目前,大部分的主流关系型数据库都提供了主从热备功能,通过配置两台(或多台)数据库的主从关系,可以将一台数据库服务器的数据更新同步到另一台服务器上。网站可以利用数据库的这一功能,实现数据库的读写分离,从而改善数据库的负载压力。
利用数据库的读写分离,Web服务器在写数据的时候,访问主数据库(Master),主数据库通过主从复制机制将数据更新同步到从数据库(Slave),这样当Web服务器读数据的时候,就可以通过从数据库获得数据。这一方案使得在大量读操作的Web应用可以轻松地读取数据,而主数据库也只会承受少量的写入操作,还可以实现数据热备份,可谓是一举两得的方案。
一、主从复制原理
关系型数据库的读写分离能够实现数据库的主从架构,那么主从架构中最重要的数据复制又是怎么一回事呢?<br />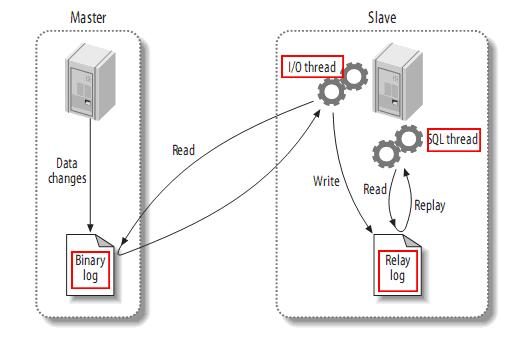<br /> 从上图来看,整体上有如下三个步凑:
(1)Master将改变记录到二进制日志(binary log)中(这些记录叫做二进制日志事件,binary log events);
(2)Slave将Master的二进制日志事件(binary log events)拷贝到它的中继日志(relay log);
(3)Slave重做中继日志(Relay Log)中的事件,将Master上的改变同步到它自己的数据库中。
二、mysql主从架构过程
第一步:在Slave服务器上执行start slave命令开启主从复制开关,开始进行主从复制。
第二步:此时,Slave服务器的I/O线程会通过在Master上已经授权的复制用户权限请求连接Master服务器,并请求从指定binlog日志文件的指定位置(日志文件名和位置就是在配置主从复制服务时执行change master命令指定的)之后开始发送binlog日志内容。
第三步:Master服务器接受到来自Slave服务器的I/O线程请求后,其上负责复制的I/O线程会根据Slave服务器的I/O线程请求的信息分批读取指定binlog日志文件指定位置之后的binlog日志信息,然后返回给Slave端I/O线程。返回的信息中除了binlog日志内容外,还有在Master服务器段记录的新的binlog文件名称,以及在新的binlog中的下一个指定更新位置。
第四步:当Slave服务器I/O线程获取到Master服务器上I/O线程发送的日志内容、日志文件及位置点后,会将binlog日志内容依次写到Slave端自身的Relay Log(即中继日志)文件(MySQL-relay-bin.xxxxxx)的最末端,并将新的binlog文件名和位置记录到master-info文件中,以便下一次读取Master端新binlog日志能够告诉Master服务器从新binlog日志的指定文件及位置开始请求新的binlog日志内容。
第五步:Slave服务器段的SQL线程会实时检测本地的Relay Log中I/O线程新增加的日志内容,然后及时地把Relay Log文件中的内容解析成SQL语句,并在自身的Slave服务器上按解析SQL语句的位置顺序执行应用这些SQL语句,并在relay-log.info中记录当前应用中继日志的文件名及位置点。
三、MySQL同步模式
3.1 异步复制(Asynchronous replication)
MySQL默认的复制即是异步的,主库在执行完客户端提交的事务后会立即将结果返给给客户端,不关心从库是否已经接收并处理,这样就会有一个问题,主如果crash掉了,此时主库上已经提交的事务可能并没有传到从库上,如果此时,强行将从库提升为主库,可能导致新主库上的数据不完整。
3.2 全同步复制(Fully synchronous replication)
指当主库执行完一个事务,所有的从库都执行了该事务才返回给客户端。因为需要等待所有从库执行完该事务才能返回,所以全同步复制的性能必然会收到严重的影响。
3.3 半同步复制(Semisynchronous replication)
