Git简介
Git是一个开源的**分布式版本控制**系统,可以有效、高速地处理从很小到非常大的项目版本管理。Git 是 Linus Torvalds为了帮助管理 Linux 内核开发而开发的一个开放源码的版本控制软件。
集中式&分布式
集中式
集中式版本控制系统,版本库是集中存放在中央服务器的,程序员开发时,用的都是自己的电脑,所以要先从中央服务器取得最新的版本,然后开始工作,工作完成后把自己的成果推送给中央服务器。<br /> 中央服务器就好比是一个图书馆,你要改一本书,必须先从图书馆借出来,然后回到家自己改,改完了,再放回图书馆。<br /> 集中式版本控制系统最大的问题就是必须联网才能工作,如果在局域网内还好,带宽够大,速度够快,可如果在互联网上,遇到网速慢的话,可能提交一个10M的文件就需要5分钟,这一点让人无法接受。<br /> 另外,集中式版本控制系统还存在一定的安全问题。主要原因是版本库存放在中央服务器,一旦中央服务器出问题,造成版本库丢失,无法从其他地方进行恢复。
分布式
分布式版本控制系统根本没有“中央服务器”,每个人的电脑上都是一个完整的版本库,这样,每个开发人员在工作的时候,就不需要联网了,因为版本库就在其自己的电脑上。既然每个人电脑上都有一个完整的版本库,那多个人如何协作呢?比方说你在自己电脑上改了文件A,你的同事也在他的电脑上改了文件A,这时,你们俩之间只需把各自的修改推送给对方,就可以互相看到对方的修改了。和集中式版本控制系统相比,分布式版本控制系统的安全性要高很多,因为每个人电脑里都有完整的版本库,某一个人的电脑坏掉了不要紧,随便从其他人那里复制一个就可以了。当然,Git的优势不单是不必联网这么简单,Git还有极其强大的分支管理,把集中式版本控制系统远远抛在了后面。
GIT的特点
分布式相比于集中式的最大区别在于开发者可以提交到本地,每个开发者通过克隆(git clone),在本地机器上拷贝一个完整的 Git 仓库。从一般开发者的角度来看,Git 有以下功能:从服务器上克隆完整的Git仓库(包括代码和版本信息)到单机上、在自己的机器上根据不同的开发目的,创建分支,修改代码、在单机上自己创建的分支上提交代码、在单机上合并分支、把服务器上最新版的代码fetch下来,然后跟自己的主分支合并等。优点:适合分布式开发,强调个体。公共服务器压力和数据量都不会太大。速度快、灵活。任意两个开发者之间可以很容易的解决冲突。离线工作。缺点:资料少(起码中文资料很少)。学习周期相对而言比较长。不符合常规思维。代码保密性差,一旦开发者把整个库克隆下来就可以完全公开所有代码和版本信息。因其资料的公开性,导致大型商业化工程几乎不会使用GIT来托管工程版本信息(除非搭建企业私服)。
Git的下载和安装
Git下载
官网: https://gitforwindows.org/
不建议去官网,如果不翻墙,会很卡并容易出错。
镜像: https://npm.taobao.org/mirrors/git-for-windows/
Git安装
选择完安装目录后,一路默认安装即可。安装完成后,打开Git bash,输入git --version,能输出git版本号,证明安装成功。安装完成后,还需要最后一步设置,在命令行输入:
$ git config --global user.name "Your Name"$ git config --global user.email "email@example.com"
因为Git是分布式版本控制系统,所以,每个机器都必须自报家门:你的名字和Email地址(可以使用Github的用户名和邮箱)。注意:git config命令的--global参数,用了这个参数,表示你这台机器上所有的Git仓库都会使用这个配置,当然也可以对某个仓库指定不同的用户名和Email地址。如果不使用--global参数,代表为某个特定的Git仓库设置用户名和邮箱。设置完成可以查看当前配置信息:
$ git config --list
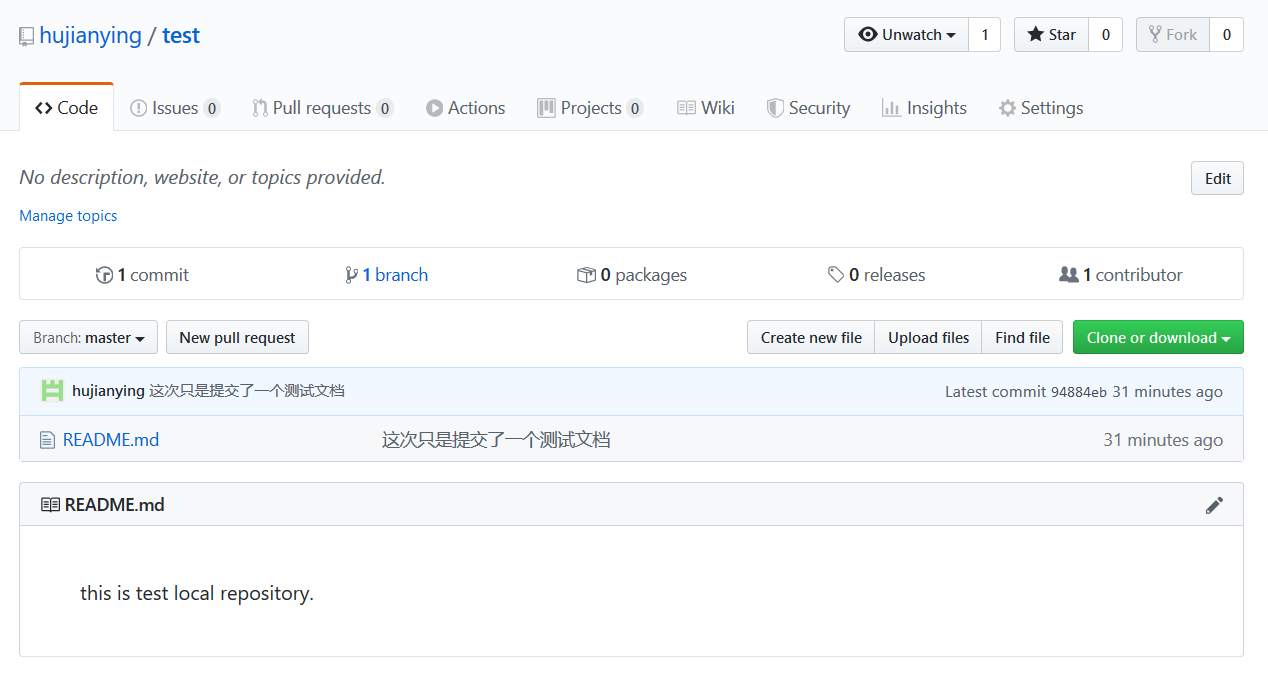
Github简介
gitHub是一个面向开源及私有软件项目的托管平台,因为只支持git作为唯一的版本库格式进行托管,故名 gitHub。gitHub于2008年4月10 日正式上线,除了git代码仓库托管及基本的Web管理界面以外,还提供了订阅、讨论组、文本渲染、在线文件编辑器、协作图谱(报表)、代码片段分享(Gist)等功能。目前,其注册用户已经超过350万,托管版本数量也是非常之多,其中不乏知名开源项目 Rubyon Rails_、_jQuery_、_python 等。作为开源代码库以及版本控制系统,Github拥有超过900万开发者用户。随着越来越多的应用程序转移到了云上,Github已经成为了管理软件开发以及发现已有代码的首选方法。如前所述,作为一个分布式的版本控制系统,在Git中并不存在主库这样的概念,每一份复制出的库都可以独立使用,任何两个库之间的不一致之处都可以进行合并。在GitHub,用户可以十分轻易地找到海量的开源代码。GitHub平台地址:[https://github.com](https://github.com)
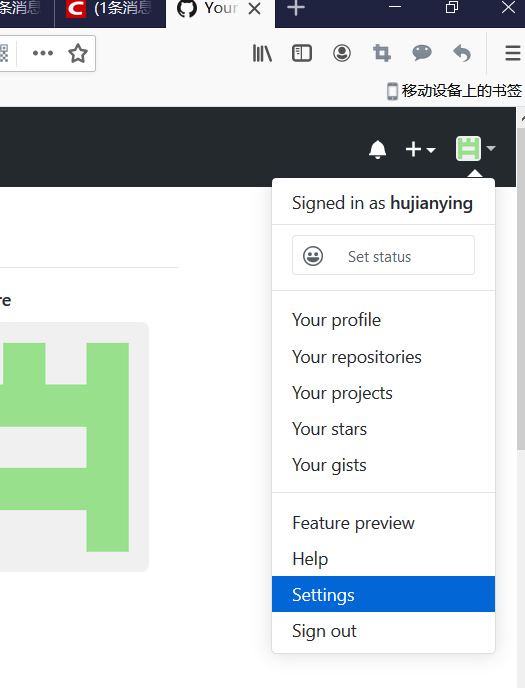
注册账号
登录平台,根据要求注册账号。
管理远程版本库
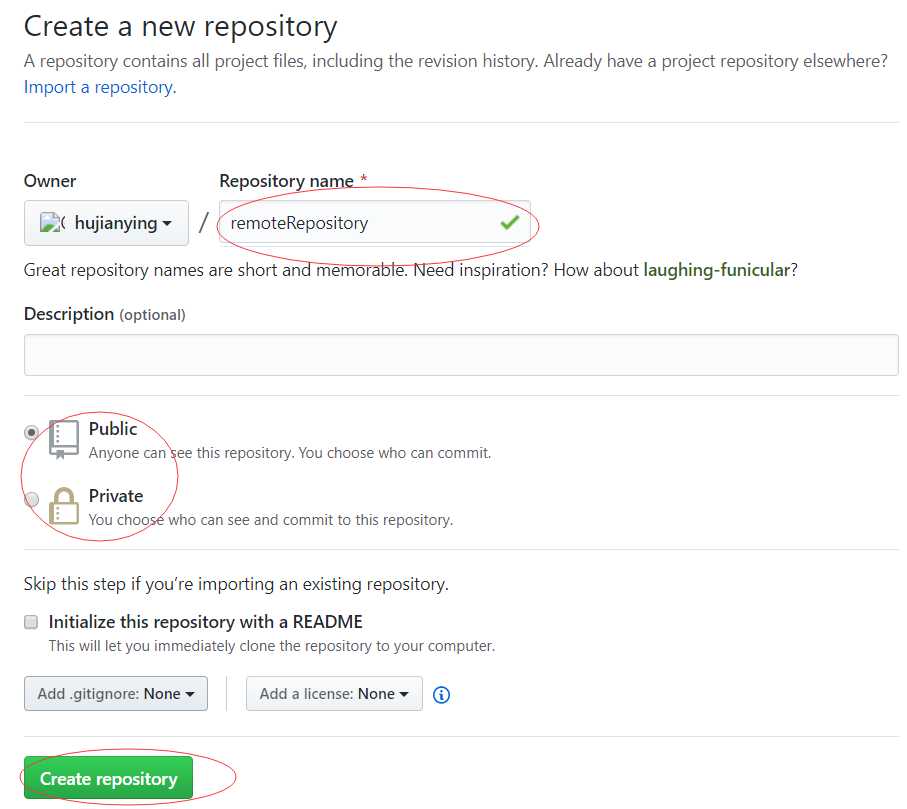
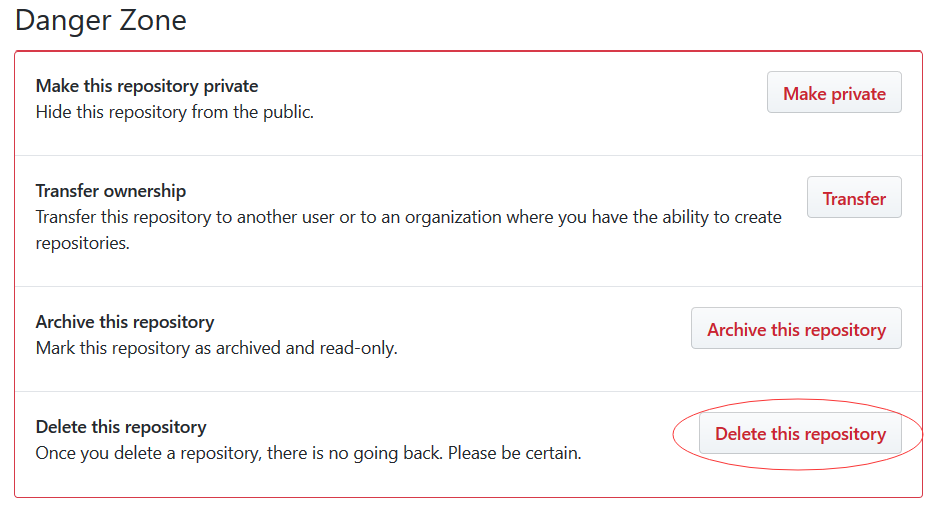
创建远程版本库
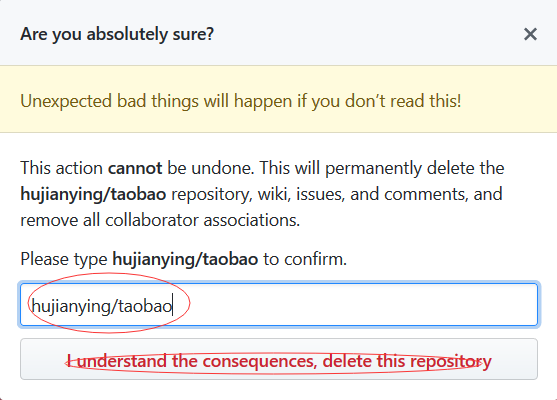
删除远程版本库
注册ssh公钥
ssh是Secure Shell(安全外壳协议)的缩写,建立在应用层和传输层基础上的安全协议。为了便于访问Github,需要在Github上注册计算机的ssh公钥,这样就不用每一次访问Github都要输入用户名和密码。
检查是否有本地密钥对
打开Git bash,输入:
$ ls ~/.ssh
Git的命令与Linux命令很类似,主要原因是,Git也是linus开发的。因此命令一脉相承,很多Linux命令在Git中也可以使用。以上命令就是在显示~/.ssh目录下是否存在密钥对,该目录对应C:\Users\用户\.ssh目录。如电脑上没有对应目录,可以使用mkdir命令创建。
$ mkdir ~/.ssh
如果显示结果中有id_rsa和id_rsa.pub,证明存在本地密钥对,无需创建。
生成密钥
如果显示结果中没有有id_rsa和id_rsa.pub,证明不存在本地密钥对,需要生成本地密钥对。
$ ssh-keygen -t rsa -C "email@email.com"
email@email.com处输入在Github上的注册邮箱。
获取公钥
$ cat ~/.ssh/id_rsa.pub
将显示内容从ssh-rsa之后所有内容复制备用。
注册公钥
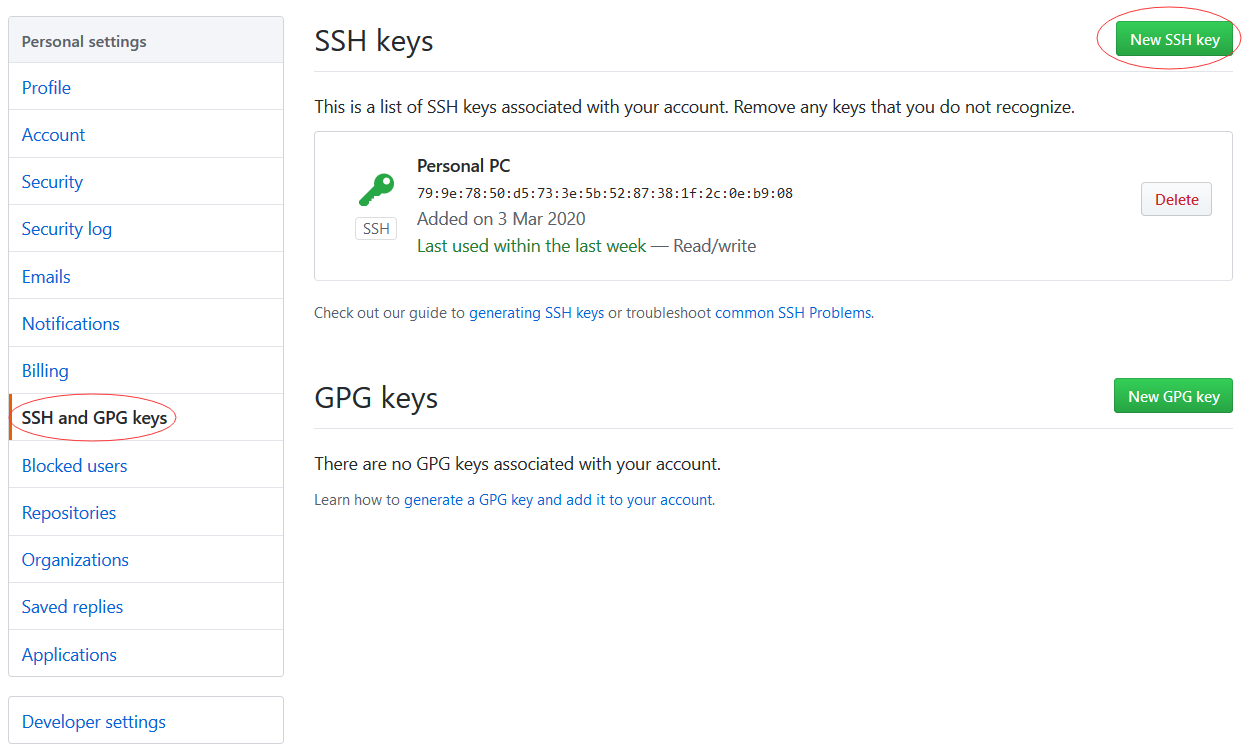
 检查公钥是否注册成功
检查公钥是否注册成功
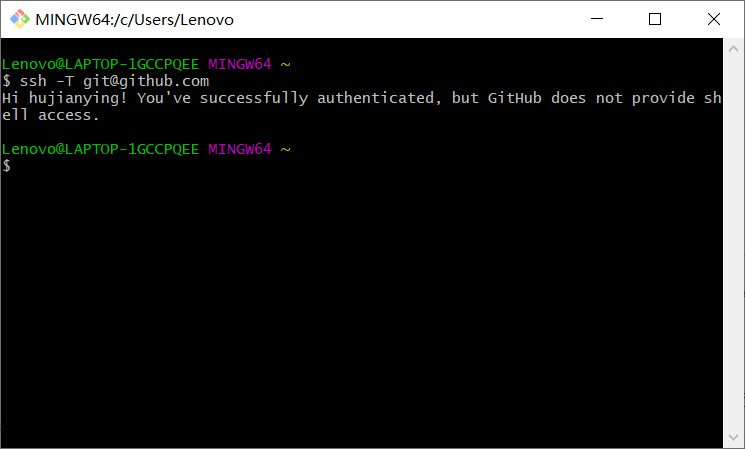
$ ssh -T git@github.com
Git的使用
创建本地版本库
版本库,又称仓库(repository),可以简单的视为一个目录,目录里的文件都会由Git进行管理,我们对文件的修改、删除,Git都能对其进行跟踪,以便追踪历史,或者在将来某个时刻可以“还原”。
选择一个合适的地方,创建一个空的目录(**为防止出错,所有目录中不要含有中文**),该目录为本地的工作区。
初始化本地版本库
进入本地版本库目录,右键单击,选择Git Bash Here,输入以下命令,回车。
$ git init
此时会在文件夹内生成一个隐藏的.git目录,该目录是Git的版本库,不要手动修改这个目录里面的文件,不然就有可能把Git版本库给破坏了。
