(我是个纯入门级别的小白,之前琛师兄让我学习pytorch,然而自己过于懒惰,开学新训的后半段基本就都浪费掉了,新训前半段刚刚接触的python,所以很多地方会犯一些低级的错误。以后只能自己多学习,多积累了。
/(ㄒoㄒ)/~~)
1.pytorch介绍
PyTorch是一个开源的Python机器学习库,基于Torch,用于自然语言处理等应用程序。其可以提供两个高级功能:1、具有强大的GPU加速的张量计算(如NumPy)。2、包含自动求导系统的的深度神经网络。
2.pytorch下载
可以直接从官网内挑选自己的pytorch格式,从而进行下载。(下载最新版本太过于缓慢了,而且国内的一些镜像网站也用不了,所以我就在’Previous versions of Pytorch’里面选择了1.5.0+cpu版本,其代码主要如下)
pip install torch==1.5.0+cpu torchvision==0.6.0+cpu -f https://download.pytorch.org/whl/torch_stable.html
(也可以尝试下后面链接的博客教学:镜像网站使用)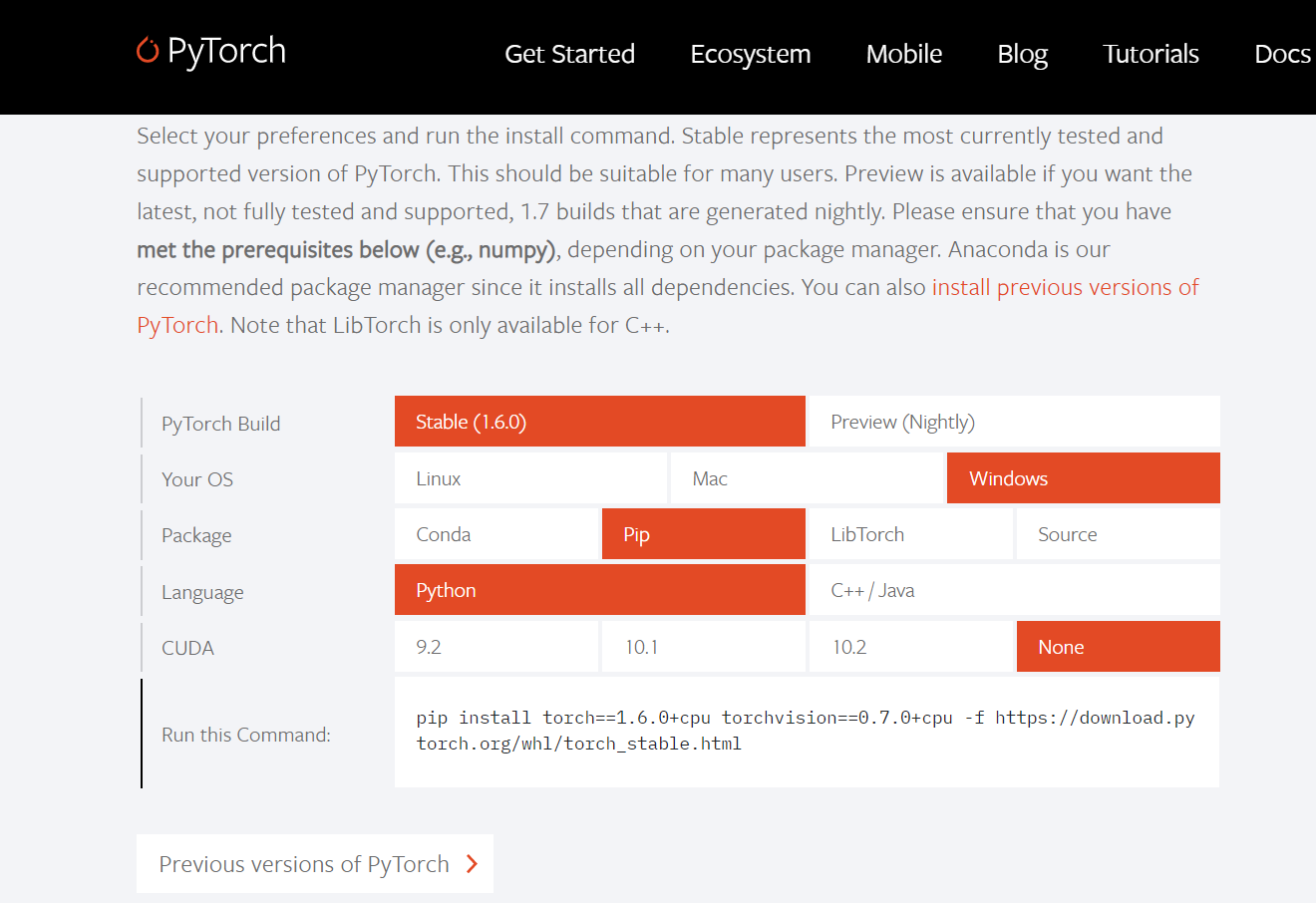
3.pytorch 60分钟快速学习
然后就是要开始紧张刺激的学习了(小白入门全是坑/(ㄒoㄒ)/~~),首先,这个pytorch的教程分为四个部分,首先是pytorch的入门介绍,然后是’Autograd’(好吧,我并不知道什么是自动分化,只是从内容上感觉是在求矩阵的梯度、雅可比行列式),第三个就是比较重要的教你怎么搭建神经网络(以灰度图像为例,如果跟我一开始一样对于图像处理、信号处理的知识基本为零的话,就赶紧去学习吧,后面补知识的时候看看有没有时间再做个这方面的总结)
,最后第四个就是手把手的教我们实战——如何实现对一个彩色图像的分类。(我的最后的程序就主要是对于第二部分和第三部分的融会贯通吧。)
如果看了英文版实在是摸不着头脑的话,可以参考一下:pytorch打怪路。文章里面对大多数用到的函数进行了解释,非常有用!
4.pytorch实现MNIST集手写数字识别
4.1.1加载并标准化数据及MNIST
import torchimport torchvisionimport torchvision.transforms as transforms#---------------1.加载并标准化数据及MNIST#归一化图像数据#如果在Windows上运行,但出现BrokenPipeError,请尝试设置torch.utils.data.DataLoader()的num_worker设置为0。transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.1307,), (0.3081,))])#cifar10为RGB信道,三维,故其对RGB 图像做归一化为 Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))trainset = torchvision.datasets.MNIST(root='./data', train=True,download=True, transform=transform)trainloader = torch.utils.data.DataLoader(trainset, batch_size=4,shuffle=True, num_workers=2)testset = torchvision.datasets.MNIST(root='./data', train=False,download=True, transform=transform)testloader = torch.utils.data.DataLoader(testset, batch_size=4,shuffle=False, num_workers=2)classes = ('0', '1', '2', '3','4', '5', '6', '7', '8', '9')
