
Redis集群
主从
用一个redis实例作为主机,其余的实例作为从机。主机和从机的数据完全一致,主机支持数据的写入和读取等各项操作,而从机则只支持与主机数据的同步和读取。因而可以将写入数据的命令发送给主机执行,而读取数据的命令发送给不同的从机执行,从而达到读写分离的目的。
问题是主从模式如果所连接的redis实例因为故障下线了,没有提供一定的手段通知客户端另外可连接的客户端地址,因而需要手动更改客户端配置重新连接。如果主节点由于故障下线了,那么从节点因为没有主节点而同步中断,因而需要人工进行故障转移工作。为了解决这两个问题,在2.8版本之后redis正式提供了sentinel(哨兵)架构。
单实例一主两从+读写分离结构: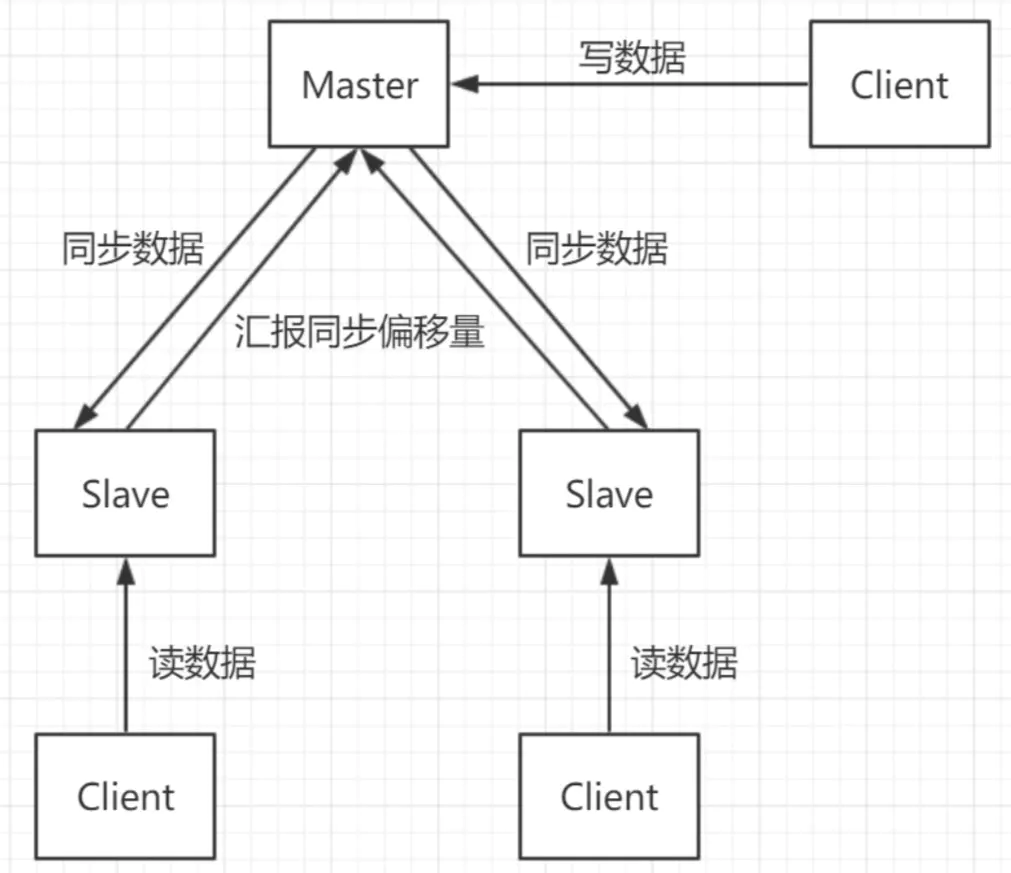
单实例的由于本质上只有一台Master作为存储,就算机器为128GB的内存,一般建议使用率也不要超过70%-80%,所以最多使用100GB数据就已经很多了,实际中50%就不错了,以为数据量太大也会降低服务的稳定性,因为数据量太大意味着持久化成本高,可能严重阻塞服务,甚至最终切主。
如果单实例只作为缓存使用,那么除了在服务故障或者阻塞时会出现缓存击穿问题,可能会有很多请求一起搞死MySQL。
如果单实例作为主存,那么问题就比较大了,因为涉及到持久化问题,无论是bgsave还是aof都会造成刷盘阻塞,此时造成服务请求成功率下降,这个并不是单实例可以解决的,因为由于作为主存储,持久化是必须的。
所以我们期待一个多主多从的Redis系统,这样无论作为主存还是作为缓存,压力和稳定性都会提升,尽管如此,笔者还是建议:Redis尽量不要做主存储!
