Resources
Books
- 《机器学习实战》第五章:Logistic回归
- 周志华《机器学习》第三章:线性模型
- 李航《统计学习方法》第六章:Logistic回归模型
documents
- https://ailearning.apachecn.org/docs/ml/5.Logistic%E5%9B%9E%E5%BD%92.html
Logistic return conclusionhttps://blog.csdn.net/achuo/article/details/51160101
Basic theory
1 Maximum likelihood estimate(最大似然估计)
2 Directional derivatives and gradients(方向导数与梯度)
3Algorithm Process
collect data
- prepare data
- analyse data
- train algorithm
- test algorithm
-
Example: Classification of data set
1 Code analyse
1 Prepare data
1 Arguments analyse
arguments: null
- returns:
- dataArray: data features
- labelArray: data labels
2 Process analyse
describe: Create data array and label array by import data form file
Process:
- Initialize dataArray and labelArray
- Import file
- Cyclic read file and
3 Code implementation
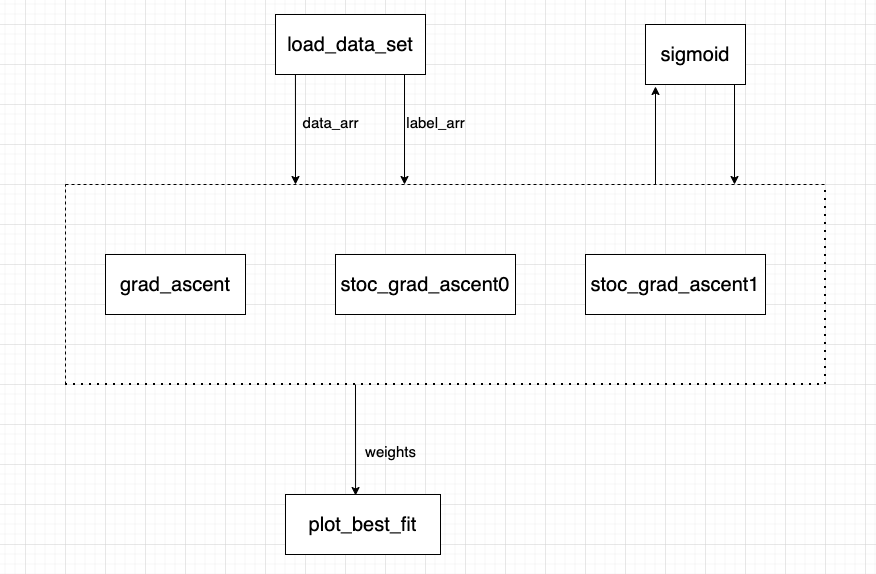
def ImpoetDataSet():dataArray = []labelArray = []f = open('data/5.Logistic/TestSet.txt', 'r')for line in f.readlines():lineArray = line.strip().split()dataArray.append([1.0, np.float(line_arr[0]), np.float(line_arr[1])])labelArray.append(int(lineArray[2]))return dataArray, labelArray
2 analyse data
1 Arguments analyse
2 Process Analyse
3 Code implementation
def plot_best_fit(weights):import matplotlib.pyplot as pltdata_mat, label_mat = load_data_set()data_arr = np.array(data_mat)n = np.shape(data_mat)[0]x_cord1 = []y_cord1 = []x_cord2 = []y_cord2 = []for i in range(n):if int(label_mat[i]) == 1:x_cord1.append(data_arr[i, 1])y_cord1.append(data_arr[i, 2])else:x_cord2.append(data_arr[i, 1])y_cord2.append(data_arr[i, 2])fig = plt.figure()ax = fig.add_subplot(111)ax.scatter(x_cord1, y_cord1, s=30, color='k', marker='^')ax.scatter(x_cord2, y_cord2, s=30, color='red', marker='s')x = np.arange(-3.0, 3.0, 0.1)y = (-weights[0] - weights[1] * x) / weights[2]"""y的由来,卧槽,是不是没看懂?首先理论上是这个样子的。dataMat.append([1.0, float(lineArr[0]), float(lineArr[1])])w0*x0+w1*x1+w2*x2=f(x)x0最开始就设置为1叻, x2就是我们画图的y值,而f(x)被我们磨合误差给算到w0,w1,w2身上去了所以: w0+w1*x+w2*y=0 => y = (-w0-w1*x)/w2"""ax.plot(x, y)plt.xlabel('x1')plt.ylabel('y1')plt.show()
3 train algorithm
1 Arguments analyse
- arguments:
- dataArray:
- dataLabels:
- return:
- weights: Regression coefficient(回归系数)
2 Process Analyse
describe: Use gradient ascent method to calculate regression coefficient
