唯一的临时有序节点(locker/node_N),然后判断自己是否是这些有序节点中序号最小的一个,如果是,则算是获取了锁。如果不是,则说明没有获取到锁,那么就需要在序列中找到比自己小的那个节点,并对其调用exist()方法,对其注册事件监听,当监听到这个节点被删除了,那就再去判断一次自己当初创建的节点是否变成了序列中最小的。如果是,则获取锁,如果不是,则重复上述步骤。
当释放锁的时候,只需将这个临时节点删除即可。三种方案的对比
- 数据库
实现简单,数据库性能存在瓶颈,不适合高并发场景,锁的失效时间难以控制,删除锁失败容易导致死锁。即这把锁没有失效时间,一旦解锁操作失败,就会导致锁记录一直在数据库中,其他线程无法再获得到锁。一般在分布式系统中使用这种机制实现分布式锁时,需要业务侧增加控制锁超时和重试的流程。 - Redis
性能好,实现起来较为方便。单点问题。这里的单点指的是单master,就算是个集群,如果加锁成功后,锁从master复制到slave的时候挂了,也是会出现同一资源被多个client加锁的。redis的设计定位决定了它的数据并不是强一致性的,在某些极端情况下,可能会出现问题,不够健壮。即便使用redlock算法来实现,在某些复杂场景下,也无法保证其实现100%没有问题。 - Zookeeper
能有效的解决单点问题,非阻塞问题以及锁无法释放的问题。实现起来较为简单。性能上不如使用缓存实现分布式锁,如果有较多的客户端频繁的申请加锁、释放锁,对于zk集群的压力会比较大。
如何选择?
如果系统不想引入过多网元,可以采用数据库锁实现,好处就是比较容易理解,但是这种方案业务层控制逻辑多且复杂,需要对业务侧足够了解,易于理解但是实现复杂度最高。
如果追求高性能,Redis是最佳选择,但是redis是有可能存在隐患的,可能会导致数据不对的情况,可靠性不如ZK。
如果系统已经存在ZK集群,优先选用ZK实现,实现最简单,且可以提供高可靠性,性能稍逊Redis缓存方案。
Redis实现分布式锁的原理以及流程
如何通过Redis来进行加锁?我们其实可以通过向Redis里面存一个值(Key-Value)来表示一把锁,key就是锁的标识(一般可以通过业务中的数据ID跟上前缀或则后缀的方式),Value可以是一个唯一值(可以用UUID),用来标识加锁方是谁。
具体加锁步骤可以如下:
- 准备向Redis里面存入一个值
- 判断如果该值存在就说明已经有其他线程加锁成功,现在不能存入只能等待或则加锁失败
- 如果该值不存在则当前线程存入成功(加锁成功)
- 对该值设置过期时间(锁可以在一定时间之后自动释放)
我们需要注意的是以上步骤的执行必须具备原子性,不然加锁逻辑自身就会导致冲突,如何保证原子性,我们可以使用set命令参数如下:
SET KEY VALUE EX 20 NX
如果是在SpringBoot里面我们可以调用方法:
stringRedisTemplate.opsForValue().setIfAbsent(key, value, 20, TimeUnit.SECONDS)
Redis加锁思路其实就是存入代表锁的值,谁存入了谁就拥有这把锁。解锁就是删除该值。
1.理解分布式锁
编程语言往往都会提供锁来保证线程并发访问共享变量,比如,Java 语言给我们提供了线程锁,开放了处理锁机制的 API,比如 Synchronized、Lock 等。当一个锁被某个线程持有的时候,另一个线程尝试去获取这个锁会失败或者阻塞,直到持有锁的线程释放了该锁。
在单台服务器内部,可以通过线程加锁的方式来同步。但是在分布式场景下就需要分布式锁来保证多实例并发安全访问共享变量。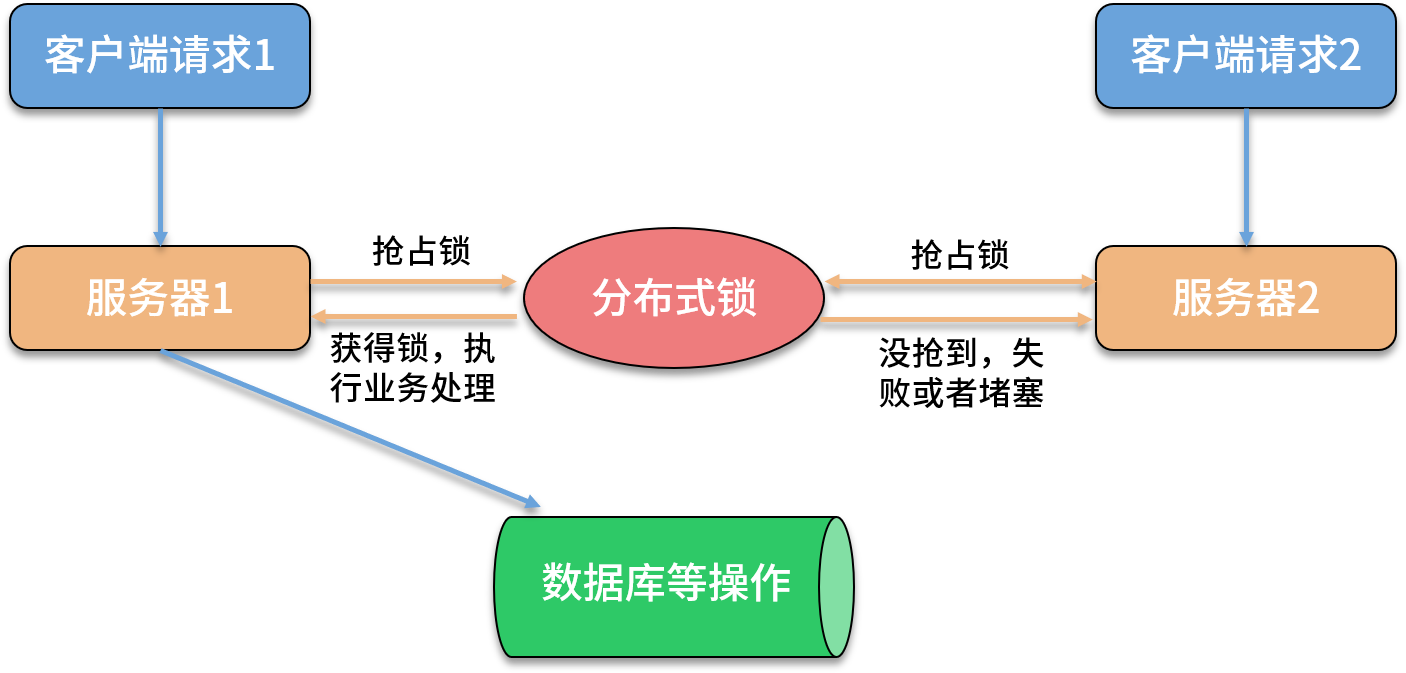
2.redis实现分布式锁的原理
1.通过setnx(lock_timeout)实现,如果设置了锁返回1, 已经有值没有设置成功返回0
2.死锁问题:通过实践来判断是否过期,如果已经过期,获取到过期时间get(lockKey),然后getset(lock_timeout)判断是否和get相同,相同则证明已经加锁成功,因为可能导致多线程同时执行getset(lock_timeout)方法,这可能导致多线程都只需getset后,对于判断加锁成功的线程, 再加expire(lockKey, LOCK_TIMEOUT, TimeUnit.MILLISECONDS)过期时间,防止多个线程同时叠加时间,导致锁时效时间翻倍。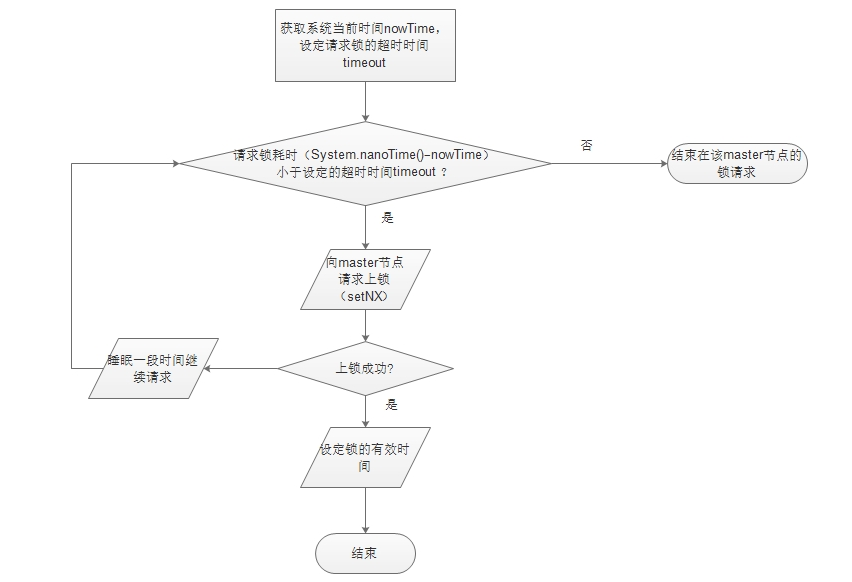
3.redisson如何实现分布式锁
定义注解@DistributedLock