- 使用深度学习在进行图像分类或者对象检测时候,首先需要对图像做数据预处理,最常见的对图像预处理方法有两种,正常白化处理又叫图像标准化处理,另外一种方法叫做归一化处理。
- 本文采用的是归一化处理方法,调用的函数为transforms.ToTensor、transforms.Normalize,ToTensor()能够把灰度范围从0-255变换到0-1之间,而后面的transform.Normalize()则把0-1变换到(-1,1)。
transforms.Normalize使用如下公式进行归一化:channel=(channel-mean)/std
其中mean为均值,std为标准差
- 先介绍一下torchvision库,它是pytorch的一个图形库,主要用于pytorch深度学习的部分,可以用来构建计算机视觉模型主要有下面几个构成
torchvision.datasets: 一些加载数据的函数及常用的数据集接口;torchvision.models: 包含常用的模型结构(含预训练模型),例如AlexNet、VGG、ResNet等torchvision.transforms: 常用的图片变换,例如裁剪、旋转等;torchvision.utils: 其他的一些有用的方法
- 该段代码利用了其中的
torchvision.transforms.Compose()类。这个类的主要作用是串联多个图片变换的操作。详细使用方法可以参考transforms.Compose()类详解:串联多个transform操作、pytorch中transforms使用详解
上述程序最终实现了将mnist数据集下载下来,并对图像数据进行预处理,使得图像灰度范围变换到(-1,1).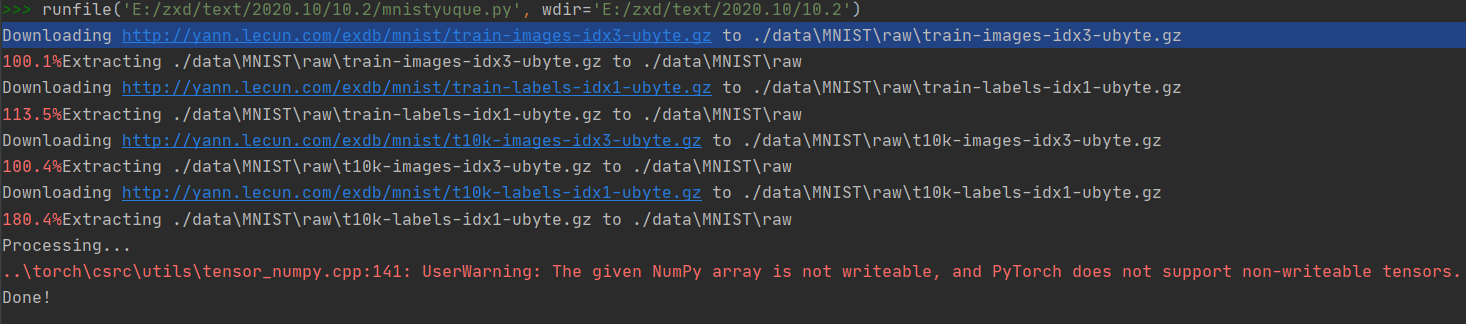
(最后有个报错的小问题,这里就是说在用数据读取的时候无需换成PIL的数据格式了,直接numpy格式就可以,无需转来转去,多此一举!报错解决办法,但是我有点不太知道针对该种模式可以怎么修改程序,回来空了再回头看看)
4.1.2显示图像与标签
import matplotlib.pyplot as pltimport numpy as np--------1.2显示图像def imshow(img):img = img /4+0.2#使范围位于[0,1],貌似当灰度范围在(-1,1)时图像无法显示出来npimg = img.numpy()#print(np.max(npimg))plt.imshow(np.transpose(npimg, (1, 2, 0)))plt.show()# 随机获得训练图像if __name__ == '__main__':dataiter = iter(trainloader)images, labels = dataiter.next()# 显示图像imshow(torchvision.utils.make_grid(images))# 显示图像对应的标签print(' '.join('%5s' % classes[labels[j]] for j in range(4)))
- 调用了
numpy、matplotlib库(当初pip这两个库的时候,我用的是3.9版本,可是一直下载不下来,而且因为是最新版本,连镜像网站上都没有这个库,所以最后我卸载了我的3.9换成了3.7版本。。。深刻教训,以后下载什么库啊包啊之类的千万不要用最新的哈哈)一个是数组库,一个是绘图库,详细教学我也不太会,只能是边用边积累了 - 在不加
