- 基础
- 流程
- 排序
- 事务
- 调优
- month_id为静态分区,day_id为动态分区:
insert overwrite table dynamic_test partition(month_id=’201710’,day_id)
select c1,c2,c3,c4,c5,c6,c7,day_id from kafka_offset
where substr(day_id,1,6)=’201710’; - month_id和 day_id均为动态分区:
insert overwrite table dynamic_test partition(month_id,day_id)
select c1,c2,c3,c4,c5,c6,c7,substr(day_id,1,6) as month_id,day_id from kafka_offset; - ???Map、Reduce数量调整
- 临时表
- 数据类型
- 是否有为null的数据
- 利用hive的优化机制减少job数:
- 小表放前大表放后
- 查询了两次a insert overwrite table tmp1 select … from a where 条件1; insert overwrite table tmp2 select … from a where 条件2; #查询了一次a from a insert overwrite table tmp1 select … where 条件1 insert overwrite table tmp2 select … where 条件2
- 更新
- 报错
Materialized View hive
SecondaryNameNode
我们需要一个易于管理的机制来帮助我们减小edit logs文件的大小和得到一个最新的fsimage文件,这样也会减小在NameNode上的压力。这跟Windows的恢复点是非常像的

Hive自定义函数包括三种UDF、UDAF、UDTF
UDF(User-Defined-Function) 一进一出
UDAF(User- Defined Aggregation Funcation) 聚集函数,多进一出。Count/max/min
UDTF(User-Defined Table-Generating Functions) 一进多出,如lateral view explore()
使用方式 :在HIVE会话中add 自定义函数的jar文件,然后创建function继而使用函数
???
https://blog.csdn.net/u013411339/category_8829708.html
大全
https://www.yuque.com/wangzhiwuimportbigdata/ihf2lk/iohbnf
大全2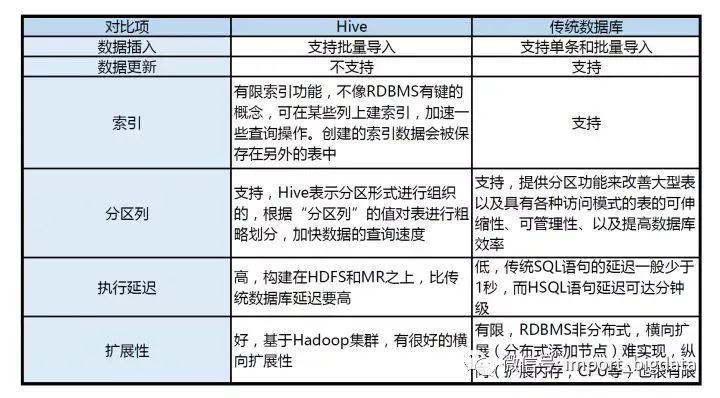
https://blog.csdn.net/houfengfei668/article/details/79619215
(2)拉链表每次上报的都是历史记录的最终状态,是记录在当前时刻的历史总量;
增量表只有上报时间,开始时间更改为上报时间
全量表:注意事项(1)全量表,有无变化,都要报**
https://mp.weixin.qq.com/s?__biz=MzI2MDQzOTk3MQ==&mid=2247484970&idx=1&sn=42720a1be22085031bfa08714dc2f245&chksm=ea68ece6dd1f65f0e1d23fd287abce8805b38126ef0e69b5595fa3c73719aaf7c402e30a06c7&scene=21
我们可以发现数据仓库大多数时候是比较适合使用星型模型构建底层数据Hive表,
而雪花模型在关系型数据库中如MySQL,Oracle中非常常见
定分区名之后就不再全表扫描,直接从指定分区(如name=jack的分区)中查询,从hdfs的角度看就是从相应的文件系统中(如name=jack文件夹下)去查找特定的数据。如下图所示:
向分区中插入数据: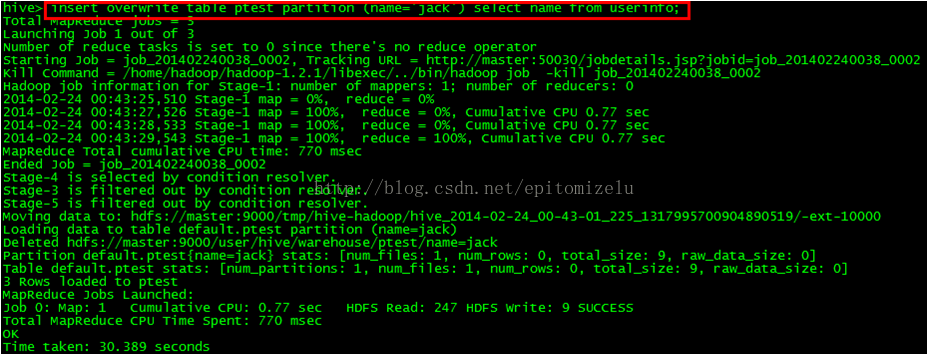
Slowly Changing Dimension 简称 SCD 是数据仓库建模和处理过程中一个很重要的概念,
类型1 (Type 1): 覆盖旧记录
类型2 (Type 2): 增加新记录
类型3 (Type 3): 增加新字段
第一种方法,直接在原来维度的基础上进行更新,不会产生新的记录:
1) 更新前:
emp_rid(代理键) emp_id(自然键) emp_name position
101212 12345 Jack Developer
更新后:
emp_rid(代理键) emp_id(自然键) emp_name position
101212 12345 Jack Manager
第二种方法,不修改原有的数据,重新产生一条新的记录,这样就可以追溯所有的历史记录:
1) 更新前:
emp_rid(代理键) emp_id(自然键) emp_name position start_date end_date
101212 12345 Jack Developer 2010-2-5 2012-6-12
更新后:
emp_rid(代理键) emp_id(自然键) emp_name position start_date end_date
201245 12345 Jack Manager 2012-6-12
第三种方法,直接在原来维度的基础上进行更新,不会产生新的记录但是只会记录上一次的历史记录:
1) 更新前:
emp_rid(代理键) emp_id(自然键) emp_name position old_position
101212 12345 Jack Developer null
更新后:
emp_rid(代理键) emp_id(自然键) emp_name position old_position
101212 12345 Jack Manager Developer
etl 4个阶段
交付阶段的主要任务是:
加载星型的和经过雪花处理的维度表数据。产生日期维度。加载退化维度。加载子维度。加载1、2、3型的缓慢变化维度。处理迟到的维度和迟到的事实。加载多值维度。加载有复杂层级结构的维度。加载文本事实到维度表。处理事实表的代理键。加载三个基本类型的事实表数据<br /> <br />原文链接:[https://blog.csdn.net/asp20/article/details/83431586](https://blog.csdn.net/asp20/article/details/83431586)
https://www.cnblogs.com/xqzt/p/4472111.html
逻辑数据映射(Logical Data Map)用来描述源系统的数据定义、目标数据仓库的模型以及将源系统的数据转换到数据仓库中需要做操作和处理方式的说明文档,通常以表格或Excel的格式保存如下的信息
简述ETL过程中哪个步骤应该出于安全的考虑将数据写到磁盘上?
