一、数据备份有哪些种?
MySQL中数据备份的方式还是蛮多的,常见的有冷备份、逻辑备份、热备份、快照备份。
1.1 冷备份
冷备份:就是在数据库停止运行的情况下,直接备份磁盘中MySQL用来存储数据的那些数据文件。
MySQL中的数据最终都存储在表空间中的。表空间 == 表空间文件。其实而所谓的空间,本质上对应着存在于操作系统磁盘上的肉眼能看到的物理文件。
参考[表空间]文档,可以了解表空间怎么配置。
表空间
见下图,其中policy是库名,该目录下的.ibd文件就是policy数据库中的所有表的物理文件。
1.2 逻辑备份
逻辑备份: 使用 mysqldump 工具去备份数据。
为啥说mysqldump是逻辑备份?原因大概是:你使用mysqldump去备份最终得到的参数其实是一堆sql,再通过回放sql的形式完成数据的恢复。在MySQL中数据表、数据行其实是逻辑存上的概念。而数据页这种概念是物理真实存在的。所以你用mysqldump得到一堆sql,自然称得上是逻辑备份喽。
1.3 热备份
热备份:直接对运行中的数据库进行备份。相对于冷备份,热备份还是比较复杂的。你想啊,对处于运行过程中的数据库进行备份,肯定就得将一些增量的数据也备份进去。
通常人们会使用一款叫:xtraback 的工具完成数据库的热备份。
除此之外,有一款Golang写的开源工具 ghost,在github上还是挺火的。它是一款支持做无损DDL的工具。这款工具在实现支持无损DDL功能时,有一部分逻辑本质上也是在支持增量数据的备份。
ghost的实现手段是:添加binlog监听事件,监听到binlog event后去解析binlog得到sql,再回放这个SQL。就像是从库使用主库对binlog进行数据恢复一样。
1.4 快照备份
快照备份:不是数据库本身提供的能力,本质上是借助于文件系统的快照功能来实现对数据库的备份。
我们知道的Linux服务器本质上也是电脑的,它会有自己的磁盘,无论是固态硬盘,还是机械磁盘。反正会有这种固态存储。还需要进一步对磁盘进行分区。然后才有将Linux文件系统中的目录都会挂载在不同的分区上。这么做的目的,简单来说就像你的window有C盘、D盘、E盘。D盘中的出问题后不会影响E盘一样。