哨兵

由Sentinel节点定期监控发现主节点是否出现了故障,当主节点出现故障时,由Redis Sentinel自动完成故障发现和转移,并通知应用方,实现高可用性。
集群架构
要支持集群首先要克服的就是分片问题,也就是一致性哈希问题,常见的方案有三种:
客户端分片:(N主N从模式)这种情况主要是类似于哈希取模的做法,当客户端对服务端的数量完全掌握和控制时,可以简单使用。
中间层分片:这种情况是在客户端和服务器端之间增加中间层,充当管理者和调度者,客户端的请求打向中间层,由中间层实现请求的转发和回收,当然中间层最重要的作用是对多台服务器的动态管理。
服务端分片:(N主N从模式)不使用中间层实现去中心化的管理模式,客户端直接向服务器中任意结点请求,如果被请求的Node没有所需数据,则向客户端回复MOVED,并告诉客户端所需数据的存储位置,这个过程实际上是客户端和服务端共同配合,进行请求重定向来完成的。
客户端分片版集群
需要解决一致性哈希的问题,也就是动态扩缩容时的数据问题。(一致性hash算法)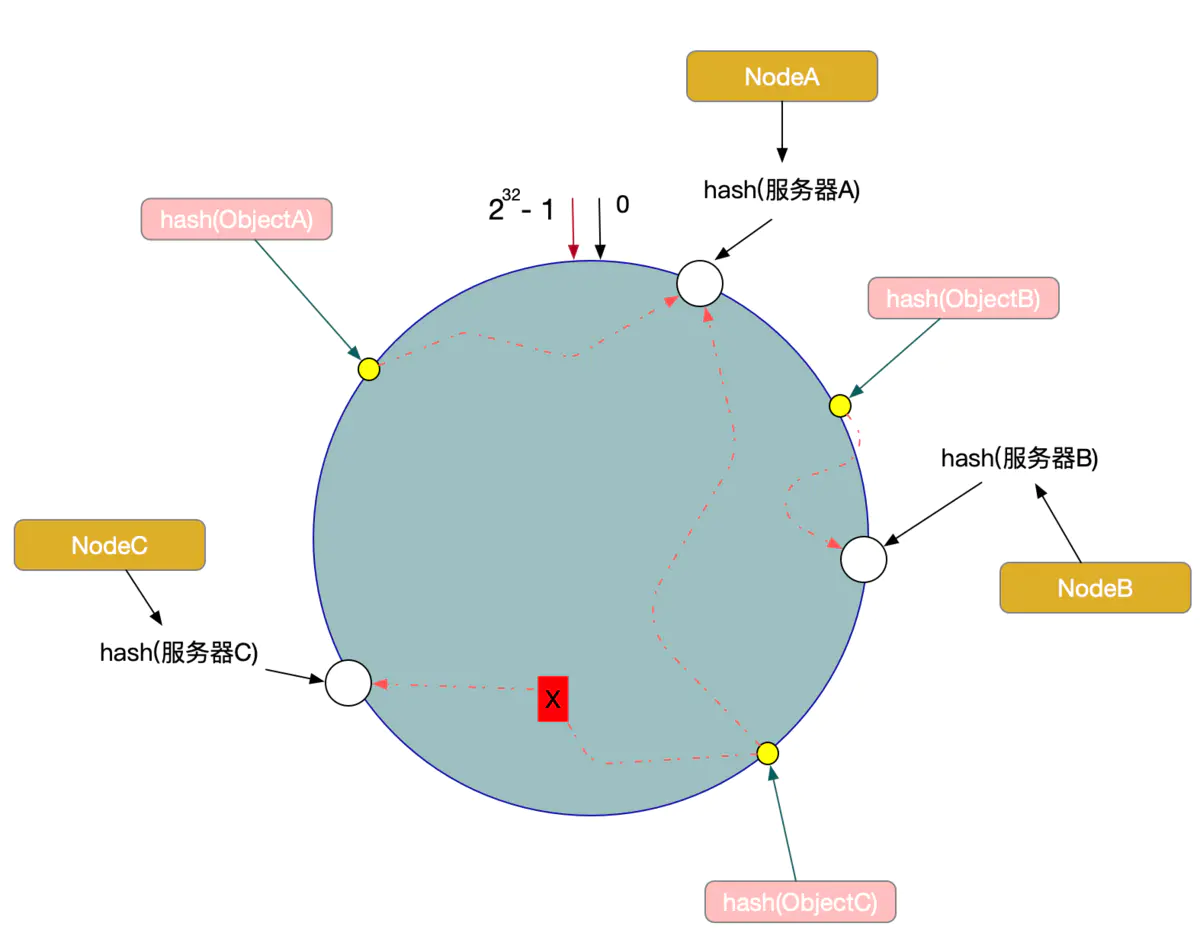
中间层分片的集群版Redis
在Redis官方发布集群版本之前,业内有一些方案迫不及待要用起自研版本的Redis集群,其中包括国内豌豆荚的Codis、国外Twiter的twemproxy。
核心思想都是在多个Redis服务器和客户端Client中间增加分片层,由分片层来完成数据的一致性哈希和分片问题,每一家的做法有一定的区别,但是要解决的核心问题都是多台Redis场景下的扩缩容、故障转移、数据完整性、数据一致性、请求处理延时等问题。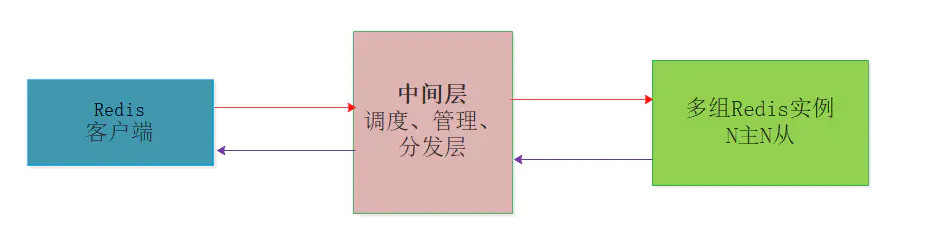