向本地版本库中添加文件
向本地版本库中添加文件需要分两步实现,先将文件添加到本地版本库,然后提交到本地版本库。
在当前目录中创建文件:README.md(项目的入门手册,里面介绍了整个项目的使用、功能),执行以下命令:
$ git add README.md
命令执行成功后不会有任何反馈信息,不成功则返回失败信息,这一点与Linux是一样的。此时再执行提交命令:
$ git commit -m "本次操作的描述信息"
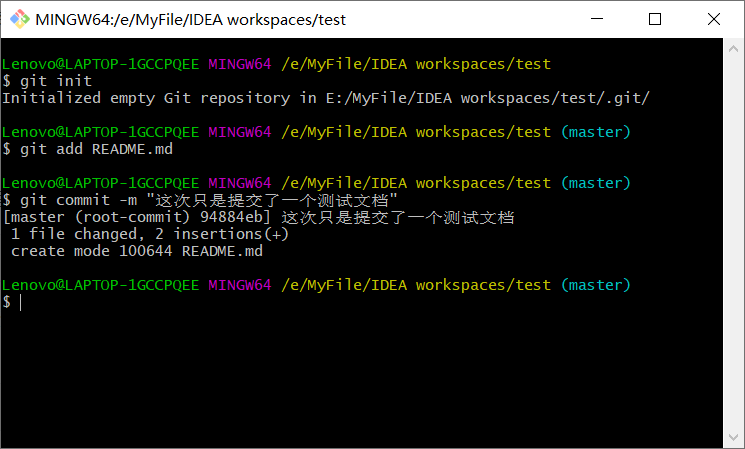
出现以上信息,文件提交成功。
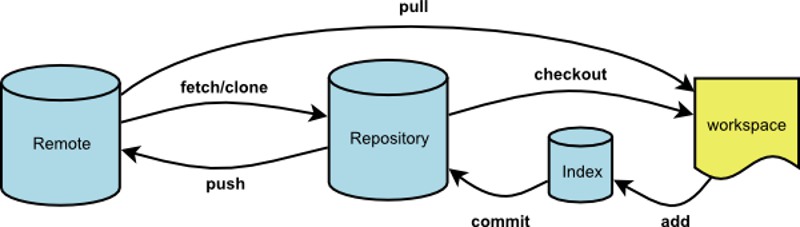
工作区和版本库
工作区就是计算机中能看到的目录,版本库是执行完init命令后生成的.git目录。
Git的版本库里存了很多东西,其中最重要的就是称为stage(或者叫index)的暂存区,还有Git为我们自动创建的第一个分支master,以及指向master的一个指针叫HEAD(当前版本的头信息)。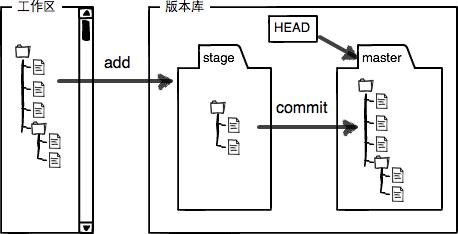
把文件添加到Git版本库是分两步执行的:
- 用git add把文件添加进去,实际上就是把文件修改添加到暂存区;
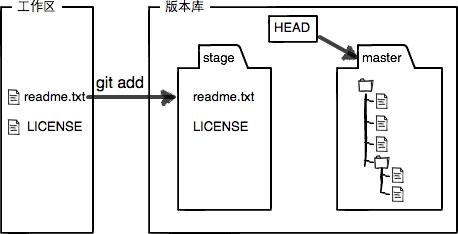
- 用git commit提交更改,实际上就是把暂存区的所有内容提交到当前分支。
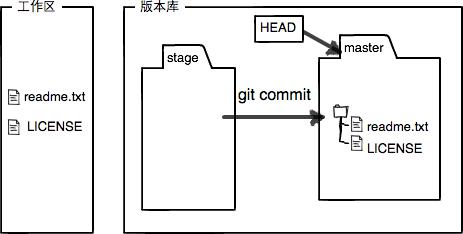
因为我们创建Git版本库时,Git自动为我们创建了唯一的master分支,所以git commit就是往master分支上提交更改。
可以简单理解为需要提交的文件修改通通放到暂存区,然后一次性提交暂存区的所有修改。也就是说git add可以执行多次,而git commit一次就可以将所有git add添加的内容提交到本地版本库中。
请注意,Git跟踪并管理的是修改,而不是具体的文件。因此,如果在工作区中对文件进行了修改,不使用git add命令将其添加到暂存区,而是直接使用git commit命令进行提交,此时版本库不会发生任何变化。
版本回退
作为版本控制系统,Git会保存每个commit版本的快照,一旦把文件改乱了,或者误删了文件,可以从最近的一次commit恢复,而不至于把所有工作成果全部丢失。
git log
使用git log命令可以查看从最近到最远的commit日志。<br /> 如果输出信息太多,很难阅读,可以试试加上--pretty=oneline参数
$ git log [--pretty=oneline]
查看完对应信息后,可以输入q退出日志。
Git的commit id不是1,2,3……递增的数字,而是一个SHA1计算出来的一个非常大的数字,用十六进制表示。每提交一个新版本,实际上Git就会把它们自动串成一条时间线。如果使用可视化工具(如idea之类)查看Git历史,就可以更清楚地看到提交历史的时间线。
git reset
使用git reset命令可以实现版本回退。<br /> 执行版本回退时,Git必须知道当前版本是哪个版本。在Git中,用HEAD表示当前版本,也就是最近的一次commit,上一个版本就是HEAD比较容易数不过来,所以写成HEAD~100。
返回上一个版本
$ git reset --hard HEAD^
指定回退到某一个具体的版本:reversion为回退的版本号,通过git log可以找到具体的版本号,没有必要写全,写前几位就可以了,Git会自动去找(一般为前7位)。
$ git reset --hard commit id
Git的版本回退速度非常快,因为Git在内部有个指向当前版本的HEAD指针,当你回退版本的时候,Git仅仅是把HEAD指针重新定位,并把工作区文件进行了更新。
git reflog
当回退到某个版本,关掉电脑后发现后悔了,想恢复到新版本怎么办?找不到新版本的commit id怎么办?在Git中,总是有后悔药可以吃的。Git提供了一个命令git reflog用来查找每一次commit记录。
$ git reflog
找到对应的commit id后,可以使用git reset命令回退到该版本。
撤销修改
当工作区的文件被git add添加到暂存区准备提交时,发现文件中有错误存在,此时可以选择手动将工作区中的文件进行修改,并再次git add添加到暂存区。也可以使用git checkout -- file丢弃工作区的修改。
git checkout —file
$ git checkout --文件名
git checkout --file的含义为放弃工作区中对文件的所有修改,这里有两种情况:
- 一种是工作区文件自修改后还没有被放到暂存区,撤销修改就回到和版本库一模一样的状态;
一种是工作区文件已经添加到暂存区后,又作了修改,撤销修改就回到添加到暂存区后的状态。
总之,就是让这个文件回到最近一次git commit或git add时的状态。 git checkout既被用来恢复工作区文件,又被用来切换分支,对用户造成了很大的认知负担。因此,新版本的Git中,该命令所做的工作被拆分为两个命令来分别承担:git switch用来切换分支,git restore用来恢复工作区文件。换言之,该命令将会逐步退出历史舞台。
git status
在使用git checkout --file命令前,可以使用git status查看工作区和暂存区状态信息,从而清楚的知道执行git checkout后,到底是恢复到最近一次git commit还是最近一次git add的状态。因为回到的状态不同,后续的操作也不同。
注意:git status不显示已经commit的信息。
git status
git diff
git diff顾名思义就是查看difference,显示的格式正是Unix通用的diff格式。比较的是工作目录(Working tree)和暂存区域快照(index)之间的差异,也就是修改之后还没有暂存起来的变化内容。
git diff
也就是修改之后还没有暂存起来的变化内容。
**git diff与git status的区别**:git status关注本地版本库的文件更新状态,git diff关注文件的更新内容。
git restore —staged
如果工作区的文件被修改,并被git add到暂存区,此时可以使用git restore --staged <file> 可以把暂存区的修改撤销掉(unstage),重新放回工作区。 老版本Git的命令为git reset HEAD <file>,再使用git checkout --file撤销工作区中文件的修改。
$ git restore --staged 文件名
删除文件
git rm
当工作区中的文件被删除,造成工作区和版本库不一致的情况,使用git status可以查看哪些文件被删除。
文件被删除有两种情况:
一是确实要从版本库中删除该文件,那就用命令git rm删掉,并且git commit;
$ git rm 要删除的文件名 $ git commit -m "提示信息" 小提示:先手动删除文件,然后使用git rm <file>和git add<file>效果是一样的。一是误操作导致删错了,因为在版本库里还存在,所以可以很轻松地把误删的文件恢复到最新版本。
$ git checkout --被删除文本名 注意:从来没有被添加到版本库就被删除的文件,是无法恢复的!git rm用于删除一个文件。如果一个文件已经被提交到版本库,那么永远不用担心误删,但是要小心,因为恢复文件到最新版本后,你会丢失最近一次提交后你修改的内容。
关联远程版本库
本地版本库与远程版本库建立关联时必须保证**名称相同**,并且远程版本库必须为空,否则关联失败。
第一种:使用http协议