快照备份要求:数据库的所有数据文件都要放在一个数据分区中。
常见的支持快照工具的文件系统和设备有:FreeBSD、UFS文件系统、Solaris的ZFS文件系统。GNU/Linux的LVM(Logical Volume Manager)
二、mysqldump备份
mysqldump语法 mysqldump [arguments] > file_name;
1、备份指定的数据库
通过参数—databases 指定你要备份的数据库
mysqldump -uroot -p --databases db1 db2 db3 > 自定义名.sql;
# 如果你没有开启GTID选项,以下这些参数都没有必要添加的。
# --triggers 备份触发器
# --routines 备份存储过程和函数
# --events 备份事件调度器
./mysqldump --set-gtid-purged=OFF --databases stusy --triggers --routines --events -uroot -p > test_backup.sql;
2、备份指定数据库中的指定数据表: 通过参数 --tables 指定你要备份的数据表。
mysqldump -uroot -p --databases db1 db2 db3 --tables t1 t2 > 自定义名.sql;
3、对一个架构进行备份
不使用—databases,直接写数据库名。对整库架构进行备份
Copy./mysqldump —set-gtid-purged=OFF —triggers —routines —events -uroot -p mysql> mysql_backup.sql;
查看备份的结果
注意点:相对于使用 —databases 参数来说。最终产出的SQL中!!没有!!为你创建数据库。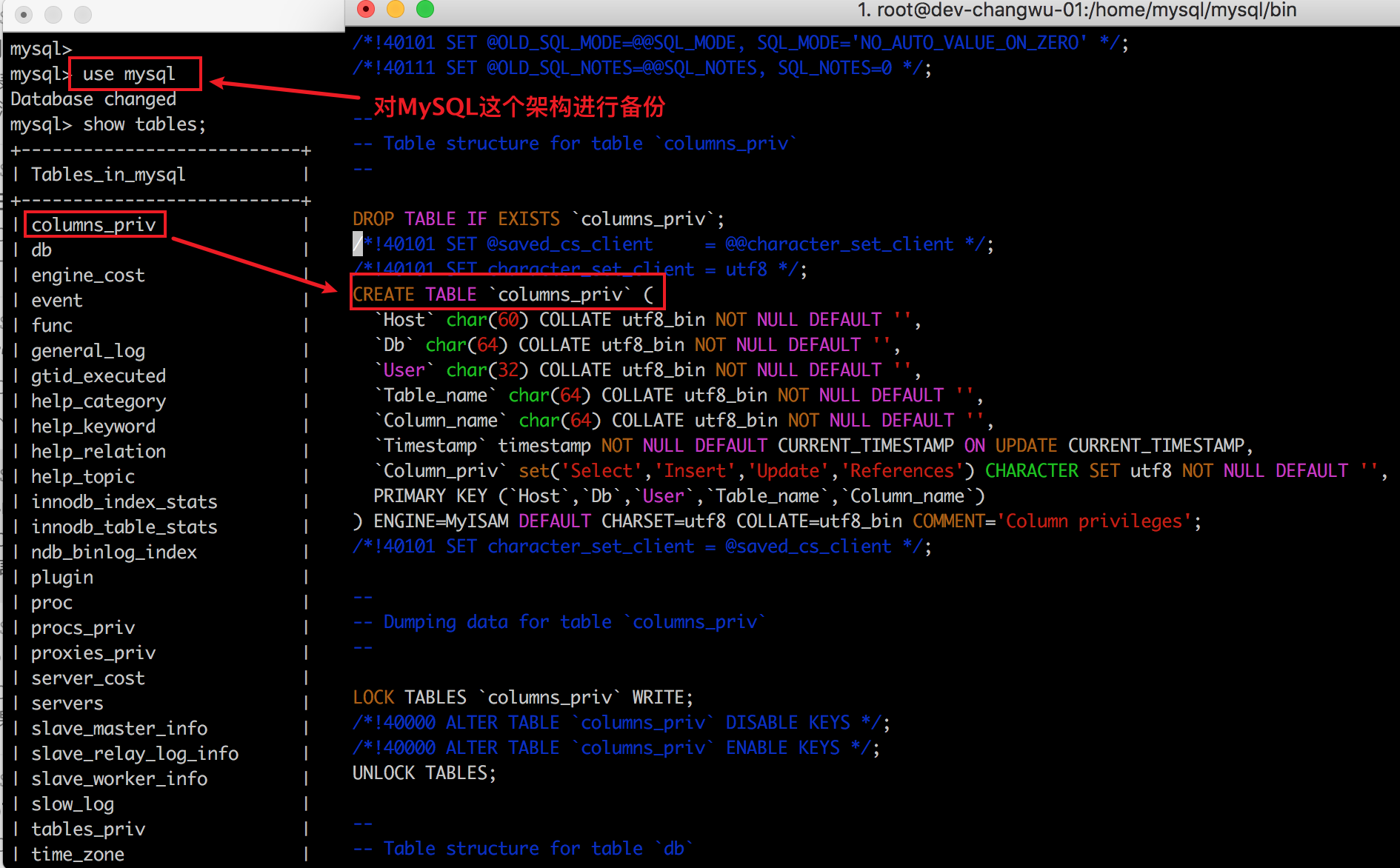
4、重点理解参数:—single-transaction
如果你想获得一份“一致性备份”可以使用该参数。那什么是一致性备份呢?
