调优过程
https://zhuanlan.zhihu.com/p/77614511
参数调优
https://blog.csdn.net/yuanbingze/article/details/97368552
在数据统计的时候选择高性能算子。
例如Dataframe使用foreachPartitions将数据写入数据库
/
将统计结果写入MySQL中
代码优化:
在进行数据库操作的时候,不要每个record都去操作一次数据库
通常写法是每个partition操作一次数据库
/
try {
videoLogTopNDF.foreachPartition(partitionOfRecords => {
val list = new ListBuffer[DayVideoAccessStat]
partitionOfRecords.foreach(info => {
val day = info.getAsString
val cmsId = info.getAsLong
val times = info.getAsLong
list.append(DayVideoAccessStat(day, cmsId, times))
})
StatDao.insertDayVideoTopN(list)
})
批次提交一次。
for(ele <- list){
pstmt.setString(1,ele.day)
pstmt.setLong(2,ele.cmsId)
pstmt.setLong(3,ele.times)
//加入到批次中,后续再执行批量处理 这样性能会好很多
pstmt.addBatch()
}
//执行批量处理
pstmt.executeBatch()
connection.commit() /
缓存到内存中
dayVideoDF.cache()
//logDF.printSchema()
//logDF.show()
StatDao.deletaDataByDay(day)
//统计每天最受欢迎(访问次数)的TopN视频产品
一个partitions相当于一个task。这是配置当shuffle数据去join或者聚合的时候的partitions的数量。200一般情况下在生产上是不够的,需要做相应的调整。
调整并行度的方式
bin/spark-submit —class XXX.XXX.XX —name XXX —master local[2] —conf spark.sql.shuffle.partitions=230 XXX.jar
.不必要的情况下,关闭分区字段类型自动推导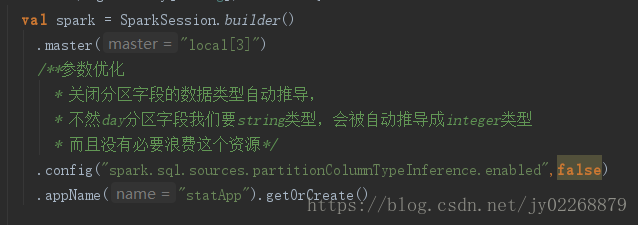

若有收获,就点个赞吧
0 人点赞
