三种统计依赖:1 直接累加 2 过去的中间结果和当天的流 3 过去的源数据和当天的流;
比如:
数据一致性和可靠性: Exactly-once semantics 处理迟到(late-arriving)数据 数据重处理(backfill)
为了彻底解决上述问题,Kafka社区也在抓紧开发Tiered Storage(KIP-405)特性。Tiered Storage采用存储与计算分离的架构,社区对这个特性非常期待。需要指出的是,Kafka的竞品Pulsar已经实现了存算分离,但为什么Kappa架构没有真正流行起来呢?也许还有其他原因。
Kappa Lamda架构
先放入数据湖在对数据库进行离线和实时分析,这个能保证实时和离线数据一致性。
[
](https://www.cnblogs.com/xiaodf/p/11642555.html)
广告投放预测这种推荐系统一般都会用到Lambda架构。一般能做精准广告投放的公司都会拥有海量用户特征、用户历史浏览记录和网页类型分类这些历史数据的。业界比较流行的做法有在批处理层用Alternating Least Squares (ALS)算法,也就是Collaborative Filtering协同过滤算法,可以得出与用户特性一致其他用户感兴趣的广告类型,也可以得出和用户感兴趣类型的广告相似的广告,而用k-means也可以对客户感兴趣的广告类型进行分类。
这里的结果是批处理层的结果。在速度层中根据用户的实时浏览网页类型在之前分好类的广告中寻找一些top K的广告出来。最终服务层可以结合速度层的top K广告和批处理层中分类好的点击率高的相似广告,做出选择投放给用户。
那就可以把 Apache Kafka 中的保留期设置为 365 天。如果你希望能够处理所有的历史数据,那就可以把 Apache Kafka 中的保留期设置为“永久(Forever)”。
与 Lambda 架构不同的是,Kappa 架构去掉了批处理层这一体系结构,而只保留了速度层。你只需要在业务逻辑改变又或者是代码更改的时候进行数据的重新处理。
在速度层上处理大规模数据可能会有数据更新出错的情况发生,这就需要我们花费更多的时间在处理这些错误异常上面。
Kappa 架构并不适用于批处理和流处理代码逻辑不一致的场景
???简单当时分析或简单增量(简单average)
单实时分析时,对历史复杂取后分享下无法处理(类复杂average)实时数仓的一个问题是历史数据只有 3-15 天,无法在其上做 Ad-hoc 的查询。
https://www.cnblogs.com/xiaodf/p/11642555.html
[
](https://www.peerislands.io/data-processing-lambda-vs-kappa-architectures-and-apache-beam/)
- Immutable append-only log: Data is stored in a system such as Kafka or Delta Lake – an immutable, append-only log of incoming data. Allows for a retention period based on requirement and data characteristics
- Speed: Use stream processing on the latest dataset and update the serving layer
- Accuracy: Only when required. Start another stream of data processing in parallel that processes the entire dataset of interest. Increase the number of parallel processing instances to account for the complete dataset size. This dataset will be more accurate and will supersede the one generated by the speed layer. You can also choose to run this only when required 两个流处理,第二个流处理分析整体数据,第二流如批处理一样
- Switch the serving layer to point to the newer dataset once processing is complete
While there are a number of implementations of this Kappa architecture, the following represents a typical implementation.
Apache Beam is an open-source, unified model for defining both batch and streaming data-parallel processing pipelines. (???通用流批一体语法,实现怎么能支撑)You can build the processing business logic in any of the support programming languages – Java, Python, Go, and many more. Once you build a data processing pipeline using Apache Beam SDK, you can use a number of supported runners for the pipeline – Apache Spark, Apache Flink, public cloud implementations such as Google Data Flow.
https://www.peerislands.io/data-processing-lambda-vs-kappa-architectures-and-apache-beam/
基于Flink Streaming Sink等相关技术,实现对HDFS文件系统的实时写入,通常将增量数据写入到数据仓库的STG或ODS层,然后基于写入的数据进行半小时或一小时作业的调度配置。
基于Flink Stream/Flink SQL等相关技术,利用实时OLAP引擎提供的Upsert功能,将实时数据增量更新到OLAP引擎中,或者将实时数据加工成宽表后实时更新到OLAP引擎中,然后在OLAP引擎上使用SQL方式进行数据计算。
基于Flink Stream/Flink SQL等相关技术,直接得到分析结果。
3、流批一体的实践( 另外一个思路 在flink后是离线数据,也能保证离线和实时一致)
ODS层实时化方向:将Kafka的数据实时写入到HDFS,已经非常普及,成为数据入仓的重要手段。
OLAP引擎实时方向:1)阿里巴巴 主要在推进 Flink + Hologres的解决方案,有一套比较推荐的方式,先通过Flink计算宽表,然后将数据写入到Hologres进行实时的聚合或点查操作。这套方向属于商业化的方案,需要付费。 2)非商业化的方案中,目前国内比较热门是 Flink + Drois 方案,类似的Flink + Kudu方案在国内的热度在下降(也可选择)。 3)基于实时OALP引擎构建完整的数据仓库,包含STG、ODS、DWD/DWS、ADS等分层模型,这个方案比价适合数据量较小的公司。
单纯使用Flink框架的方向:主要是在尝试和探索Flink SQL在流数据、批数据上的效果。
https://zhuanlan.zhihu.com/p/443319129

