Resources
books
- 周志华《机器学习》第七章:贝叶斯分类器
- 李航《统计学习方法》第四章:朴素贝叶斯法
- 《机器学习实战》第四章:基于概率论的方法:朴素贝叶斯
documents
https://zhuanlan.zhihu.com/p/26262151
Example: Block insulting comments
1 Code analyse
1 Prepare data
1 Argument analyse
CreateDataSet():
- describe: Create data set or import data set
- returns: data set
- CerateWordList():
- describe: Use documents words to reate a word set
- returns: word set
- BuildWordVector():
- describe: Change input words to word vector
- arguments:
- wodSet:
- inputSet:
- returns: word vector
2 Process analyse
- CreateDataSet():
- CerateWordList():
- BuildWordVector():
2 Code analyse
def CreateDataSet():postingList = [['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'],['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'],['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him'],['stop', 'posting', 'stupid', 'worthless', 'gar e'],['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'],['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']]# 1 is insulting document, 0 is not insulting documentclassVector = [0, 1, 0, 1, 0, 1]return postList, classVector
def CerateWordList(dataSet):# create empty setwordSet = set()for data in dataSet:# | calculate the nuion of two setswordSet = wordSet | set(data)return list(wordSet)
def BuildWordVector(wordSet, inputSet):result = [0] * len(wordSet)for word in inputSet:if word in wordSet:result[wordSet.index(word)] = 1return result
3 Train algorithm
1 Arguments analyse
- discribe:
- arguments:
- trainText: (Documents to be trained)
- trainCategory: (Documents catrgorys)
- returns:
- p0Vector: (Non-insulting words appear probility vector)
- p1Vector: (Insulting words appear probility vector)
- appearProb: (The appear probility of insulting files)
2 Process analyse
- Calculate doucuments quantity and words quality in a document
- Calculate the apper probability of insulting files
- Initialize words apper list and total number
- Calculate words apper list and total number(Realize by loop and condition statements)
- Calculate probability(log from)
3 Code implementation
def TrainAlgorithm(trainText, trainCategory):documentsNum = len(trainText)documentWordsNum = len(trainText[0])appearProb = np.sum(trainCategory)/documentNump0Num = np.zeros(documentWordsNum)p1Num = np.zeros(documentWordsNum)p0TotalNum = 0p1TotalNum = 0for i in documentsNum:if trainCategory(i) == 0:p0Num += trainText[i]p0TotalNum += np.sum(trainText[i])else:p1Num += trainText[I]p1TotalNum += np.sum(trainText[i])p0Vector = p0Num/p0TotalNump1Vector = p1Num/p1TotalNumreturn p0Vector, p1Vector, appearProb
4 Optimized algorithm code implementation
def TrainAlgorithm(trainText, trainCategory):documentsNum = len(trainText)documentWordsNum = len(trainText[0])appearProb = np.sum(trainCategory)/documentNump0Num = np.ones(documentWordsNum)p1Num = np.ones(documentWordsNum)p0TotalNum = 2.0p1TotalNum = 2.0for i in documentsNum:if trainCategory(i) == 0:p0Num += trainText[i]p0TotalNum += np.sum(trainText[i])else:p1Num += trainText[I]p1TotalNum += np.sum(trainText[i])p0Vector = log(p0Num/p0TotalNum)p1Vector = log(p1Num/p1TotalNum)return p0Vector, p1Vector, appearProb
4 Test algorithm
1 Arguments analyse
- discribe:
- arguments:
- classifyVector: The vector to be classify
- p0Vector: Non-insulting words appear probility vector
- p1Vector: Insulting words appear probility vector
- appearProb: The appear probility of insulting files
- returns:
2 Process analyse
- Calculate formula: log(P(F1|C))+log(P(F2|C))+….+log(P(Fn|C))+log(P(C))
- (classifyVector * p1Vector) means relative every words and its probility
3 Code implementation
def Naive_Bayes_Classify(classifyVector, p0Vector, p1Vector, appearProb):p1 = np.sum(classifyVector * p1Vector) + np.log(appearProb)p0 = np.sum(classifyVector * p1Vector) + np.log(1 - appearProb)if p1 > p0:return 1else:retuen 0
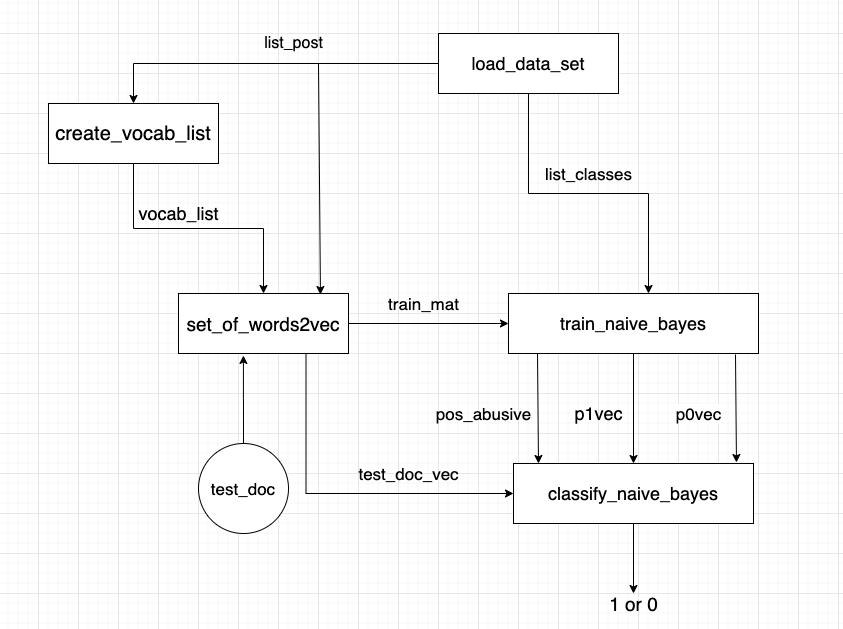
2 Process chart

若有收获,就点个赞吧
0 人点赞
