1.数据库解决方案
1.1 悲观锁方案
select id,... from XX where id =#{id} for update
加上for update 就会锁定查询出来的数据,在事务的执行过程中其他的事务将不能再对其进行读写。
缺点:因为悲观锁(又称独占锁或排他锁)中的资源只能被一个事务锁持有,这样会造成过多的等待还事务上下文的切换导致缓慢。
1.2 乐观锁方案
使用CAS+可重入方案
1.表中加入version字段
create table t_product
(
id int(12) not null auto_increment comment '编号',
version int(10) not null default 0 commnet '版本号',
...
);
注意:
- 不使用版本号的话,会导致一些库存卖不掉(ABA问题,即库存被其中一个线程修改然后又修改回去(回滚),但其他线程发现不了,即A->B->A)
2.更新库存
<update id ="decreaseProduct">
update t_product set stock = stock -#{quantity},
version = version +1
where id = #{id} and version = #{version}
</update>
mybaits的mapper
public int decreaseProduct(@Param("id") Long id,@Param("quantity") int quantity,@Param("version") int version);
service中的实现
使用可重入机制,原因:使用版本号解决了ABA问题,但由于加了版本号的判断,会有大量的请求得到失败的结果,而且在高并发的情况下失败率有点高。
可重入有两种方案:
1.时间戳机制
将一个请求设置100ms的生存期,如果在100ms内发送版本冲突则重新尝试,否则请求失败
/**
*
* @param userId
* @param productId
* @param quantity
* @return
*/
@Transactional(isolation = Isolation.READ_COMMITTED,rollbackFor = Exception.class)
public boolean purchase(Long userId,Long productId,int quantity){
//当前时间
long start = System.currentTimeMillis();
// 如果循环时间大于100ms 返回终止循环
while(true){
// 循环时间
long end = System.currentTimeMillis();
//如果循环时间大于100ms返回终止循环
if(end - start >100){