业内Codis配合LVS等多种做法实现Redis集群的方案有很多都应用到生成环境中,表现都还不错,主要是官方集群版本在Redis3.0才出现,对其稳定性如何,很多公司都不愿做小白鼠,不过事实上经过迭代目前已经到了Redis5.x版本,官方集群版本还是很不错的,至少笔者这么认为。
服务端分片的官方集群版本
官方版本区别于上面的Codis和Twemproxy,实现了服务器层的Sharding分片技术,换句话说官方没有中间层,而是多个服务结点本身实现了分片,当然也可以认为实现sharding的这部分功能被融合到了Redis服务本身中,并没有单独的Sharding模块。
官方集群引入slot的概念进行数据分片,之后将数据slot分配到多个Master结点,Master结点再配置N个从结点,从而组成了多实例sharding版本的官方集群架构。
Redis Cluster 是一个可以在多个 Redis 节点之间进行数据共享的分布式集群,在服务端,通过节点之间的特殊协议进行通讯,这个特殊协议就充当了中间层的管理部分的通信协议,这个协议称作Gossip流言协议。
分布式系统一致性协议的目的就是为了解决集群中多结点状态通知的问题,是管理集群的基础,如图展示了基于Gossip协议的官方集群架构图: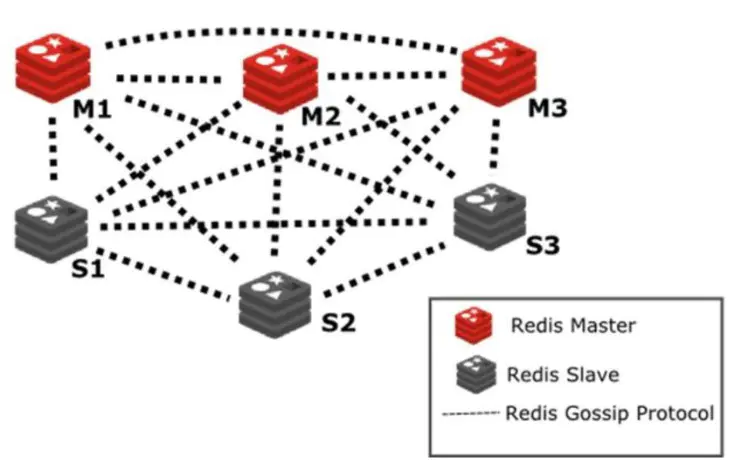
如何选择
- 集群的优势在于高可用,将写操作分开到不同的节点,如果写的操作较多且数据量巨大,且不需要高级功能则可能考虑集群
- 哨兵的优势在于高可用,支持高级功能,且能在读的操作较多的场景下工作,所以在绝大多数场景中是适合的