答:Staging的意思就是将数据写到磁盘上。出于安全及ETL能方便重新开始,在数据准备区(Staging Area)中的每个步骤中都应该将数据写到磁盘上,即生成文本文件或者将建立关系表保存数据,而不应该以数据不落地方式直接进行ETL。
变化数据捕获(CDC)技术是ETL工作中的重点和难点,通常需要在增量抽取时完成。实现变化数据捕获时最理想的是找到源系统的DBA。如果不能找到,就需要ETL项目组自己进行检测数据的变化。下面是一些常用的技术。
1.采用审计列
审计列指表中如“添加日期”、“修改日期”、“修改人”等信息的字段。应用程序在对该表的数据进行操作时,同时更新这些字段,或者建立触发器来更新这些字段。采用这种方式进行变化数据捕获的优点是方便,容易实现。缺点是如果操作型系统没有相应的审计字段,需要改变已有的操作型系统的数据结构,以保证获取过程涉及的每张表都有审计字段。
2.数据库日志
DBMS日志获取是一种通过DBMS提供的日志系统来获得变化的数据。它的优点是对数据库或访问数据库的操作系统的影响最小。缺点是要求DBMS支持,并且对日志记录的格式非常了解。
3.全表扫描
全表扫描或者全表导出文件后进行扫描对比也可以进行变化数据捕获,尤其是捕获删除的数据时。这种方法的优点是,思路清晰,适应面广,缺点是效率比较差。
在维度表的迁移过程中,有一种处理方式是使用无意义的整型值分配给维度记录并作为维度记录的主键,这些作为主键的整型值称为代理键(Surrogate Key)。使用代理键有很多好处,如隔离数据仓库与操作环境,历史记录的保存,查询速度快等。
同时,在事实表的迁移过程中,为了保证参照完整性也需要进行代理键的替换工作。为了代理键替换的效率高一些,我们通常在数据准备区中建立代理键查找表(Surrogate Mapping Table or Lookup Table)。代理键查找表中保存最新的代理键和自然键的对应关系。在对事实表进行代理键替换时,为了保证效率高,需要把代理键查找表中的数据加载到内存中,并可以开多线程依次替换同一记录的中的不同代理键,使一条事实记录在所有的代理键都替换完后再写如磁盘中,这样的替换过程称为代理键替换管道(Surrogate Key Pipeline)。
了起夜率,说明值班制度在数据部门应该是普遍存在的现象
漂移
https://blog.csdn.net/zhchs2012/article/details/98214488
hive中导入数据的4种方式从本地导入:loaddatalocalinpath/home/liuzcintotableods.test从hdfs导入:loaddatainpath/user/hive/warehouse/a.txtintoods.test查询导入:createtabletmp_testasselectfromods.test查询结果导入:insertintotabletmp.testselectfromods.test
.Hive的执行流程?用户提交查询等任务给Driver。编译器获得该用户的任务Plan。编译器Compiler根据用户任务去MetaStore中获取需要的Hive的元数据信息。编译器Compiler得到元数据信息,对任务进行编译,先将HiveQL转换为抽象语法树,然后将抽象语法树转换成查询块,将查询块转化为逻辑的查询计划,重写逻辑查询计划,将逻辑计划转化为物理的计划(MapReduce),最后选择最佳的策略。将最终的计划提交给Driver。Driver将计划Plan转交给ExecutionEngine去执行,获取元数据信息,提交给JobTracker或者SourceManager执行该任务,任务会直接读取HDFS中文件进行相应的操作。获取执行的结果。取得并返回执行结果。
基础
hadoop为优化有arm版本
insert overwrite快
cube是每个属性一个维度,多个维度交叉点都计算,每个小的cube都算,维度越多计算量越大
hive命令可以用sql或者beeline看的格式化一点
https://koendecouck.github.io/2018/02/impalavshive/ 这个讲hive的utc很底层要改为年 月 日 分开
java scala的hadoop 环境
https://github.com/sdravida/hadoop2.6_Win_x64
[
hdfs dfs -setrep -R 2 /想临时增加副本的目录
](https://blog.csdn.net/dengmanzhou3124/article/details/101891023)
hive -e \
“MSCK REPAIR TABLE ods.ods_carrecord;
MSCK REPAIR TABLE ods.ods_imsirecord;
MSCK REPAIR TABLE ods.ods_faceimage;[
,因为没有经过hive,是直接写的文件,所以无论内外部都需要做分区修复
spark直接写文件,需要同步到hive的系统知道(meta数据)
](https://blog.csdn.net/dengmanzhou3124/article/details/101891023)
安全模式
- HDFS集群故障时,必要的话需要启动安全模式,暂停数据写入:hdfs dfsadmin -safemode enter
- 故障修复时关闭安全模式:hdfs dfsadmin -safemode leave
[
服务器端相关的(NameNode、DataNode、JournalNode、ResourceManager、NodeManager),core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml的配置项修改只后都需要重启服务。
任务相关的配置,比如map/reduce申请的内存数、map/reduce提交时需要指定的额外的java参数等,就不需要重启服务。
](https://blog.csdn.net/dengmanzhou3124/article/details/101891023)
传统 OLTP 数据库通常采用行式存储。以下图为例,所有的列依次排列构成一行,以行为单位存储,再配合以 B+ 树或 SS-Table 作为索引,就能快速通过主键找到相应的行数据。
行式存储对于 OLTP 场景是很自然的:大多数操作都以实体(entity)为单位,即大多为增删改查一整行记录,显然把一行数据存在物理上相邻的位置是个很好的选择。
[
](https://blog.csdn.net/ws1296931325/article/details/86635751)
列式存储对于 OLTP 不友好,一行数据的写入需要同时修改多个列。但对 OLAP 场景有着很大的优势:
- 当查询语句只涉及部分列时,只需要扫描相关的列
- 每一列的数据都是相同类型的,彼此间相关性更大,对列数据压缩的效率较高
BigTable 并非列式存储,借鉴C-Store 等列式存储的某些设计,但 BigTable 本身按 Key-Value Pair 存储数据,和列式存储并无关系。
BigTable 的列簇(column family)概念,列簇可以被指定给某个 locality group,决定了该列簇数据的物理位置,从而可以让同一主键的各个列簇分别存放在最优的物理节点上。由于 column family 内的数据通常具有相似性,对它做压缩要比对整个表压缩效果更好。(hbase)
列式数据库可以是关系型、也可以是 NoSQL
DBMS 采用 NSM (N-ary Storage Model) 即按行存储的方式,将完整的行(即关系 relation)从 Header 开始依次存放。页的最后有一个索引,存放了页内各行的起始偏移量。由于每行长度不一定是固定的,索引可以帮助我们快速找到需要的行,而无需逐个扫描。
NSM 的缺点在于,如果每次查询只涉及很小的一部分列,那多余的列依然要占用掉宝贵的内存以及 CPU Cache,从而导致更多的 IO;为了避免这一问题,很多分析型数据库采用 DSM (Decomposition Storage Model) 即按列分页:将 relation 按列拆分成多个 sub-relation。类似的,页的尾部存放了一个索引。
NSM 能更快速的取出一行记录,这是因为一行的数据相邻保存在同一页;DSM 能更好的利用 CPU Cache 以及使用更紧凑的压缩。PAX 的做法是将一个页划分成多个 minipage,minipage 内按列存储,而一页中的各个 minipage 能组合成完整的若干 relation。
很多先进的 DBMS 已经抛弃了按页存储的模式,但是其中的某些思想,例如数据分区、分区内索引、行列混合等,仍然处处可见于这些现代的系统中。
编码和压缩不仅是节约空间的手段,更多时候也是组织数据的手段。在 PowerDrill、Dremel 等系统中,我们会看到很多编码本身也兼具了索引的功能,
分布式:延迟要比硬盘大得多,且受网络环境影响很大。大多不支持随机写入。为了抵消网络的 overhead,通常写入都以几十 MB 为单位。很多定位于 OLAP 的列式存储选择放弃 OLTP 能力,从而能构建在分布式文件系统之上。
分布式文件系统的性能发挥到极致,无非有几种方法:按块(分片)读取数据、流式读取、追加写入等。
C-Store 的主要贡献有以下几点:通过精心设计的 projection 同时实现列数据的多副本和多种索引方式;用读写分层的方式兼顾了(少量)写入的性能。
ORC 支持各种格式的字段,包括常见的 int、string 等,也包括 struct、list、map 等组合字段;字段的 meta 信息就放在 ORC 文件的尾部
https://zhuanlan.zhihu.com/p/35622907[
](https://blog.csdn.net/ws1296931325/article/details/86635751)
Apache Parquet是Hadoop生态系统中任何项目均可使用的列式存储格式,而与选择数据处理框架,数据模型或编程语言无关。创建Parquet是为了使Hadoop生态系统中的任何项目都可以使用压缩的,高效的列式数据表示形式。
Parquet是从头开始构建的,考虑了复杂的嵌套数据结构,并使用了Dremel论文中描述的记录粉碎和组装算法。我们相信这种方法优于嵌套名称空间的简单扁平化。

平衡二叉树又称 AVL 树,在满足二叉查找树特性的基础上,要求每个节点的左右子树的高度差不能超过 1。
我们应该寻找一种单个节点可以存储多个键值和数据的平衡树。也就是我们接下来要说的 B 树。
B 树相对于平衡二叉树,每个节点存储了更多的键值(key)和数据(data),并且每个节点拥有更多的子节点,子节点的个数一般称为阶。
B+ 树非叶子节点上是不存储数据的,仅存储键值,而 B 树节点中不仅存储键值,也会存储数据。
因为 B+ 树索引的所有数据均存储在叶子节点,而且数据是按照顺序排列的。
SSTable文件分为数据区与索引区,尾部的footer指出了meta index block与data index block的偏移与大小,index block指出了各data block的偏移与大小,metaindex block指出了filter block的偏移与大小
https://blog.csdn.net/ws1296931325/article/details/86635751
https://www.cnblogs.com/pengbangxiang/p/9705286.html
Map阶段传递给Reduce阶段的过程就叫Shuffle,洗牌、发牌(核心机制:数据分区、排序、缓存)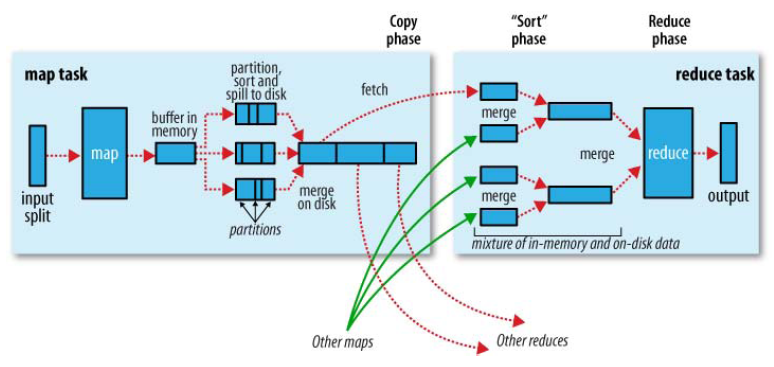
海量实时计算,Ad-Hoc Query,在人可容忍的交互时间内(5秒内),对于给定查询返回结果,典型应用场景为:
- 产品运营实时洞察
- A/B Testing
- 用户增长领域
查询有以下特点:
- (灵活性) 查询方式不固定,不能被预计算
- (海量) 查询数据规模超出传统数据库可以承受的规模 (100亿+)
- (实时) 可以查询到最近产生的数据, 这一点不同业务形态要求的实时性会有差别
Ad-Hoc Query 在很多方面和 OLAP 很像,只是要求更高的灵活性
- ORC 比 Parquet 晚一点出现,在数据压缩上有一定优势
- Parquet 出现的早,开源社区的支持度会比 ORC 好一点,但已经非常接近了
- Parquet 和 ORC 背后是 Cloudera(Impala) 和 Hortonworks(Hadoop,hive) 两家商业公司之争
- 最近阿里巴巴也加入了 ORC 阵营,并做了成吨的优化
- ORC 前景看好一些
大数据计算引擎和存储引擎完全解耦,中间的定期 Table Compaction 成了一个空白地带 ???,因为这需要一个常驻的后台服务。可以选择 Spark 去实现 Table Compaction,毕竟只需要几行代码,但从工程实践的角度讲,引入一个流程从来都不是几行代码这么简单,需要解决的问题有很多:
如果选择 Spark Compaction,关于加载实时数据的方案可能是,额外写一份数据到 HBase/ElasticSearch,这样可以历史数据从 HDFS ORC 加载,实时数据从 HBase/ElasticSearch 加载。
Apache Kudu 为了解决海量数据的实时性查询而生,它不像 HBase 那样专注于 OLTP,而是取得了 OLAP/OLTP 的一个平衡点。