return false;
}
// 获取产品
ProductP0 product = productDao.getProduct(productId);
if(product.getStock() < quantity){
return false;
}
// 获取当前版本号
int version = product.getVersion();
int result = productDao.decreaseProduct(productId,quantity,version);
//如果更新数据失败,说明数据在多线程中被其他线程修改导致失败,则通过循环重入尝试购买商品
if (result == 0){
continue;
}
// 初始化购买记录
PurchaseRecordPo pr = this.initPurchaseRecord(userId,product,quantity);
//插入购买记录
purchaseRecordDao.insertPurchaseRecord(pr);
return true;
}
}
2.限制次数
/**
*
* @param userId
* @param productId
* @param quantity
* @return
*/
@Transactional(isolation = Isolation.READ_COMMITTED,rollbackFor = Exception.class)
public boolean purchase(Long userId,Long productId,int quantity) {
//限定循环3次
for (int i=0;i<3;i++){
// 获取产品
ProductP0 product = productDao.getProduct(productId);
if(product.getStock() < quantity){
return false;
}
// 获取当前版本号
int version = product.getVersion();
int result = productDao.decreaseProduct(productId, quantity, version);
//如果更新数据失败,说明数据在多线程中被其他线程修改导致失败,则通过循环重入尝试购买商品
if (result == 0) {
continue;
}
// 初始化购买记录
PurchaseRecordPo pr = this.initPurchaseRecord(userId, product, quantity);
//插入购买记录
purchaseRecordDao.insertPurchaseRecord(pr);
return true;
}
return false;
}
1.3总结