$ git remote add origin https://github.com/用户名/远程版本库.git
第二种:使用ssh协议
$ git remote add origin git@github.com:用户名/远程版本库.git
以上命令可以在远程版本库创建后的页面中复制(第一种点选https复制,第二种点选ssh复制)。该命令执行完成没有出现其他信息,代表关联成功。
使用https除了速度慢以外,还有个最大的麻烦是每次推送都必须输入口令,但是在某些只开放http端口的公司内部就无法使用ssh协议而只能用https。<br />
推送文件
当本地版本库中有文件时,在关联远程版本库后,可将对应文件push推送到远程版本库。
$ git push -u origin master
第一次提交时可以使用-u参数,此时会需要你输入Github的用户名和密码。以后再次推送时,不需要使用-u参数,出现以下信息代表推送成功。
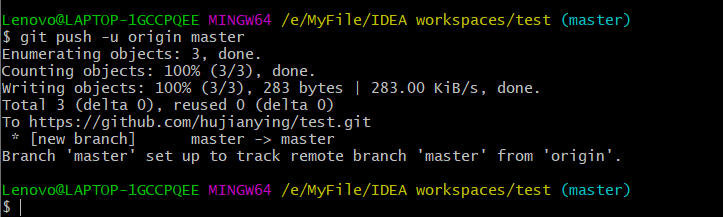
此时远程版本库中内容会发生改变。
拉取文件
从远程版本库拉取文件分为两种方式:git fetch和git pull。
git fetch
使用git fetch命令可以将远程版本库拉取到本地版本库,用户在检查了对应的更新信息后,可以决定是否合并到本地分支中。
获取远程版本库中全部更新
$ git fetch <远程主机名>
获取远程版本库中某个分支的更新
$ git fetch <远程主机名> <分支名>
获取origin版本库的master分支
$ git fetch origin master
取回更新后,会返回一个FETCH_HEAD,指的是某个分支在远程版本库上的最新状态,可以在本地通过它查看取回的更新信息。
$ git log -p FETCH_HEAD
返回的信息包括更新的文件名,更新的作者和时间,以及更新的代码(红色[删除]和绿色[新增])。可以通过这些信息来判断是否产生冲突,以确定是否将更新merge到当前分支。
git pull
使用git pull命令会将远程版本库中的最新内容拉取到本地并直接合并,即:git pull = git fetch + git merge,这样可能会产生冲突,需要手动解决。
获取远程版本库中的某个分支,并使之与本地版本库中的某个分支进行合并
$ git pull <远程版本库名> <分支名>:<本地分支名>
如果远程分支是与当前分支合并,则冒号后面的部分可以省略:
$ git pull origin 远程分支名
第一次拉取
如果从零开始开发,那么最好的方式是先创建远程版本库,然后从远程版本库克隆。远程版本库创建成功后,可以使用git clone命令将远程版本库克隆到本地,生成本地版本库。
第一种:使用http协议
$ git clone https://github.com/用户名/远程版本库.git
第二种:使用ssh协议
$ git clone git@github.com:用户名/远程版本库.git
如果多人协作开发,每个人都可以从远程版本库中克隆一份,按分工开发自己对应的模块即可。
非第一次拉取
1、建立与远程版本库的连接
$ git remote add origin https://github.com/用户名/远程版本库.git
2、从远程版本库中拉取文件到本地
$ git pull git@github.com:用户名/远程版本库.git
分支管理
几乎所有的版本控制系统都以某种形式支持分支。 使用分支意味着你可以把你的工作从开发主线上分离开来,以免影响开发主线。
在很多版本控制系统中,这是一个略微低效的过程——常常需要完全创建一个源代码目录的副本。对于大项目来说,这样的过程会耗费很多时间。
有人把 Git 的分支模型称为它的“必杀技特性”,也正因为这一特性,使得 Git 从众多版本控制系统中脱颖而出。 为何 Git 的分支模型如此出众呢? Git 处理分支的方式可谓是难以置信的轻量,创建新分支这一操作几乎能在瞬间完成,并且在不同分支之间的切换操作也是一样便捷。
与许多其它版本控制系统不同,Git 鼓励在工作流程中频繁地使用分支与合并,哪怕一天之内进行许多次。 理解和精通这一特性,你便会意识到 Git 是如此的强大而又独特,并且从此真正改变你的开发方式。
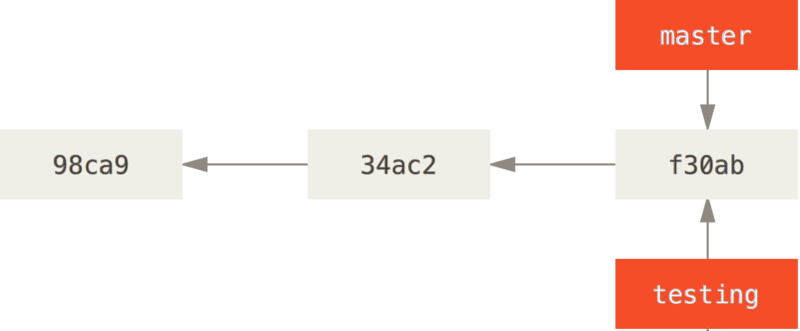
**Git的分支,其实本质上仅仅是指向提交对象的可变指针。**
Git的默认分支名字是master,指向master分支的指针会在每次提交时自动向前移动。
分支创建
使用git branch命令可以创建分支。当该命令执行时,Git会为当前分支创建了一个可以移动的新指针。
$ git branch testing
Git有一个名为HEAD的特殊指针, 指向当前所在的本地分支。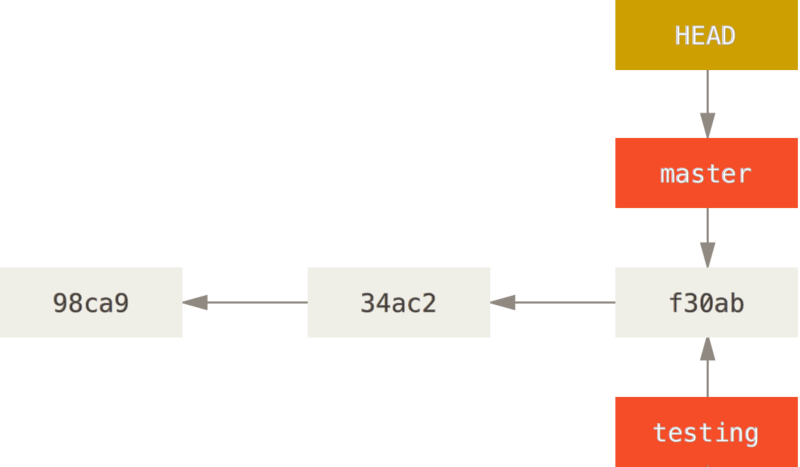
请注意:git branch 命令仅仅创建一个新分支,并不会自动切换到新分支中去。如需创建分支直接切换到该分支,可以使用git switch -c命令完成创建。
$ git switch -c 分支名
可以使用git log命令查看各个分支当前所指的对象。
$ git log --oneline --decorate
分支切换
使用git checkout切换到一个已存在的分支。
$ git checkout testing
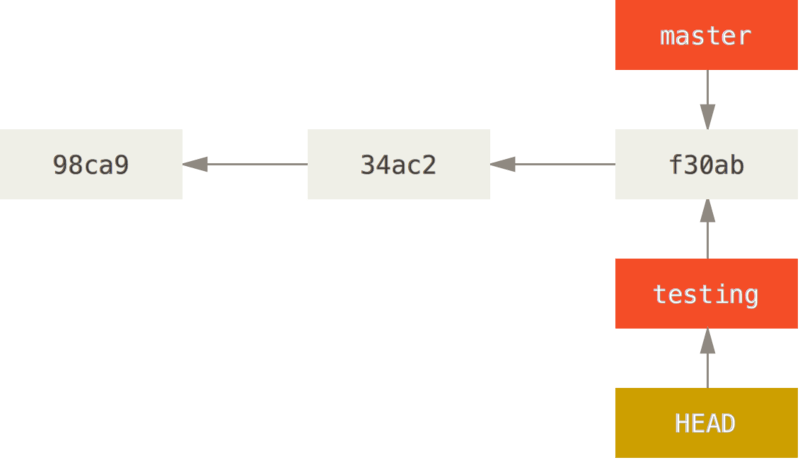
当切换分支后,执行commit提交操作后:
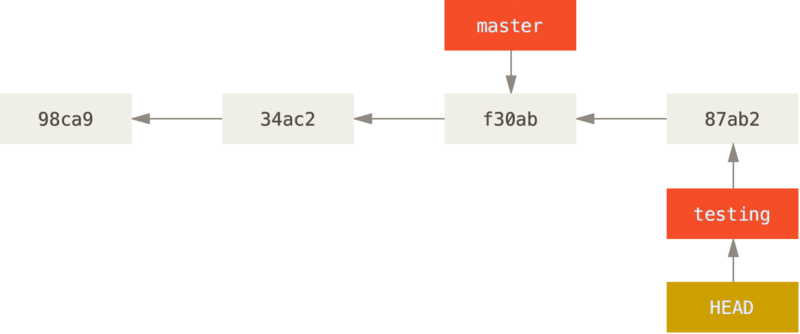
如图所示,testing分支向前移动了,但是master分支却没有,它仍然指向运行git checkout时所指的对象。
切换回master分支 :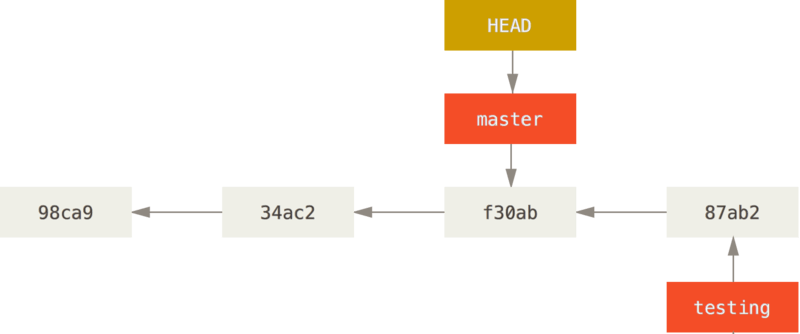
一是使 HEAD 指回 master 分支,二是将工作目录恢复成 master 分支所指向的快照内容。 也就是说,现在做修改的话,项目将始于一个较旧的版本。
本质上来讲,这就是忽略 testing 分支所做的修改,以便于向另一个方向进行开发。
对master分支执行commit提交操作:<br />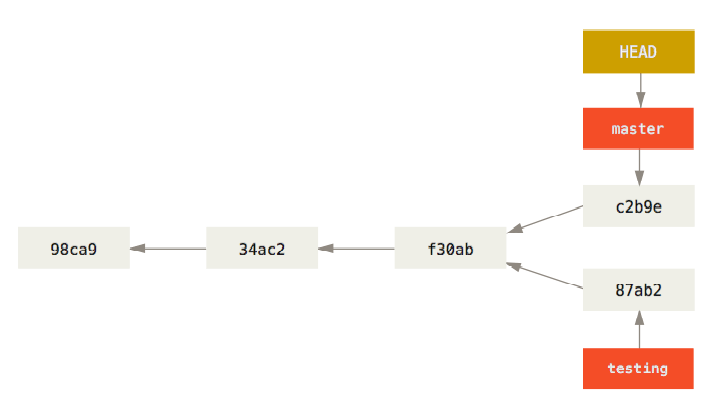<br /> 由上图可知,现在这个项目的提交历史已经产生了分叉。<br /> 创建了一个新分支testing,并切换过去进行了一些工作,随后又切换回master分支进行了另外一些工作。上述两次改动针对的是不同分支:你可以在不同分支间不断地来回切换和工作,并在时机成熟时将它们合并起来。 而所有这些工作,你需要的命令只有branch、checkout和commit。
分支合并
使用git merge命令将某个指定分支合并到当前分支。
$ git merge 分支名
如果合并的两个分支之间没有冲突,合并将会成功。一般来说,合并在对应分支中的代码开发完成之后才会发生。因此,合并成功之后,可以将对应分支删除。<br /> 通常来说,当分支合并时,Git会用Fast forward模式,但这种模式下进行分支删除,会导致分支信息丢失。<br /> 如果强制禁用Fast forward模式,Git就会在merge时生成一个新的commit,此时从分支历史上就可以看出分支信息。<br /> 在合并时使用--no -ff参数就可以强制禁用Fast forward模式。
$ git merge --no-ff -m "描述信息" 分支名
删除分支
使用git branch命令删除指定分支。
当分支已提交并被合并
$ git branch -d 分支名
当分支已提交但未合并
$ git branch -D 分支名
分支冲突的解决