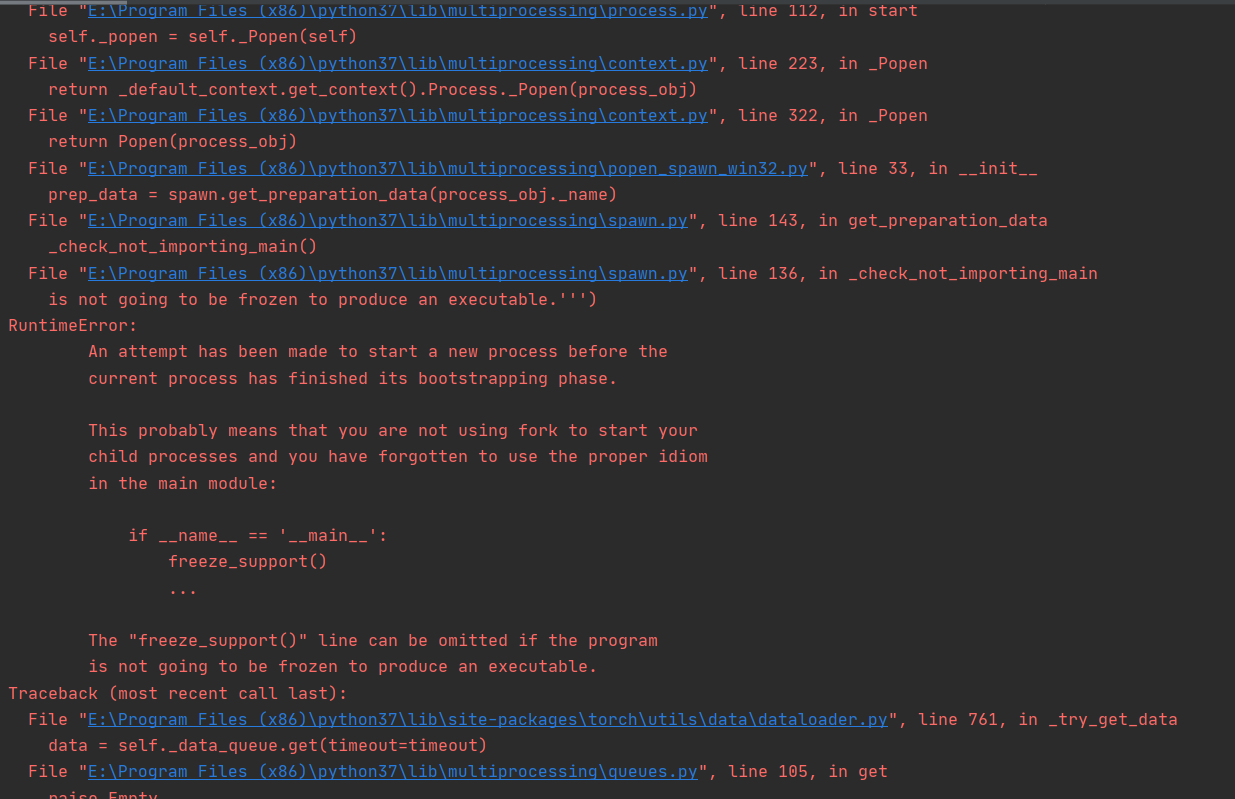
if __name__ == '__main__':时,会产生下面这种报错,只有加了这个条件才能正常运行。 - Python中if name == ‘main‘:的作用和原理
最终我们随机显示的训练集图像及其标签如下:(此段代码可以不放在主代码里,只用作展示)

4.2定义卷积神经网络
#--------------2.定义卷积神经网络from torch.autograd import Variableimport torch.nn as nnimport torch.nn.functional as Fclass Net(nn.Module): # 我们定义网络时一般是继承的torch.nn.Module创建新的子类def __init__(self):super(Net, self).__init__()self.conv1 = nn.Conv2d(1, 25, 3) # 添加第一个卷积层,调用了nn里面的Conv2d()self.pool = nn.MaxPool2d(2, 2) # 最大池化层self.conv2 = nn.Conv2d(25, 50, 3) # 同样是卷积层self.fc1 = nn.Linear(50*5*5, 1024) # 接着三个全连接层self.fc2 = nn.Linear(1024, 128)self.fc3 = nn.Linear(128, 10)def forward(self, x):x = self.pool(F.relu(self.conv1(x))) # F是torch.nn.functional的别名,这里调用了relu函数 F.relu()x = self.pool(F.relu(self.conv2(x)))x = x.view(-1, 50*5*5) # .view( )是一个tensor的方法,使得tensor改变size但是元素的总数是不变的。# 第一个参数-1是说这个参数由另一个参数确定, 比如矩阵在元素总数一定的情况下,确定列数就能确定行数。# 那么为什么这里只关心列数不关心行数呢,因为马上就要进入全连接层了,而全连接层说白了就是矩阵乘法,# 你会发现第一个全连接层的首参数是50*5*5,所以要保证能够相乘,在矩阵乘法之前就要把x调到正确的size# 更多的Tensor方法参考Tensor: http://pytorch.org/docs/0.3.0/tensors.htmlx = F.relu(self.fc1(x))x = F.relu(self.fc2(x))x = self.fc3(x)return x# 和python中一样,类定义完之后实例化就很简单了,我们这里就实例化了一个netnet = Net()#print(net)
其中卷积层参数的设置参考了:PyTorch基础入门六 ,由于python掌握的不是很熟练,关于类的相关内容从这里辅助理解:Python类的定义和使用
神经网络的相关知识还有着很大匮乏,计划通过阅读《深度学习的入门 基于python的理论和实现》进一步掌握。
4.3定义损失函数和优化器
#------------------3.定义损失函数和优化器import torch.optim as optim # 导入torch.potim模块criterion = nn.CrossEntropyLoss() # 同样是用到了神经网络工具箱 nn 中的交叉熵损失函数optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9) # optim模块中的SGD梯度优化方式---随机梯度下降
