order by 工作原理
select city,name,age from t where city=’杭州’ order by name limit 1000 ;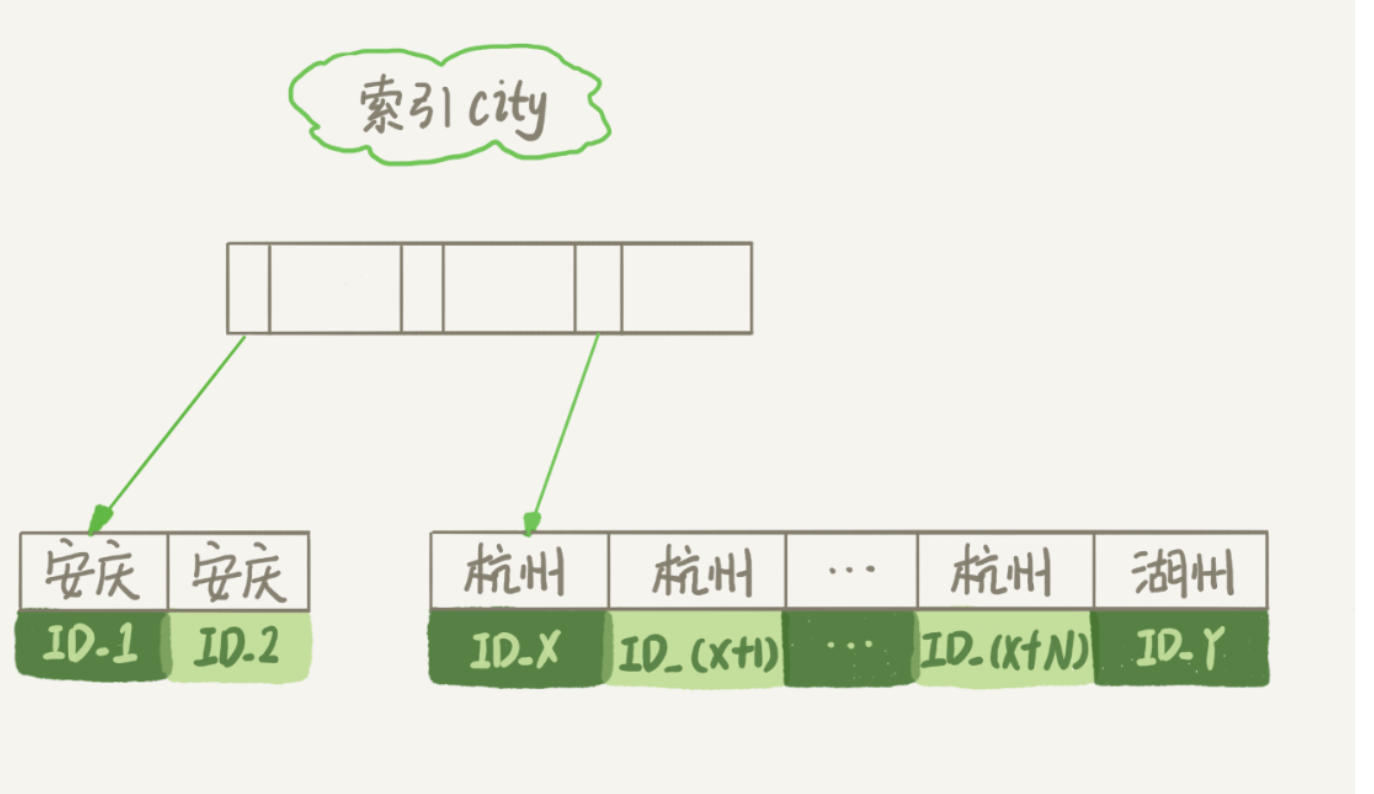
1: 为避免全表扫描, 我们都会在city加上索引
2: 全字段排序流程:
从图中可以看到,满足 city=’杭州’条件的行,是从 IDX 到 ID(X+N) 的这些记录。
通常情况下,这个语句执行流程如下所示 :
- 初始化 sort_buffer,确定放入 name、city、age 这三个字段;
- 从索引 city 找到第一个满足 city=’杭州’条件的主键 id,也就是图中的 ID_X;
- 到主键 id 索引取出整行,取 name、city、age 三个字段的值,存入 sort_buffer 中;
- 从索引 city 取下一个记录的主键 id;
- 重复步骤 3、4 直到 city 的值不满足查询条件为止,对应的主键 id 也就是图中的 ID_Y;
- 对 sort_buffer 中的数据按照字段 name 做快速排序;
- 按照排序结果取前 1000 行返回给客户端。
3: mysql排序算法: 如果内存够用, 就直接快排, 如果不够用采取外部排序算法
如果要排序的对象占用内存很大, 就算采取外部排序, 需要很多外部文件才能完成排序, 这时候需要其他算法才可以: 新算法: 放入sort_buffer的只有需要排序的字段, 等排序ok, 再回表查询其他字段, 也称之为row排序
4: row排序:
- 初始化 sort_buffer,确定放入两个字段,即 name 和 id;
- 从索引 city 找到第一个满足 city=’杭州’条件的主键 id,也就是图中的 ID_X;
- 到主键 id 索引取出整行,取 name、id 这两个字段,存入 sort_buffer 中;
- 从索引 city 取下一个记录的主键 id;
- 重复步骤 3、4 直到不满足 city=’杭州’条件为止,也就是图中的 ID_Y;
- 对 sort_buffer 中的数据按照字段 name 进行排序;
- 遍历排序结果,取前 1000 行,并按照 id 的值回到原表中取出 city、name 和 age 三个字段返回给客户端。
5: 全字段排序 VS rowid 排序
a: rowid排序多了一次回表, 第一次回表是为了根据city查name, 第二次回表是为了查其他字段