在合并分支时,如果两个分支之间存在代码冲突,合并会失败,必须手动解决冲突之后才能完成合并。<br /> 案例:<br />1、创建本地版本库,并在工作区中创建a.md,其内容为a,add到暂存区,并commit到本地版本库。<br />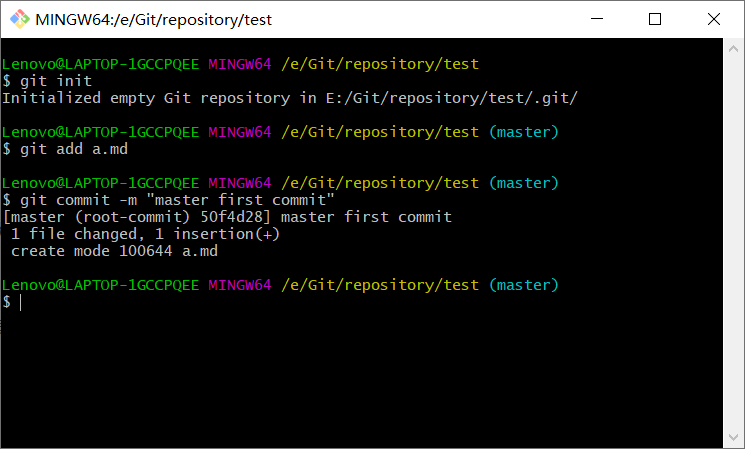<br />2、创建新分支:testing,并在分支中将a.md内容改成atesting,添加到暂存区,并提交到本地版本库。<br />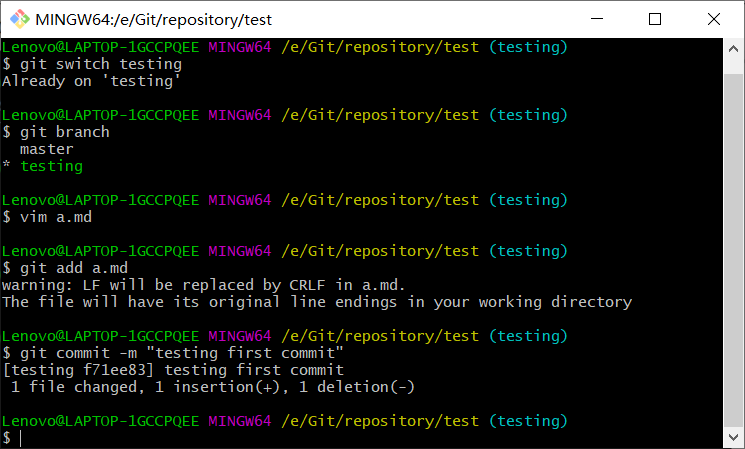<br />3、切换到master分支,将a.md内容改成anotesting,添加到暂存区,并提交到本地版本库,执行合并操作。<br />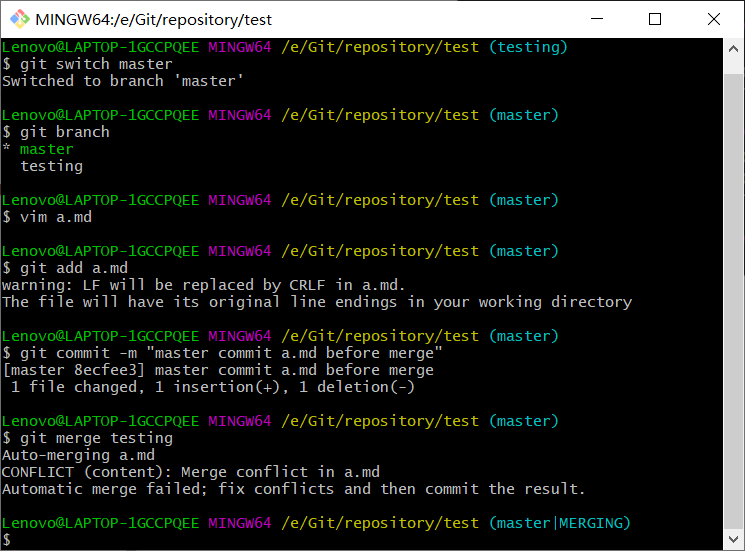<br />4、可以看到存在冲突信息:CONFLICT,需要手动解决冲突,此时直接vim a.md可以看到冲突信息。<br />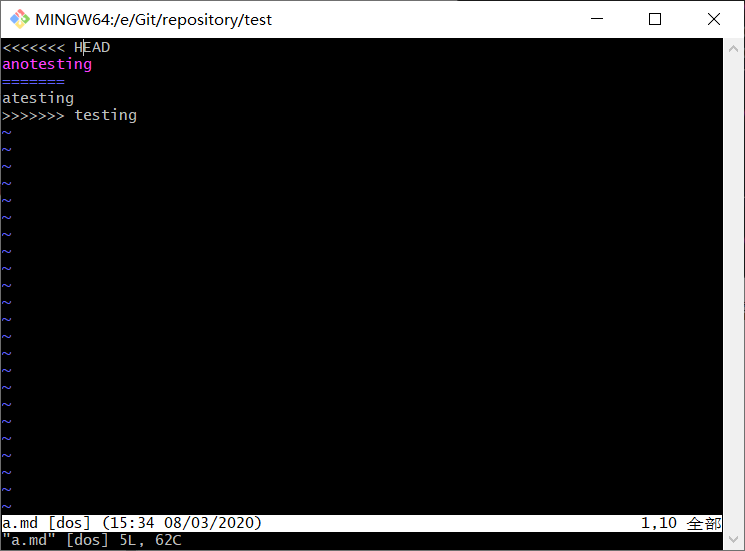<br />5、将anotesting修改成atesting,保存退出,然后重新add和commit,再执行merge,合并成功,删除分支testing。<br />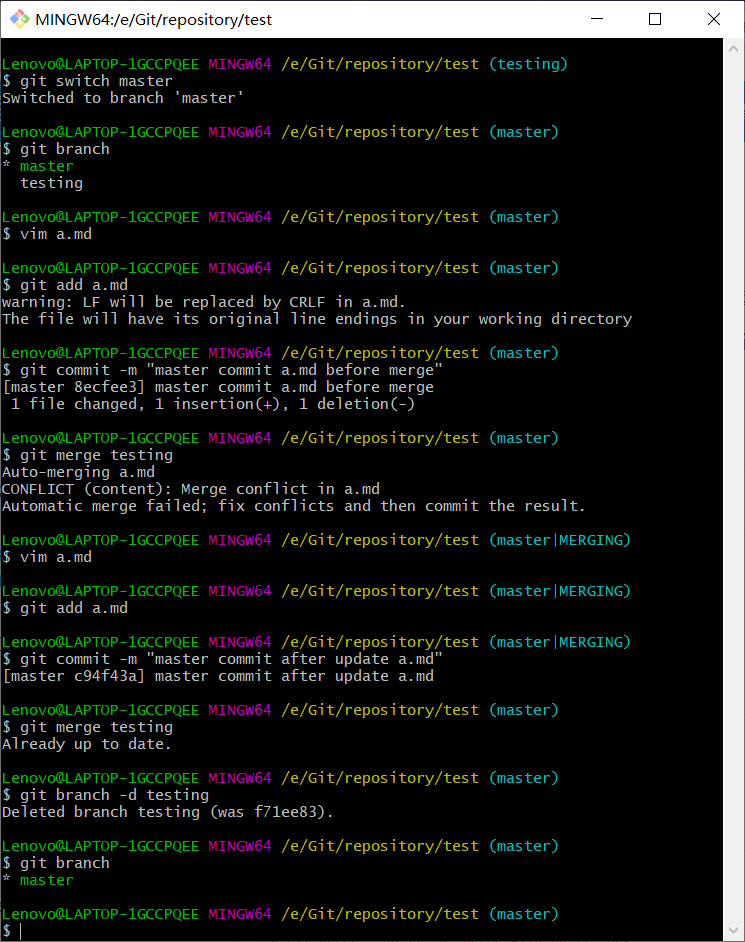
分支管理策略
在实际开发中,我们应该按照几个基本原则进行分支管理:
- 首先,master分支应该是非常稳定的,也就是仅用来发布新版本,平时不能在上面干活;
- 创建一个用于开发的dev分支,dev分支不是一个稳定的分支,小组成员再根据dev分支创建自己的分支,开发过程中可以不断将dev分支与自己的分支进行合并;
- 当项目开发结束需要对外进行发布,比如1.0版本发布时,才将把dev分支合并到master上,在master分支发布1.0版本;
BUG分支
软件开发中,bug就像家常便饭一样。<br /> 有了bug就需要修复,在Git中,由于分支是如此的强大,所以每个bug都可以通过一个新的临时分支来修复,修复后,合并分支,然后将临时分支删除。<br /> 应用场景:<br /> 当程序员接到一个修复bug的任务时,可以创建一个分支来修复它,但是当前正在dev上进行的开发工作还没有提交,而且此时对应的开发工作没做完,还不能提交,怎么处理? 而工作只进行到一半,还没法提交,预计完成还需1天时间。但是,必须在两个小时内修复该bug,怎么办?<br /> 在Git还提供了一个stash功能,可以把当前工作临时“储存”起来,等以后恢复bug后再回来继续工作。<br /> 案例:<br />1、创建本地版本库,并在工作区中创建a.md,内容为a,添加到暂存区并提交到本地版本库。
2、创建dev分支,并修改a.md内部为adev,使用git stash存储当前工作,不做add和commit操作。此时使用vim a.md时会发现值已经变成了a。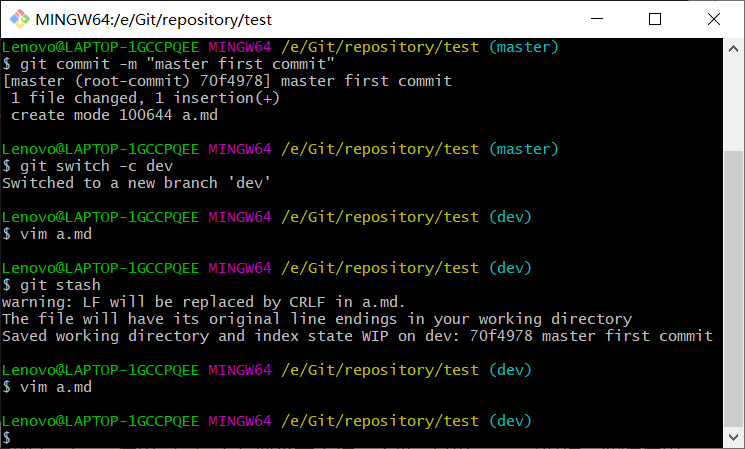
3、切换到master分支,创建并切换到修复bug的分支bug-01,修改a.md内容为abugupdate,添加到暂存区并提交到本地版本库。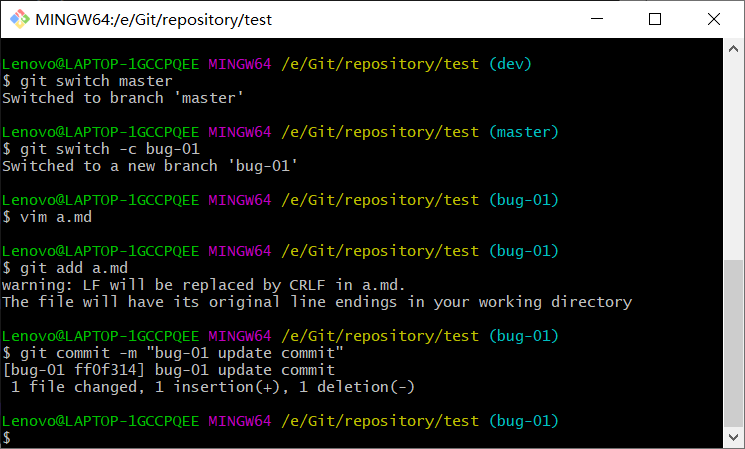
4、切换到master分支,合并分支bug-01,并删除分支bug01,后切换到dev。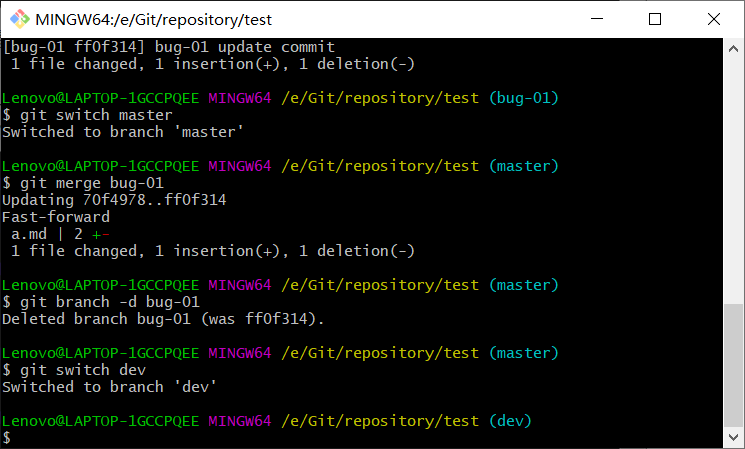
5、vim检查dev分支下的a.md,此时会发现之前修改的adev变回了a,执行恢复操作git stash apply或git stash pop,此时会恢复到stash保存的工作状态,vim检查a.md,内容已改回adev。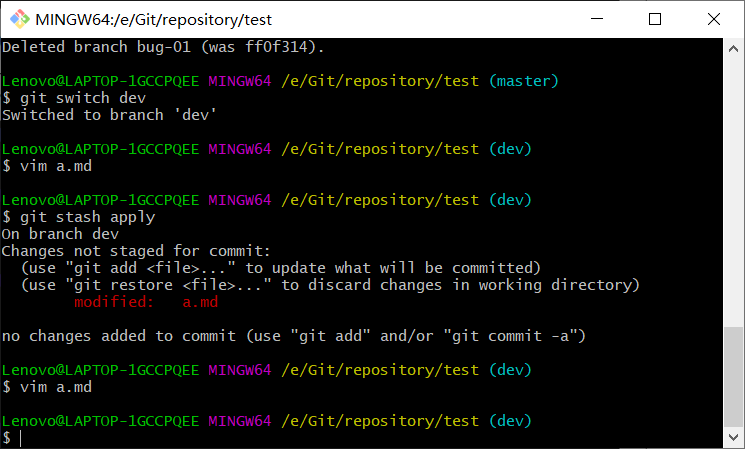
git stash恢复有两种方式:
- 一种是用git stash apply恢复,但是恢复后,stash内容并不删除。这种方式可以进行多次恢复,你需要用git stash drop来删除stash内容。
另一种方式是用git stash pop,恢复的同时把stash内容也删了,因此这种方式只能恢复一次。
Git标签
发布一个版本时,通常先在版本库中打一个标签(tag),来唯一确定打标签时刻的版本。将来无论什么时候,取某个标签的版本,就是把那个打标签的时刻的历史版本取出来,所以标签也是版本库的一个快照。<br /> Git的标签虽然是版本库的快照,但其实它就是指向某个commit的指针,跟分支很像但有所区别:分支可以移动,标签不能移动,所以创建和删除标签都是瞬间完成的。<br /> commit id的是一长串无意义的字符组合,常人无法记忆,因此才使用标签来代替(类似于ip地址与域名的关系)。<br /> 在Git中打标签非常简单,切换到对应分支上,使用git tag命令即可以实现。$ git tag 标签名 一般标签为V1.0之类,代表当前版本号默认标签是打在最新提交的commit上的,如果希望给提交的历史版本打标签,需要先找到对应历史版本的commit id(可以使用git log或git reflog查看)。$ git tag 标签名 commit id推送标签到远程:推送指定标签到远程 $ git push origin 标签名 推送所有标签到远程 $ git push origin --tags删除标签:删除本地标签 $ git tag -d 标签名 删除远程标签分两步执行 1.删除本地标签 $ git tag -d 标签名 2.删除远程标签 $ git push origin :refs/tags/标签名自定义Git
忽略特殊文件
有些时候,某些文件必须放到Git工作目录中,但又不能提交它们,比如保存了数据库密码的配置文件等。要解决这个问题,可以在Git工作区的根目录下创建一个特殊的.gitignore文件,然后把要忽略的文件名填进去,Git就会自动忽略这些文件。<br /> 好在Git考虑到了大家的感受,这个问题解决起来也很简单,在Git工作区的根目录下创建一个特殊的`.gitignore`文件,然后把要忽略的文件名填进去,Git就会自动忽略这些文件。<br /> 不需要从头写.gitignore文件,GitHub已经为我们准备了各种配置文件,只需要组合一下就可以使用了。所有配置文件可以直接在线浏览:[https://github.com/github/gitignore](https://github.com/github/gitignore)<br /> 忽略文件的原则是:
- 忽略操作系统自动生成的文件,比如缩略图等;
- 忽略编译生成的中间文件、可执行文件等,也就是如果一个文件是通过另一个文件自动生成的,那自动生成的文件就没必要放进版本库,比如Java编译产生的.class文件;
忽略你自己的带有敏感信息的配置文件,比如存放口令的配置文件。
创建.gitignore文件
在windows系统中,直接创建时会提示请输入文件名,有两种方式处理 1、使用Linux命令touch进行创建 touch .gitignore 2、在windows系统中,可以先创建文件后,保存或另存为的方式实现设置忽略规则
在文件中设置忽略规则 vim .gitignore忽略规则中可以使用通配符*,比如要忽略所有后缀为.txt的文件,在.gitignore文件中可以设置*.txt。当设置好忽略规则后,被忽略的文件将无法使用git add命令添加到暂存区,如果要强制将该文件添加到暂存区,可以使用-f参数。
$ git add -f 要强制添加的文件
缓存处理
新建的文件在git中会有缓存,如果某些文件已经被纳入了版本管理中,就算是在.gitignore中已经声明了忽略路径也是不起作用的。此时应该先把本地缓存删除,然后再进行git push,这样就不会出现忽略的文件。git清除本地缓存命令如下:
git rm -r --cached .
