常见的索引模型
1: hash : 适合: 等值查询 缺点: 范围查询.
2: 有序数组: 优点: 区间查询 缺点: 更新成本太高 使用场景: 静态数据存储
3: 搜索树: 二叉树不适合做数据引擎结构原因: 树太高, 数据存储到磁盘, 每次都要随机读写, 太慢 因此一般都是n叉树(访问磁盘次数小)
4: 数据库底层存储的核心基于以上这些数据结构, 只有了解这些才能从原理上分析适用场景
innobe的索引模型
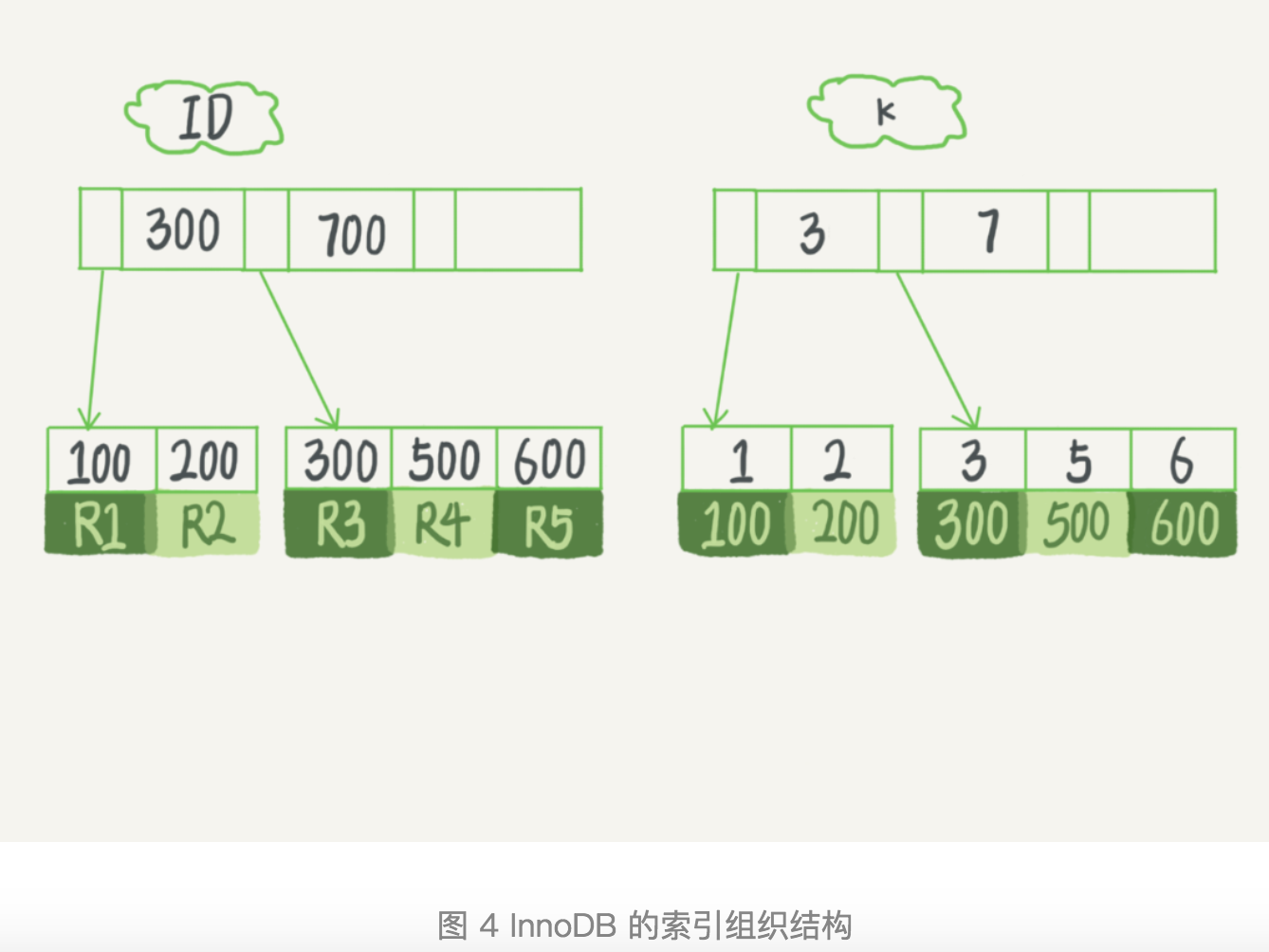
1: 使用的数据索引模型: b+树
2: 索引分类: 主键索引(叶子节点存放整行数据, 也叫聚簇索引)和非主键索引(存放主键值, 二级索引, 普通索引)
3: 索引的区别: 1: 主键索引: 搜索主键索引b+树 2: 普通索引, 先根据 普通索引找到主键, 然后根据主键索引回表
innobe索引的维护及使用场景
索引维护需要耗性能的点: 1: 插入的数字需要放在叶子节点的中间, 比如400, 就需要整体数据往后移
2: 叶分裂, 叶子节点的数据太多需要分裂.