Data Capture & Streaming. This stage captures the required data from the source system, and converts them into data streams using either off-the-shelf DB connectors or custom connectors, depending on the source type. 1Data implements data sharding and throttling, which enable data synchronization at scale, in this phase.
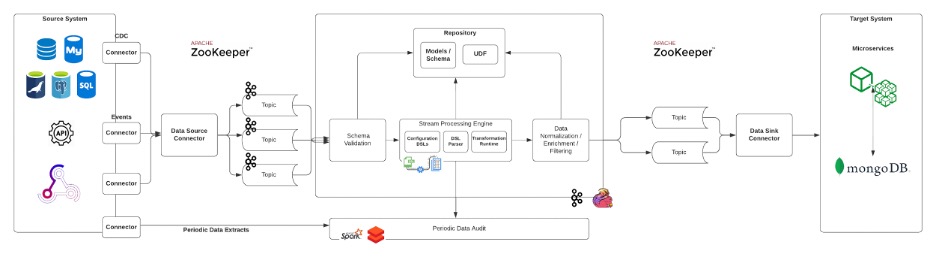
Auditing. Most data that gets migrated is enterprise-critical; 1Data audits the entire data synchronization process for missed data and incorrect updates.
Two way sync. The logical architecture can be utilized to enable data synchronization from the MongoDB database back to the source database.
https://www.peerislands.io/1data-peerislands-data-sync-accelerator/
服务器成本浪费:Kappa架构的核心原理依赖于外部高性能存储redis,hbase服务。(???为了复杂历史分析)但是这2种系统组件,又并非设计来满足全量数据存储设计,对服务器成本严重浪费。
IOTA架构
为保证实时数据吞吐,轻量Buffer机制对下游进行数据缓冲。整体最核心部分为实时增量计算。(复杂实时???)
shangyexinzhi.com/article/1921015.html

??统一逻辑表
https://zhuanlan.zhihu.com/p/385232253
https://blog.csdn.net/yunqiinsight/article/details/94433309

clickhouse 大宽表 presto、impala多表 spark sql据说回内存报错
[
](https://www.zhihu.com/zvideo/1263897491700961280)

查询队列

存储和计算分离:前提是存储自带索引???

谓词下推
基本的意思predicate pushdown 是SQL语句中的部分语句( predicates 谓词部分) 可以被 “pushed” 下推到数据源或者靠近数据源的部分.通过尽早过滤掉数据,
预查询;分区查、合

ggg 谓词注册 用bloom、事件用索引,大表用谓词下推、预查询、UDF
ggg https://www.zhihu.com/zvideo/1263897491700961280
https://blog.95id.com/ark-iota-architecture.html
https://blog.51cto.com/u_15023245/2620481
实时数据导入 Hive 数仓,Table / SQL 层的 streaming file sink 来啦,Flink 1.11 支持 Filesystem connector [1] 和 Hive connector 的 streaming sink [2]。
https://blog.51cto.com/u_15023245/2620481