git add .
git commit -m 'update .gitignore'
配置别名
有些比较长的命令可以配置简单的别名,从而减少工作量。
$ git config --global alias.别名 要取别名的命令
案例:给commit操作取别名cm
$ git config --global alias.cm commit
用法:
没取别名之前:$ git commit -m "提示信息"
取别名之后:$ git cm -m "提示信息"
搭建Git服务器
CentOS默认自带Git,但版本较低,一般会将其替换为高版本Git。
步骤1:替换默认Git
1:安装依赖包
[root@localhost tmp]# yum install curl-devel expat-devel gettext-devel openssl-devel zlib-devel gcc perl-ExtUtils-MakeMaker
2:上传git-2.22.0.tar.gz到/usr/local/tmp,解压后移动到/usr/local/git。
解压
[root@localhost tmp]# tar zxvf git-2.22.0.tar.gz
移动
[root@localhost tmp]# mv git-2.22.0 ../git
3:安装git-2.22.0.tar.gz
[root@localhost git]# make prefix=/usr/local/git all
[root@localhost git]# make prefix=/usr/local/git install
4:修改环境变量
[root@localhost git]# vim /etc/profile
增加如下内容:
export PATH=/usr/local/git/bin:$PATH
5:导入环境变量配置
[root@localhost git]# source /etc/profile
6:测试
[root@localhost git]# git --version
输出git version 2.22.0代表安装成功。
步骤2:增加用户及用户组
1、增加用户
增加用户
[root@localhost ~]# adduser git
修改用户密码
[root@localhost ~]# passwd git
在提示框中输入和确认用户密码,两次密码必须一致
2、增加用户组,如果存在则不作处理
[root@localhost ~]# groupadd git
将用户放入该用户组管理
[root@localhost ~]# usermod -G git git
步骤3:创建git仓库
1、在/srv下创建git远程仓库
[root@localhost srv]# mkdir gitrepo.git
2、进入远程仓库完成初始化工作
--bare代表生成一个裸库,即无工作区的仓库
[root@localhost gitrepo.git]# git init --bare
3、让git用户组的git用户管理远程仓库
[root@localhost gitrepo.git]# chown -R git:git /srv/gitrepo.git/
步骤4:添加公钥