todo 下面的:我劝!这位年轻人不讲MVCC,耗子尾汁! 贴上链接。
添加—single-transaction参数后,mysqldump会自动帮你执行 start transaction 开启事务的SQL。如果你看过白日梦之前写的 “我劝!这位年轻人不讲MVCC,耗子尾汁!”,想必你一定了解,MVCC的实现原理,回到现在的这个问题中,也就是说,只要你执行开启事务的语句就会得到一个一致性可重复读的视图(read view)。说白了:此次执行mysqldump得到的SQL文件中的数据,就是你执行的该命令的那个瞬间,打下的快照的数据。
注意:如果你不使用—single-transaction参数,会自动添加上—lock-all-tables。此外,还需要知道当我们使用参数—single-transaction获取到的那个一致性实图并不能隔离DDL(表级别的操作,比如添加列)。所以你要确保在备份时没有其他的DDL语句执行。
5、重点理解参数:—master-data
Copy# 当值为1时,转存文件中会有change master 语句。 —master-data = 1 # 当值为2时,转存文件中当 change master 语句会被注释。 —master-data = 2
下面分别让 —master-data 为不同的值。查看产出。
Copy./mysqldump —set-gtid-purged=OFF —databases stusy —tables test_backup —triggers —routines —events —master-data=2 -uroot -p > test_backup.sql; 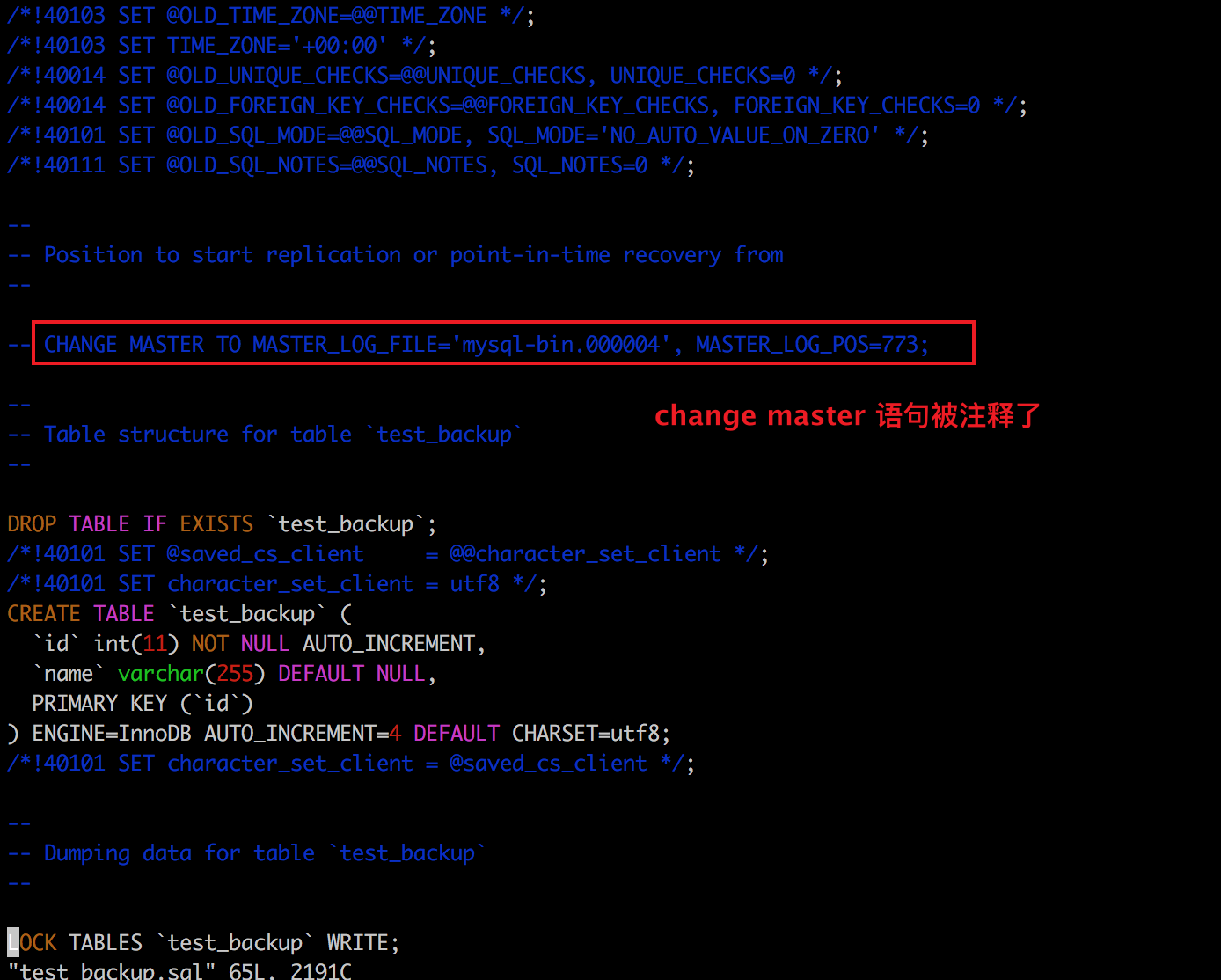
Copy./mysqldump —set-gtid-purged=OFF —databases stusy —tables test_backup —triggers —routines —events —master-data=1 -uroot -p > test_backup.sql; 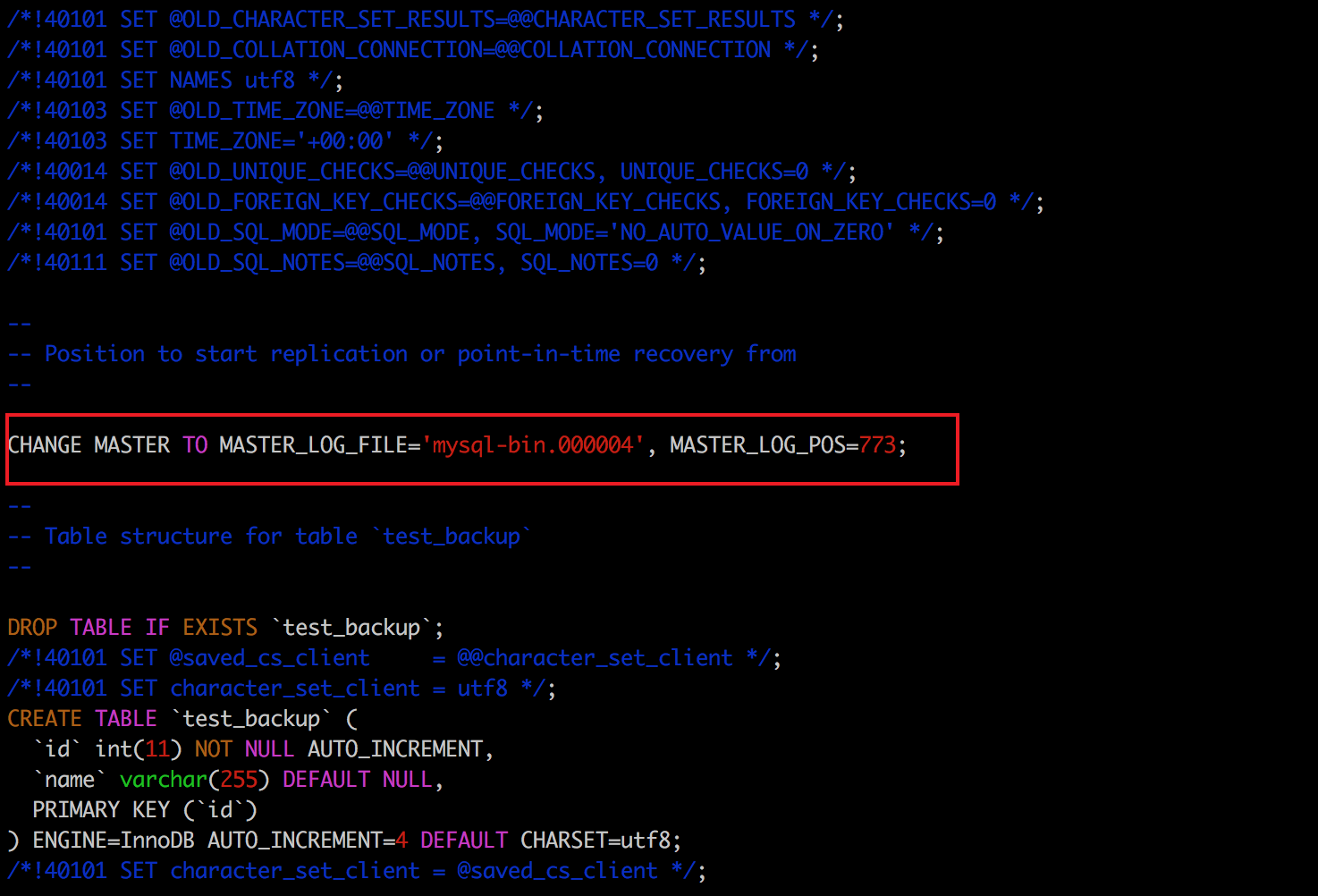