SMACK架构使用Akka进行数据采集(Akka可以应对高并发和实时性要求很高的场景,非常适合IOT领域),然后将数据写入Kafka,接着使用Spark Streaming进行实时流处理,处理的结果和原始数据都写入Cassandra。到这里,所有的做法和Kappa架构是一样的。不同于Kappa架构的地方在于,SMACK架构依然保留了批处理能力,它巧妙地利用了Cassandra的多数据中心(Multiple Datacenters)特性将数据透明地冗余到两个Cassandra集群(集群1用来接收流处理结果,集群2用于批处理分析,供Spark(Spark Core或Spark SQL)读写。
原文链接:https://blog.csdn.net/weixin_41507897/article/details/112567486
分层
DM(Data Mart) 数据集市,为了特定的应用目的或应用范围,而从数据仓库中独立出来的一部分数据,也可称为部门数据或主题数据。

分布式任务
Airflow和Oozie区别
Oozie Workflow job是由多个Action组成的有向无环图(DAG)。
Oozie Coordinator job是根据时间(频率)和数据可用性触发的可重复执行的Oozie Workflow job(简单讲就是根据时间或数据条件,规划workflow的执行)。
Oozie与Hadoop技术栈的项目集成,支持多种类型的Hadoop作业(例如Java map-reduce,Streaming map-reduce,Pig,Hive,Sqoop和Distcp,Spark)以及系统特定的工作(例如Java程序和shell脚本)。
Oozie是一个可水平扩展,可靠和可使用扩展插件(scalable, reliable and extensible)的系统。
https://www.jianshu.com/p/6cb3a4b78556
airflow是一款开源的,分布式任务调度框架,它将一个具有上下级依赖关系的工作流,组装成一个有向无环图。
https://zhuanlan.zhihu.com/p/43383509
Airflow可以解决两个任务间依赖的问题(信息传递、基于信息步调设置)
集群安装和管理
Cloudera版本(Cloudera’s Distribution Including Apache Hadoop,简称“CDH”),基于Web的用户界面,支持大多数Hadoop组件,包括HDFS、MapReduce、Hive、Pig、 Hbase、Zookeeper、Sqoop,简化了大数据平台的安装、使用难度。
https://www.jianshu.com/p/106739236db4
AI
ALINk
跑批
存储
Hive保存元信息,因此数据模型不用重建,而Pig不保存元信息,因此数据模型需要重建。依赖yarn,由yarn基于任务分配资源调度。是结构化,类似关系型。小文件多,hive就hdfs集群的主节点占用太大。跑批纠正实时
由于Hive的数据模型是表结构,因此Hive是先创建表,后加载数据,而Pig的数据模型是包结构,Pig在加载数据的同时创建包。
Hive的数据模型是表,表由行和列组成,表不可以嵌套,Pig的数据模型是包,包由tuple和field组成,包可以嵌套。
https://www.cnblogs.com/lijinze-tsinghua/p/8505389.html
HBase:冷热划分(资源消耗多),查询也快,没有小文件,一个块128M,小文件多,hive就hdfs集群的主节点占用太大,hive和hbase表可互相转换,hbase设计要很好才能利用(大公司已经放弃,跑批占用cpu高时和hive比优势不大, 不支持SQL,写业务逻辑麻烦),有个phoniex使得可以支持SQL,非结构化如果字段没有就省空间
ClickHouse 存储计算是一体的,其他的都是单纯的计算框架
Impala 可参考论文: Impala: A Modern, Open-Source SQL Engine for Hadoop
Presto 可参考论文: Presto: SQL on Everything
ClickHouse 可参考官方文档: Overview of ClickHouse Architecture
Spark 可参考: The Internals Of Apache Spark
计算引擎
Pig更轻量级,执行效率更快,适用于实时分析
Pig与Hive作为一种高级数据语言,均运行于HDFS之上,是hadoop上层的衍生架构,用于简化hadoop任务,并对MapReduce进行一个更高层次的封装。Pig与Hive的区别如下:
Pig是一种面向过程的数据流语言;Hive是一种数据仓库语言,并提供了完整的sql查询功能。
Pig更轻量级,执行效率更快,适用于实时分析;Hive适用于离线数据分析。
Hive查询语言为Hql,支持分区;Pig查询语言为Pig Latin,不支持分区???。
Hive支持JDBC/ODBC;Pig不支持JDBC/ODBC。
Pig适用于半结构化数据(如:日志文件);Hive适用于结构化数据。
https://blog.csdn.net/yz930618/article/details/80689360
Pig由Yahoo开发,主要应用于数据分析,Twitter公司大量使用Pig处理海量数据,Pig之所以是数据分析引擎,是因为Pig相当于一个翻译器,将PigLatin语句翻译成MapReduce程序(最终都是)(只有在执行dump和store命令时才会翻译成MapReduce程序),而PigLatin语句是一种用于处理大规模数据的脚本语言。
Impala: 在hadoop之上,同时代产品,只能去hive查,要求hive数据存储是precite,也内存计算
spark:支持所有的数据源,依赖yarn,由yarn基于任务分配资源调度。RDD可以落盘或不落盘1 Rdd(只有数据) 2 Data set(有数据类型也有数据) 3 data frame (有schema),速度居中。
Presto是一个分布式SQL查询引擎,用于查询分布在一个或多个不同数据源中的大数据集。presto可以通过使用分布式查询,可以快速高效的完成海量数据的查询。它是完全基于内存的,所以速度非常快。presto不仅可以查询HDFS,还可以查询RDMBS数据库。
不能复杂sql,支持的少如hive,数量大时快比clickhouse快
https://www.cnblogs.com/cuishuai/p/7889813.html
Presto基于集群内存处理,基于Hive元数据,不进行mr而shuffle落盘,效率高。spark sql即使内存也没有Presto快,
议通过clickhouse来进行查询,保证查询速度,特点:数据量较小,查询速度快
针对冷数据,可以通过直接通过Spark/MR来直接查询HDFS数据,特点:数据量巨大,查询速度较慢
中等复杂sql,少量查询时速度最快 ???clickhouse是否应该和mongo比较