https://zhuanlan.zhihu.com/p/131366019
spark去yarn申请资源后,spark跑在yarn制定所在的机器中
hdfs主节点只能通过ha实现主备,yarn主节点好像也一样
hdfs文件块大小是优化速度的重要因素,mr通过hdfs namenode制定了data node后,data node如果在不同的机器,不同机器记忆 scsi或sata一起传数据,读的速度更快
常用命令和原理
dfs. namenode.name.dir属性可以配置多个目录
块的大小可以通过配置参数( dfs.blocksize)来规定
hdfs://namenode:port/dir-a/dir-b/dir-c/file.data
副本数量也可以通过参数设置dfs.replication
HDFS是设计成适应一次写入,多次读出的场景,且不支持文件的修改
hdfs步骤图:

https://www.cnblogs.com/tjp40922/p/12670542.html
Hadoop 为什么不建议使用 RAID:
因为采用 RAID 会有下面三个缺点:1. 性能会有所降低,主要受限于最慢的disk(哪怕一个品牌的disk,性能也会不一样);
2. 磁盘整理可用性降低,其中一块或是几块盘坏掉,可能会造成整个 RAID 都不可用;
3. 可能会造成资源浪费,Hadoop 中每份数据都会有三个副本,存在冗余的 RAID 就没有必要;

非Java客户端访问元数据库,在服务器端启动MetaStoreServer,客户端利用Thrift协议通过MetaStoreServer访问元数据库。


https://www.cnblogs.com/bonelee/p/12441814.html
cnblogs.com/hark0623/p/12248889.html
https://blog.csdn.net/zhm1002/article/details/106642457
Hive表和数据迁移
Hive的三种Join方式
cnblogs.com/raymoc/p/5323824.html
Hive使用SerDe读写表的行数据
HDFS FILES—>InputFileFormat—>
Row Object—>Serializer—>
hive文件的存储格式主要分为以下四种: TEXTFILE、SEQUENCEFILE、RCFILE、ORCFILE
其中TEXTFILE为默认格式,建表时不指定默认为这个格式,导入数据时直接把数据文 件COPY到HDFS上不进行处理。
SEQUENCEFILE、RCFILE、ORCFILE格式的表不能直接从本地文件导入数据,数据要 先导入到textfile格式的表中,然后再从表中用insert导入SequenceFile,RcFile和 OrcFile中。
Orcfile(Optimized Row Columnar)是hive 0.11版里引入的新的存储格式, 是 对之前的RCFile存储格式的优化。可以看到每个Orc文件由1个或多个stripe(线条)组成,每个stripe250MB大小, 这个Stripe实际相当于之前的rcfile里的RowGroup概念,不过大小由 4MB->250MB, 这样应该能提升顺序读的吞吐率。每个Stripe里有三部分组成,分 别是IndexData,Row Data,Stripe Footer:
1、Index Data:一个轻量级的index,默认是每隔1W行做一个索引。这里做的索引只是记录某行的各字段在Row Data中的offset。
2、Row Data:存的是具体的数据,和RCfile一样,先取部分行,然后对这些行按列进行存储。与RCfile不同的地方在于每个列进行了编码,分成多个Stream来存储
3、Stripe Footer:存的是各个Stream的类型,长度等信息。
它更多的用在多任务节点的场景下,快速地全表扫描大规模数据。但是在某些场景下,建立索引还是可以提高Hive表指定列的查询速度。(虽然效果差强人意)
索引适用的场景适用于不更新的静态字段。以免总是重建索引数据。每次建立、更新数据后,都要重建索引以构建索引表。
Hive索引的机制如下:
hive在指定列上建立索引,会产生一张索引表(Hive的一张物理表),里面的字段包括,索引列的值、该值对应的HDFS文件路径、该值在文件中的偏移量;
v0.8后引入bitmap索引处理器,这个处理器适用于排重后,值较少的列(例如,某字段的取值只可能是几个枚举值)
因为索引是用空间换时间,索引列的取值过多会导致建立bitmap索引表过大。
但是,很少遇到hive用索引的。说明还是有缺陷or不合适的地方的。
原文链接:https://blog.csdn.net/i000zheng/article/details/80435610
hive索引
- 使用过程繁琐
- 需用额外Job扫描索引表
- 不会自动刷新,如果表有数据变动,索引表需要手动刷新
更新maven更多的mirror库,以便能找到hive等包
https://blog.csdn.net/zxctime/article/details/106007508
from_unixtime可能是时区,count 1不行,count *偶尔可以,
https://tech.meituan.com/2014/02/12/hive-sql-to-mapreduce.html
分页
select t11. from ( select row_number() over (order by t10.objectid) as rnum ,t10. from myobject t10 )t11 where t11.rnum between 1 and 50;
row_number() over(order by 1) as auto_increment_id 加自增字段
drop table if exists tmp_test05.tmp_place_collide;
create table tmp_test05.tmp_place_collide as
SELECT row_number() over(order by 1) as auto_increment_id, placeid
from
(
SELECT placeid
FROM dwd_test05.dwd_predeal_imsirecord_t6
where day=’20210814’ and placeid in (SELECT placeid
FROM dwd_test05.dwd_predeal_carrecord_t6
where day=’20210814’)
group by placeid
) t1;
hive -S -e “use test; select * from ${tablename} limit ${limitcount};”
hive -hiveconf enter_school_date=”20130902” -hiveconf min_ag=”26” -f testvar.sql
https://www.cnblogs.com/cc-java/p/6898788.html
hive -e “selectuser, login_timestamp from user_login” > /tmp/out.txt
hive> insert overwrite localdirectory”/tmp/out/“
hive> insert overwrite directory”/tmp/out/“ (hdfs)
hive> insert overwrite table query_result
selectuser, login_time from user_login;
https://blog.csdn.net/zhuce1986/article/details/39586189
前缀才能用
create temporary table tmp_test05.tmp_carids as
select carid from dwd_test05.dwd_predeal_carrecord where day=’20210814’ group by carid;
select count(1) from tmp_test05.tmp_carids;
hive传参数给shell脚本
r=$(hive -e “SELECT count(1) from (SELECT count(1) FROM ods_test05.ods_imsirecord where day=’20211009’ GROUP BY imsi) t”)
hive传递状态给shell脚本
docker exec node3 hive -e “desc $t1;” 2>&1 | grep ‘Table not found’ 执行完了才执行下面
t1_status=$?
if [ $t1_status == 0 ];then
echo “success”
else
echo “false”
fi
例子:
短期优化
set mapreduce.map.memory.mb=30000;
set mapreduce.map.cpu.vcores=5;
set mapreduce.reduce.memory.mb=15000;
set mapreduce.reduce.cpu.vcores=5;
set hive.auto.convert.join = true;
set hive.mapjoin.smalltable.filesize = 62500000;
drop table if exists tmp_test05.tmp_short_carids;
create table tmp_test05.tmp_short_carids as
select row_number() over(order by 1) as auto_increment_id, carid,catchtime,placeid
from(
select carid,catchtime,placeid, COUNT(1) over (PARTITION by carid ) as place_num from dwd_test05.dwd_predeal_carrecord where day=’20210814’
) t1
where place_num > 1;
drop table if exists tmp_test05.tmp_short_imsis;
create table tmp_test05.tmp_short_imsis as
select imsi,uptime,placeid
from(
select imsi,uptime,placeid, COUNT(1) over (PARTITION by imsi ) as place_num2 from dwd_test05.dwd_predeal_imsirecord where day=’20210814’
) t1
where place_num2 > 1;
with distinct_person as
(
select
imsi,
pid
from dwd_test05.dwd_person
where quality=1 and (weight>=800 or (weight<800 and weightrank=1))
group by imsi,pid
),
place_camera as
(
select distinct placeid,substr(placeid,22) as simpleplace
from dim_test05.dim_mdb_camera
)
insert overwrite table ads_test05.ads_ci_travelrecord partition(day=”20210814”)
select md5(cast(concat(“20210814”,t5.imsi,t5.carid) as binary)) as ccid, t5.carid,t5.imsi,place_camera.placeid, t5.catchtime,t5.uptime, t5.pid
from place_camera
join (
select t3.carid,t3.imsi,t3.placeid,t3.catchtime,t3.uptime, t4.pid
from(
select t1.carid,t2.imsi,t1.placeid,t1.catchtime,t2.uptime, count(1) over(partition by t1.carid, t2.imsi) as cnbyday
from (
select carid,catchtime,placeid from tmp_test05.tmp_short_carids where auto_increment_id >= 1 and auto_increment_id < 5000
) t1
join
(
select imsi,uptime,placeid from tmp_test05.tmp_short_imsis
) t2
on t1.placeid=t2.placeid
where abs(t1.catchtime-t2.uptime)<= 360
) t3
left join distinct_person t4 on t3.imsi = t4.imsi
) t5