1、在/home/git下创建.ssh目录,如果存在则不需创建,该目录为隐藏目录,如需查看,可使用ls -a参数
[root@localhost git]# mkdir .ssh
2、授权
[root@localhost git]# chmod 700 .ssh
3、在.ssh目录下创建authorized_keys,如存在不需创建
[root@localhost git]# touch .ssh/authorized_keys
4、授权
[root@localhost git]# chmod 600 .ssh/authorized_keys
5、将本地公钥id_rsa.pub上传到/usr/local/tmp
6、将公钥的内容添加到authorized_keys中
[root@localhost .ssh]# cat /usr/local/tmp/id_rsa.pub >> authorized_keys
步骤5:打开RSA认证
1、Git服务器打开RSA认证
vim /etc/ssh/sshd_config
放开以下内容的注释:
RSAAuthentication yes
PubkeyAuthentication yes
AuthorizedKeysFile .ssh/authorized_keys
PermitRootLogin yes
2、重启sshd服务
[root@localhost .ssh]# service sshd restart
步骤6:建立软链接
替换了默认git,安装目录被修改成/usr/local/git,避免git-upload-pack和git-receive-pack命令找不到。
git-upload-pack:将对象发送回git-fetch-pack(从另一个存储库接收缺少的对象)
[root@localhost gitrepo.git]# ln -s /usr/local/git/bin/git-upload-pack /usr/bin/git-upload-pack
git-receive-pack:接收推入存储库的内容
[root@localhost gitrepo.git]# ln -s /usr/local/git/bin/git-receive-pack /usr/bin/git-receive-pack
步骤7:测试
在本地仓库中使用git克隆远程仓库,在某个文件夹中右键使用git bash
$ git clone git@192.168.113.130:/srv/gitrepo.git
如果要求输入密码,输入git用户的密码即可。
出现warning: You appear to have cloned an empty repository.代表远程git服务器搭建成功。
idea中的Git操作
idea中集成了Git和GitHub。
Git配置
file->settings->version control->Git<br />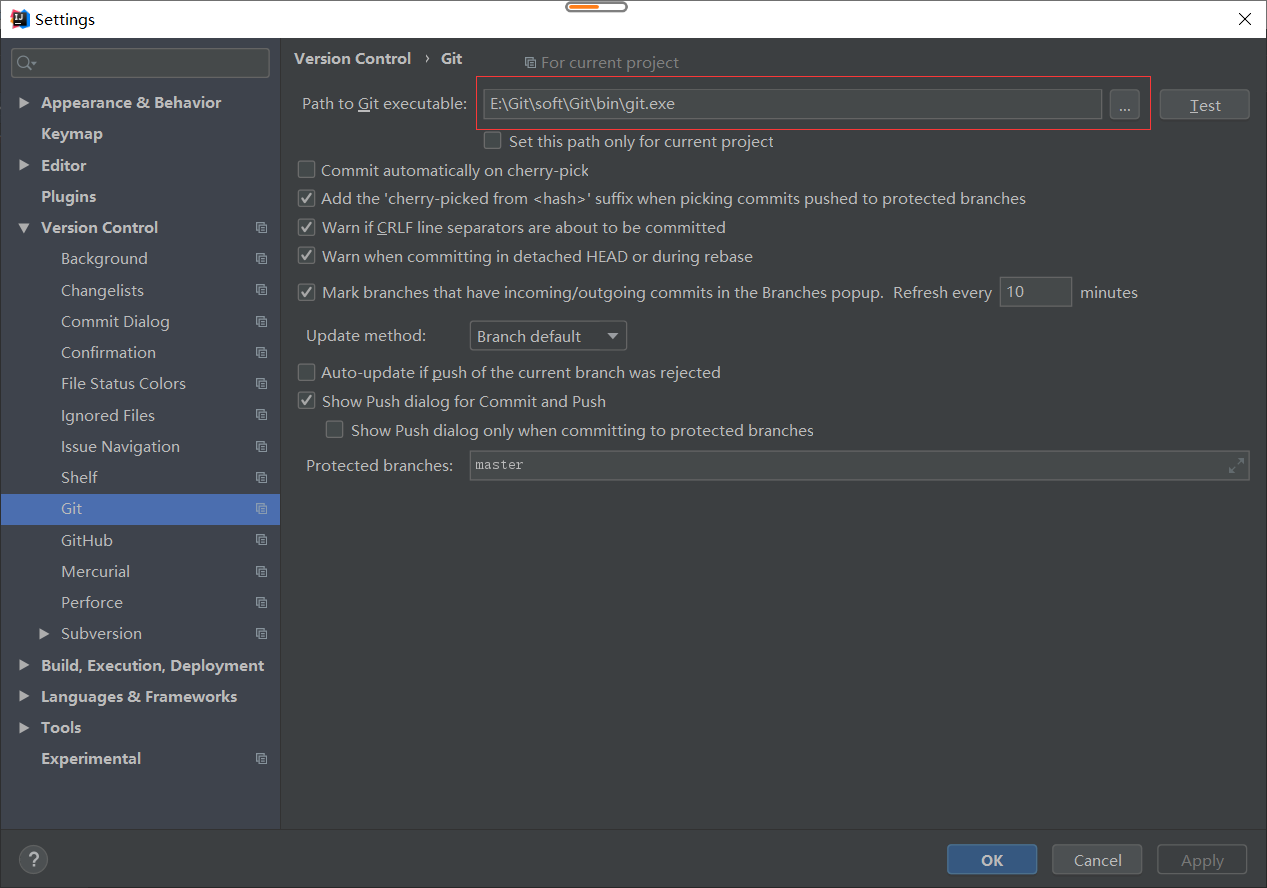
GitHub配置
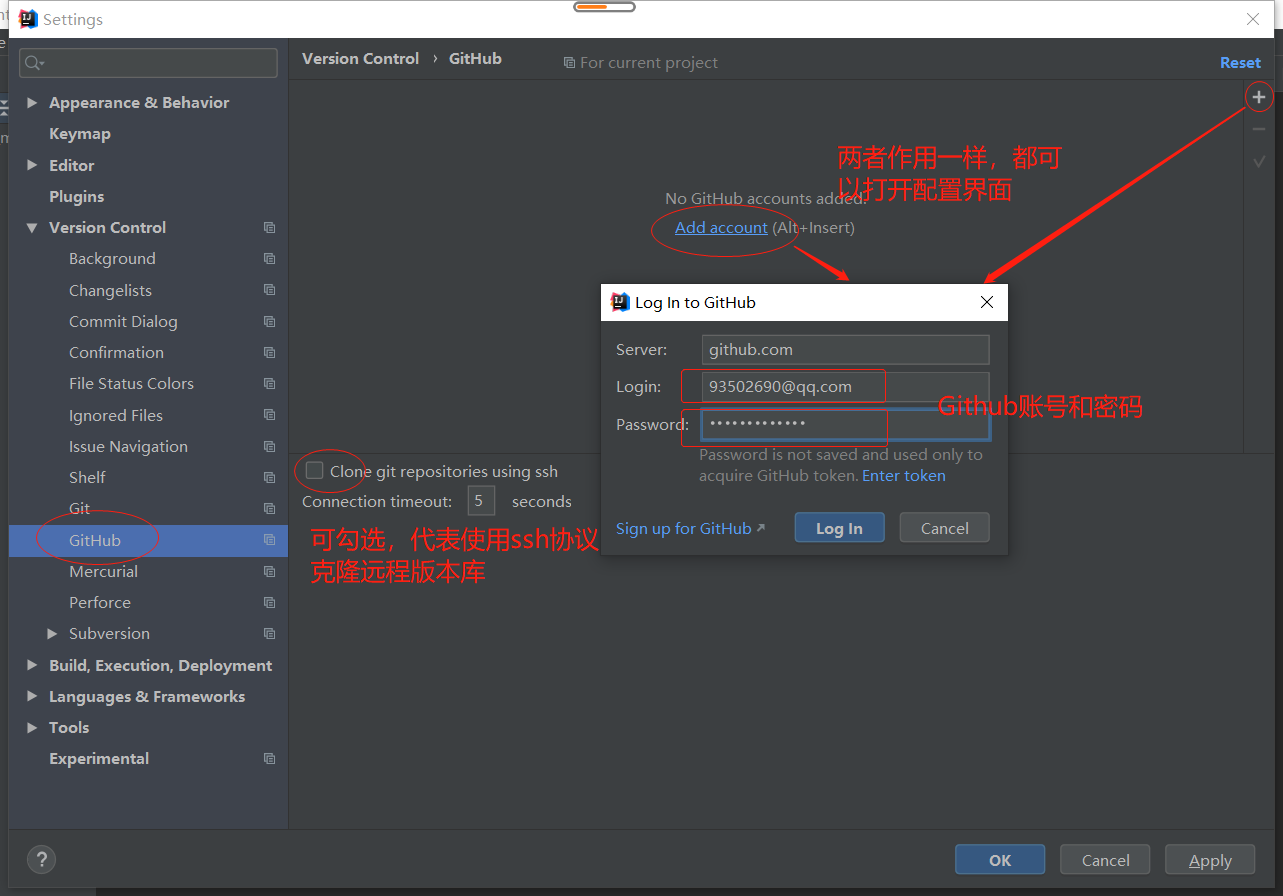
idea忽略特殊文件
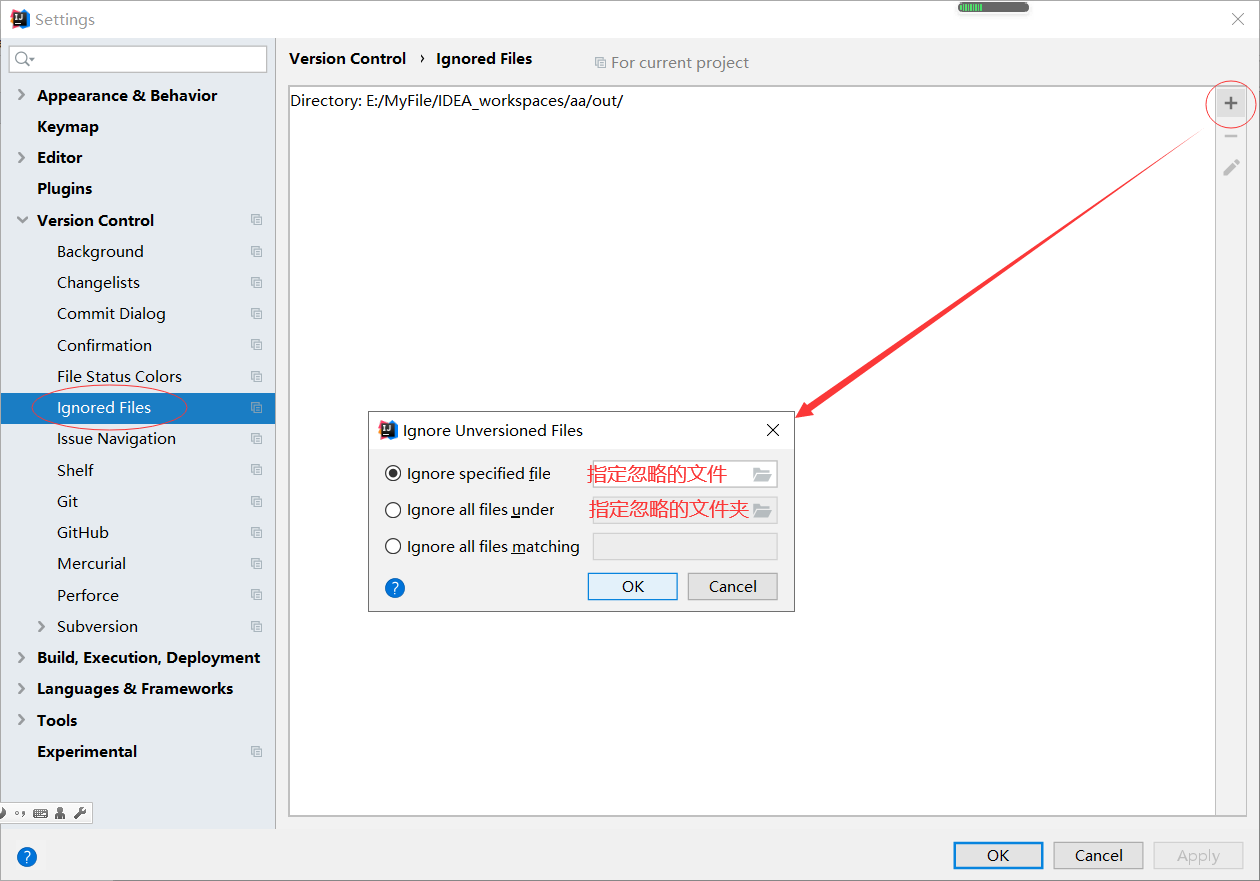