4.4训练网络
#--------------------4.训练网络if __name__ == '__main__':for epoch in range(2): # loop over the dataset multiple times 指定训练一共要循环几个epochrunning_loss = 0.0 #定义一个变量方便我们对loss进行输出for i, data in enumerate(trainloader, 0):# 这里我们遇到了第一步中出现的trailoader,代码传入数据# enumerate是python的内置函数,既获得索引也获得数据,# get the inputs; data is a list of [inputs, labels]# data是从enumerate返回的data,包含数据和标签信息,分别赋值给inputs和labelsinputs, labels = datainputs, labels = Variable(inputs), Variable(labels) # 将数据转换成Variable,第二步里面我们已经引入这个模块,所以这段程序里面就直接使用了# zero the parameter gradientsoptimizer.zero_grad() # 要把梯度重新归零,因为反向传播过程中梯度会累加上一次循环的梯度# forward + backward + optimizeoutputs = net(inputs) # 把数据输进网络net,这个net()在第二步的代码最后一行我们已经定义了loss = criterion(outputs, labels) # 计算损失值,criterion我们在第三步里面定义了loss.backward() # loss进行反向传播,下文详解optimizer.step() # 当执行反向传播之后,把优化器的参数进行更新,以便进行下一轮# print statistics # 这几行代码不是必须的,为了打印出loss方便我们看而已,不影响训练过程running_loss+=loss.item() # 从下面一行代码可以看出它是每循环0-1999共两千次才打印一次if i % 2000 == 1999: # print every 2000 mini-batches 所以每个2000次之类先用running_loss进行累加print('[%d, %5d] loss: %.3f' %(epoch + 1, i + 1,running_loss / 2000)) # 然后再除以2000,就得到这两千次的平均损失值running_loss = 0.0 # 这一个2000次结束后,就把running_loss归零,下一个2000次继续使用print('Finished Training')# 快速保存模型PATH = './cifar_net.pth'torch.save(net.state_dict(), PATH)
运行上述程序可以得到以下输出: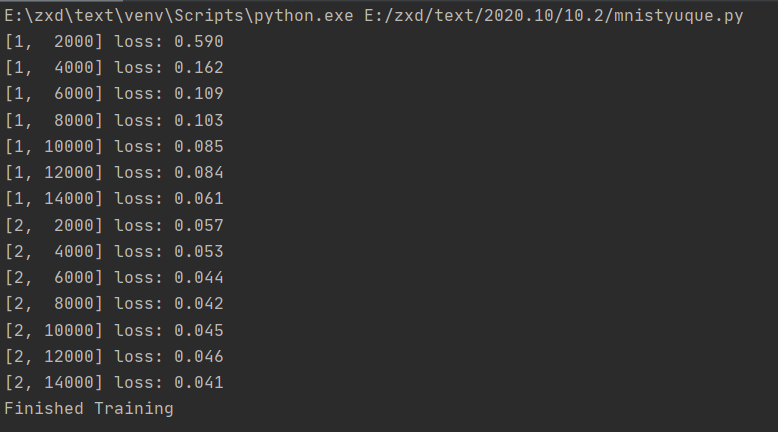
已经在训练数据集中对网络进行了2次训练,可以得到一组比较适合的参数。
其中模型加载和训练需要注意(使得后面测试集调用网络可以不用再重新训练)
4.5测试准确率及各个标签下的准确率
