一. 定义
其中,x前的系数全为常数,x只有一次项。若n=1,则称为一元线性回归,若n>=2,则称为多元线性回归。
二.一元线性回归
(1)具体例子
这是一幅房价(纵轴)和房屋面积(横轴)之间关系的散点图,我们希望可以通过面积来预测房价,即找到函数f(x)=w0+w1x1,其中x1是房屋面积。而一元线性回归就是帮助我们找到最“适合”的拟合的直线。
(2)代价函数
如何确定找到的直线是最适合的?我们通过最小化代价函数来找到。
最小化函数是通过历史悠久的判断误差的方法:最小二乘法来确定的。为了便于之后的计算,我们再乘以1/2,于是得到代价函数: ,其中m是测试集的大小,h(x)是线性回归函数,y是预先确定好的标签值。
,其中m是测试集的大小,h(x)是线性回归函数,y是预先确定好的标签值。
如何来确定在什么时候取得代价函数的最优解,即最小值。可以有两种方法,两种方法使用范围不同,各自有各自的优势。
方法一:梯度下降法
优点:可以计算多个特征(通常大于10000)的目标函数的参数;
缺点:需要确定学习率,需要进行多次迭代
背景:一元线性回归的代价函数是凸的,总是可以找到最优解。
过程: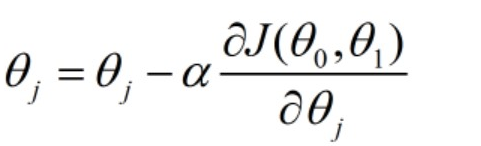 ,其中偏导数前面的常数被称为学习率,每次同步更新
,其中偏导数前面的常数被称为学习率,每次同步更新 ,同步更新的具体过程为:
,同步更新的具体过程为: ,不断迭代这个过程,直到代价函数收敛,收敛了的话都不会再改变的。
,不断迭代这个过程,直到代价函数收敛,收敛了的话都不会再改变的。
Notes:(1)分别对求偏导数,可以得到式子中的偏导项分别为: ,因为每次迭代需要遍历整个数据集,也被称之为Batch梯度下降
,因为每次迭代需要遍历整个数据集,也被称之为Batch梯度下降
(2)具体的执行过程,可以利用散点图和等高线图来理解
当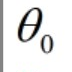 =0时,代价函数退化为二次函数,我们假设起点在1,梯度下降的方法就是从起点出发,每次向下降方向最快的地方走一步,在如图所示的过程中,迭代了10次到达最优解。当然,实际的迭代次数会比10次多很多。
=0时,代价函数退化为二次函数,我们假设起点在1,梯度下降的方法就是从起点出发,每次向下降方向最快的地方走一步,在如图所示的过程中,迭代了10次到达最优解。当然,实际的迭代次数会比10次多很多。