on t5.placeid = place_camera.simpleplace
beeline -u ‘jdbc:hive2://node2:10000/default’
https://blog.csdn.net/lp_cq242/article/details/84033059
流程
hdfs读写流程 https://blog.csdn.net/weixin_39797324/article/details/110256944

排序
与数据库中order by的区别在于hive.mapred.mode = strict模式下 必须指定limit否则执行会报错
事务
https://blog.csdn.net/zjerryj/article/details/91470261
调优
RAC(Real Application Cluster)真正应用集群就像一辆机动灵活的小货车,响应快;Hadoop就像吞吐量巨大的轮船,启动开销大,如果每次只做小数量的输入输出,利用率将会很低。所以用好Hadoop的首要任务是增大每次任务所搭载的数据量。
Hadoop的核心能力是parition和sort,因而这也是优化的根本。
避实就虚,用 job 数的增加,输入量的增加,占用更多存储空间,充分利用空闲 CPU 等各种方法,分解数据倾斜造成的负担。
原文链接:https://blog.csdn.net/young_0609/article/details/84593316
思路:点击时分析和临时分析分离(概览数据要一直展示,不好搞点击)
长期车码跑6天碰撞2次及以上中间数据,再基于6天、30天、180算置信度
思路:实时把数据全部放在一起一分钟切,之内的数据放在一起(未来实现)
思路:mapjoin,找出小表,shell循环多次
思路:多次insert出各种中间表
思路:先得到两个device下同时有的car , 两次imsi感觉概率太大, 再互相去碰
思路:基于短期两个点算,有问题,因为可能卡口的数量不多,不会同时过多个点,一个点一个时间范围内碰多天增加置信度。
思路:分区分桶,orc的index
思路:mongo通过index补数据
时间类型用的long
思路:通过分区分布统计后的结果再连接原始表ads_ci_travelrecord。但是业务特性,统计能合并的信息不够多,还不如一次性统计;但是加入连接表一次都碰撞的分桶表时可能性能就提升了
思路:统一时间不同几个任务操作一个表,不要竞争
调参
矢量查询(Vectorized query) 每次处理数据时会将1024行数据组成一个batch进行处理,而不是一行一行进行处理,这样能够显著提高执行速度。
可以通过设置
set hive.vectorized.execution.enabled = true; set hive.vectorized.execution.reduce.enabled = true;
https://www.cnblogs.com/SpeakSoftlyLove/p/6063908.html
COST BASED QUERY OPTIMIZATION可以优化hive的每次查询。如果想要使用CBO,需要开启一下选项:
set hive.cbo.enable=true; set hive.compute.query.using.stats=true; set hive.stats.fetch.column.stats=true; set hive.stats.fetch.partition.stats=true;
如果我们想要使用CBO,需要通过HIVE的分析模式来收集表的不同统计数据,我们可以通过下面的命令来进行:
analyze table tweets compute statistics for columns;
这样子,HIVE就可以通过消耗评估和不同的执行计划来让我们的查询跑的更快。
UDF
tez引擎和LLAP
Hive Indexing
https://www.cnblogs.com/shun7man/p/13339831.html
https://zhuanlan.zhihu.com/p/268314469
LLAP是Hive部署在Yarn之上的一个用于数据缓存的服务,这样Hive任务在运行时,可以直接从LLAP中提取数据,或者缓存频繁查询的数据结果。利用LLAP,官方表示可以提升大概25倍的运行效率。
count distinct
原来因为加入distinct,map阶段不能用combine消重,数据输出为(key,value)形式然后在reduce阶段进行消重。
重点是,Hive在处理COUNT这种“全聚合(full aggregates)”计算时,它会忽略用户指定的Reduce Task数,而强制使用1。
示意图如下
解决办法:转换为子查询,转化为两个mapreduce任务 先select distinct的字段,然后在count(),这样去重就会分发到不同的reduce块,count依旧是一个reduce但是只需要计数即可。
优化方法:利用gourp by 按id,account分组,存入一个临时表 只需要对临时表进行统计即可
select count(*) from (select distinct account form tablename where…)t;
insert overwrite table temp select id,account,count(1) as num from tablename group by id,account;
https://www.cnblogs.com/ling1995/p/7339424.html
先单表
https://blog.csdn.net/eagle89/article/details/108621735
增加并行度
set mapred.reduce.tasks=1000;
排序
分块停止???
排序后加快
自增字段
还可以基于整数基于取模把数据分开(加一个字段)
https://zhuanlan.zhihu.com/p/161231280
存储过程
HPL/SQL is a built-in part of Apache Hive since version 2.0. The source code and binaries available on this site can help you build and use HPL/SQL for any Hive version, any SQL-on-Hadoop, NoSQL or RDBMS product.
http://www.hplsql.org/doc
例子
https://blog.csdn.net/u010520724/article/details/112344713
限制
https://www.cnblogs.com/qifengle-2446/p/6424546.html
分区分桶(目录分数据、文件分数据)
量大时可以基于carid进行分桶
基于分区的查询的语句不需要带partition:
SELECT day_table.* FROM day_table WHERE day_table.dt>= ‘2008-08-08’;
create table fentong(
> id int,
> name string,
> age int,)clustered by(age) into 4 buckets
> row format delimited fields terminated by ‘,’;
select id, name, age from fentong tablesample(bucket 1 out of 4 on age);
网上很多案例教程说的非常绕,一时很难离清楚,现分享如下通俗 易懂的教程:
怎么分:①在前面创建分桶表的时候有这样语句:age int,)clustered by(age) into 4 buckets 说明本案例是以年龄age来划分成4个桶;
分桶的数据怎么分到四个桶:它是将表中对应的字段值(比如age)分别来除以桶的个数4,结果取余数(也就是取模),若余数为0就放到1号桶,余数为1就放到2号桶
余数为2就放到3号桶,余数为3就放到4号桶
②这句话怎么理解:select id, name, age from psnbucket tablesample(bucket 2 out of 4 on age);
https://www.cnblogs.com/wang3680/p/11737106.html
双分区建表语句:create table day_hour_table (id int, content string) partitioned by (dt string, hour string);双分区表,按天和小时分区,在表结构中新增加了dt和hour两列。
https://blog.csdn.net/wisgood/article/details/17188047
一个目录对应一个分区,一个文件对应一个分桶。Hive默认采用对某一列的每个数据进行hash(哈希),使用hashcode对 桶的个数求余,确定该条记录放入哪个桶中。
只能对一列进行分桶。表可以同时分区和分桶,当表分区时,每个分区下都会有
https://www.jianshu.com/p/004462037557
此时静态分区和动态分区才会有很大的不同,或者说是依据导数据的方式来判断 是动态分区还是静态分区:
insert into employee_hrpar partition(sex=’male’) select id,username,bir from ods_users where sex=’male’;
insert into employee_hrpar partition(sex=’female’) select id,username,bir from ods_users where sex=’female’;
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
创建分区表都是上面的创建方式,添加数据的方式如下:再次之前可以使用groupby 或者 distinct 了解下数据信息,方便下面的分区.
动态不手动指定
insert into myuser partition(sex) select * from ods_users;
静态分区:是自己定义数据 多用于增量表(不断增加表的内容)比如新闻表,每天都会变化增加需要事先知道有多少分区,每个分区都要手动插入。动态分区:事先先用group 或者distinct 看一下字段值的种类
多用于每年 每月 每日 等 多用于全量导入 数据量不能太大
https://blog.csdn.net/qq_41704237/article/details/107294668
month_id为静态分区,day_id为动态分区:
insert overwrite table dynamic_test partition(month_id=’201710’,day_id)
select c1,c2,c3,c4,c5,c6,c7,day_id from kafka_offset
where substr(day_id,1,6)=’201710’;
month_id和 day_id均为动态分区:
insert overwrite table dynamic_test partition(month_id,day_id)
select c1,c2,c3,c4,c5,c6,c7,substr(day_id,1,6) as month_id,day_id from kafka_offset;
https://blog.csdn.net/afafawfaf/article/details/80249974
还可以直接赋值(静态和动态一起)
insert overwrite table dwd.dwd_predeal_carrecord1_t1 partition(day = ‘20211015’, placeid)
select
y.carid,
substr(y.placeid,22) as placeid,
y.catchtime
ValidationFailureSemanticException Partition spec {placeid=null, day=null} contains non-partition columns
我是因为表明写错了
插入分区字段名必须跟创建表分区字段名相同
https://blog.csdn.net/qq_44868502/article/details/102852941
For me fix was that both column name has to be lower-case in the table and PARTITION BY clause’s in table definition has to be lower-case. (they can be both upper-case too; due to this Hive bug HIVE-14032 the case just has to match)
必须小写双分区
It’s because of the extra characters present in the file. Best solution is to remove all the blank characters and reinsert if you want.