b: 对于 InnoDB 表来说,rowid 排序会要求回表多造成磁盘读,因此不会被优先选择。
c: 尽量选择全字段排序
d: mysql对于排序确实成本比较高
6: 有没有其他排序手段
建立联合索引
select city,name,age from t where city=’杭州’ order by name limit 1000 ; —》(city,name) —-> 进一步优化—->
(city,name,age)(使用覆盖索引)
7: 思考题: 多字段查询: select city,name,age from t where city in (‘杭州’,’陕西’) order by name limit 1000
虽然有 (city,name) 联合索引,但是同时查询了两个城市, 所以mysql内部是需要帮你排序的, 如果之后一个城市, 基于联合索引, 本身就是排序好的就不要再次排序了
方法1: 业务自己排序, 拆成两个语句, 然后业务自己做归并排序 缺点: 需要把满足条件的都返回给客户端, 而且都是全字段返回, 会导致占用内存大
方法2: 同样拆成两个语句, 不同的是,只select name, id; 排序结果之后根据id查询具体值
有索引但不一定触发
1: 对索引字段做函数操作, 会破坏索引值的有序性, 因此优化器放弃走树搜索功能
2: 每次你的业务代码升级时,把可能出现的、新的 SQL 语句 explain 一下,是一个很好的习惯。
3: 举例子:
a: 对索引字段函数操作: select count() from tradelog where month(t_modified)=7;
b: 隐式类型转换: select from tradelog where CAST(tradid AS signed int) = 110717; (字符串转话为数字)
c: 隐式字符编码转换: select from trade_detail where CONVERT(traideid USING utf8mb4)=$L2.tradeid.value; utf8mb4是utf8的超集
d: 隐式字符编码转换: select d. from tradelog l , trade_detail d where d.tradeid=CONVERT(l.tradeid USING utf8) and l.id=2; // 这个会使用到索引: 因为没有对索引字段操作哈

若有收获,就点个赞吧
0 人点赞
