快照在mvcc的工作原理
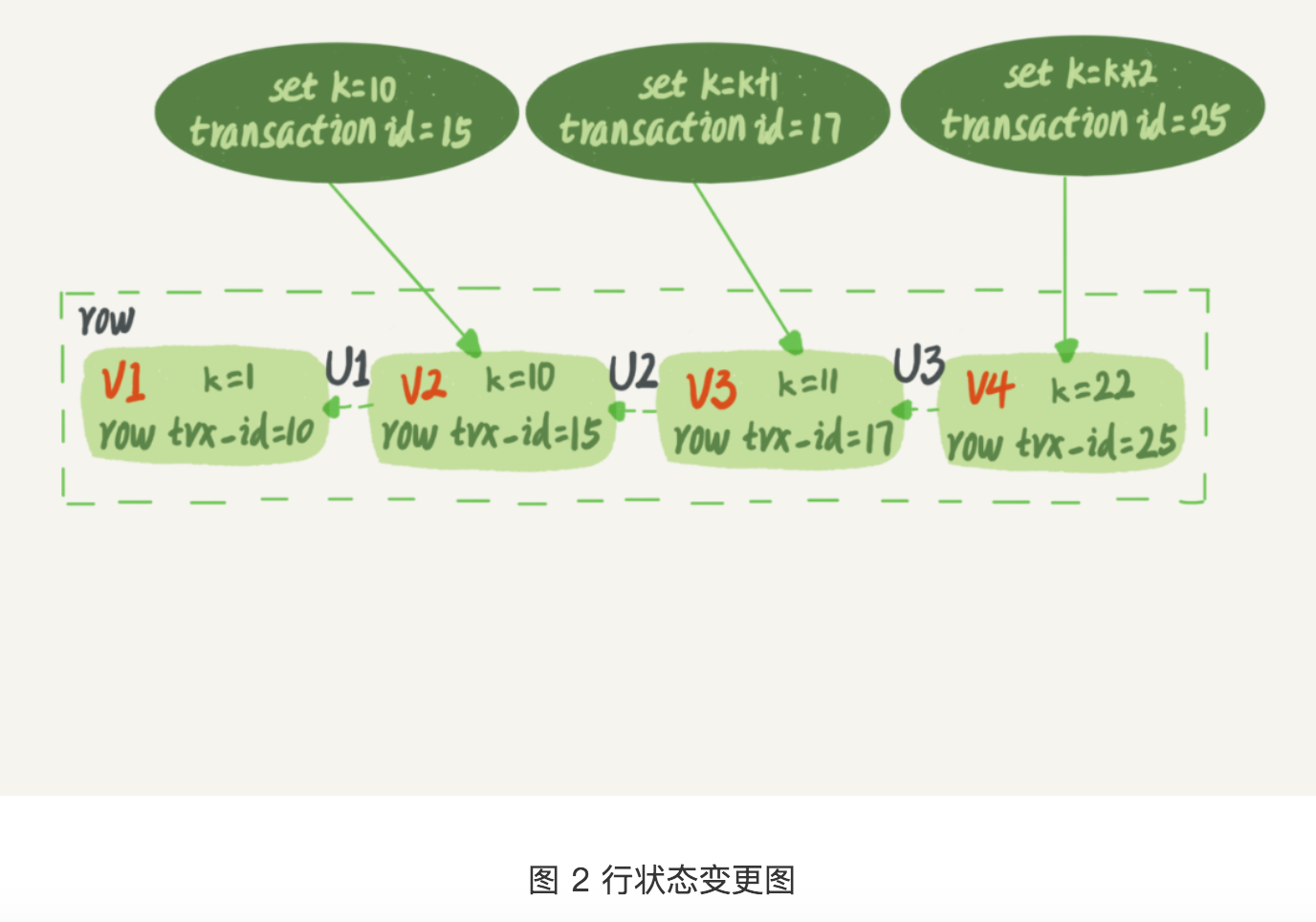
问题驱动: 可重复读隔离级别下, 假如一个库有100g的数据, 那么我启动一个事务, mysql就拷贝100g的数据, 岂不是很慢??