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface Lock {
//锁的名称
String lockName();
//锁的存在时间
int lockLiveTimeout() default 30;
//锁的获取时间
int getLockTimeout() default 15;
String pramIndex() default "";
}
定义切面代码
@Component
@Aspect
public class LockAdvice {
@Resource
private RedissonClient redissonClient;
@Around("@annotation(com.woniuxy.car.platform.utils.Lock)")
public Object lock(ProceedingJoinPoint joinPoint) throws Throwable{
MethodSignature ms= (MethodSignature) joinPoint.getSignature();
Method method=ms.getMethod();
Lock lock=method.getDeclaredAnnotation(Lock.class);
String key=lock.lockName();
if (!lock.pramIndex().equals("")){
Object arg = joinPoint.getArgs()[0];
Field field = arg.getClass().getDeclaredField(lock.pramIndex());
field.setAccessible(true);
String string = field.get(arg).toString();
key=key+":"+string;
}
RLock rLock=redissonClient.getLock(key);
try{
rLock.tryLock(lock.lockLiveTimeout(),lock.getLockTimeout(), TimeUnit.SECONDS);
return joinPoint.proceed();
}finally {
rLock.unlock();
}
}
}
使用注解@DistributedLock实现分布式锁
@Service
public class DistributionService {
@Resource
private StringRedisTemplate stringRedisTemplate;
@Autowired
private RedissonClient redissonClient;
/*
*通过aop注解实现分布式锁,推荐
*/
@DistributedLock(key = "lock")
public void contTest(){
String cout=stringRedisTemplate.opsForValue().get("count");
int i = Integer.parseInt(cout);
if (i>0) {
i--;
stringRedisTemplate.opsForValue().set("count", i + "");
}
}
@DistributedLock(lockName = "lock", lockNamePost = ".lock")
public int aspect(Action<Integer> action) {
return action.action();
}
}
12 RocketMQ(消息队列)
消息队列是一种异步的服务间通信方式,是分布式系统中重要的组件,主要解决应用耦合,异步消息,流量削锋等问题,实现高性能,高可用,可伸缩和最终一致性架构。
12.1 消息服务介绍和使用场景
什么是AMQP: 即Advanced Message Queuing Protocol,一个提供统一消息服务的应用层标准高级消息队列协议,是应用层协议的一个开放标准,为面向消息的中间件设计。基于此协议的客户端与消息中间件可传递消息,并不受客户端中间件不同产品,不同的开发语言等条件的限制。
什么是JMS:java消息服务(Java Message Service),Java平台中关于面向消息中间件的接口
JMS是一种与厂商无关的API。
使用场景:
核心应用:
解耦:订单系统 >> 物流系统
异步:用户注册 >> 发送邮件,初始化信息
削峰:秒杀、日志处理
跨平台、多语言