#---------------------------------------------------------def imshow(img):img = img /4+0.2#使范围位于[0,1]npimg = img.numpy()#print(np.max(npimg))plt.imshow(np.transpose(npimg, (1, 2, 0)))plt.show()if __name__ == '__main__':dataiter = iter(testloader) # 创建一个python迭代器,读入的是我们第一步里面就已经加载好的testloaderimages, labels = dataiter.next() # 返回一个batch_size的图片,根据第一步的设置,应该是4张imshow(torchvision.utils.make_grid(images)) # 展示这四张图片print('GroundTruth: ',' '.join('%5s' % classes[labels[j]] for j in range(4))) # python字符串格式化 ' '.join表示用空格来连接后面的字符串,参考python的join()方法
最终我们随机显示的测试集图像及其标签如下:(此段代码可以不放在主代码里,只用作展示)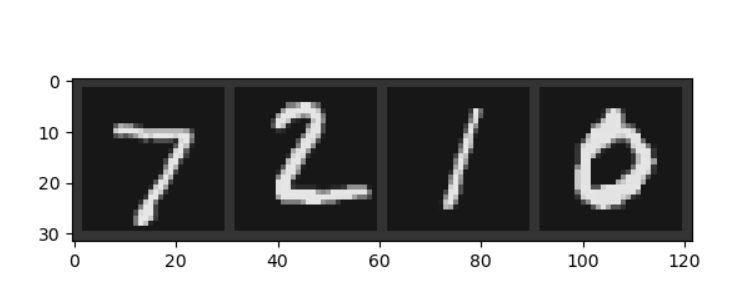

最后,检验我们网络模型的准确率:
#----------------------------------------- 5.测试准确率correct = 0 # 定义预测正确的图片数,初始化为0total = 0 # 总共参与测试的图片数,也初始化为0with torch.no_grad():for data in testloader: # 循环每一个batchimages, labels = dataoutputs = net(images) # 输入网络进行测试_, predicted = torch.max(outputs.data, 1)total += labels.size(0) # 更新测试图片的数量correct += (predicted == labels).sum().item() # 更新正确分类的图片的数量print('Accuracy of the network on the 10000 test images: %d %%' % (100 * correct / total)) # 最后打印结果#----------------- 6.各类准确率class_correct = list(0. for i in range(10))# 定义一个存储每类中测试正确的个数的 列表,初始化为0class_total = list(0. for i in range(10))# 定义一个存储每类中测试总数的个数的 列表,初始化为0with torch.no_grad(): # 以一个batch为单位进行循环for data in testloader:images, labels = dataoutputs = net(images)_, predicted = torch.max(outputs, 1)c = (predicted == labels).squeeze()for i in range(4): # 因为每个batch都有4张图片,所以还需要一个4的小循环label = labels[i] # 对各个类的进行各自累加class_correct[label] += c[i].item()class_total[label] += 1for i in range(10):print('Accuracy of %5s : %2d %%' % (classes[i], 100 * class_correct[i] / class_total[i]))
最终得到的识别准确率为: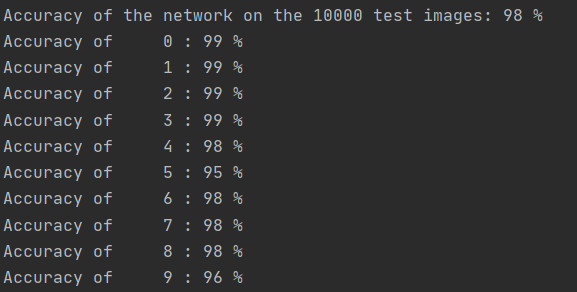