一主多从模式下,有一个从节点返回成功,即成功,不必等待多个节点全部返回。介于异步复制和全同步复制之间,主库在执行完客户端提交的事务后不是立刻返回给客户端,而是等待至少一个从库接收到并写到relay log中才返回给客户端。相对于异步复制,半同步复制提高了数据的安全性,同时它也造成了一定程度的延迟,这个延迟最少是一个TCP/IP往返的时间。所以,半同步复制最好在低延时的网络中使用。
四、MySQL半同步复制技术
一般而言,普通的replication,即MySQL的异步复制,依靠MySQL二进制日志也即binary log进行数据复制。 比如两台机器,一台主机(master),另外一台是从机(slave)。
正常的复制为:
- 事务t1写入binlog buffer;
- dumper线程通知slave有新的事务t1;
- binlog buffer进行checkpoint;
- slave的io线程接收到t1并写入到自己的的relay log;
- slave的sql线程写入到本地数据库。
这时,master和slave都能看到这条新的事务,即使master挂了,slave可以提升为新的master。
异常的复制为:
- 事务t1写入binlog buffer;
- dumper线程通知slave有新的事务t1;
- binlog buffer进行checkpoint;
- slave因为网络不稳定,一直没有收到t1;
- master挂掉,slave提升为新的master,t1丢失。
很大的问题是: 主机和从机事务更新的不同步,就算是没有网络或者其他系统的异常,当业务并发上来时,slave因为要顺序执行master批量事务,导致很大的延迟。
为了弥补以上几种场景的不足,MySQL从5.5开始推出了半同步复制。
相比异步复制,半同步复制提高了数据完整性,因为很明确知道,在一个事务提交成功之后,这个事务就至少会存在于两个地方。即在master的dumper线程通知slave后,增加了一个ack(消息确认),即是否成功收到t1的标志码,也就是dumper线程除了发送t1到slave,还承担了接收slave的ack工作。 如果出现异常,没有收到ack,那么将自动降级为普通的复制,直到异常修复后又会自动变为半同步复制。即表示MASTER只需要接收到其中一台SLAVE的返回信息,就会commit;否则需等待直至达到超时时间然后切换成异步再提交。
4.1 半同步复制具体特性
主库产生binlog到主库的binlog file,传到从库中继日志,然后从库应用;也就是说传输是异步的,应用也是异步的。半同步复制指的是传输同步,应用还是异步的!
从库会在连接到主库时告诉主库,它是否配置了半同步。
如果半同步复制在主库端是开启了的,并且至少有一个半同步复制的从库节点,那么此时主库的事务线程在提交时会被阻塞并等待,结果有两种可能,要么至少一个从库节点通知它已经收到了所有这个事务的binlog事件,要么一直等待直到超过配置的某一个时间点为止,而此时,半同步复制将自动关闭,转换为异步复制。
从库节点只有在接收到某一个事务的所有Binlog,将其写入并Flush到Relay Log文件之后,才会通知对应主库上面的等待线程。
如果在等待过程中,等待时间已经超过了配置的超时时间,没有任何一个从节点通知当前事务,那么此时主库会自动转换为异步复制,当至少一个半同步从节点赶上来时,主库便会自动转换为半同步方式的复制。
半同步复制必须是在主库和从库两端都开启时才行,否则主库默认使用异步方式复制。
五、全同步复制(组复制)
组复制模型:它支持单主模型和多主模型两种工作方式(默认是单主模型)
单主模型: 从复制组中众多个MySQL节点中自动选举一个master节点,只有master节点可以写,其他节点自动设置为read only。当master节点故障时,会自动选举一个新的master节点,选举成功后,它将设置为可写,其他slave将指向这个新的master。
多主模型: 复制组中的任何一个节点都可以写,因此没有master和slave的概念,只要突然故障的节点数量不太多,这个多主模型就能继续可用。
组复制原理:组复制由多个 server成员构成,并且组中的每个 server 成员可以独立地执行事务,但所有读写(RW)事务只有在冲突检测成功后才会提交。只读(RO)事务不需要在冲突检测,可以立即提交。

若有收获,就点个赞吧
0 人点赞