- 如果分桶表创建时定义了排序键,那么数据不仅要分桶,还要排序
- 如果分桶键和排序键不同,且按降序排列,使用Distribute by … Sort by分桶排序
- 如果分桶键和排序键相同,且按升序排列(默认),使用 Cluster by 分桶排序,即如下:
我们也可以选择使用 SORTED BY … 在桶内排序,排序键和分桶键无需相同。ASC 为升序选项,DESC 为降序选项,默认排序方式是升序。
https://blog.csdn.net/whdxjbw/article/details/82219022
order by:
order by会对所给的全部数据进行全局排序,并且只会“叫醒”一个reducer干活。它就像一个糊涂蛋一样,不管来多少数据,都只启动一个reducer来处理。因此,数据量小还可以,但数据量一旦变大order by就会变得异常吃力,甚至“罢工”。
sort by:
sort by是局部排序。相比order by的懒惰糊涂,sort by正好相反,它不但非常勤快,而且具备分身功能。sort by会根据数据量的大小启动一到多个reducer来干活,并且,它会在进入reduce之前为每个reducer都产生一个排序文件。这样的好处是提高了全局排序的效率。
sort by不像order by,它不能保证全局排序,在多个reduce输出的情况下,它只能保证每个reduce的输出结果有序
distribute by:
distribute by的功能是:distribute by 控制map结果的分发,它会将具有相同字段的map输出分发到一个reduce节点上做处理。即就是,某种情况下,我们需要控制某个特定行到某个reducer中,这种操作一般是为后续可能发生的聚集操作做准备。
所以当distribute by 遇上 sort by时,distribute by要放在前面,这个不难理解,因为要先通过distribute by 将待处理的数据从map端做分发,这样,sort by 这个擅长局部排序的才能去放开的干活。不然要是没有distribute by的分发,那么sort by 将要处理全部的数据
cluster by:
cluster by,在《Hadoop权威指南第二版》中这样描述道:
from recrds2
select year , temperature
cluster by year; 和distribute、sort一样的,就是分桶用的语句
也就是说,如果参照上面气象数据的栗子,当二者皆取year列时
https://blog.csdn.net/qq_40795214/article/details/82190827
写入的方法
set hive.enforce.bucketing=true;
得到的分桶对应的文件,数据是无序的,也就是 sorted by 或 sort by无
方法二:
//关闭强制分桶开关:
hive (myhive)> set hive.enforce.bucketing=false;
//设置reduces数和分桶数一致:
hive (myhive)> set mapreduce.job.reduces=3;
//通过其他表插入数据,要添加 distribute by 以及 sort by。
两者完全相同。物理上每个桶就是目录里的一个文件,一个作业产生的桶(输出文件)数量和reduce任务个数相同。
hive (myhive)> insert into table student select id, name from stu distribute by st_dept;
jianshu.com/p/004462037557
https://blog.csdn.net/panfelix/article/details/107433442
set hive.enforce.bucketing = true; //???和前面的sort有序要关enforce.bucketing,可以通过clusterby解决,还是false
set hive.optimize.bucketmapjoin = true; _set hive.optimize.bucketmapjoin.sortedmerge = true; set hive.input.format=org.apache.hadoop.hive.ql.io.BucketizedHiveInputFormat; _
Bucket columns==Join Columns==Sort Columns,完全具备具备使用Sort Merge Bucket Map Join的条件
Sort Merge
https://blog.csdn.net/yjgithub/article/details/66972966
clustered by和sorted by不会影响数据的导入,这意味着,用户必须自己负责数据如何如何导入,包括数据的分桶和排序。
‘set hive.enforce.bucketing = true’ 可以自动控制上一轮reduce的数量从而适配bucket的个数,当然,用户也可以自主设置mapred.reduce.tasks去适配bucket个数,推荐使用’set hive.enforce.bucketing = true’
ggg
hive并不检查两个join的表是否已经做好bucket且sorted,需要用户自己去保证join的表,否则可能数据不正确。有两个办法
1)hive.enforce.sorting 设置为true。
2)手动生成符合条件的数据,通过在sql中用distributed c1 sort by c1 或者 cluster by c1
表创建时必须是CLUSTERED且SORTED,如下
create table test_smb_2(mid string,age_id string)
CLUSTERED BY(mid) SORTED BY(mid) INTO 500 BUCKETS;
2 SMB join (针对bucket mapjoin 的一种优化)
2.1 条件
1)
set hive.auto.convert.sortmerge.join=true;
set hive.optimize.bucketmapjoin = true;
set hive.optimize.bucketmapjoin.sortedmerge = true;
set hive.auto.convert.sortmerge.join.noconditionaltask=true;
2) 小表的bucket数=大表bucket数
3) Bucket 列 == Join 列 == sort 列
https://www.cnblogs.com/streetpasser/p/13033038.html
不是:下面的key value是不是orc中的column的一定行,这样多行还是要拆分成多个column key,行列块切分
mapreduce key-value的:map-reduce的key就是对应连接字段的值,value就是其它关联字段
map阶段:在map阶段,把所有记录标记成
https://blog.csdn.net/sofuzi/article/details/81265402
Reason:
SQL Error [10141] [42000]: Error while compiling statement: FAILED: SemanticException [Error 10141]: Bucketed table metadata is not correct. Fix the metadata or don’t use bucketed mapjoin, by setting hive.enforce.bucketmapjoin to false. The number of buckets for table dws_ci_imsicarpoint_t5 partition day=20210814 is 64, whereas the number of files is 448
reduce side join:map阶段的主要任务是对不同文件中的数据打标签。
在reduce阶段,reduce函数获取key相同的来自File1和File2文件的value list, 然后对于同一个key,对File1和File2中的数据进行join(笛卡尔乘积)。
map side join(小表内存)让每个map task内存中存在一份(比如存放到hash table中),然后只扫描大表:对于大表中的每一条记录key/value,在hash table中查找是否有相同的key的记录,如果有,则连接后输出即可。
为了支持文件的复制,Hadoop提供了一个类DistributedCache,JobTracker在作业启动之前会获取这个URI列表,并将相应的文件拷贝到各个TaskTracker的本地磁盘上。
???不仅exist可以么
Semi Join(类似我的车的一个值找出来单独过滤)
如果能够在map端过滤掉不会参加join操作的数据,则可以大大节省网络IO。
实现方法很简单:选取一个小表,假设是File1,将其参与join的key抽取出来,保存到文件File3中,File3文件一般很小,可以放到内存中。在map阶段,使用DistributedCache将File3复制到各个TaskTracker上,然后将File2中不在File3中的key对应的记录过滤掉,剩下的reduce阶段的工作与reduce side join相同。
bloomfilter:1个bit表示是否在,多个hash冲突是是否在, 缺点是存在误差和删除困难。
数组的每个元素都只占1bbit空间,并且每个元素只能为0或1。
布隆过滤器还拥有K个哈希函数,当一个元素加入到布隆过滤器时会使用k个hash函数对其进行k次计算,得到k个哈希值,并且根据得到的哈希值,在位数组中把对应下标的值置为1
BloomFilter最常见的作用是:判断某个元素是否在一个集合里面。它最重要的两个方法是:add() 和contains()。
BloomFilter最常见的作用是:判断某个元素是否在一个集合里面。它最重要的两个方法是:add() 和contains()。
最大的特点是不会存在 false negative,即:如果contains()返回false,则该元素一定不在集合中,但会存在一定的 false positive,
即:如果contains()返回true,则该元素一定在集合中。
SemiJoin抽取出来的小表的key集合在内存中仍然存放不下,这时候可以使用BloomFiler以节省空间。
因而可将小表中的key保存到BloomFilter中,在map阶段过滤大表,可能有一些不在小表中的记录没有过滤掉(但是在小表中的记录一定不会过滤掉),这没关系,只不过增加了少量的网络IO而已。
(大表分为:bloom中有的,一定是小表的,这一部分用bloomfliter传,其它的用小表key传实际参数)
对于buffer and in memory sort,主要思想是:在reduce()函数中,将某个key对应的所有value保存下来,然后进行排序。 这种方法最大的缺点是:可能会造成out of memory。
对于value-to-key conversion,主要思想是:将key和部分value拼接成一个组合key(实现WritableComparable接口或者调用setSortComparatorClass函数),这样reduce获取的结果便是先按key排序,后按value排序的结果,需要注意的是,用户需要自己实现Paritioner,以便只按照key进行数据划分。Hadoop显式的支持二次排序,在Configuration类中有个setGroupingComparatorClass()方法,可用于设置排序group的key值
http://my.oschina.net/leejun2005/blog/95186 MapReduce 中的两表 join 几种方案简介
http://my.oschina.net/leejun2005/blog/111963 Hadoop 多表 join:map side join 范例
http://my.oschina.net/leejun2005/blog/158491 Hive & Performance 学习笔记
https://blog.csdn.net/wisgood/article/details/17186107
LEFT SEMI JOIN (左半连接)是 IN/EXISTS 子查询的一种更高效的实现。
1、left semi join 的限制是, JOIN 子句中右边的表只能在 ON 子句中设置过滤条件,在 WHERE 子句、SELECT 子句或其他地方过滤都不行。
2、left semi join 是只传递表的 join key 给 map 阶段,因此left semi join 中最后 select 的结果只许出现左表。
3、因为 left semi join 是 in(keySet) 的关系,遇到右表重复记录,左表会跳过,而 join 则会一直遍历。这就导致右表有重复值得情况下 left semi join 只产生一条,join 会产生多条,也会导致 left semi join 的性能更高。
示例
可以改写为
https://blog.csdn.net/happyrocking/article/details/79885071
https://blog.csdn.net/qq_43688472/article/details/103886453?utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7Edefault-1.no_search_link&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7Edefault-1.no_search_link
列式 

https://www.cnblogs.com/ITtangtang/p/7677912.html
每个ORC文件由1个或多个stripe组成,每个stripe250MB大小,这个Stripe实际相当于之前的rcfile里的RowGroup概念,每个Stripe大小250MB,这样能提升顺序读的吞吐率。每个Stripe里有三部分组成,分别是IndexData,Row Data,Stripe Footer:
https://blog.csdn.net/sanms/article/details/11197895
ORC的压缩比 5

上图中原始的TEXT文本文件为585GB,使用Hive早期的RCFILE压缩后为505GB,使用Impala中的PARQUET压缩后为221GB,而Hive中的ORC压缩后仅为131GB,压缩比最高。
还有一个更有效的优化手段是在数据入库的时候,根据id字段排序后入库,这样尽量能使id=0的数据位于同一个文件甚至是同一个stripe中,那么在查询时候,只有负责读取该文件的Map Task需要扫描文件,其他的Map Task都会跳过扫描,大大节省Map Task的执行时间。使用ORDER BY可能不太现实,另一个有效手段是使用DISTRIBUTE BY id SORT BY id;
hive.optimize.index.filter,是否自动使用索引,默认为false(不使用);如果不设置该参数为true,那么ORC的索引当然也不会使用。
在Hive中执行set hive.optimize.index.filter=true;
http://lxw1234.com/archives/2016/04/630.htm
mapreduce的二次排序 SecondarySort
gg 类型
https://blog.csdn.net/godlovedaniel/article/details/115528063
数据块抽样 ???
Hive提供了另外一种按照百分比进行抽样的方式,这种是基于行数的,按照输入路径下的数据块百分比进行的抽样。
hive (myhive)> select * from student tablesample(0.1 percent) ;
jianshu.com/p/004462037557
链接:https://www.jianshu.com/p/004462037557
<br />小文件的缺陷我们就不说了,直接进入到正题.