程序仍然存在一些瑕疵.后续可以继续改进。
4.6完整代码(不包含训练集与测试集图像的展示)
import torchimport torchvisionimport torchvision.transforms as transforms#---------------1.加载并标准化数据及MNIST#归一化图像数据#如果在Windows上运行,但出现BrokenPipeError,请尝试设置torch.utils.data.DataLoader()的num_worker设置为0。transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.1307,), (0.3081,))])#cifar10为RGB信道,三维,故其对RGB 图像做归一化为 Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))trainset = torchvision.datasets.MNIST(root='./data', train=True,download=True, transform=transform)trainloader = torch.utils.data.DataLoader(trainset, batch_size=4,shuffle=True, num_workers=2)testset = torchvision.datasets.MNIST(root='./data', train=False,download=True, transform=transform)testloader = torch.utils.data.DataLoader(testset, batch_size=4,shuffle=False, num_workers=2)classes = ('0', '1', '2', '3','4', '5', '6', '7', '8', '9')import matplotlib.pyplot as pltimport numpy as np#--------------2.定义卷积神经网络from torch.autograd import Variableimport torch.nn as nnimport torch.nn.functional as Fclass Net(nn.Module): # 我们定义网络时一般是继承的torch.nn.Module创建新的子类def __init__(self):super(Net, self).__init__() # 第二、三行都是python类继承的基本操作,此写法应该是python2.7的继承格式,但python3里写这个好像也可以self.conv1 = nn.Conv2d(1, 25, 3) # 添加第一个卷积层,调用了nn里面的Conv2d()self.pool = nn.MaxPool2d(2, 2) # 最大池化层self.conv2 = nn.Conv2d(25, 50, 3) # 同样是卷积层self.fc1 = nn.Linear(50*5*5, 1024) # 接着三个全连接层self.fc2 = nn.Linear(1024, 128)self.fc3 = nn.Linear(128, 10)def forward(self, x): # 这里定义前向传播的方法,为什么没有定义反向传播的方法呢?