当 不等于0时,我们利用散点图和登高线图来演示相应的过程。

如初始拟合的直线是1,在第一次同步的更新后,等高线图中逐步开始向最优解的方向靠近,到达了代价更小的2,同样的,第三次到达了代价更小的3,不断重复这个过程,一定会到达等高线图中最小的值,即最优解。<br /> 经过多次迭代的梯度下降后,我们最终会得到使得代价函数最小的,即我们找到了最“适合”测试集的代价函数。
三. 多元线性回归
(1)具体例子
这次在预测房价时,不再只是房屋面积一个特征,还包括卧室数目,楼层,使用年限等多个特征。
共有m个样本值,n个参数。
(2)代价函数
与一元线性回归类似,不过由原先的一个特征变成了由多个特征构成的特征向量。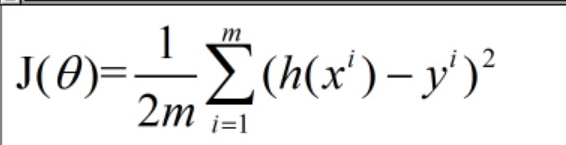
继续使用梯度下降来获得最优解。梯度下降算法和一元线性回归类似,不过在更新时,要同时更新n+1个参数。
偏导项也只是将一个特征变为多个特征即可。
四. 梯度下降中的常用技巧
(1)特征缩放
可能会存在这样的情况,两个特征值x1和x2的取值范围非常大,会导致所画出来的等高线图非常的扁平或非常的瘦长,这些都会导致收敛的速度非常慢,影响算法的执行效率。
如x1的取值范围是0~2000,x2的取值范围是1~5,会导致最后画出来的等高线图非常的瘦长。
可以做如下改变 ,其中u是x特征测试集的平均值,b是其范围,这种把原特征进行缩放的操作,就叫做特征缩放。特征缩放可以加快算法收敛的速度。但为了最后的目标方程,在求得缩放后的参数后,还要缩放回去。相应的w:=bw+u;
,其中u是x特征测试集的平均值,b是其范围,这种把原特征进行缩放的操作,就叫做特征缩放。特征缩放可以加快算法收敛的速度。但为了最后的目标方程,在求得缩放后的参数后,还要缩放回去。相应的w:=bw+u;
特征缩放后的等高线图
(2)学习率的选择
过高的学习率可能导致算法无法收敛,过低的学习率又会导致算法收敛速度太慢。按照吴恩达老师的经验,学习率可以从0.001开始,以3倍的速率递增,逐步实验达到一个较好的效果。
五. 正规方程
正规方程是利用数学方法求得的,能使代价函数最小化的参数向量。
优点:不需要迭代,在测试集较小,特征值较少时使用效果非常好
缺点:其算法复杂度为 ,在测试集规模较大,特征值较多的时候速度会非常慢,甚至于算法无法运行。
,在测试集规模较大,特征值较多的时候速度会非常慢,甚至于算法无法运行。
算法: ,其中x是特征值矩阵,对应的特征值全为1,y是标签值向量。无需考虑矩阵可逆的问题,在线性代数层面不可逆的矩阵,matlab等软件会拼凑一个伪可逆矩阵,可以完美的实现求“逆”功能。
,其中x是特征值矩阵,对应的特征值全为1,y是标签值向量。无需考虑矩阵可逆的问题,在线性代数层面不可逆的矩阵,matlab等软件会拼凑一个伪可逆矩阵,可以完美的实现求“逆”功能。
六.正则化
1 过拟合与欠拟合问题
2.过拟合
我们在利用线性回归算法时,在追求代价函数最小化的过程中最可能发生过拟合问题。主要原因是因为我们的特征值太多了,会导致学到的参数对于测试集来说泛化效果并不好。我们可以通过减少不必要的特征值来防止过拟合发生,但常常用到的是正则化方法。
3.正则化
正则化的一个例子:
图一比较好的拟合了样本点,图二虽然更好的拟合样本点,但是很明显出现了过拟合的现象,出现过拟合现象的原因是因为多余的特征x^3,x^4的加入,我们可以采取一种简单的方法来降低x^3,x^4的影响,阻止过拟合现象的产生。令: ,这样在最小化代价函数的时候,只有参数
,这样在最小化代价函数的时候,只有参数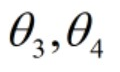 非常小的时候,才能够取得最优解,特征x^3,x^4的影响才能消失。
非常小的时候,才能够取得最优解,特征x^3,x^4的影响才能消失。
正则化的思想:减小每个参数的值,来使得拟合后的曲线更为光滑,减少多特征所带来的影响。
(1)使用正则化的线性回归梯度下降法:
在使用梯度下降进行更新的时候:
可以看到,使用正则化后,只是 的系数比之前稍微小了一点,其所对应的特征不会发挥特别大的作用。
的系数比之前稍微小了一点,其所对应的特征不会发挥特别大的作用。
(2)使用正则化的正规方程:
同样的,无需担心矩阵的可逆问题,新增加的矩阵是一个(n+1)维的矩阵

若有收获,就点个赞吧
0 人点赞