乐观锁是一种不使用数据库锁的机制,并且不会造成线程的阻塞,只是采用多版本号机制来实现。但是,因为版本的冲突造成了请求失败的概率剧增,所以这时往往需要通过重入的机制将请求失败的概率降低。但是,多次的重入会带来过多执行SQL的问题。为了克服这个问题,可以考虑使用按时间戳或则限制重入次数的办法。可见乐观锁还是一个相对比较复杂的机制。目前,有些企业已经开始使用NoSQL来处理这方面的问题,其中当属Redis解决方案。
2. ZooKeeper
ZooKeeper也是我们常见的实现分布式锁方法,相比于数据库如果没了解过ZooKeeper可能上手比较难一些。ZooKeeper是以Paxos算法为基础分布式应用程序协调服务。Zk的数据节点和文件目录类似,所以我们可以用此特性实现分布式锁。我们以某个资源为目录,然后这个目录下面的节点就是我们需要获取锁的客户端,未获取到锁的客户端注册需要注册Watcher到上一个客户端,可以用下图表示。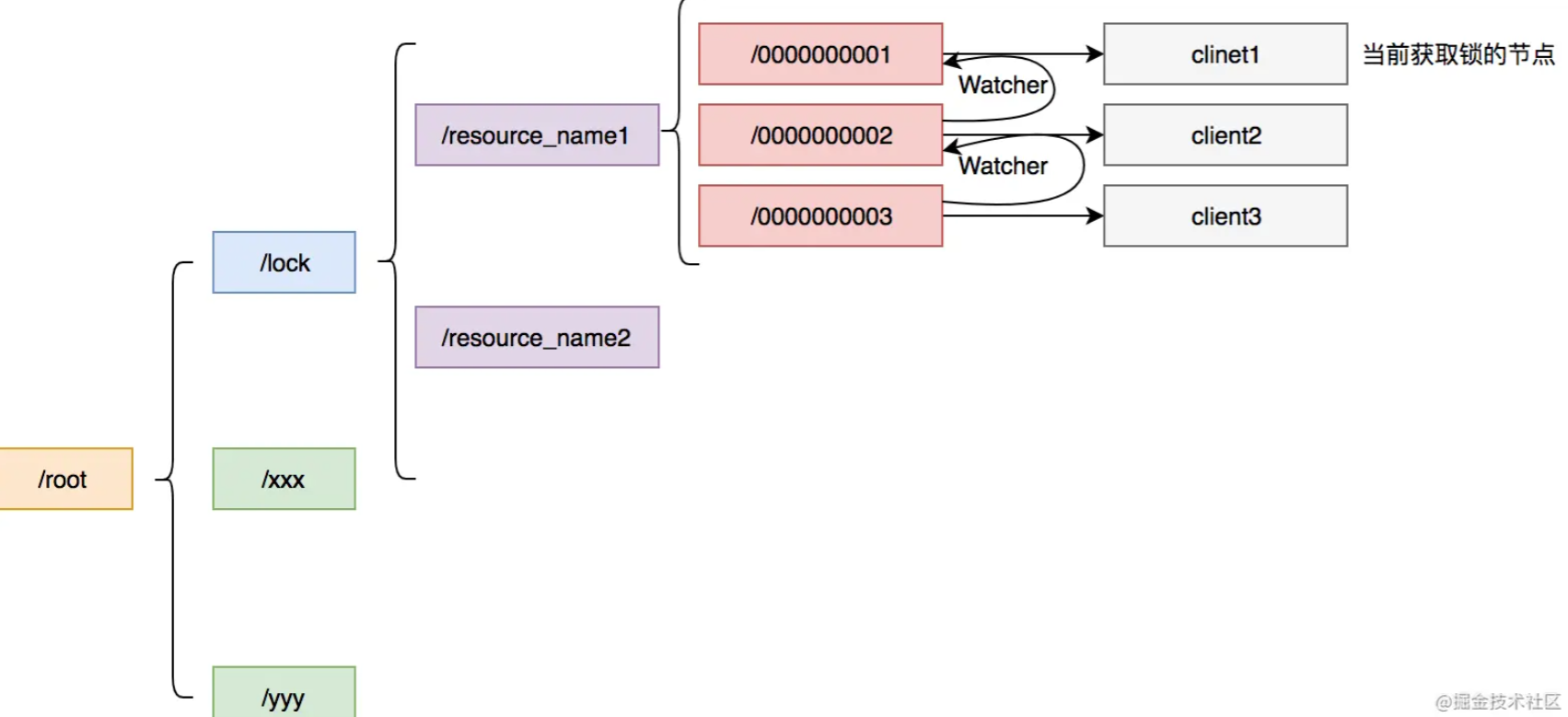
/lock是我们用于加锁的目录,/resource_name是我们锁定的资源,其下面的节点按照我们加锁的顺序排列。
2.1Curator
Curator封装了Zookeeper底层的Api,使我们更加容易方便的对Zookeeper进行操作,并且它封装了分布式锁的功能,这样我们就不需要再自己实现了。
Curator实现了可重入锁(InterProcessMutex),也实现了不可重入锁(InterProcessSemaphoreMutex)。在可重入锁中还实现了读写锁。
2.2InterProcessMutex
InterProcessMutex是Curator实现的可重入锁,我们可以通过下面的一段代码实现我们的可重入锁: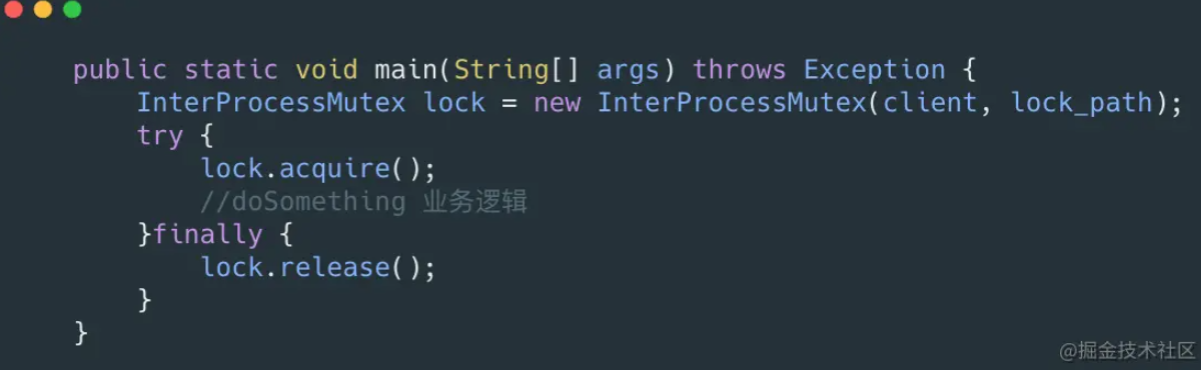
我们利用acuire进行加锁,release进行解锁。
加锁的流程具体如下:
- 首先进行可重入的判定:这里的可重入锁记录在ConcurrentMap
- 然后在我们的资源目录下创建一个节点:比如这里创建一个/0000000002这个节点,这个节点需要设置为EPHEMERAL_SEQUENTIAL也就是临时节点并且有序。
- 获取当前目录下所有子节点,判断自己的节点是否位于子节点第一个。
- 如果是第一个,则获取到锁,那么可以返回。
- 如果不是第一个,则证明前面已经有人获取到锁了,那么需要获取自己节点的前一个节点。/0000000002的前一个节点是/0000000001,我们获取到这个节点之后,再上面注册Watcher(这里的watcher其实调用的是object.notifyAll(),用来解除阻塞)。
- object.wait(timeout)或object.wait():进行阻塞等待这里和我们第5步的watcher相对应。
解锁的具体流程:
- 首先进行可重入锁的判定:如果有可重入锁只需要次数减1即可,减1之后加锁次数为0的话继续下面步骤,不为0直接返回。