undo log: 回滚日志, 以上3个虚线箭头就是
可重复读的定义: 以我启动的时刻为准, 之前已经提交的事务对我都是可见的, 但是启动之后都不可见, 并伴随事务结束
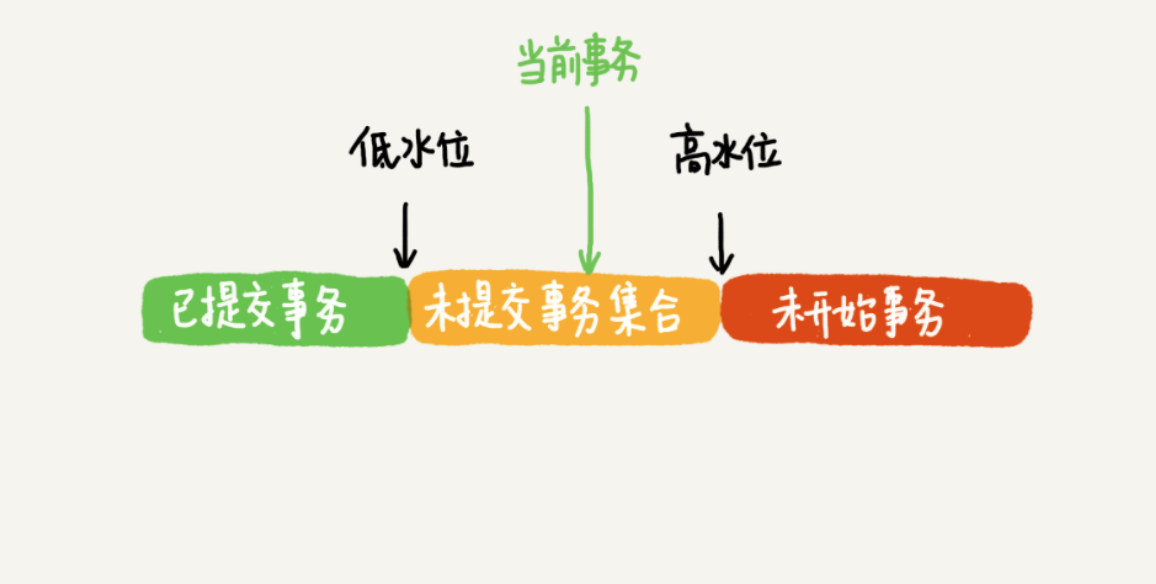
实现: innobe为每个事务都维护一个数据, 保存这当前活跃的事务id(已经生成, 但是没有提交), 数组最小值为低水位, 当前系统最大事务id为高水位
数据库版本的可见性规则:
- 如果落在绿色部分,表示这个版本是已提交的事务或者是当前事务自己生成的,这个数据是可见的;
- 如果落在红色部分,表示这个版本是由将来启动的事务生成的,是肯定不可见的;
- 如果落在黄色部分,那就包括两种情况
1. 若 row trx_id 在数组中,表示这个版本是由还没提交的事务生成的,不可见;
2. 若 row trx_id 不在数组中,表示这个版本是已经提交了的事务生成的,可见。
可见性规则翻译(便于肉眼判断)
- 版本未提交,不可见;
- 版本已提交,但是是在视图创建后提交的,不可见;
- 版本已提交,而且是在视图创建前提交的,可见。
可重复读隔离级别下的更新操作
1: 更新数据都是先读后写的,而这个读,只能读当前的值,称为“当前读”(current read) , 如果你还是按照可重复读级别的历史版本去读的话, 相当于丢失了数据. 所以在更新的时候应该无视历史版本, 从最新数据读
2: select * from t where id=1 修改一下,加上 lock in share mode 或 for update(当前读)
3: 可重复读的核心就是一致性读(consistent read);而事务更新数据的时候,只能用当前读。如果当前的记录的行锁被其他事务占用的话,就需要进入锁等待。
重要术语
事务id: 新事务启动时候会向系统申请一个trans_id, 按照顺序严格递增
多版本: 每行数据都是有多个版本的, 每个版本都有自己的row_trx_id
当前读: 读最新的数据, 无视历史版本

若有收获,就点个赞吧
0 人点赞