一般搭建过mysql集群的同学都知道这条change master sql语句的作用是: 从库认主库的命令。
是的,使用参数—master-data=1得到的备份文件通常主要做用是创建一个replication(从库)。
上面介绍了工作中常用的几种用法和注意点。
其实mysqldump支持的参数多达几十个。你可以使用 —help查看它们。
如果上面的参数不能满足你的需求。你可去官网查阅:https://dev.mysql.com/doc/refman/5.7/en/mysqldump.html
https://www.cnblogs.com/chenmh/p/5300370.html
三、binlog备份
3.1 GTID是什么
GTID (global transcation identifier):是MySQL5.6版本中添加进来的新特性 ,使用GTID可以唯一的标识一个事物。
GTID常见的作用:
比如一条update有语句进入MySQL之后经历如下过程,也是所谓的两阶段提交 :
- 写undolog
- 写redolog(prepare)
- 写binlog
- 写redolog(commit)
MySQL集群中,主库将自己成功执行过的事物都写在binlog,然后集群中的从库会dump主库记录的binlog回放出数据,完成数据同步。当我们将GTID相关的配置打开后,update语句经历如下过程:
1. 写undolog # 回滚
2. 写redolog(prepare) # 保证提交的不会丢失
3. 写一个特殊的Binlog Event,类型为GTID_Event,指定下一个事务的GTID
4. 写binlog # 主从同步事物使用
5. 写redolog(commit)
也就是说mysql会在binlog中多为我们记录一行GTID。这个GTID和当前事物唯一对应。不会重复。
这时当从库向主库发送同步数据当请求时:binlog和GTID都会传送到slave端,从库在回放日志同步数据时,同样会使用GTID写binlog,这样主库和从库之间的数据,就通过GTID强制性的关联并且保持同步了。
