一、Mysql架构


- Mysql如果分成Server和存储引擎层2大部分,那么查询缓存(Caches)位于Server层,Buffer Pool位于存储引擎层。
- Tomcat通过Mysql驱动和Mysql数据库建立网络连接。
- 建立网络连接后,Java代码才能基于这个连接执行SQL语句。
- 数据库连接池: 在一个池子中维持多个数据库的连接,让多个线程使用里面不同的数据库连接去执行SQL语句,执行完后,不会销毁这个数据库连接,而是把连接放回池子里,后续可以继续使用。这样可以解决多个线程并发使用多个数据库连接执行SQL语句的问题,而且还避免了数据库连接的频繁创建和销魂的问题。
- 网络连接必须得分配给一个线程去处理,由一个线程来监听请求以及读取请求数据,比如从网络连接中读取和解析出来一条由我们系统发送过去的SQL语句。
- SQL接口: Mysql的工作线程接收到SQL语句后,就会转交给SQL接口去执行。
- 解析器(Parser): 通过解析器让机器理解这个SQL语句要干什么。比如: 一条查询语句
SELECT id,name,age FROM user WHERE id=1,通过查询解析器解析,会把这个语句拆分成以下几个部分:
a、从”user”表里查询;
b、查询id为1的那行数据;
c、对查询出的那行数据提取id,name,age字段。
- 优化器(Optimizer): 通过优化器选择一条最优查询路径。
- 执行器: 执行器根据优化器生成一套执行计划,然后不停调用存储引擎的各种接口去完成SQL语句的执行计划。(大致就是不停的更新或者提取一些数据出来)
- 存储引擎: 调用存储引擎接口,真正执行SQL语句。我们的数据有的存放在内存中,有的存放在磁盘文件里,现在已知道SQL语句如何执行了, 怎么知道哪些数据在内存?哪些数据在磁盘?执行的时候是更新内存数据,还是更新磁盘数据? 如果更新磁盘数据,是先查询哪个磁盘文件,再更新哪个磁盘文件? 这个时候就需要存储引擎了,存储引擎就是执行SQL语句的,他会根据一定的步骤去查询内存缓存数据,磁盘数据,更新磁盘数据等执行操作。
二、存储引擎(InnoDB)架构
2.1 InnoDB的重要存储结构: 缓冲池
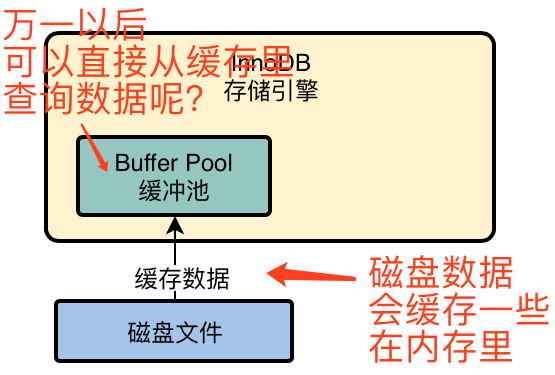

- InnoDB存储引擎有一个非常重要的放在内存中的组件,就是缓冲池(Buffer Pool),这里面会缓存很多数据,以便以后查询的时候,万一缓冲池中有的话,就不用去查磁盘了。
- 当InnoDB存储引擎要执行更新语句的时候,比如id=10,会先看看id=10的这条记录是否在缓冲池中,如果不在的话,那么会直接从磁盘中加载到缓冲池中,而且接着还会对这行记录加独占锁(不允许其他线程同时更新)。
2.2 undo日志文件: 如何让你更新的数据回滚?
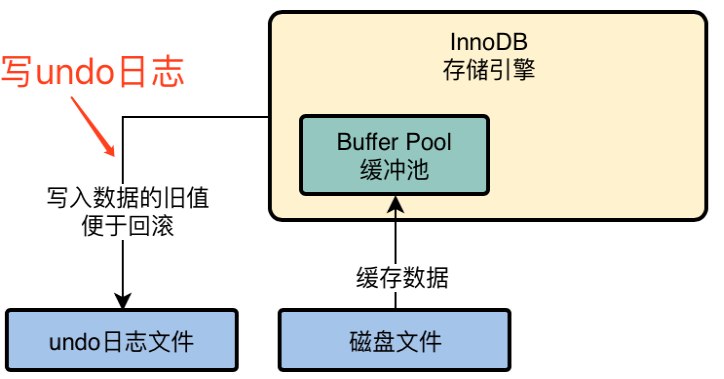
如果我们执行一个更新语句,且是一个事务操作,那么事务提交之前是可以回滚的,考虑未来可能会回滚数据的需求,会把更新前的值记录到undo日志文件中。比如: 更新id=10的记录name值是”zhangsan”,要改成”xxx”,那么就会把”zhangsan”写入undo日志文件。2.3 更新缓冲池中的数据

在进行了加载缓存数据和数据旧值写入undo日志后,就开始正式更新记录了,更新的时候会先更新缓冲池中的记录,此时这个数据就是脏数据,因为和磁盘中数据的不一致。2.4 Redo Log Buffer: 万一系统宕机,如何避免数据丢失?

为了保障数据的安全稳定,不丢失数据。InnoDB并不是一个事务提交后就将 Buffer Pool 中被修改的数据同步到磁盘上,而是要先记录到redo log日志中,以防崩溃之后可以恢复。最后再从Buffer Pool 中把脏页连续写入磁盘。而且记录到redo log日志中也不是直接写磁盘,而是先写到redo log 缓冲区。2.5 如果还没有提交事务,Mysql宕机了怎么办?

如果事务还没有提交,Mysql就崩溃了,那么内存Buffer Pool中修改过的数据和redo日志都会丢失。2.6 提交事务的时候,将redo日志写入磁盘中
接着我们想要提交一个事务,此时就会根据一定的策略把redo日志从Redo Log Buffer中刷入到磁盘文件中。
这个策略根据 innodb_flush_log_at_trx_commi参数配置。
redo log和binlog

若有收获,就点个赞吧
0 人点赞