HIVE自动合并输出的小文件的主要优化手段为:
set hive.merge.mapfiles = true:在只有map的作业结束时合并小文件,
set hive.merge.mapredfiles = true:在Map-Reduce的任务结束时合并小文件,默认为False;
set hive.merge.size.per.task = 256000000; 合并后每个文件的大小,默认256000000
set hive.merge.smallfiles.avgsize=256000000; 当输出文件的平均大小小于该值时并且(mapfiles和mapredfiles为true),HIVE将会启动一个独立的map-reduce任务进行输出文件的merge。
set hive.merge.orcfile.stripe.level=false; 当这个参数设置为true,orc文件进行stripe Level级别的合并,当设置为false,orc文件进行
set hive.merge.smallfiles.avgsize=60; —输出文件的平均大小小于60byte将被合并.
文件级别的合并。
???
建议大家将参数:hive.merge.smallfiles.avgsize设置大点:set hive.merge.smallfiles.avgsize=256000000;
进而减少小文件数量.
Hive优化–自动合并输出小文件的参数推荐:
set hive.merge.mapfiles = true;
set hive.merge.mapredfiles = true;
set hive.merge.size.per.task = 256000000;
set hive.merge.smallfiles.avgsize=256000000;
set hive.merge.orcfile.stripe.level=false;
hive.merge.size.per.task:作业结束时合并文件的大小,默认256MB;
hive.merge.smallfiles.avgsize:在作业输出文件小于该值时,起一个额外的map/reduce作业将小文件合并为大文件,小文件的基本阈值,设置大点可以减少小文件个数,需要mapfiles和mapredfiles为true,默认值是16MB;
return code 2 资源不够就增加动态分区
set hive.exec.dynamic.partition=true;(可通过这个语句查看:set hive.exec.dynamic.partition;)
set hive.exec.dynamic.partition.mode=nonstrict;
SET hive.exec.max.dynamic.partitions=100000;(如果自动分区数大于这个参数,将会报错)
SET hive.exec.max.dynamic.partitions.pernode=100000;
文件不够增加文件
set hive.exec.max.created.files = 200000;
spark 双分区命名
当insert overwrite table xxxx partition(xxx) select xxxx的时候 ,注意查询的动态分区字段要放到最后一列(多个分区字段,或者最后多列),不然的话会造成插入分区错误,或报错
仅有2个map
set mapreduce.map.memory.mb=15000;
set mapreduce.map.cpu.vcores=5;
set mapreduce.reduce.memory.mb=30000;
set mapreduce.reduce.cpu.vcores=5;
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nostrick;
SET hive.exec.max.dynamic.partitions=10000000;
SET hive.exec.max.dynamic.partitions.pernode=100000;
set hive.vectorized.execution.enabled = true;
set hive.vectorized.execution.reduce.enabled = true;
set hive.optimize.index.filter=true
set hive.enforce.bucketing=true;
set hive.auto.convert.sortmerge.join=true;
set hive.optimize.bucketmapjoin = true;
set hive.optimize.bucketmapjoin.sortedmerge = true;
set hive.auto.convert.sortmerge.join.noconditionaltask=true;
set hive.auto.convert.join = true;
set hive.mapjoin.smalltable.filesize = 5120000000;
insert overwrite table dws_test05.dws_ci_imsicarpoint partition(day=’20210814’)
select t1.carid,t2.imsi,t1.placeid,t1.catchtime,t2.uptime
from (
select carid,catchtime,placeid,day from dwd_test05.dwd_predeal_carrecord_t6
where day=’20210814’ and placeid = ‘6a9’
) t1
join
(
select imsi,uptime,placeid,day from dwd_test05.dwd_predeal_imsirecord_t6
where day=’20210814’ and placeid = ‘6a9’
) t2
on t1.placeid=t2.placeid
where abs(t1.catchtime-t2.uptime)<= 360;
???Map、Reduce数量调整
https://blog.csdn.net/u013332124/article/details/97373278
临时表
Hive临时表数据存储设置
从Hive1.1开始临时表可以存储在内存或SSD,使用hive.exec.temporary.table.storage参数进行配置,该参数有三种取值:memory、ssd、default。
set hive.exec.temporary.table.storage = memory;
create temporary table tmp_test05.tmp_carids as
select carid from dwd_test05.dwd_predeal_carrecord where day=’20210814’ group by carid;
select count(1) from tmp_test05.tmp_carids;
如果内存足够大,将中间数据一直存储在内存,可以大大提升计算性能。
:https://blog.csdn.net/u010520724/article/details/111859402
正確的寫法:
select distinct refid,imsi from (select * from HIVE_D_MT_UU_H_SPARK limit 1000);
調優的寫法:
CREATE TABLE TEMP_HIVE_D_MT_UU_H_SPARK AS
select * from HIVE_D_MT_UU_H_SPARK limit 1000;
select distinct refid,imsi from TEMP_HIVE_D_MT_UU_H_SPARK;
hive最快的執行就是不走MapReduce。簡單的select的是最快的,嵌套啥的都比較忙。與關系型數據庫不同。
临时udf
create temporary function getDistance as ‘com.wisec.hive.DistanceUDF’;
[
](https://blog.csdn.net/maenlai0086/article/details/90763593)
数据类型
hive的string其实就是java的string,java中string的长度,在java中string的字符索引使用的是int。
大约是2G个字符,java string一个英文字符一个字节
不同数据类型关联产生的倾斜问题
问题:不同数据类型 id 的关联会产生数据倾斜问题。
一张表 s8 的日志,每个商品一条记录,要和商品表关联。但关联却碰到倾斜的问题。 s8 的日志中有 32 为字符串商品 id,也有数值商品 id,日志中类型是 string 的,但商品中的 数值 id 是 bigint 的。猜想问题的原因是把 s8 的商品 id 转成数值 id 做 hash 来分配 Reduce, 所以字符串 id 的 s8 日志,都到一个 Reduce 上了,解决的方法验证了这个猜测。
解决方法:把数据类型转换成字符串类型
SELECT * FROM s8_log a LEFT OUTER JOIN r_auction_auctions b ON
a.auction_id=CASE(b.auction_id AS STRING)
原文链接:https://blog.csdn.net/young_0609/article/details/84593316
是否有为null的数据
left join,right join的结果
利用hive的优化机制减少job数:
不论是外关联outer join还是内关联inner join,如果join的key相同,不管有多少表,都会合并为一个MapReduce任务:
select a.val,b.val,c.val from a JOIN b ON (a.key = b.key1) JOIN c ON (c.key2 = b.key1) ——一个job select a.val,b.val,c.val from a JOIN b ON (a.key = b.key1) JOIN c ON (c.key2 = b.key2) ——两个job
4.善用multi-insert:
with tmp_a as ( select name from tmp_test3 ) from tmp_a insert overwrite table tmp_test1 select name where name = ‘test123’
对同一张表的union all 要比多重insert快的多,
原因是hive本身对这种union all做过优化,即只扫描一次源表;
而多重insert也只扫描一次,但应为要insert到多个分区(这个占用时间),所以做了很多其他的事情,导致消耗的时间非常长;
https://blog.csdn.net/mnasd/article/details/81386755
- 一般情况下,单个SQL中最多可以写256路输出,超过256路,则报语法错误。
- 在一个multi insert中:
- 对于分区表,同一个目标分区不允许出现多次。
- 对于未分区表,该表不能出现多次。
- 对于同一张分区表的不同分区,不能同时有Insert overwrite和Insert into操作,否则报错返回。
https://blog.csdn.net/u011500419/article/details/90286322
According to Apache Hive Wiki (https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DML), multi inserts “minimize the number of data scans required. Hive can insert data into multiple tables by scanning the input data just once (and applying different query operators) to the input data”.
https://blog.csdn.net/yjgithub/article/details/78191882
Yes you can apply join condition as well. Below is the query format :
multi-insert没有from语句,通过一个from多次insert,insert之间没有分号
from emp a,emp b(没看到可以这样用要statement)
insert into table manager select distinct a.manager_id, a.name where a.id=b.manager_id
insert into table dept select distinct a.dept_id, a.project_id;
Above query will apply self join on emp table and will extract manager_id and name and then will insert into the manager table. Also it will insert project_id and dept_id in the dept table.