- 删除当前节点。
- 删除threadDataMap里面的可重入锁的数据。
2.3读写锁
Curator提供了读写锁,其实现类是InterProcessReadWriteLock,这里的每个节点都会加上前缀:
根据不同的前缀区分是读锁还是写锁,对于读锁,如果发现前面有写锁,那么需要将watcher注册到和自己最近的写锁。写锁的逻辑和我们之前4.2分析的依然保持不变。private static final String READ_LOCK_NAME = "__READ__"; private static final String WRITE_LOCK_NAME = "__WRIT__";2.4锁超时
Zookeeper不需要配置锁超时,由于我们设置节点是临时节点,我们的每个机器维护着一个ZK的session,通过这个session,ZK可以判断机器是否宕机。如果我们的机器挂掉的话,那么这个临时节点对应的就会被删除,所以我们不需要关心锁超时。2.5 ZK小结
- 优点:ZK可以不需要关心锁超时时间,实现起来有现成的第三方包,比较方便,并且支持读写锁,ZK获取锁会按照加锁的顺序,所以其是公平锁。对于高可用利用ZK集群进行保证。
- 缺点:ZK需要额外维护,增加维护成本,性能和Mysql相差不大,依然比较差。并且需要开发人员了解ZK是什么。
3.Redis解决方案
1.使用Redis执行Lua脚本的方式实现下单操作的原子性,下单函数的事务传播属性设置为Propagation.REQUIRES_NEW,意味着将当前事务挂起,开启新的事务,这样回滚时只会回滚这个方法内部的事务,不会影响全局事务。
@Transactional(propagation = Propagation.REQUIRES_NEW)
public boolean dealRedisPurchase(List<PurchaseRecordPo> prpList){
for (PurchaseRecordPo prp : prpList){
purchaseRecordDao.insertPurchaseRecord(prp);
productDao.dreasePurchaserRecord(prp.getProductId(),prp.getQuantity());
}
return true;
}
锁续命: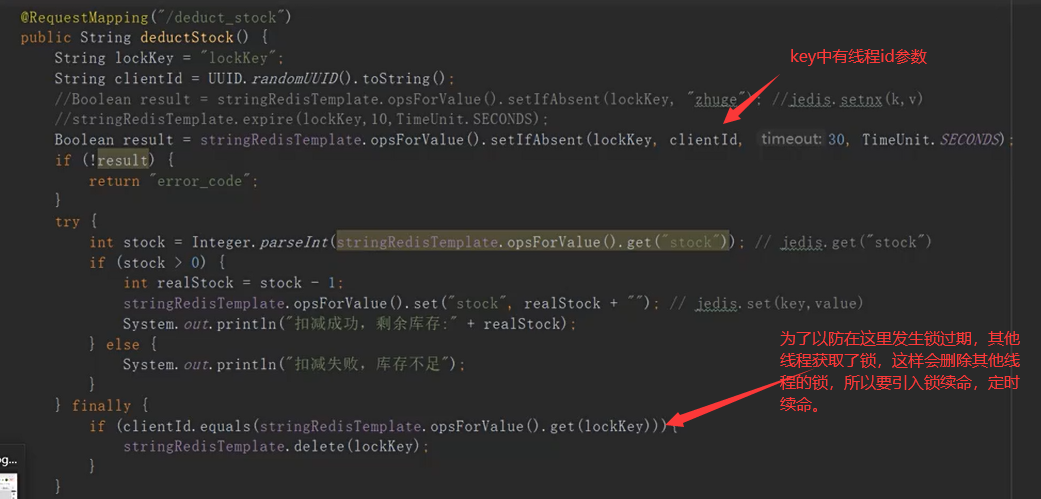
注:把第二个箭头处的判断和删除做成原子操作就不需要锁续命了。
2.添加定时任务,将redis中的数据更新到数据库
总结:从性能来讲,redis方案明显更快,但redis的存储是基于内存的,如果操作不当容易引发数据的丢失,所以使用Redis时建议使用独立的Redis服务器,而且做好备份、容灾等手段也是十分必要的。

若有收获,就点个赞吧
0 人点赞