这时如果从库想在主库同步数据,只需要告诉主库自己有哪些GTID就好了,主库会把从库没有的GTID对应的事务日志给从库让它去同步数据。
在这种方式出现之前,主从之间同步数据时,从库需要告诉主库自己已经同步到binlog.0000x,position=yyy的地方了。这个binlog.0000x,position=yyy需要人为的去查看一下。不能说查看这两个信息比较麻烦,但是肯定不如GTID来的方便。
3.2 binlog长啥样
查看binlog:mysqlbinlog --base64-output=DECODE-ROWS -v binlog.000011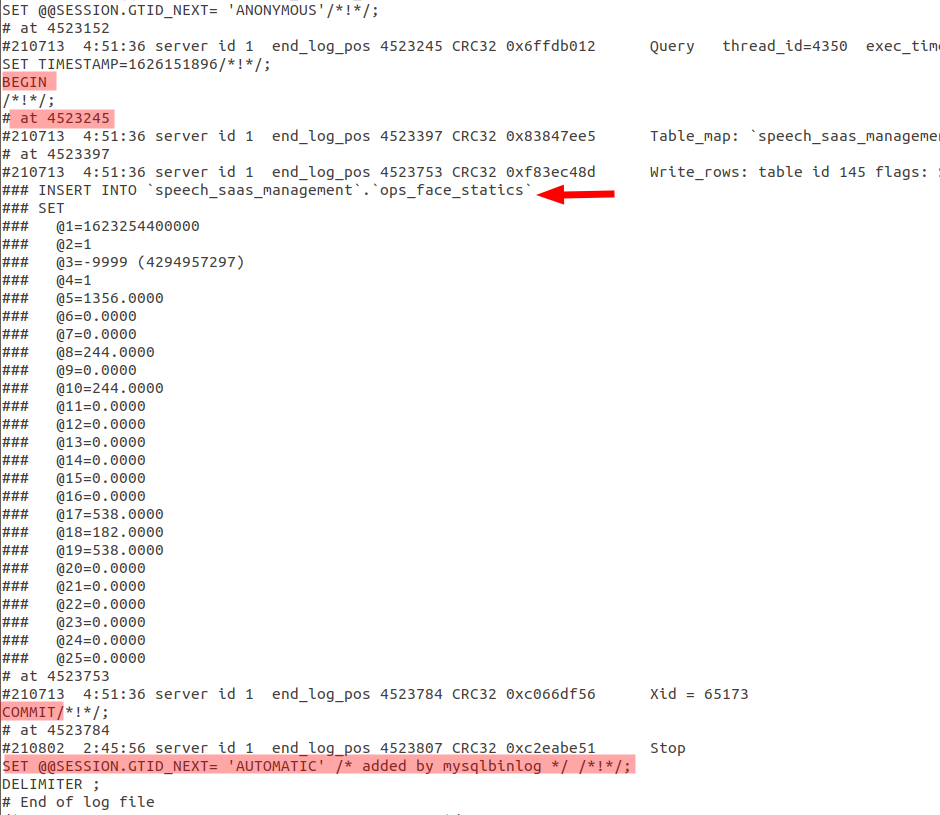
binlog中只会记录对数据库作出修改的写入或者更新的sq。就像上图中中begin、xxx、commit。
binlog中是有位点的,称为:position。即上图中的at xxx中的xxx。每一个事物都有自己的开启、结束位点,可以通过开始和结束位点找到事务。就上图,该事务的start-positon=956,stop-position=1230。
这个位点有啥用呢?
作用1:搭建主从集群时,通过下面的命令告诉从库,应该从主库的哪个binlog的哪个位点开始同步数据
CHANGE MASTER TO MASTER_HOST='10.157.23.158', MASTER_USER='mysqlsync', MASTER_PASSWORD='mysqlsync123', MASTER_PORT=8882, MASTER_LOG_FILE='mysql-bin.000008', MASTER_LOG_POS=1013; # 这就是位点作用2:数据恢复时,指定从哪个位点恢复到哪个位点,或者跳过哪个位点。
3.3 binlog进行数据恢复
其实误删数据后是可以通过binlog将数据恢复出来的。既然是使用binlog恢复数据,前提是你的MySQL开启了binlog(参数log_bin,默认情况下mysql不会帮你记录binlog)。如果没有打开binlog,数据可能真的没办法恢复。