In simple words using inner join below query will also do the same task as above :
from emp a inner join emp b
insert into table manager select distinct a.manager_id, a.name where a.id=b.manager_id
insert into table dept select distinct a.dept_id, a.project_id;
with cte_SNG as
(
select
store_id,order_id,paid_time,department,category,upc,upc_desc,gmv,
channel,paid_date
from cn_ec_bi_dl_secure.wm_order_line_o
where paid_date in( ‘2020-01-03’,’2020-01-04’)
and channel=’SNG’ and store_id=1094
)
from cte_SNG
—插入表_1(test1094_order_line_text)
insert overwrite table vn09jj5.test1094_order_line_text partition(channel,paid_date) —分区
select
store_id,order_id,paid_time,department,category,upc,upc_desc,gmv,
channel,paid_date
where paid_date = ‘2020-01-03’ and channel=’SNG’ and store_id=1094
—插入表_2(test1094_order_line_orc_snappy)
insert overwrite table vn09jj5.test1094_order_line_orc_snappy partition(channel,paid_date) —分区
select
store_id,order_id,paid_time,department,category,upc,upc_desc,gmv,
channel,paid_date
where paid_date = ‘2020-01-04’ and channel=’SNG’ and store_id=1094
https://www.cnblogs.com/rose0705/articles/13454724.html
使用insert all 同时向三个表中插入数据
SCOTT@PROD>insert all
2 when deptno = 10 then
3 into emp10 values (empno,ename,deptno)
4 when deptno = 20 then
5 into emp20 values (empno,ename,deptno)
6 when deptno = 30 then
7 into emp30 values (empno,ename,deptno)
8 select empno,ename,deptno from emp;
https://blog.csdn.net/citiao3931/article/details/100289169
- 插入相同表,如果overwrite和into混用,结果都会追加;
https://blog.csdn.net/yjgithub/article/details/78191882
sql explain 执行计划
[
](https://blog.csdn.net/maenlai0086/article/details/90763593)
小表放前大表放后
mapjoin设置
https://blog.csdn.net/lquarius/article/details/107708662
参数
https://blog.csdn.net/maenlai0086/article/details/90763593
在编写带有join的代码语句时,应该将条目少的表/子查询放在join操作符的前面
因为在Reduce阶段,位于join操作符左边的表会先被加载到内存,载入条目较少的表可以有效的防止内存溢出(OOM)。所以对于同一个key来说,对应的value值小的放前面,大的放后面
LEFT SEMI JOIN是IN和EXISTS的一种高效实现
查询了两次a insert overwrite table tmp1 select … from a where 条件1; insert overwrite table tmp2 select … from a where 条件2; #查询了一次a from a insert overwrite table tmp1 select … where 条件1 insert overwrite table tmp2 select … where 条件2
尽量避免使用distinct进行重排,特别是大表,容易产生数据倾斜(key一样在一个reduce处理)。使用group by替代
- sort by实现部分有序,单个reduce的输出结果是有序的,效率高,通常与distribute by一起使用(distribute by 关键词可以指定map到reduce的key分发)
explain dependency查看sql实际扫描多少分区 ??? ggg
explain SELECT count(1) from (SELECT count(1) FROM ods_test05.ods_imsirecord where day = ‘20211009’ GROUP BY imsi) t
元数据表


compaction_queue为空后面的压缩都为空
更新
https://blog.csdn.net/cuma2369/article/details/107666669
希望
报错
FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.MoveTask. Unable to move source
由于ddl copy而ddl中有location导致第二个命名表出问题
MSCK REPAIR Table *; 预处理写入后,需要定时更新元数据让hive知道hdfs写入数据了
元数据损坏
show create table ods.ods_imsirecord
describe formatted ods.ods_imsirecord
alter table ods.ods_imsirecord add partition(day=’20211217’,hour=’01’)


现象通过新建hive,同时指向copy到的hdfs没有问题,指向老的hdfs就问题
小文件
如果存储1亿个文件,则NameNode需要20G空间,这毫无疑问1亿个小文件是不可取的。
以及不断的从一个DatanNde跳到另一个DataNode去检索小文件
处理大量小文件速度远远小于处理同等大小的大文件的速度。每一个小文件要占用一个slot,而task启动将耗费大量时间甚至大部分时间都耗费在启动task和释放task上。后者每一个小文件启动一个map task,
Hadoop中有一些特性可以用来减轻bookkeeping开销:可以在一个JVM中允许task JVM重用,以支持在一个JVM中运行多个map task,以此来减少JVM的启动开销(通过设置mapred.job.reuse.jvm.num.tasks属性,默认为1,-1表示无限制)。另 一种方法是使用MultiFileInputSplit,它可以使得一个map中能够处理多个split。
文件是许多记录(Records)组成的,那么可以通过调用HDFS的sync()方法(和append方法结合使用),每隔一定时间生成一个大文件。
HAR File
Hadoop Archives (HAR files)
https://blog.csdn.net/lp_cq242/article/details/84033059
1 spark写trigger时长长一点
2 加密导致不能后面添加
3 set hive.merge.mapfiles = true #在Map-only的任务结束时合并小文件
set hive.merge.mapredfiles = true #在Map-Reduce的任务结束时合并小文件
4
set hive.exec.parallel.thread.number=16; //同一个sql允许最大并行度,默认为8
- 合并文件的大小:hive.merge.size.per.task=256_1000_1000(默认值为 256000000)
Hadoop 的 计算框架,不怕数据多,就怕作业数多。
设置合理的mapreduce的task数,能有效提升性能。(比如,10w+级别的计算,用160个reduce,那是相当的浪费,1个足够)。了解数据分布,自己动手解决数据倾斜问题是个不错的选择。
- jobs数比较多的作业运行效率相对比较低,比如即使有几百行的表,如果多次关联对此汇总,产生几十个jobs,将会需要30分钟以上的时间且大部分时间被用于作业分配,初始化和数据输出。M/R作业初始化的时间是比较耗时间资源的一个部分。
set hive.groupby.skewindata=true;这是通用的算法优化,但算法优化有时不能适应特定业务背景,开发人员了解业务,了解数据,可以通过业务逻辑精确有效的解决数据倾斜问题。
相同的 Group By Key 有可 能分发到不同的 reduce 中,从而达到负载均衡的目的;第二个 MapReduce 任务再根据预处 理的数据结果按照 Group By Key 分布到 reduce 中(这个过程可以保证相同的 Group By Key 分布到同一个 reduce 中),最后完成最终的聚合操作。
- 数据倾斜是导致效率大幅降低的主要原因,可以采用多一次 Map/Reduce 的方法, 避免倾斜。???
- 数据量较大的情况下,慎用count(distinct),count(distinct)容易产生倾斜问题。
- 对小文件进行合并,是行至有效的提高调度效率的方法,假如所有的作业设置合理的文件数,对云梯的整体调度效率也会产生积极的正向影响。
set hive.merge.mapfiles = true #在Map-only的任务结束时合并小文件set hive.merge.mapredfiles = true #在Map-Reduce的任务结束时合并小文件
set hive.exec.parallel.thread.number=16; //同一个sql允许最大并行度,默认为8
Hive系统内部已针对不同的查询预设定了优化方法,用户可以通过调整配置进行控制,
可以只读取查询中所需要用到的列,而忽略其它列
在编写带有 join 操作的代码语句时,应该将条目少的表/子查询放在 Join 操作符的左边。 因为在 Reduce 阶段,位于 Join 操作符左边的表的内容会被加载进内存,载入条目较少的表 可以有效减少 OOM(out of memory)即内存溢出。
INSERT OVERWRITE TABLE pv_users SELECT pv.pageid, u.age FROM page_view p
JOIN user u ON (pv.userid = u.userid)
JOIN newuser x ON (u.userid = x.userid);
所以对于同一个 key 来说,对应的 value 值小的放前,大的放后,这便是“小表放前”原则。
- 如果 Join 的 key 相同,不管有多少个表,都会则会合并为一个 Map-Reduce
如果 Join 的条件不相同,Map-Reduce 的任务数目和 Join 操作的数目是对应的
Join 操作在 Map 阶段完成,不再需要Reduce,前提条件是需要的数据在 Map 的过程中可以访问到
hive.join.emit.interval = 1000
hive.mapjoin.size.key = 10000
hive.mapjoin.cache.numrows = 10000
进行GROUP BY操作时需要注意一下几点:
hive.map.aggr=true(用于设定是否在 map 端进行聚合,默认值为真) hive.groupby.mapaggr.checkinterval=100000(用于设定 map 端进行聚合操作的条目数)
出现主键为 null 的情况,如果取其中的 user_id 和 bmw_users 关联,就会碰到数据倾斜的问题。原因是 Hive 中,主键为 null 值的项会被当做相同的 Key 而分配进同一个计算 Map。
解决方法 1:user_id 为空的不参与关联,子查询过滤 null 函数过滤 解决方法 2 如下所示: CASE WHEN a.user_id IS NULL THEN CONCAT(‘dp_hive’,RAND()) ELSE a.user_id END =b.user_id;
解决方法1中log读取两次,job 数为2。解决方法2中 job 数是1。把空值的 key 变成一个字符串加上随机数,就能把倾斜的 数据分到不同的Reduce上,从而解决数据倾斜问题。
关联通过二次排序实现的,关联的列为 partion key,关联的列和表的 tag 组成排序的 group key,根据 pariton key分配Reduce。同一Reduce内根据group key排序。
问题:不同数据类型 id 的关联会产生数据倾斜问题。
一张表 s8 的日志,每个商品一条记录,要和商品表关联。但关联却碰到倾斜的问题。 s8 的日志中有 32 为字符串商品 id,也有数值商品 id,日志中类型是 string 的,但商品中的 数值 id 是 bigint 的。