分布式事务、最终一致性
RPC调用上下游对接、数据源变动》通知下属
12.2 主流消息中间件框架对比
- Apache ActiveMQ
Apache出品,历史悠久,支持多种语言的客户端和协议Java,NET,c++等,基于JMS Provider实现。吞吐量不高,多队列的时候性能下降,存在消息丢失的情况,比较少大规模使用。 - Kafka
是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。Kafaka是一种高吞吐量的分布式发布订阅消息系统,它可以处理大规模的网站中的所有动作流数据(网页浏览,搜索和其他用户行动),副本集机制,实现数据冗余,保持数据尽量不丢失,支持多个生产者和消费者。不支持批量和广播消息,运维难度大。 - RabbitMQ
是一个开源的AMQP实现,服务器端用Erlang语言编写,支持多种客户端。。。用于在分布式系统中存储转发消息,在易用性、扩展性、高可用性等方便表现不错。使用Erlang开发,阅读和修改源码难度大 RocketMQ
阿里开源的消息中间件,Java开发,具有高吞吐量、高可用性、适合大规模分布式系统应用的特点,性能强劲(零拷贝技术),支持海量堆积,支持指定次数和时间间隔的失败消息重发,支持consumer端tag过滤,延迟消息等,在阿里内部大规模使用,适合在电商、互联网金融等领域使用。因为是阿里内部从实践到产品的产物,因此里面很多接口、API并不是很普遍适用。12.3 RocketMQ介绍
是一款开源的分布式消息系统,基于高可用分布式集群技术,提供低延时的、高可靠的消息发布与订阅服务。同时,广泛应用于多个领域,包括异步通信解耦、企业解决方案、金融支付、电信、电子商务、快递物流、广告营销、社交、即时通信、移动应用、手游、视频、物联网、车联网等。
具有以下特点:能够保证严格的消息顺序
- 提供丰富的消息拉取模式
- 高效的订阅者水平扩展能力
- 实时的消息订阅机制
- 亿级消息堆积能力
- 支持分布式事务
12.4 RocketMQ核心概念
- 消息模型(Message Model)
RocketMQ主要由 Producer、Broker、Consumer 三部分组成,其中Producer 负责生产消息,Consumer 负责消费消息,Broker 负责存储消息。Broker 在实际部署过程中对应一台服务器,每个 Broker 可以存储多个Topic的消息,每个Topic的消息也可以分片存储于不同的 Broker。Message Queue 用于存储消息的物理地址,每个Topic中的消息地址存储于多个 Message Queue 中。ConsumerGroup 由多个Consumer 实例构成。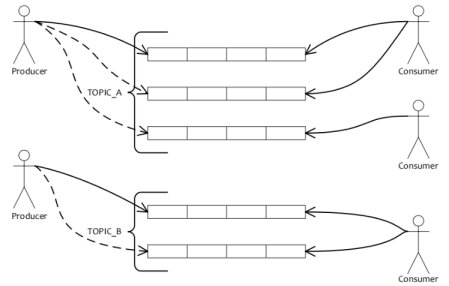
消息生产者(Producer):
负责生产消息,一般由业务系统负责生产消息。一个消息生产者会把业务应用系统里产生的消息发送到broker服务器。RocketMQ提供多种发送方式,同步发送、异步发送、顺序发送、单向发送。同步和异步方式均需要Broker返回确认信息,单向发送不需要。
消息消费者(Consumer):
负责消费消息,一般是后台系统负责异步消费。一个消息消费者会从Broker服务器拉取消息、并将其提供给应用程序。从用户应用的角度而言提供了两种消费形式:拉取式消费、推动式消费。
主题(Topic):
表示一类消息的集合,每个主题包含若干条消息,每条消息只能属于一个主题,是RocketMQ进行消息订阅的基本单位。
消息队列(Message Queue):
正真存放消息的地方,每一个主题下面会有多个队列
标签(Tag):
为消息设置的标志,用于同一主题下区分不同类型的消息。来自同一业务单元的消息,可以根据不同业务目的在同一主题下设置不同标签。标签能够有效地保持代码的清晰度和连贯性,并优化RocketMQ提供的查询系统。消费者可以根据Tag实现对不同子主题的不同消费逻辑,实现更好的扩展性。
组(Group):
生产者组(Producer Group)
同一类Producer的集合,这类Producer发送同一类消息且发送逻辑一致。如果发送的是事务消息且原始生产者在发送之后崩溃,则Broker服务器会联系同一生产者组的其他生产者实例以提交或回溯消费。
消费者组(Consumer Group)
同一类Consumer的集合,这类Consumer通常消费同一类消息且消费逻辑一致。消费者组使得在消息消费方面,实现负载均衡和容错的目标变得非常容易。要注意的是,消费者组的消费者实例必须订阅完全相同的Topic。 - 部署结构