这其实就涉及到torch.autograd模块了,# 但说实话这部分网络定义的部分还没有用到autograd的知识,所以后面遇到了再讲x = self.pool(F.relu(self.conv1(x))) # F是torch.nn.functional的别名,这里调用了relu函数 F.relu()x = self.pool(F.relu(self.conv2(x)))x = x.view(-1, 50*5*5) # .view( )是一个tensor的方法,使得tensor改变size但是元素的总数是不变的。# 第一个参数-1是说这个参数由另一个参数确定, 比如矩阵在元素总数一定的情况下,确定列数就能确定行数。# 那么为什么这里只关心列数不关心行数呢,因为马上就要进入全连接层了,而全连接层说白了就是矩阵乘法,# 你会发现第一个全连接层的首参数是16*5*5,所以要保证能够相乘,在矩阵乘法之前就要把x调到正确的size# 更多的Tensor方法参考Tensor: http://pytorch.org/docs/0.3.0/tensors.htmlx = F.relu(self.fc1(x))x = F.relu(self.fc2(x))x = self.fc3(x)return x# 和python中一样,类定义完之后实例化就很简单了,我们这里就实例化了一个netnet = Net()#print(net)#------------------3.定义损失函数和优化器import torch.optim as optim # 导入torch.potim模块criterion = nn.CrossEntropyLoss() # 同样是用到了神经网络工具箱 nn 中的交叉熵损失函数optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9) # optim模块中的SGD梯度优化方式---随机梯度下降#--------------------4.训练网络if __name__ == '__main__':for epoch in range(2): # loop over the dataset multiple times 指定训练一共要循环几个epochrunning_loss = 0.0 #定义一个变量方便我们对loss进行输出for i, data in enumerate(trainloader, 0):# 这里我们遇到了第一步中出现的trailoader,代码传入数据# enumerate是python的内置函数,既获得索引也获得数据,# get the inputs; data is a list of [inputs, labels]# data是从enumerate返回的data,包含数据和标签信息,分别赋值给inputs和labelsinputs, labels = datainputs, labels = Variable(inputs), Variable(labels) # 将数据转换成Variable,第二步里面我们已经引入这个模块,所以这段程序里面就直接使用了# zero the parameter gradientsoptimizer.zero_grad() # 要把梯度重新归零,因为反向传播过程中梯度会累加上一次循环的梯度# forward + backward + optimizeoutputs = net(inputs) # 把数据输进网络net,这个net()在第二步的代码最后一行我们已经定义了loss = criterion(outputs, labels) # 计算损失值,criterion我们在第三步里面定义了loss.backward() # loss进行反向传播,下文详解optimizer.step() # 当执行反向传播之后,把优化器的参数进行更新,以便进行下一轮# print statistics # 这几行代码不是必须的,为了打印出loss方便我们看而已,不影响训练过程running_loss+=loss.item() # 