把数据类型转换成字符串类型
SELECT * FROM s8_log a LEFT OUTER JOIN r_auction_auctions b ON a.auction_id=CASE(b.auction_id AS STRING)
Hive 对 union all 的优化的特性:对 union all 优化只局限于非嵌套查询。消灭子查询内的 group by
t1 相当于一个目录,t2 相当于一个目录,对 Map/Reduce 程序来说,t1,t2 可以作为 Map/Reduce 作业的 mutli inputs。这可以通过一个 Map/Reduce 来解决这个问题。Hadoop 的 计算框架,不怕数据多,就怕作业数多。
但如果换成是其他计算平台如 Oracle,那就不一定了,因为把大的输入拆成两个输入, 分别排序汇总后 merge(假如两个子排序是并行的话),是有可能性能更优的(比如希尔排 序比冒泡排序的性能更优)。
消灭子查询内的 COUNT(DISTINCT),MAX,MIN。
SELECT FROM (SELECT FROM t1 UNION ALL SELECT c1,c2,c3 COUNT(DISTINCT c4) FROM t2 GROUP BY c1,c2,c3) t3 GROUP BY c1,c2,c3;
由于子查询里头有 COUNT(DISTINCT)操作,直接去 GROUP BY 将达不到业务目标。这时采用 临时表消灭 COUNT(DISTINCT)作业不但能解决倾斜问题,还能有效减少 jobs。
INSERT t4 SELECT c1,c2,c3,c4 FROM t2 GROUP BY c1,c2,c3;
SELECT c1,c2,c3,SUM(income),SUM(uv) FROM
(SELECT c1,c2,c3,income,0 AS uv FROM t1
UNION ALL
SELECT c1,c2,c3,0 AS income,1 AS uv FROM t2) t3
GROUP BY c1,c2,c3;
job 数是 2,减少一半,而且两次 Map/Reduce 比 COUNT(DISTINCT)效率更高。
???作业数、task数怎么定义
消灭子查询内的 JOIN
SELECT FROM (SELECT FROM t1 UNION ALL SELECT FROM t4 UNION ALL SELECT FROM t2 JOIN t3 ON t2.id=t3.id) x
GROUP BY c1,c2;
1
2
3
上面代码运行会有 5 个 jobs。加入先 JOIN 生存临时表的话 t5,然后 UNION ALL,会变成 2 个 jobs。
INSERT OVERWRITE TABLE t5
SELECT FROM t2 JOIN t3 ON t2.id=t3.id;
SELECT FROM (t1 UNION ALL t4 UNION ALL t5);
GROUP BY替代COUNT(DISTINCT)达到优化效果
关于COUNT(DISTINCT)的数据倾斜问题不能一概而论
https://blog.csdn.net/young_0609/article/details/84593316
1:尽量尽早地过滤数据,减少每个阶段的数据量,对于分区表要加分区,同时只选择需要使用到的字段
select … from A
join B
on A.key = B.key
where A.userid>10
and B.userid<10
and A.dt=’20120417’
and B.dt=’20120417’;
应该改写为:
select …. from (select …. from A
where dt=’201200417’
and userid>10
) a
join ( select …. from B
where dt=’201200417’
and userid < 10
) b
on a.key = b.key;
尽量原子化操作,尽量避免一个SQL包含复杂逻辑
可以使用中间表来完成复杂的逻辑
如果union all的部分个数大于2,或者每个union部分数据量大,应该拆成多个insert into 语句,
hive.exec.parallel参数控制在同一个sql中的不同的job是否可以同时运行,提高作业的并发
通过在条件中指定分区,来限制数据扫描的范围,可以极大提高查询的效率
https://thutmose.blog.csdn.net/article/details/52096464
create table psn1(
id int,
name String,
likes Array
address Map
)
partitioned by (sex String)
正确写法:
load data local inpath ‘/~/~/~/data.txt’ overwrite into table psn1 partition (sex=’boy’);
https://blog.csdn.net/qq_33982605/article/details/79685920
内部表,也即Hive管理的表,相对于内部表来说,其管理仅仅是在逻辑和语法意义上的,实际的数据并非由Hive本身来管理,而是交给了HDFS。当创建一个外部表的时候,仅仅是指向一个外部目录而已。如果你想删除表,只是删除表的元数据信息,并不会对实际的物理数据进行删除。创建一张简单的外部表,这里与内部表的区别是,添加了关键字external和location数据位置
分区可以让数据的部分查询变得更快,也就是说,在加载数据的时候可以指定加载某一部分数据,并不是全量的数据。
分桶表通常是在原始数据中加入一些额外的结构,这些结构可以用于高效的查询,例如,基于ID的分桶可以使得用户的查询非常的块。
分区表又分为静态分区表和动态分区表两种:
- 静态分区表:所谓的静态分区表指的就是,我们在创建表的时候,就已经给该表中的数据定义好了数据类型
partitioned by (enter_date string,country string);
这样创建表之后的表目录结构是这样的:
动态分区表:所谓的动态分区表,其实建表方式跟静态分区表没有区别,最主要的区别是在载入数据的时候,静态分区表我们载入数据之前必须保证该分区存在,并且我么已经明确知道载入的数据的类型,知道要将数据加载到那个分区当中去,而动态分区表,在载入的时候,我们事先并不知道该条数据属于哪一类,而是需要hive自己去判断该数据属于哪一类,并将该条数据加载到对应的目录中去。建表语句跟静态分区表的建表语句相同,这里不再赘述,主要来看看数据的加载:
对于动态分区表数据的加载,我们需要先开启hive的非严格模式,并且通过insert的方式进行加载数据
| 1 2 |
hive> set hive.exec.dynamic.partition.mode=nonstrict; |
|---|---|
hive> insert into table enter_country_people(user string,age int) partition(enter_date,country) select user,age,enter_date,country from enter_country_people_bak;
https://www.cnblogs.com/Gxiaobai/p/11371153.html
如果设置了mapred.reduce.tasks/mapreduce.job.reduces参数,那么Hive会直接使用它的值作为Reduce的个数;
Hive自己如何确定reduce数: reduce个数的设定极大影响任务执行效率,不指定reduce个数的情况下,Hive会猜测确定一个reduce个数,基于以下两个设定:hive.exec.reducers.bytes.per.reducer(每个reduce任务处理的数据量,默认为1000^3=1G) hive.exec.reducers.max(每个任务最大的reduce数,默认为999)计算reducer数的公式很简单N=min(参数2,总输入数据量/参数1)即,如果reduce的输入(map的输出)总大小不超过1G,那么只会有一个reduce任务;如:select pt,count(1) from popt_tbaccountcopy_mes where pt = ‘2012-07-04’ group by pt; /group/p_sdo_data/p_sdo_data_etl/pt/popt_tbaccountcopy_mes/pt=2012-07-04 总大小为9G多,因此这句有10个reduce
调整reduce个数方法一: 调整hive.exec.reducers.bytes.per.reducer参数的值;
调整reduce个数方法二; set mapred.reduce.tasks = 15

这次会话中的所有日志消息将会输出到这个日志文件中,包含SQL语句的执行日志,查看这个日志文件可以看到以下信息:
https://www.cnblogs.com/yurunmiao/p/4224137.html
未实验
https://blog.csdn.net/shudaqi2010/article/details/90288901
第四,查看分桶数据:
与分区不同的是,分区依据的不是真实数据表文件中的列,而是我们指定的伪列,但是分桶是依据数据表中真实的列而不是伪列。第一,分桶之前要执行命令hive.enforce.bucketiong=true;
???
第一,如何分桶:
第二,要使用关键字clustered by 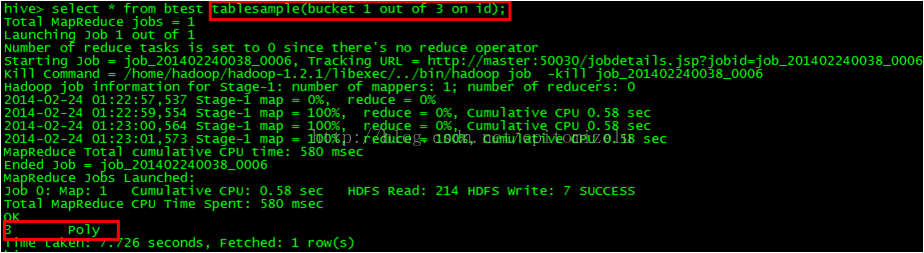
https://mp.weixin.qq.com/s?__biz=MzI2MDQzOTk3MQ==&mid=2247485048&idx=1&sn=5fc1219f4947bea9743cd938cec510c7&chksm=ea68ecb4dd1f65a2df364d79272e0e472a394c5b13b5d55d848c89d9498ccb7ea78a933fbdea&scene=21#wechat_redirect
join 优化
Common/shuffle/Reduce JOIN 连接发生的阶段,发生在reduce 阶段, 适用于大表 连接 大表(默认的方式)
Map join :连接发生在map阶段 , 适用于小表 连接 大表
大表的数据从文件中读取
小表的数据存放在内存中(hive中已经自动进行了优化,自动判断小表,然后进行缓存)
set hive.auto.convert.join=true;
SMB join
Sort -Merge -Bucket Join 对大表连接大表的优化,用桶表的概念来进行优化。在一个桶内发生笛卡尔积连接(需要是两个桶表进行join)
set hive.auto.convert.sortmerge.join=true; set hive.optimize.bucketmapjoin = true; set hive.optimize.bucketmapjoin.sortedmerge = true; set hive.auto.convert.sortmerge.join.noconditionaltask=true;[
学会查看sql的执行计划,优化业务逻辑 ,减少job的数据量。](https://www.cnblogs.com/niudaxianren/p/10018634.html)
Hive中也有执行计划,但是Hive的执行计划都是预测的,这点不像Oracle和SQL Server有真实的计划,可以看到每个阶段的处理数据、消耗的资源和处理的时间等量化数据。Hive提供的执行计划没有这些数据,这意味着虽然Hive的使用者知道整个SQL的执行逻辑,但是各阶段耗用的资源状况和整个SQL的执行瓶颈在哪里是不清楚的。
想要知道HiveSQL所有阶段的运行信息,可以查看YARN提供的日志。查看日志的链接,可以在每个作业执行后,在控制台打印的信息中找到。如下图所示: Tracking URL [
[
表现:任务进度长时间维持在99%(或100%),查看任务监控页面,发现只有少量(1个或几个)reduce子任务未完成。
原因:某个reduce的数据输入量远远大于其他reduce数据的输入量
](https://www.cnblogs.com/niudaxianren/p/10018634.html)在原分组key上添加随机数后分组聚合一次,然后对结果去掉随机数后再分组聚合
在join时,有大量为null的join key,则可以将null转成随机值,避免聚集[
将为空的 key 转变为字符串加随机数或纯随机数,将因空值而造成倾斜的数据分不到多个 Reducer。
](https://www.cnblogs.com/niudaxianren/p/10018634.html)不同数据类型关联产生数据倾斜
情形:比如用户表中 user_id 字段为 int,log 表中 user_id 字段既有 string 类型也有 int 类型。当按照 user_id 进行两个表的 Join 操作时。
后果:处理此特殊值的 reduce 耗时;只有一个 reduce 任务
默认的 Hash 操作会按 int 型的 id 来进行分配,这样会导致所有 string 类型 id 的记录都分配
到一个 Reducer 中。
解决方式:把数字类型转换成字符串类型[
数据写入hive需要repair,
hive -e \ “MSCK REPAIR TABLE ods.ods_carrecord; MSCK REPAIR TABLE ods.ods_imsirecord; MSCK REPAIR TABLE ods.ods_faceimage;”

若有收获,就点个赞吧
0 人点赞