- 主从的优势在于支持高级功能,且能在读的操作较多的场景下工作,但无法保证高可用,不建议在数据要求严格的场景下使用
同步机制
理解持久化和数据同步的关系,需要从单点故障和高可用两个角度来分析:1 单点宕机故障
假如我们现在只有一台作为缓存的Redis机器,通过持久化将热点数据写到磁盘,某时刻该Redis单点机器发生故障宕机,此期间缓存失效,主存储服务将承受所有的请求压力倍增,监控程序将宕机Redis机器拉起。
重启之后,该机器可以Load磁盘RDB数据进行快速恢复,恢复的时间取决于数据量的多少,一般秒级到分钟级不等,恢复完成保证之前的热点数据还在,这样存储系统的CacheMiss就会降低,有效降低了缓存击穿的影响。
在单点Redis中持久化机制非常有用,只写文字容易让大家睡着,我画了张图: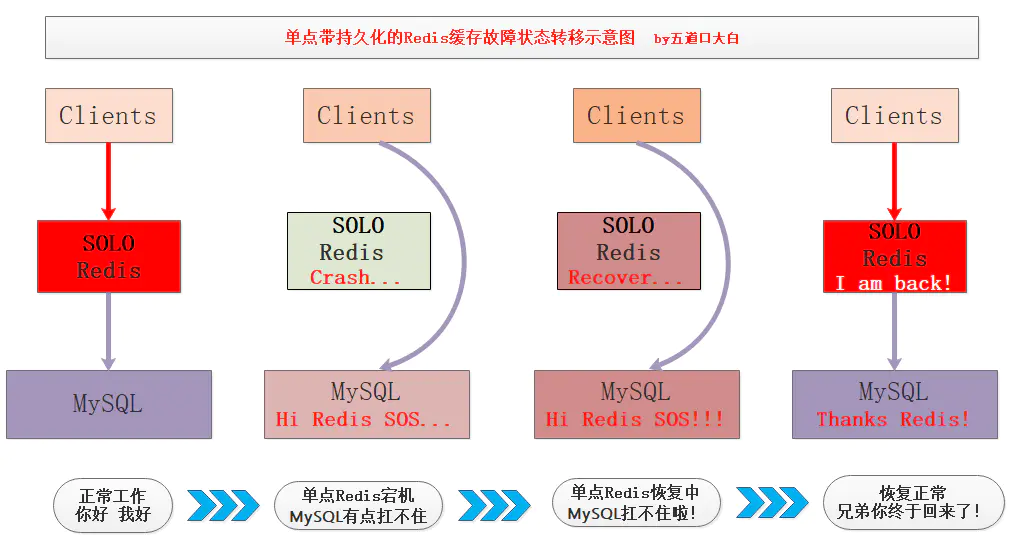
作为一个高可用的缓存系统单点宕机是不允许的,因此就出现了主从架构,对主节点的数据进行多个备份,如果主节点挂点,可以立刻切换状态最好的从节点为主节点,对外提供写服务,并且其他从节点向新主节点同步数据,确保整个Redis缓存系统的高可用。
如图展示了一个一主两从读写分离的Redis系统主节点故障迁移的过程,整个过程并没有停止正常工作,大大提高了系统的高可用: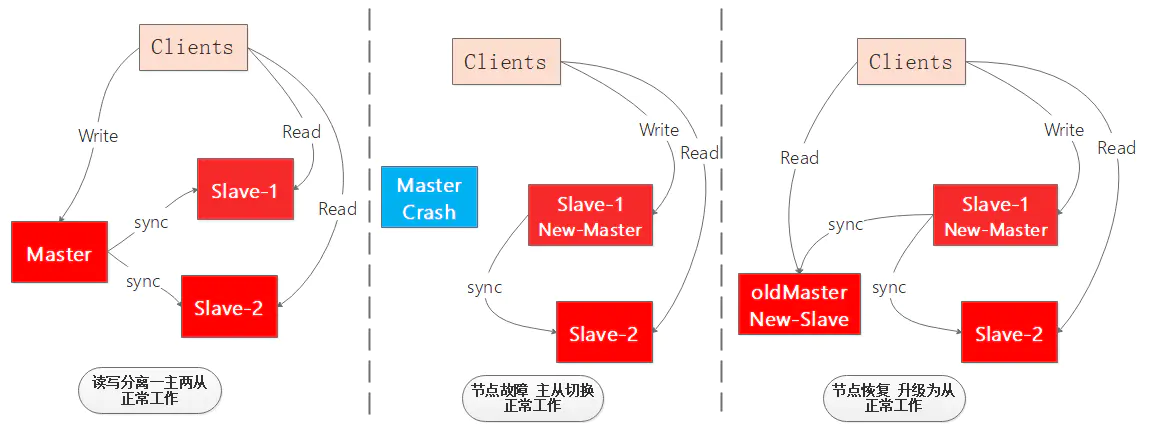
从上面的两点分析可以得出个小结论【划重点】:
持久化让单点故障不再可怕,数据同步为高可用插上翅膀。
我们理解了数据同步对Redis的重要作用,接下来继续看数据同步的实现原理和过程、重难点等细节问题吧!

若有收获,就点个赞吧
0 人点赞