使用注意事项: 1: 主键自增 : 数据都是追加, 不需要后移操作
2: 主键长度小: 存储普通索引树节省空间
优化回表次数
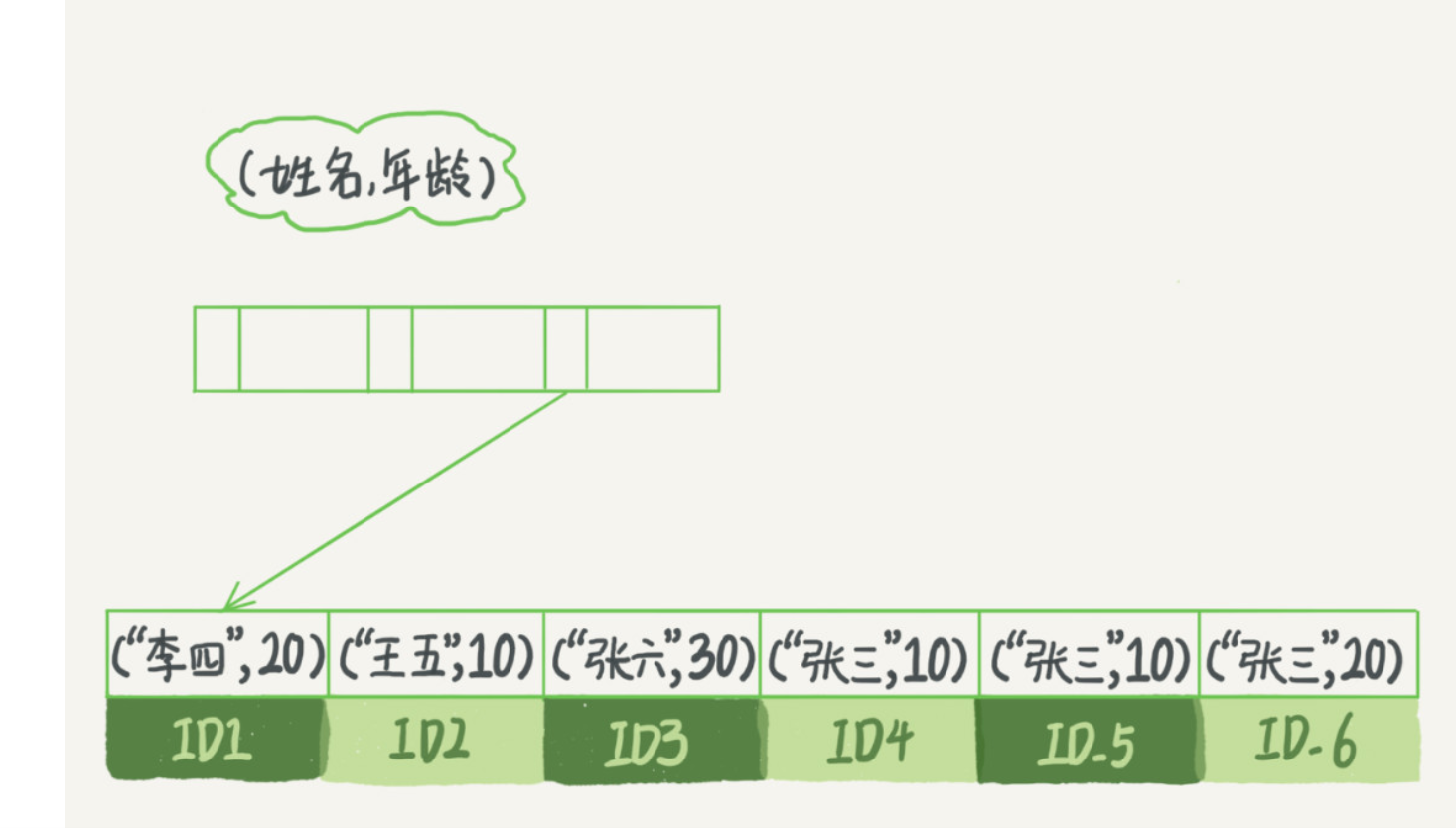
1: 覆盖索引: 查询的内容已经在索引上面了, 就不需要回表, 例如: 你要根据普通索引查询主键的值
2: 最左匹配原则: 要查找姓名中第一个字为’张‘的人, sql语句: “where name like ‘张 %’”, 通常有了(a,b)索引就不需要a索引了, 这时候你要考虑联合索引的顺序, 原则: 减少索引空间,减少索引个数
3: 索引下推: select * from tuser where name like ‘张 %’ and age=10 (建立联合索引(name, age)
不使用索引下推: 根据前缀匹配, 只要满足name like “张%”, 就回表.
使用索引下推: 可以其他索引字段做进一步的过滤,比如age=10, 从而减少回表个数
4: 设计表结构的原则: 减少资源消耗

若有收获,就点个赞吧
0 人点赞