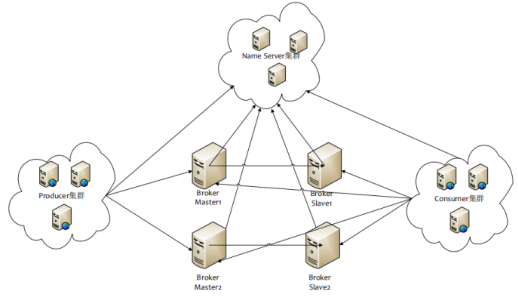
RocketMQ的服务端有两部分组成:- 代理服务器(Broker Server)
消息中转角色,负责存储消息、转发消息。代理服务器在RocketMQ系统中负责接收从生产者发送来的消息并存储、同时为消费者的拉取请求作准备。代理服务器也存储消息相关的元数据,包括消费者组、消费进度偏移和主题和队列消息等。 - 名字服务(Name Server)
名称服务充当路由消息的提供者。生产者或消费者能够通过名字服务查找各主题相应的Broker IP列表。多个Namesrv实例组成集群,但相互独立,没有信息交换。
- 代理服务器(Broker Server)
12.5 消息类型
- 普通消息
消息系统所传输信息的物理载体,生产和消费数据的最小单位,每条消息必须属于一个主题。RocketMQ中每个消息拥有唯一的Message ID,且可以携带具有业务标识的Key。系统提供了通过Message ID和Key查询消息的功能。 - 普通顺序消息
普通顺序消费模式下,消费者通过同一个消费队列收到的消息是有顺序的,不同消息队列收到的消息则可能是无顺序的。 - 严格顺序消
严格顺序消息模式下,消费者收到的所有消息均是有顺序的。 - 延时消息
是指消息发送到broker后,不会立即被消费,等待特定时间投递给真正的topic。 broker有配置项messageDelayLevel,默认值为“1s 5s 10s 30s 1m 2m 3m 4m 5m 6m 7m 8m 9m 10m 20m 30m 1h 2h”,18个level。可以配置自定义messageDelayLevel。注意,messageDelayLevel是broker的属性,不属于某个topic。发消息时,设置delayLevel等级即可:msg.setDelayLevel(level)。level有以下三种情况:
· level == 0,消息为非延迟消息
· 1<=level<=maxLevel,消息延迟特定时间,例如level==1,延迟1s
· level > maxLevel,则level== maxLevel,例如level==20,延迟2h
定时消息会暂存在名为SCHEDULE_TOPIC_XXXX的topic中,并根据delayTimeLevel存入 特定的queue,queueId = delayTimeLevel – 1,即一个queue只存相同延迟的消息,保证具有 相同发送延迟的消息能够顺序消费。broker会调度地消费SCHEDULE_TOPIC_XXXX,将消 息写入真实的topic。
需要注意的是,定时消息会在第一次写入和调度写入真实topic时都会计数,因此发送数量、tps都会变高。 - 事务消息
RocketMQ事务消息(Transactional Message)是指应用本地事务和发送消息操作可以被定义 到全局事务中,要么同时成功,要么同时失败。RocketMQ的事务消息提供类似 X/Open XA 的分布事务功能,通过事务消息能达到分布式事务的最终一致。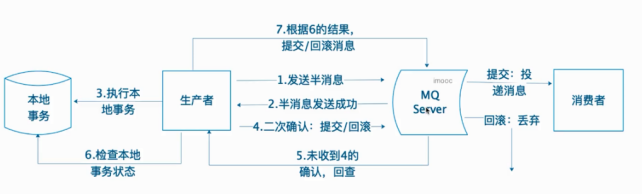
12.6 消息传播模式
- 集群模式(Clustering)
集群消费模式下,相同Consumer Group的每个Consumer实例平均分摊消息。 - 广播模式(Broadcasting)
广播消费模式下,相同Consumer Group的每个Consumer实例都接收全量的消息。
12.7 消息消费模式
- 拉取式消费(Pull Consumer)
Consumer消费的一种类型,应用通常主动调用Consumer的拉消息方法从Broker服务器拉消 息、主动权由应用控制。一旦获取了批量消息,应用就会启动消费过程。 - 推动式消费(Push Consumer)
Consumer消费的一种类型,该模式下Broker收到数据后会主动推送给消费端,该消费模式 一般实时性较高。
12.8 消息刷盘
- 同步刷盘:
如上图所示,只有在消息真正持久化至磁盘后RocketMQ的Broker端才会真正返回Producer 端一个成功的ACK响应。同步刷盘对MQ消息可靠性来说是一种不错的保障, 但是性能上 会有较大影响,一般适用于金融业务应用该模式较多。 - 异步刷盘:
能够充分利用OS的PageCache的优势,只要消息写入PageCache即可将成功的ACK返回给 Producer端。消息刷盘采用后台异步线程提交的方式进行,降低了读写延迟,提高了MQ的 性能和吞吐量。
12.9 消息重试
Consumer消费消息失败后,要提供一种重试机制,令消息再消费一次。Consumer消费消息 失败通常可以认为有以下几种情况:
由于消息本身的原因,例如反序列化失败,消息数据本身无法处理(例如话费充值,当前消 息的手机号被注销,无法充值)等。这种错误通常需要跳过这条消息,再消费其它消息,而 这条失败的消息即使立刻重试消费,99%也不成功,所以最好提供一种定时重试机制,即过 10秒后再重试。
由于依赖的下游应用服务不可用,例如db连接不可用,外系统网络不可达等。遇到这种错 误,即使跳过当前失败的消息,消费其他消息同样也会报错。这种情况建议应用sleep 30s, 再消费下一条消息,这样可以减轻Broker重试消息的压力。
RocketMQ会为每个消费组都设置一个Topic名称为“%RETRY%+consumerGroup”的重试队列 (这里需要注意的是,这个Topic的重试队列是针对消费组,而不是针对每个Topic设置的), 用于暂时保存因为各种异常而导致Consumer端无法消费的消息。考虑到异常恢复起来需要一些时间,会为重试队列设置多个重试级别,每个重试级别都有与之对应的重新投递延时, 重试次数越多投递延时就越大。RocketMQ对于重试消息的处理是先保存至Topic名称为 “SCHEDULE_TOPIC_XXXX”的延迟队列中,后台定时任务按照对应的时间进行Delay后重 新保存至“%RETRY%+consumerGroup”的重试队列中。
12.10 消息从投
生产者在发送消息时,同步消息失败会重投,异步消息有重试,oneway没有任何保证。消息 重投保证消息尽可能发送成功、不丢失,但可能会造成消息重复,消息重复在RocketMQ中 是无法避免的问题。消息重复在一般情况下不会发生,当出现消息量大、网络抖动,消息重 复就会是大概率事件。另外,生产者主动重发、consumer负载变化也会导致重复消息。如下 方法可以设置消息重试策略:
retryTimesWhenSendFailed:同步发送失败重投次数,默认为2,因此生产者会最多尝试发送 retryTimesWhenSendFailed + 1次。不会选择上次失败的broker,尝试向其他broker发送,最 大程度保证消息不丢。超过重投次数,抛出异常,由客户端保证消息不丢。当出现 RemotingException、MQClientException和部分MQBrokerException时会重投。
retryTimesWhenSendAsyncFailed:异步发送失败重试次数,异步重试不会选择其他broker,仅 在同一个broker上做重试,不保证消息不丢。
retryAnotherBrokerWhenNotStoreOK:消息刷盘(主或备)超时或slave不可用(返回状态非 SEND_OK),是否尝试发送到其他broker,默认false。十分重要消息可以开启。
12.11 死信队列
死信队列用于处理无法被正常消费的消息。当一条消息初次消费失败,消息队列会自动进行消息重试;达到最大重试次数后,若消费依然失败,则表明消费者在正常情况下无法正确地消费该消息,此时,消息队列 不会立刻将消息丢弃,而是将其发送到该消费者对应的特殊队列中。
RocketMQ将这种正常情况下无法被消费的消息称为死信消息(Dead-Letter Message),将存 储死信消息的特殊队列称为死信队列(Dead-Letter Queue)。在RocketMQ中,可以通过使 用console控制台对死信队列中的消息进行重发来使得消费者实例再次进行消费。
12.12 RocketMQ安装与启动
- 服务器安装
下载: https://archive.apache.org/dist/rocketmq/4.7.1/rocketmq-all-4.7.1-bin-release.zip - yum install -y zip unzip
解压:unzip rocketmq-all-4.6.0-bin-release.zip
根据机器内存情况设置运行内存:- 修改runserver.sh
JAVA_OPT=”${JAVA_OPT} -server -Xms128m -Xmx128m -Xmn256m -XX:MetaspaceSize=128m -XX:MaxMetaspaceSize=320m” - 修改runbroker.sh
JAVA_OPT=”${JAVA_OPT} -server -Xms256m -Xmx256m -Xmn128m” - 修改tools.sh
JAVA_OPT=”${JAVA_OPT} -server -Xms128m -Xmx128m -Xmn256m -XX:MetaspaceSize=128m -XX:MaxMetaspaceSize=128m”
