
MySQL的InnoDB索引数据结构是B+树,主键索引叶子节点的值存储的就是MySQL的数据行,普通索引的叶子节点的值存储的是主键值,这是了解聚簇索引和非聚簇索引的前提。
一、定义
- 聚簇索引:将数据存储与索引放到了一块,找到索引也就找到了数据,那么这个索引就是聚簇索引,所以主键就是聚簇索引,修改聚簇索引其实就是修改主键。
- 非聚簇索引:索引的存储和数据的存储是分离的,也就是说找到了索引但没找到数据,需要根据索引上的值(主键)再次回表查询,非聚簇索引也叫做辅助索引。myisam通过key_buffer把索引先缓存到内存中,当需要访问数据时(通过索引访问数据),在内存中直接搜索索引,然后通过索引找到磁盘相应数据,这也就是为什么索引不在key buffer命中时,速度慢的原因 。
澄清一个概念:innodb中,在聚簇索引之上创建的索引称之为辅助索引,辅助索引访问数据总是需要二次查找,非聚簇索引都是辅助索引,像复合索引、前缀索引、唯一索引,辅助索引叶子节点存储的不再是行的物理位置,而是主键值。
聚簇索引具有唯一性:由于聚簇索引是将数据跟索引结构放到一块,因此一个表仅有一个聚簇索引。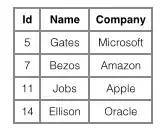
InnoDB:
- InnoDB使用的是聚簇索引,将主键组织到一棵B+树中,而行数据就储存在叶子节点上,若使用”where id = 14”这样的条件查找主键,则按照B+树的检索算法即可查找到对应的叶节点,之后获得行数据。
- 若对Name列进行条件搜索,则需要两个步骤:第一步在辅助索引B+树中检索Name,到达其叶子节点获取对应的主键。第二步使用主键在主索引B+树种再执行一次B+树检索操作,最终到达叶子节点即可获取整行数据。(重点在于通过其他键需要建立辅助索引)
MyISM:
MyISM使用的是非聚簇索引,非聚簇索引的两棵B+树看上去没什么不同,节点的结构完全一致只是存储的内容不同而已,主键索引B+树的节点存储了主键,辅助键索引B+树存储了辅助键。表数据存储在独立的地方,这两颗B+树的叶子节点都使用一个地址指向真正的表数据,对于表数据来说,这两个键没有任何差别。由于索引树是独立的,通过辅助键检索无需访问主键的索引树。
二、举例区分聚簇索引和非聚簇索引
下面创建了一个学生表,做三种查询,来说明什么情况下是聚簇索引,什么情况下不是。
create table student (id bigint,no varchar(20) ,name varchar(20) ,address varchar(20) ,PRIMARY KEY (`id`) USING BTREE,UNIQUE KEY `idx_no` (`no`) USING BTREE )ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC;
第一种,直接根据主键查询所有字段数据,此时主键是聚簇索引,因为主键对应的索引叶子节点存储了id=1的所有字段的值。
select from student where id = ‘1’;
第二种,根据编号查询编号和名称,编号本身是一个唯一索引,但查询的列包含了学生编号和学生名称,当命中编号索引时,该索引的节点的数据存储的是主键ID,需要根据主键ID重新查询一次,所以这种查询下no不是聚簇索引。
select no,name from student where no = ‘test’;
第三种,我们根据编号查询编号(有人会问知道编号了还要查询?要,你可能需要验证该编号在数据库中是否存在),这种查询命中编号索引时,直接返回编号,因为所需要的数据就是该索引,不需要回表查询,这种场景下no是聚簇索引。也是实现了索引覆盖。
*覆盖索引(covering index)指一个查询语句的执行只用从索引中就能够取得,不必从数据表中读取。
select no from student where no = ‘test’;
三、聚簇索引的优势
看上去聚簇索引的效率明显要低于非聚簇索引,因为每次使用辅助索引检索都要经过两次B+树查找,这不是多此一举吗?聚簇索引的优势在哪?
- 由于行数据和叶子节点存储在一起,同一页中会有多条行数据,访问同一数据页不同行记录时,已经把页加载到了Buffer中,再次访问的时候,会在内存中完成访问,不必访问磁盘。这样主键和行数据是一起被载入内存的,找到叶子节点就可以立刻将行数据返回了,如果按照主键Id来组织数据,获得数据更快。
- 辅助索引使用主键作为”指针”而不是使用地址值作为指针的好处是,减少了当出现行移动或者数据页分裂时辅助索引的维护工作,使用主键值当作指针会让辅助索引占用更多的空间,换来的好处是InnoDB在移动行时无须更新辅助索引中的这个”指针”。也就是说行的位置(实现中通过16K的Page来定位)会随着数据库里数据的修改而发生变化(前面的B+树节点分裂以及Page的分裂),使用聚簇索引就可以保证不管这个主键B+树的节点如何变化,辅助索引树都不受影响。
- 聚簇索引适合用在排序的场合,非聚簇索引不适合
- 取出一定范围数据的时候,使用用聚簇索引
- 二级索引需要两次索引查找,而不是一次才能取到数据,因为存储引擎第一次需要通过二级索引找到索引的叶子节点,从而找到数据的主键,然后在聚簇索引中用主键再次查找索引,再找到数据
- 可以把相关数据保存在一起。例如实现电子邮箱时,可以根据用户 ID 来聚集数据,这样只需要从磁盘读取少数的数据页就能获取某个用户的全部邮件。如果没有使用聚簇索引,则每封邮件都可能导致一次磁盘 I/O。
四、聚簇索引的劣势
- 维护索引很昂贵,特别是插入新行或者主键被更新导至要分页(page split)的时候。建议在大量插入新行后,选在负载较低的时间段,通过OPTIMIZE TABLE优化表,因为必须被移动的行数据可能造成碎片。使用独享表空间可以弱化碎片
- 表因为使用UUId(随机ID)作为主键,使数据存储稀疏,这就会出现聚簇索引有可能有比全表扫面更慢,

所以建议使用int的auto_increment作为主键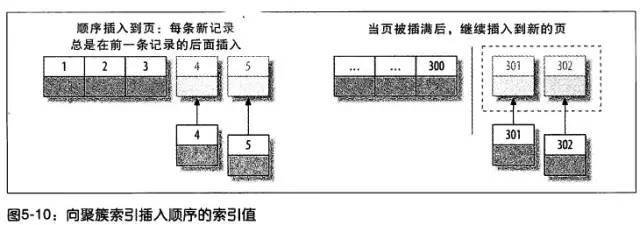
主键的值是顺序的,所以 InnoDB 把每一条记录都存储在上一条记录的后面。当达到页的最大填充因子时(InnoDB 默认的最大填充因子是页大小的 15/16,留出部分空间用于以后修改),下一条记录就会写入新的页中。一旦数据按照这种顺序的方式加载,主键页就会近似于被顺序的记录填满(二级索引页可能是不一样的)

若有收获,就点个赞吧
0 人点赞