从下面一行代码可以看出它是每循环0-1999共两千次才打印一次if i % 2000 == 1999: # print every 2000 mini-batches 所以每个2000次之类先用running_loss进行累加print('[%d, %5d] loss: %.3f' %(epoch + 1, i + 1,running_loss / 2000)) # 然后再除以2000,就得到这两千次的平均损失值running_loss = 0.0 # 这一个2000次结束后,就把running_loss归零,下一个2000次继续使用print('Finished Training')# 快速保存模型PATH = './cifar_net.pth'torch.save(net.state_dict(), PATH)#----------------------------------------- 5.测试准确率correct = 0 # 定义预测正确的图片数,初始化为0total = 0 # 总共参与测试的图片数,也初始化为0with torch.no_grad():for data in testloader: # 循环每一个batchimages, labels = dataoutputs = net(images) # 输入网络进行测试_, predicted = torch.max(outputs.data, 1)total += labels.size(0) # 更新测试图片的数量correct += (predicted == labels).sum().item() # 更新正确分类的图片的数量print('Accuracy of the network on the 10000 test images: %d %%' % (100 * correct / total)) # 最后打印结果#----------------- 6.各类准确率class_correct = list(0. for i in range(10))# 定义一个存储每类中测试正确的个数的 列表,初始化为0class_total = list(0. for i in range(10))# 定义一个存储每类中测试总数的个数的 列表,初始化为0with torch.no_grad(): # 以一个batch为单位进行循环for data in testloader:images, labels = dataoutputs = net(images)_, predicted = torch.max(outputs, 1)c = (predicted == labels).squeeze()for i in range(4): # 因为每个batch都有4张图片,所以还需要一个4的小循环label = labels[i] # 对各个类的进行各自累加class_correct[label] += c[i].item()class_total[label] += 1for i in range(10):print('Accuracy of %5s : %2d %%' % (classes[i], 100 * class_correct[i] / class_total[i]))
5.感悟
至此,基本实现了基于pytorch的神经网络方法在MNIST数据集上的复现,从中会发现很多自己还存在的问题,比如说关于图像处理方面的知识储备过差,编程实现能力不足,很多基础知识并不牢固,关于神经网络的知识只是进行了相关的了解。
后续在学习一些课程的同时,就需要多看看神经网络的架构,和一些参数的调整方法,进一步打牢自己的基础。

若有收获,就点个赞吧
0 人点赞