- 修改runserver.sh
运行 name server
nohup sh bin/mqnamesrv &
查看启动日志
tail -f ~/logs/rocketmqlogs/namesrv.log
运行broker
nohup sh bin/mqbroker -n localhost:9876 &
查看启动日志
tail -f ~/logs/rocketmqlogs/broker.log
关闭服务
sh bin/mqshutdown broker
sh bin/mqshutdown namesrv
要想完全清空数据,删除文件夹~/store,然后重启ggg
控制台安装
下载: git clone https://github.com/apache/rocketmq-externals.git
找到rocketmq-console/src/main/resources/application.properties 根据需求,修改配置
server.port=8081
name server地址
也可以不修改,在启动完console后,在控制台导航栏 - 运维 - NameSvrAddrList一栏设置
修改 pom.xml ,修改RocketMQ相关依赖的版本4.7.1
切换到控制台目录 cd rocketmq-console
mvn clean package -DskipTests12.13 Springboot集成RocketMQ
导包
<dependency> <groupId>org.apache.rocketmq</groupId> <artifactId>rocketmq-spring-boot-starter</artifactId> <version>2.1.1</version> </dependency>发送消息
@Autowired private RocketMQTemplate rocketMQTemplate; //1,发送同步消息 @GetMapping("/send/{msg}") public SendResult sendMessage(@PathVariable("msg") String msg) { //携带tag与key Message<String> message = MessageBuilder.withPayload(msg) .setHeader(MessageConst.PROPERTY_KEYS, UUID.randomUUID().toString()) .build(); //rocketMQTemplate.send("msgtest:order_pay", message); SendResult sr=rocketMQTemplate.syncSend("msgtest:order_pay", message); return sr; } //2,发送异步消息 @GetMapping("/send2/{msg}") public String sendMessage2(@PathVariable("msg") String msg) { Map<String, Object> maps = new HashMap<>(); maps.put("KEYS", UUID.randomUUID().toString()); rocketMQTemplate.asyncSend("msgtest:order_pay", MessageBuilder.withPayload( new MessageDto(msg)). setHeader(MessageConst.PROPERTY_KEYS,UUID.randomUUID().toString()).build(), new SendCallback() { @Override public void onSuccess(SendResult sendResult) { System.out.println("发送成功: " + sendResult); } @Override public void onException(Throwable e) { System.out.println("发送失败: " + e.getMessage()); } }); return "异步发送成功!"; } //3,发送单项消息 @GetMapping("/send3/{msg}") public String sendMessage3(@PathVariable("msg") String msg) { Map<String, Object> maps = new HashMap<>(); maps.put("KEYS", UUID.randomUUID().toString()); rocketMQTemplate.sendOneWay("msgtest:order_pay",MessageBuilder.withPayload( new MessageDto(msg)).setHeader("KEYS", UUID.randomUUID().toString()).build()); return "发送单项消息成功!"; } //4,发送顺序消息 @GetMapping("/send5") public String sendMessage5() { Map<String, Object> maps = new HashMap<>(); maps.put("KEYS", UUID.randomUUID().toString()); for(int i = 0; i<10;i++) { String msg = "order: " + i + " : " + System.currentTimeMillis(); rocketMQTemplate.syncSendOrderly( "msgtest:order_pay", MessageBuilder.withPayload(new MessageDto(msg)).setHeader("KEYS", UUID.randomUUID().toString()).build(), //hash值匹配一个消息队列的,所有消息的hash值现在一样,会放入一个队列中 "message" ); } return "发送顺序消息成功!"; } //5,发送延时消息 @GetMapping("/send4/{msg}") public String sendMessage4(@PathVariable("msg") String msg) { Map<String, Object> maps = new HashMap<>(); maps.put("KEYS", UUID.randomUUID().toString()); rocketMQTemplate.syncSend("msgtest:order_pay", MessageBuilder.withPayload(new MessageDto(msg)).setHeader("KEYS", UUID.randomUUID().toString()).build(), 3000, //延迟等级 2); return "发送延迟消息成功!"; }消费消息
@Component @RocketMQMessageListener(consumerGroup = "order-group",topic = "msgtest", selectorExpression = "order_pay" //设置顺序(单线程)消费,默认是多线程异步消费 //,consumeMode = ConsumeMode.ORDERLY //广播模式 //,messageModel = MessageModel.CLUSTERING ) public class ConsumerListener implements RocketMQListener<MessageDto> { @Override public void onMessage(MessageDto message) { System.out.println("消费消息"); System.out.println(message); } }处理事务消息
//发送事务消息 @GetMapping("/send6") public TransactionSendResult sendMessage6(User user) { Map<String, Object> maps = new HashMap<>(); maps.put("KEYS", UUID.randomUUID().toString()); //自定义该消息的事务ID String txId = UUID.randomUUID().toString(); //处理事务业务逻辑需要用到的对象 //发送半消息 Message<String> message=MessageBuilder.withPayLoad("msg") .setHeader(MessageConst.PROPERTY_KEYS,txId) .setHeader("key",txId) .build(); return rocketMQTemplate.sendMessageInTransaction( "order_pay", message, user); }```java //2,本地事务执行以及回查程序 @Component @RocketMQTransactionListener public class LocalTransactionMessageListener implements RocketMQLocalTransactionListener {