Process:
- Converts data array to a data matrix
- Converts label array to a label matrix and transpose
- Calculate data quantity and label quantity
- Initialize learning rate and max cycles
- Initialize regression coefficient
- Loop computations regression coefficient
3 Code implementation
def sigmoid(x):return 1.0 / (1 + np.exp(-x))
def GradAscent(dataArray, dataLabels):
dataMatrix = np.mat(dataArray)
labelMatrix = np.mat(dataLabels).transpose()
m, n = np.shape(dataMatrix)
alpha = 0.001
maxCycles = 500
weights = np.ones((n, 1))
for k in range(maxCycles):
h = sigmoid(data_mat * weights)
error = labelMatix - h
weights = weights + alpha * dataMatix.transpose() * error
return weights
4 Train algorithm optimize: random gradient rise
1 Arguments analyse
2 Process Analyse
3 Code implementation
def stoc_grad_ascent0(data_mat, class_labels):
"""
随机梯度上升,只使用一个样本点来更新回归系数
:param data_mat: 输入数据的数据特征(除去最后一列),ndarray
:param class_labels: 输入数据的类别标签(最后一列数据)
:return: 得到的最佳回归系数
"""
m, n = np.shape(data_mat)
alpha = 0.01
weights = np.ones(n)
for i in range(m):
# sum(data_mat[i]*weights)为了求 f(x)的值, f(x)=a1*x1+b2*x2+..+nn*xn,
# 此处求出的 h 是一个具体的数值,而不是一个矩阵
h = sigmoid(sum(data_mat[i] * weights))
error = class_labels[i] - h
# 还是和上面一样,这个先去看推导,再写程序
weights = weights + alpha * error * data_mat[i]
return weights
5 Train algorithm optimize again
1 Arguments analyse
2 Process Analyse
3 Code implementation
def stoc_grad_ascent1(data_mat, class_labels, num_iter=150):
"""
改进版的随机梯度上升,使用随机的一个样本来更新回归系数
:param data_mat: 输入数据的数据特征(除去最后一列),ndarray
:param class_labels: 输入数据的类别标签(最后一列数据
:param num_iter: 迭代次数
:return: 得到的最佳回归系数
"""
m, n = np.shape(data_mat)
weights = np.ones(n)
for j in range(num_iter):
# 这里必须要用list,不然后面的del没法使用
data_index = list(range(m))
for i in range(m):
# i和j的不断增大,导致alpha的值不断减少,但是不为0
alpha = 4 / (1.0 + j + i) + 0.01
# 随机产生一个 0~len()之间的一个值
# random.uniform(x, y) 方法将随机生成下一个实数,它在[x,y]范围内,x是这个范围内的最小值,y是这个范围内的最大值。
rand_index = int(np.random.uniform(0, len(data_index)))
h = sigmoid(np.sum(data_mat[data_index[rand_index]] * weights))
error = class_labels[data_index[rand_index]] - h
weights = weights + alpha * error * data_mat[data_index[rand_index]]
del(data_index[rand_index])
return weights
2 Process Chart

若有收获,就点个赞吧
0 人点赞