线上的数据库不断承接流量,binlog会不断滚动变大,你要赶在binlog被清理之前去恢复数据。
情况一:没有开启GITD
如果你的MySQL没有开启GTID。直接使用下面的命令,就能把你指定的binlog中指定范围的positon的数据回放出来。除了用位点缩小范围,还可以指定开始时间和结束时间来缩小范围。
mysqlbinlog start-positon=956,stop-position=1230 ../var/binlog.000011 | ./mysql-uroot -p
思考这样的情况:
假设你没有赶在binlog被清理之前去恢复数据,当你去恢复数据时上图中delete sql之前的binlog已经被删除了。那怎么办?
这时你可以通过最近的全量备份把delete之前的数据恢复出来,然后delete之后的增量数据,通过mysqlbinlog工具恢复出来,注意别忘了通过positon跳过这个delete,不然一执行会放出来delete语句,数据又全被删除了。
如果你没有全量备份,binlog也不全了。那就悬了!
情况二:开启GITD
开启GTID的MySQL,同样执行这行命令恢复数据会遇到下面的错误。
mysqlbinlog start-positon=956,stop-position=1230 ../var/binlog.000011 | ./mysql-uroot -p

如果你看了前面白日梦跟你介绍的什么是GTID,想必你已经知道为啥报错了。因为你用binlog回放数据,其实就是让mysql重新执行一下binlog中记录的逻辑,问题就出在binlog中记录了set next_gtid=xxx,因为gtid唯一的,是不能重复的。
所以需要添加参数—skip-gtids=true
mysqlbinlog --skip-gtids=true --start-position=684 --stop-position=1485 ../var/mysql-bin.000003 | ./mysql -uroot -p
nter password:

若有收获,就点个赞吧
0 人点赞