idea推送文件至远程版本库
1、准备远程版本库:git@github.com:hujianying/test.git
2、idea创建项目:helloworld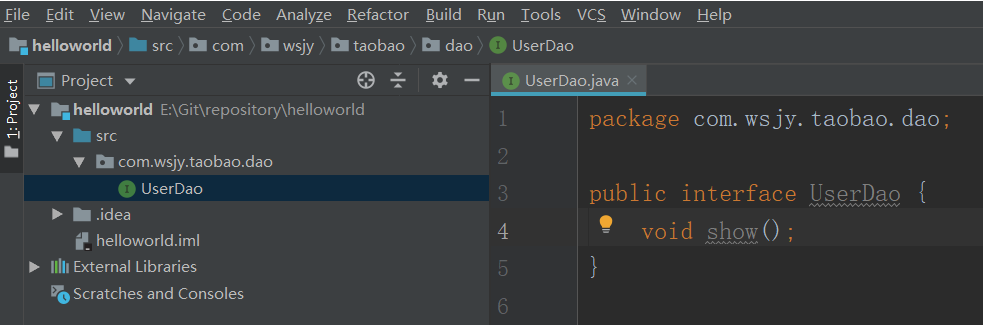
3、将项目文件根目录指定为本地版本库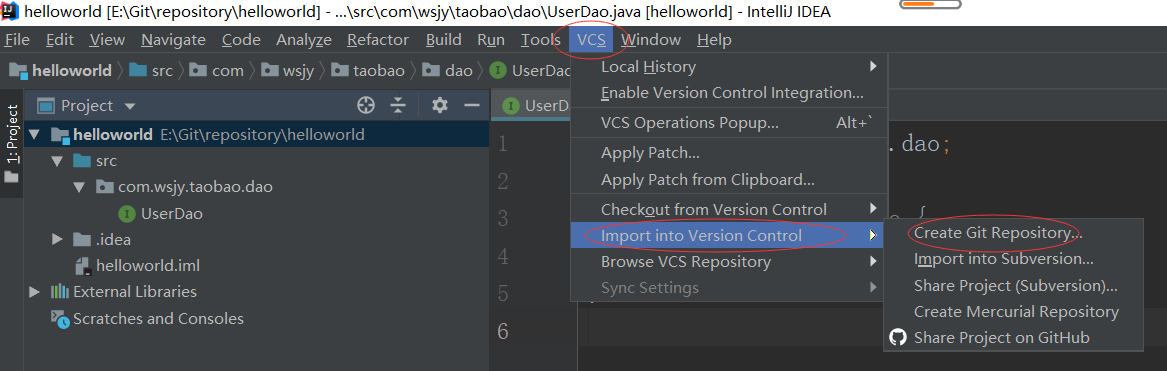
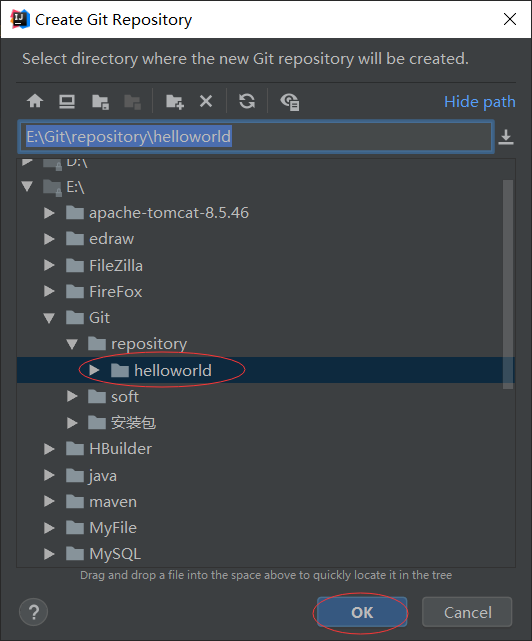
4、将项目文件添加到本地版本库的index区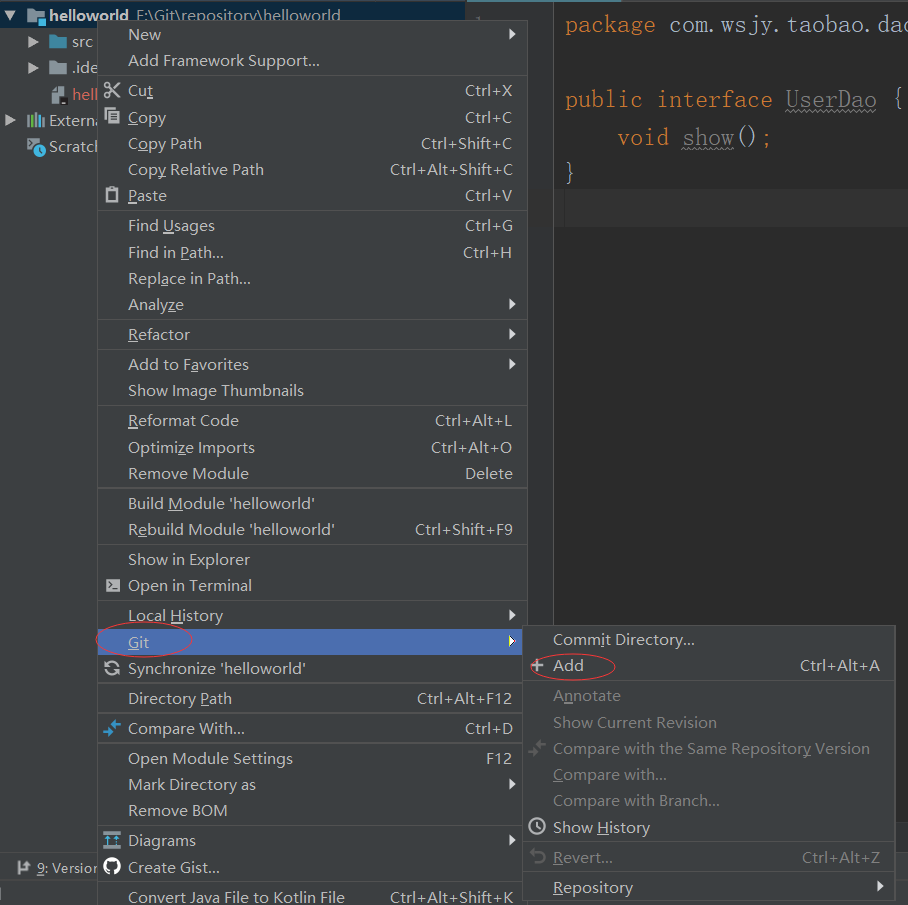
5、将stage区的文件提交到本地版本库,点击commit,在此步可以选择commit and push,提交到本地版本库的同时推送到远程版本库。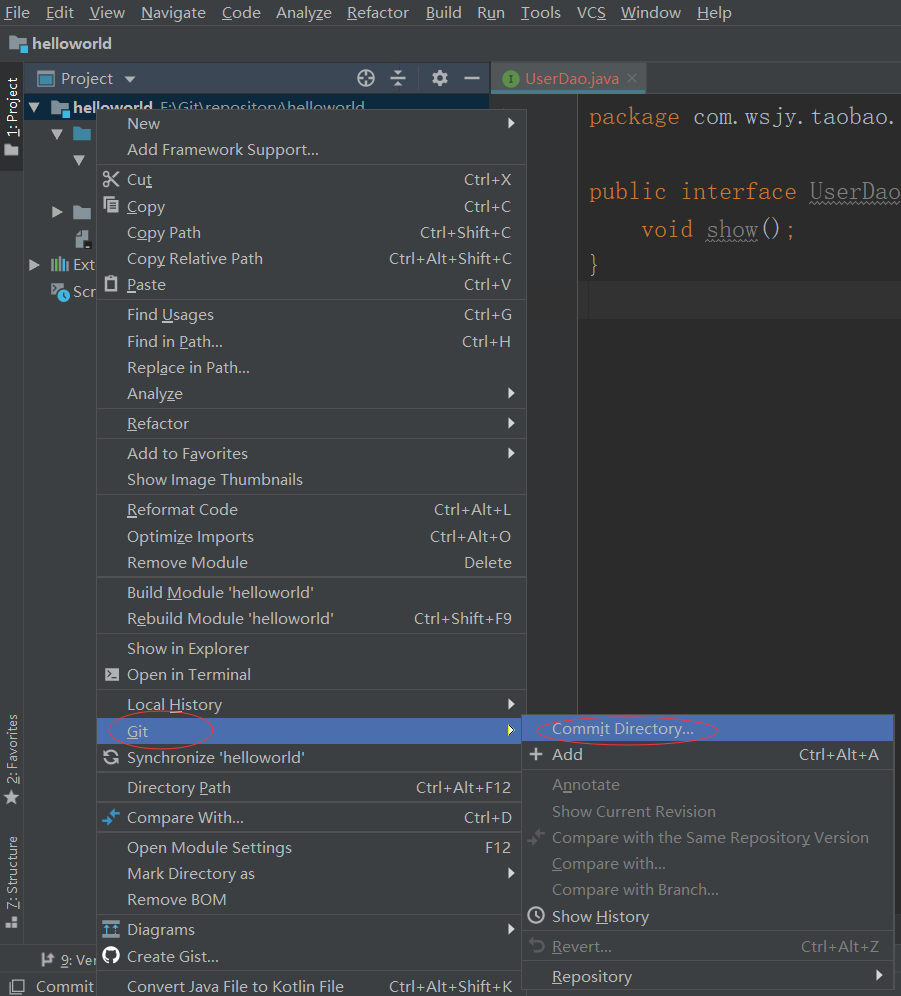
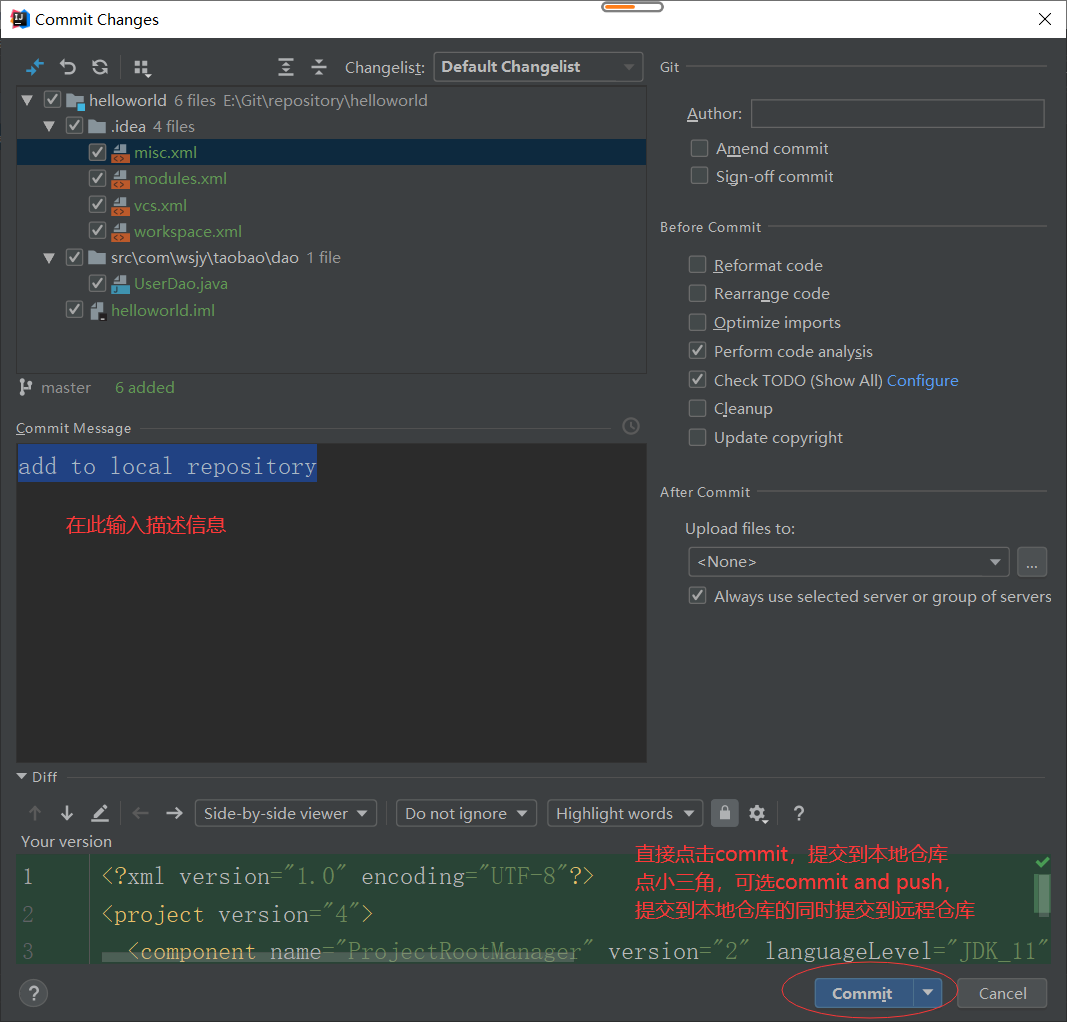
6、将本地版本库的文件推送到远程版本库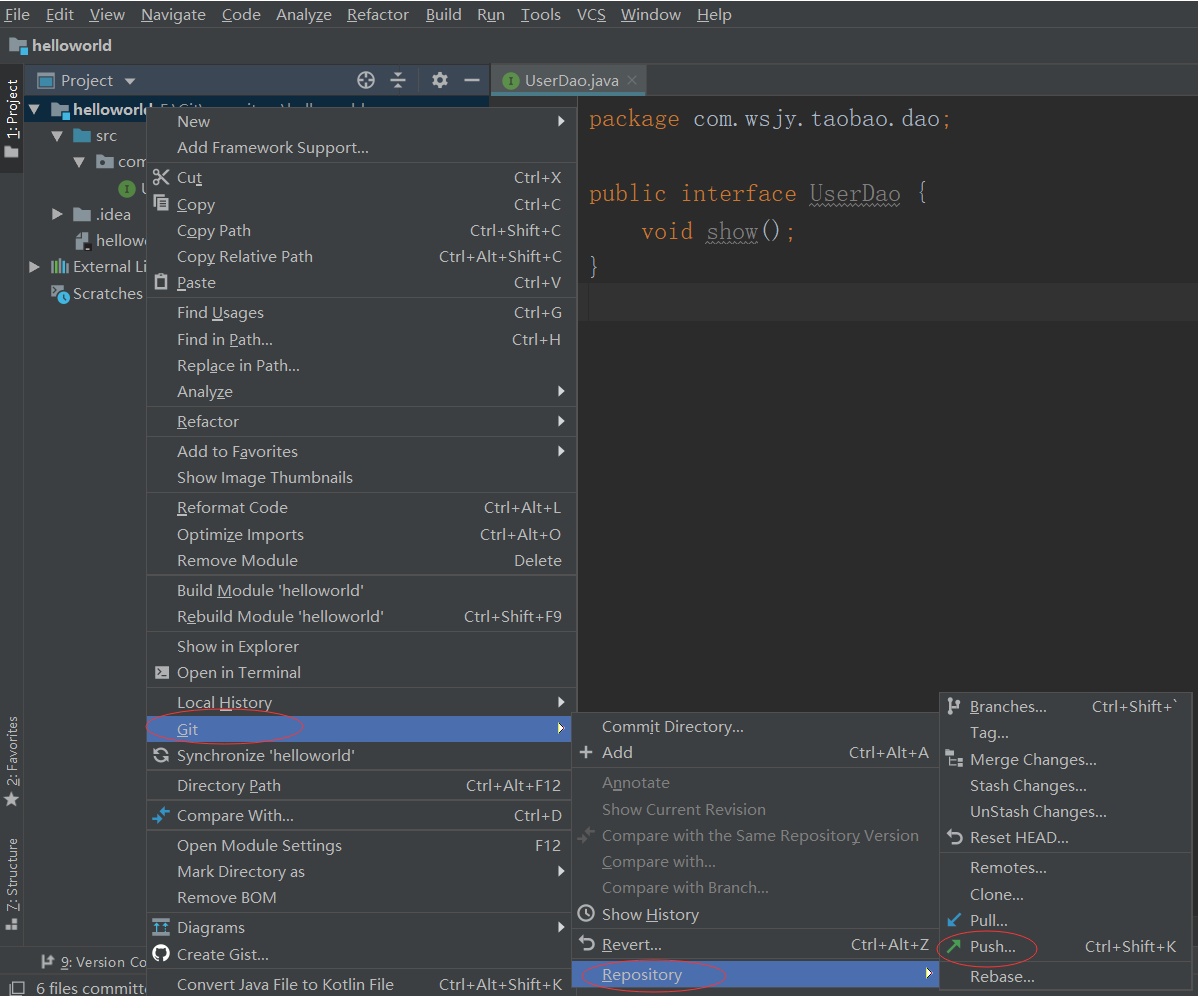
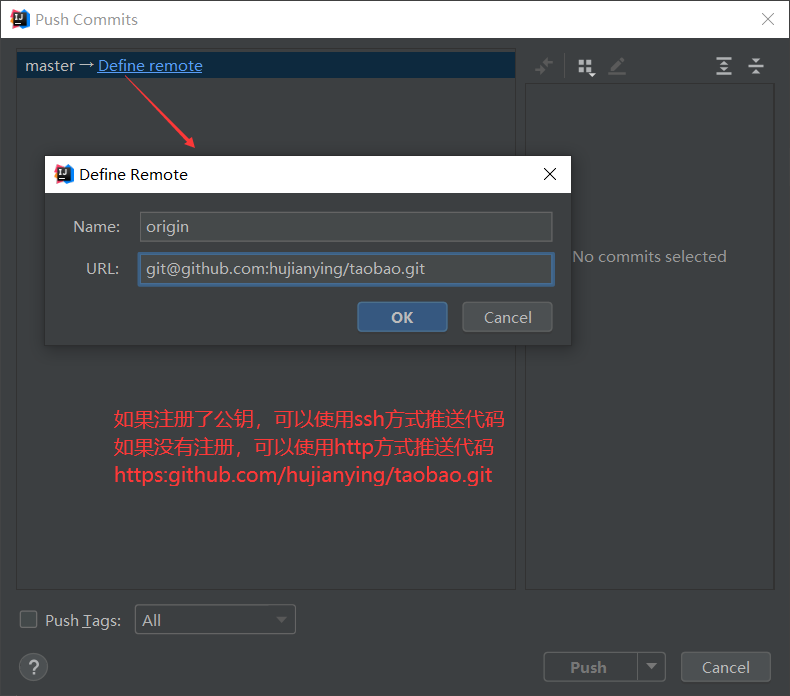
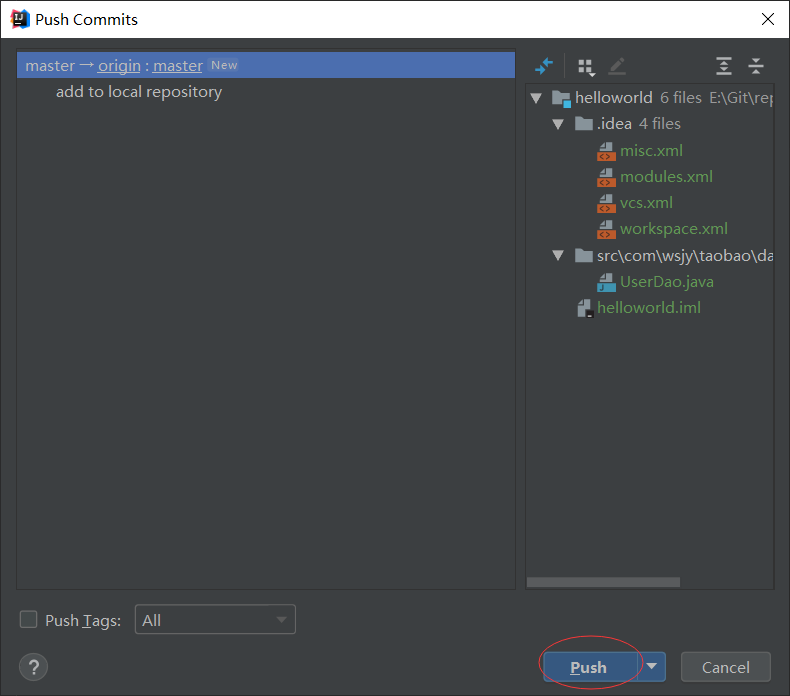
push成功后会出现push successful提示,此时刷新远程版本库会看到对应文件已被提交。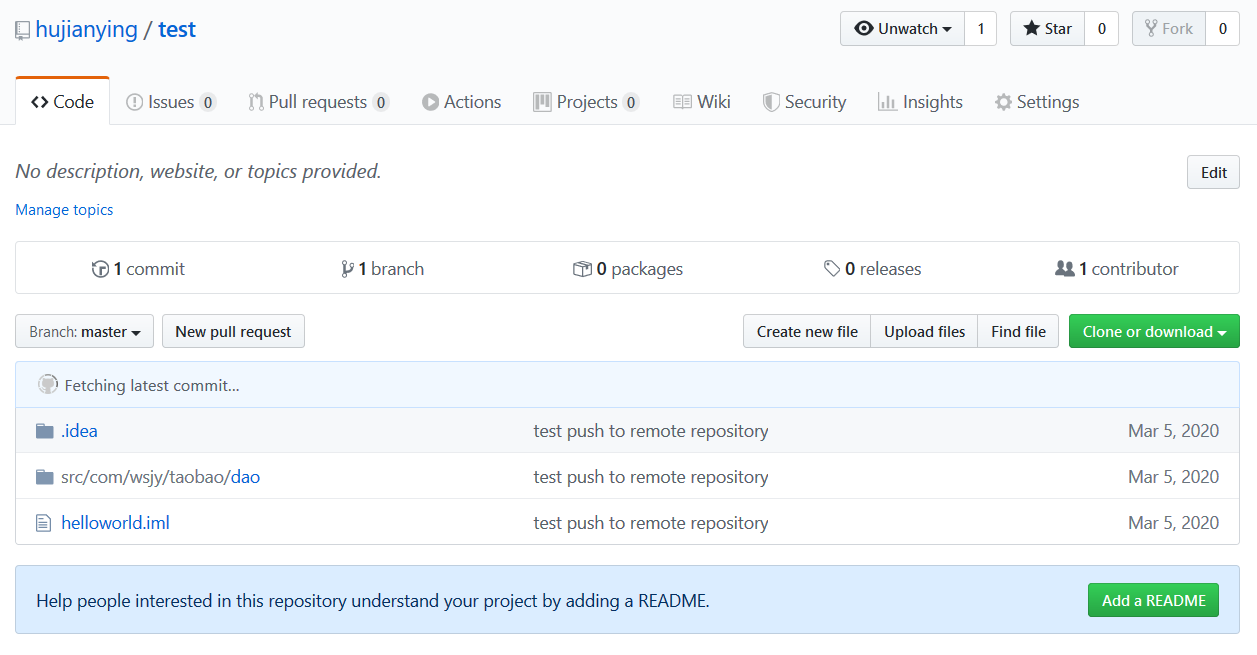
idea拉取远程版本库文件
第一次拉取文件


非第一次拉取

分支管理
工作中使用版本控制软件完成多人协作开发,是非常常见的场景。<br /> 假设有一个项目ego,由程序员A、程序员B、程序员C、程序员D一起开发。其中程序员A是项目组长,B、C、D为组员。项目为为4个模块:project_a、project_b、project_c、project_d,A、B、C、D分别对应开发其中的一个模块。<br /> 一般由项目组长A创建项目并上传到远程版本库。<br /> 使用idea可以在无远程版本库时将新建项目直接推送到Github,在此过程中会自动创建远程版本库并将项目推送至远程版本库中。<br />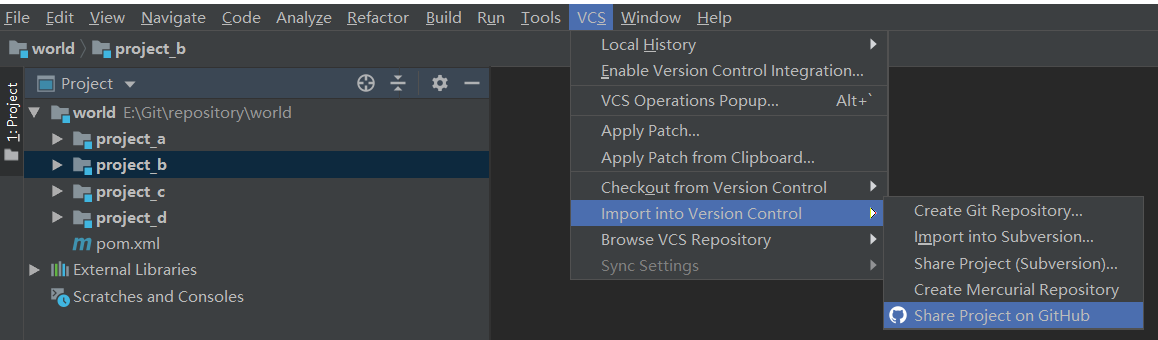<br />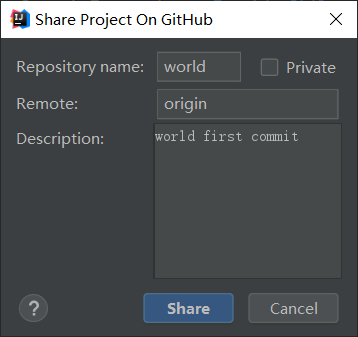<br /> 组员B、C、D分别从远程版本库拉取项目(参见从第一次拉取远程版本库文件操作)。<br /> 拉取项目后,B、C、D开始对各自的模块进行开发。组员各自对当前项目所做的修改,都可以分别推送到远程版本库(参见推送文件操作)。<br /> 如果在某个组员的将项目推送到远程版本库之前,其他成员已经push了他们的项目到远程版本库,此时,idea会要求进行分支合并才可以提交。<br /> 比如组长A推送了project_a到远程版本库,而后组员B再向远程版本库中推送project_b时,idea会做以下提示,要求合并分支。<br />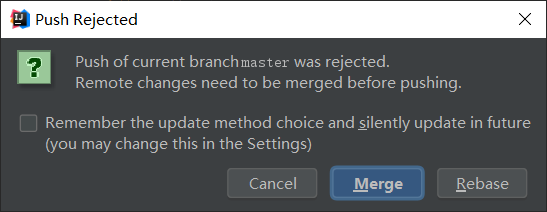<br /> 点击merge,此时idea会将自动完成本地版本库和远程版本库的同步。即先pull拉取远程版本库信息,再将更新后的本地版本库信息push推送到远程版本库中。
