概念上: 1: 普通索引允许key重复 2: 唯一索引不允许重复
性能上: 从更新操作上看: 1: 普通索引可以使用change buffer, 减少读磁盘i/o. 2: 唯一索引不可以使用, 因为它需要从磁盘读数据来判断是否有key冲突
从读操作上看: 因为普通索引要多多个数据, 而唯一索引只需要读一个数据, 但是mysql读数据是以页为单位的. 所以性能都差不多
业务选择: 如果业务已经可以保证不会有key冲突, 那么选择普通索引较好
chang buffer使用场景
1: 普通索引
2: 写多读少. 因为其原理是, 把写的操作缓存下来, 不直接操作磁盘, 等到下次读的时候在和磁盘中的数据做merge,
chang buffer和redo log区别
1: chang buffer主要是减少读磁盘, redo log主要是减少写磁盘
mysql优化器选择索引的标准
1: 背景: 一张表可能建立多个索引, mysql内部会选择合适的索引来执行
2: 选择标准:
a: 扫描行数
b: 是否使用临时表、是否排序
3: 如何预估扫描行数: 根据统计信息(区分度)来估算, 基数”(cardinality)越大(索引所在列不同值的个数), 区分度越好.
4: mysql什么场景下会选择索引?
a: 没有正确统计扫描行数 (方法: analyze table t 命令): 实践证明: 发现 explain 的结果预估的 rows 值跟实际情况差距比较大
b: 在扫描行数和排序两个指标上偏向于排序.
5: 比较有用的命令. a: 通过慢查询日志(slow log)来查看一下具体的执行情况(具体耗时, 实际的扫描行数等)
b: explain : 查看执行计划
6: 索引选择异常: a: force index 强行选择一个索引
b:我们可以考虑修改语句,引导 MySQL 使用我们期望的索引
c: 在有些场景下,我们可以新建一个更合适的索引,来提供给优化器做选择,或删掉误用的索引
怎么给字符串字段加索引
1: 前缀索引:
优点: 节省空间
缺点: a: 增加扫描行数: 需要回表比对查询是值是否符合条件 ——- 可以通过选择合适的前缀索引长度来避免
b: 覆盖索引用不上——-》 需要考虑业务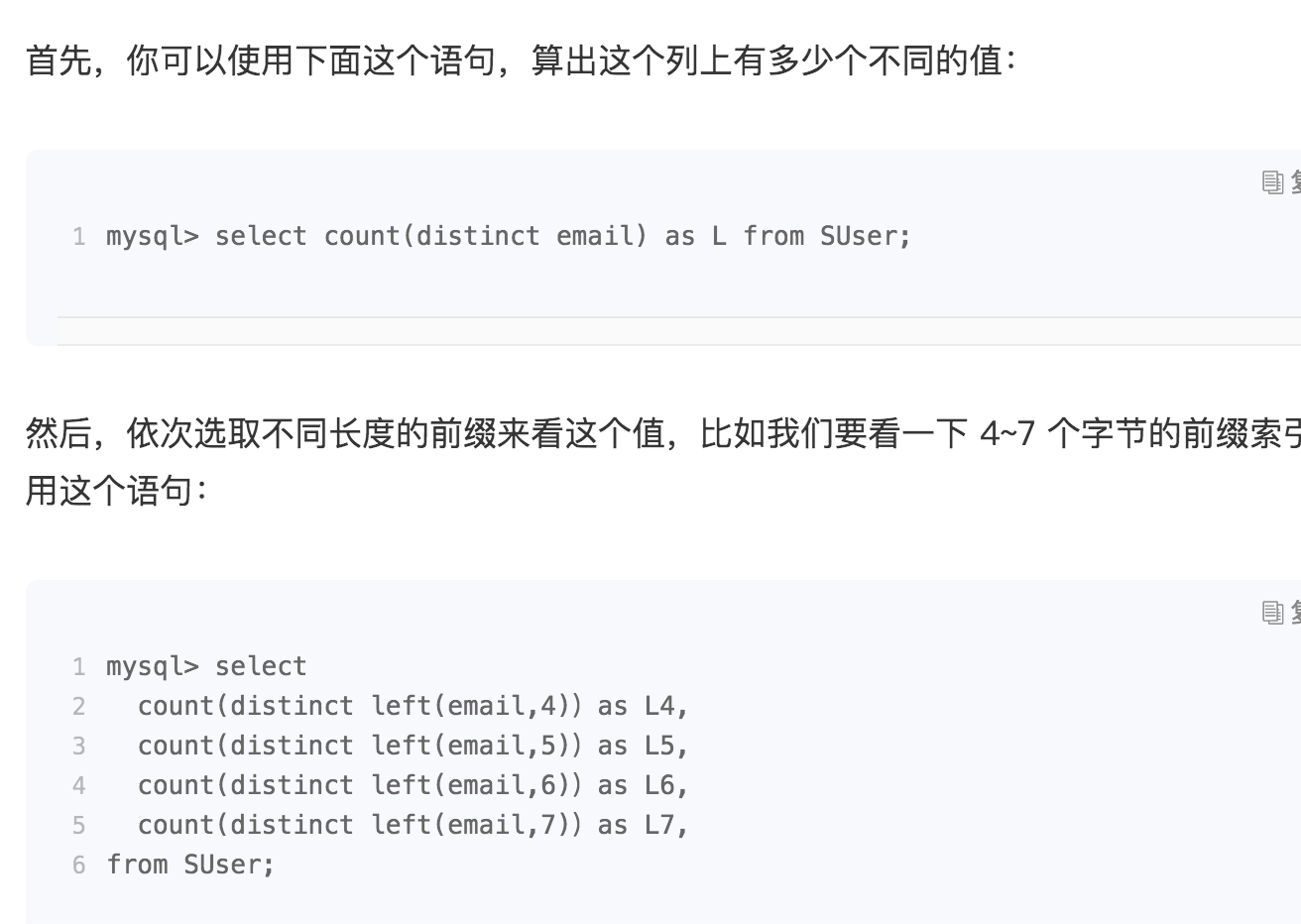
2: 选择合适的前缀长度: 主要看区分度
3: 区分度不够好怎么办?
a: 倒叙存储: reverse
b: 使用hash字段: 在表上再创建一个整数字段,来保存身份证的校验码,同时在这个字段上创建索引、
从查询效率上来看, b会好一点, 因为a本质上还是前缀索引,可能会扫描多行记录.而且不会用上覆盖索引的特性
两种方式都不支持范围查询

若有收获,就点个赞吧
0 人点赞