//逻辑当中需要的业务处理对象 @Autowired private UserService us;
//用来保存事务执行成功的日志mapper对象 @Autowired private RocketTransactionLogMapper rocketTransactionLogMapper;
//执行本地事务逻辑 @Override public RocketMQLocalTransactionState executeLocalTransaction(Message msg, Object arg) {
User user = (User)arg; String txId = msg.getHeaders().get(MessageConst.PROPERTY_KEYS, String.class); try { us.addUser(user); StringRedisTemplate.opsForValue().setIfAbsent(txId,user,10,TimUnit.SECONDS) return RocketMQLocalTransactionState.COMMIT; }catch(Exception e) { e.printStackTrace(); return RocketMQLocalTransactionState.ROLLBACK; }}
/ 事务回查的时候需要调用的回查方法,通过日志里面保存的事务日志去检查事务执行情况 根据事务日志id去查询日志 / @Override public RocketMQLocalTransactionState checkLocalTransactionMessage msg) {
String txId = msg.getHeaders().get(MessageConst.PROPERTY_KEYS, String.class); String state=streingRedisTemplate.opsForValue.get(txId); RocketTransactionLog rs = rocketTransactionLogMapper.selectOne( new QueryWrapper<RocketTransactionLog>().eq("r_txid", txId)); if(rs == null) return RocketMQLocalTransactionState.ROLLBACK; return RocketMQLocalTransactionState.COMMIT;}
12.14 RocketMQ常见面试问题
- 如何避免消息重复消费?
RocketMQ不保证消息不重复,如果需要保证严格的不重复消费,需要自己在业务端去重,接口幂等性保障,消费端处理业务消息需要要吃幂等性,可以用Redis、关系数据库等来配合验证消息是否被消费。 - RocketMQ如何保证消息的可靠性传输
produce端: 不采用oneway发送,使用同步或则异步方式发送,做好重试,但是重试的Message key必须唯一。投递的日志需要保存,关键字段,投递时间,投递状态,重试次数,请求体,响应体
broker端: 双主双从架构,NamerServer需要多节点,同步双写、异步刷盘(同步刷盘则可靠性更高,但是性能差点,根据业务选择)
consumer端: 消息消费务必保留日志,即消息的元数据和消息体,做好幂等性处理 - 消息发生大量堆积应该怎么处理(大量堆积在broker里面)
线上故障了,怎么处理?
消息堆积了10小时,有几千万条消息待处理,现在怎么办?
修复consumer,然后慢慢消费?也需要几小时才可以消费完成,新的消息怎么办?
正确的姿势:
临时topic队列扩容,并提高消费能力,但是如果增加Consumer数量,堆积的topic里面的message queue 数量固定,过多的consumer不能分配到message queue。编写临时的处理分发程序,从旧topic快速读取到临时的新topic中,新topic的queue数量扩容多倍,然后再启动更多的consumer进行再临时的新的topic里消费。

若有收获,就点个赞吧
0 人点赞