创建分支
如项目开发过程中,产品经理要求为项目增加新的功能,此需求应由组员C来实现。此时可为project_c模块创建新的分支,新功能的开发完全在分支中进行,不会影响project_c原本的项目主干master。<br /> 当新需求开发完毕并且测试无误后,可以将该分支再合并到project_c项目主干中并提交到远程版本库,也可选择将该分支提交到远程版本库,由项目组长A来决定是否与项目主干进行合并。<br />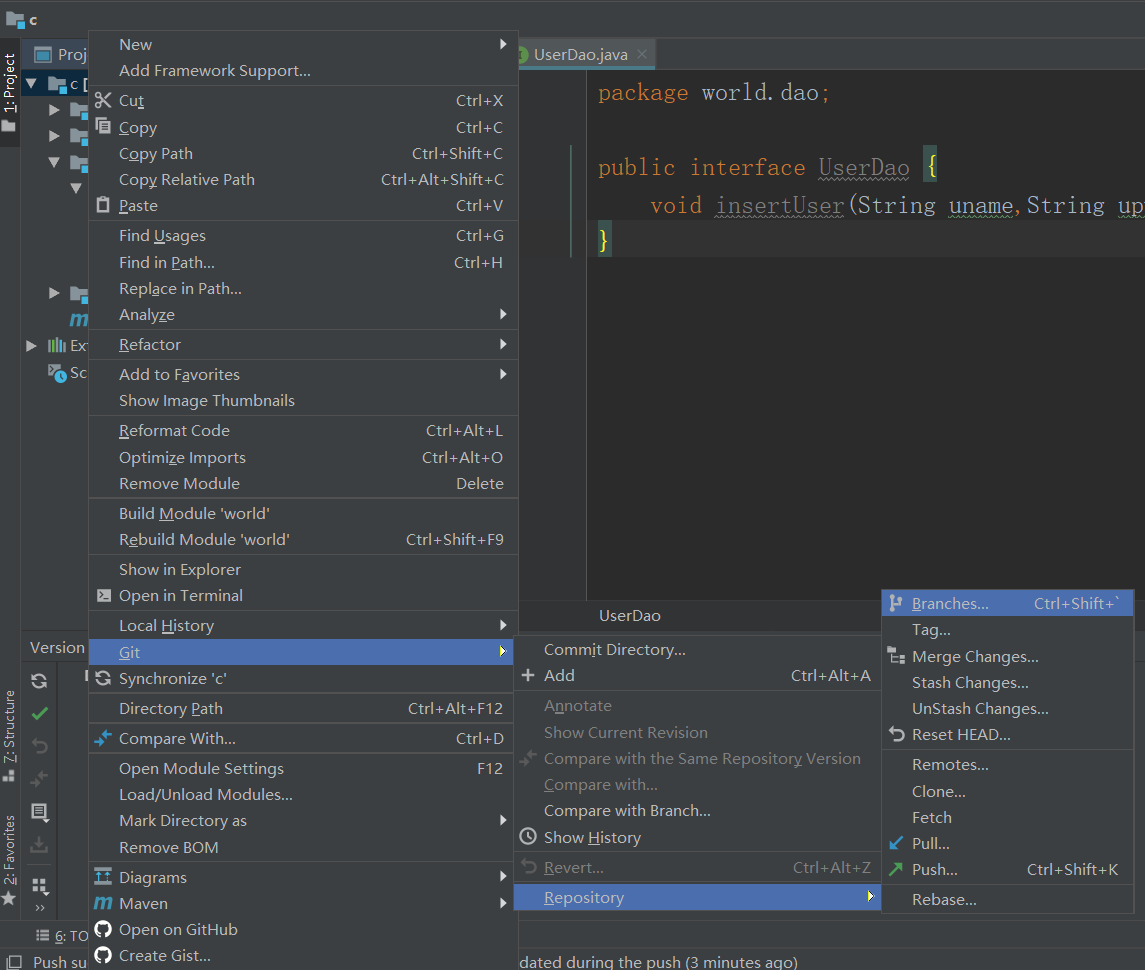<br /><br /><br /> 创建一个叫newFunction的新分支,勾选checkout branch代表创建后直接选中该分支。<br />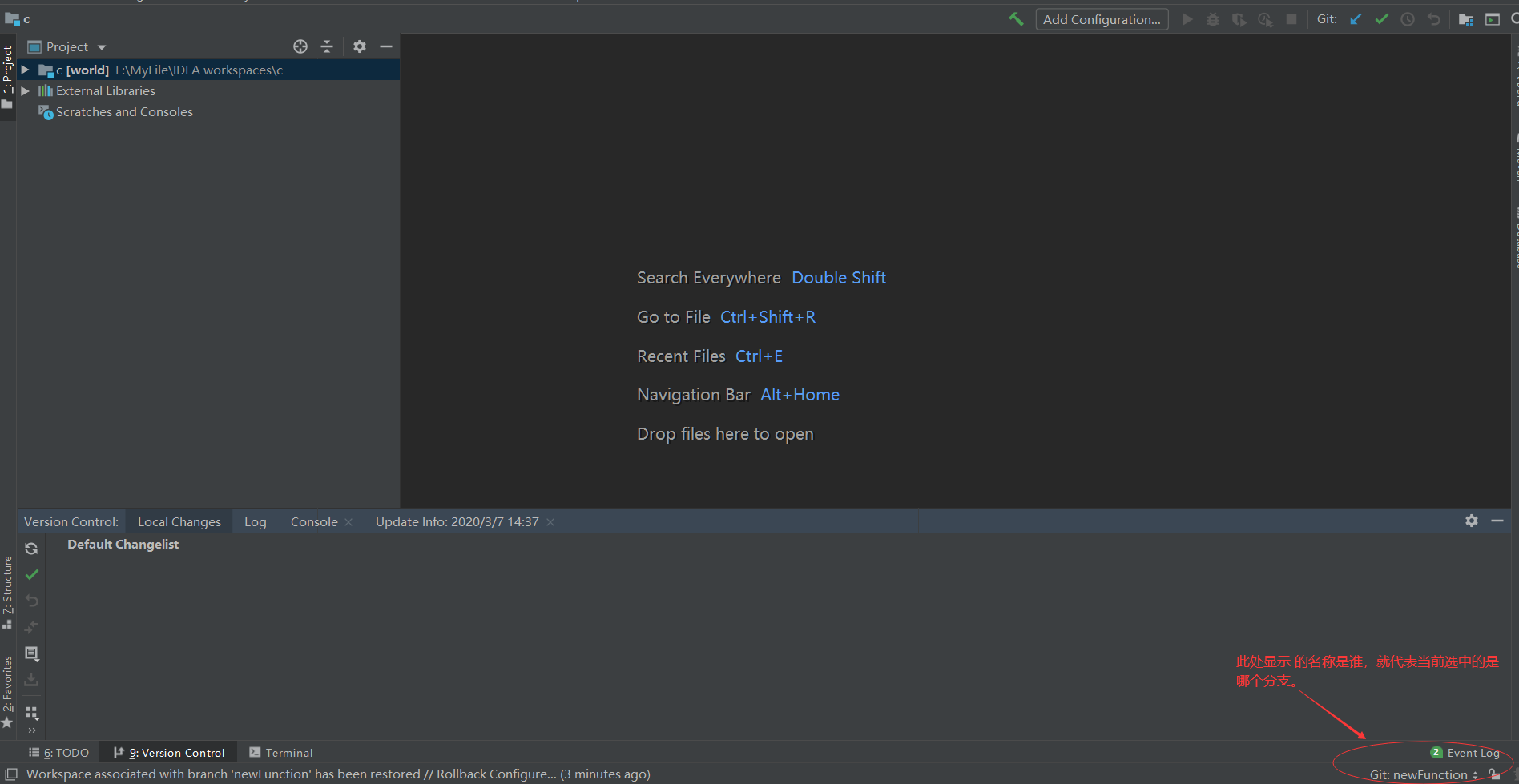<br /> 使用check out可以根据需要切换到不同的分支。<br />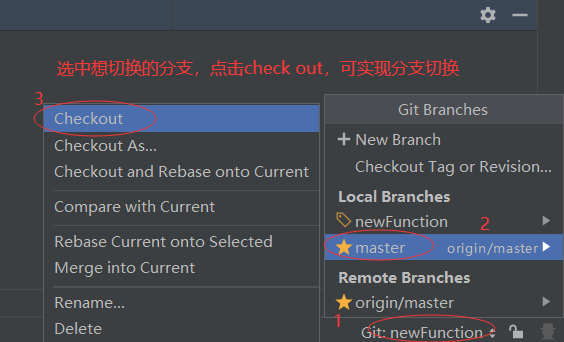
分支合并
一般来说,项目中的分支合并有两种选择:
- 直接在本地版本库中实现合并,最后完成本地版本库与远程版本库的同步。
- 提交到远程版本库,由项目组长决定是否进行合并。
本地版本库合并
先将分支开发的项目添加到的本地版本库(add/commit),此时切换到主干master,可以看到主干和分支的代码是不一样的(如果不commit到本地版本库,切换分支时,两边的代码是一样的)。<br /> 切换到主干master,建议先执行pull,然后再执行merge into current进行分支合并。<br />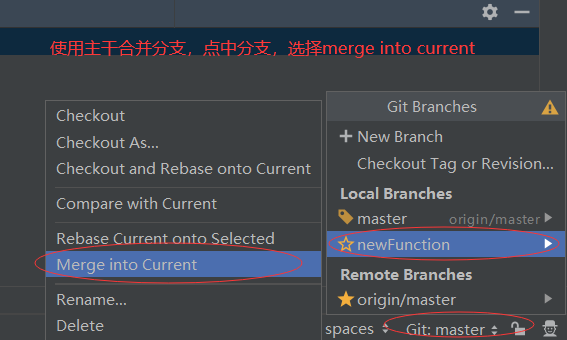<br /> 如果主干代码和分支代码没有冲突,此时会合并成功,分支代码会出现在主干内。此时的合并发生在本地版本库内,需要push才能完成本地版本库和远程版本库的同步。取消分支合并
当合并后有可能发现分支中的功能出现了bug或其他原因,我们可以取消合并。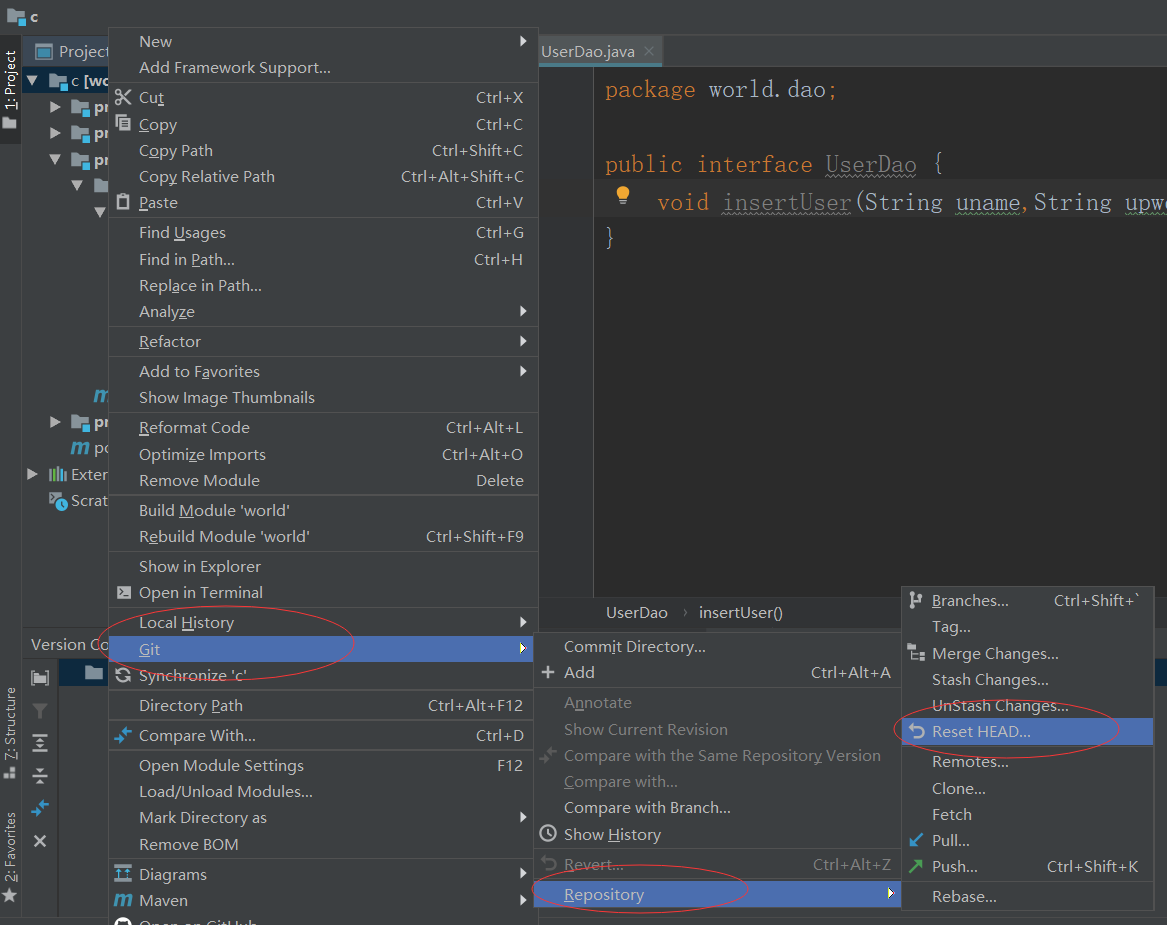
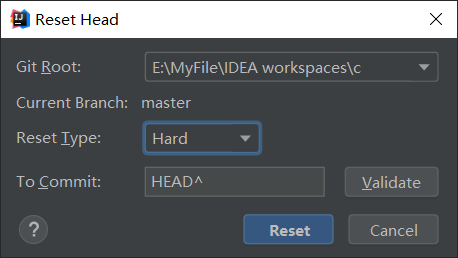
HEAD^ 是还原到上一个版本,HEAD^^ 是还原到上上一个版本。
Reset Type 有三种:
- mixed 默认方式,只保留源码,回退commit和index信息
- soft 回退到某个版本,只回退了commit的信息,不会恢复到index file一级。如果还要提交,直接commit
hard 彻底回退,本地源码也会变成上一个版本内容
一般使用默认的 mixed 或者粗暴的 hard 方式。因为是取消合并,所以选择 Hard 方式,并且是HEAD^还原到上一个版本,回退后恢复了原来master的代码。
请注意,合并是发生在本地版本库,因此无法通过在本地版本库中的取消合并操作影响到远程版本库。远程版本库合并
将远程分支pull到本地,与本地master合并后,再将本地master push到远程,然后将远程分支删除。

若有收获,就点个赞吧
0 人点赞