https://zhuanlan.zhihu.com/p/117326011
SQL&&MPP
???no-sql和sql合的mpp
NewSQL
SQL
No-SQL
对比和测试标准
https://blog.csdn.net/enweitech/article/details/44995167
我们使用Yahoo!发布的标准YCSB测试规则
mongo 速度不快、不能连表(麻烦)
- MongoDB(文档类,V2.6.1)
- SequoiaDB(文档类,V1.8)
- HBase(宽表类,V0.94.6-CDH 4.5.0)
- Cassandra(宽表类,V1.1.12)

CAP原则
一致性(C):在分布式系统中的所有数据备份,在同一时刻是否同样的值。(等同于所有节点访问同一份最新的数据副本)
可用性(A):在集群中一部分节点故障后,集群整体是否还能响应客户端的读写请求。(对数据更新具备高可用性)
分区容忍性(P):分区容错性,是指由于节点之间的网络问题,即使一些消息延迟,整个系统能继续提供服务(提供一致性或者可用性)。
首先,虽然只要是分布式系统,就可能存在分区,但分区出现的概率是很小的(否则就需要去优化网络或者硬件),CAP在大多数时候允许完美的C和A;只有在分区存在的时间段内,才需要在C与A之间权衡。
其次,一致性和可用性都是一个度的问题,不是0或者1的问题,可用性可以在0%到100%之间连续变化,一致性分为很多级别(比如在casandra,可以设置consistency level)。因此,当代CAP实践的目标应该是针对具体的应用,在合理范围内最大化数据一致性和可用性的效力。
https://blog.csdn.net/weixin_40861707/article/details/94880724
数据同步
Sqoop是一款用来在Hadoop(Hive)和关系型数据库之间传输数据的工具。有集群机制,但是只能支持同步关系型数据,不支持mongo,底层还是mr
DataX开源单机,速度,并支持mongo
DataX 是阿里开源的一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle等)、HDFS、Hive、ODPS、HBase、FTP等各种异构数据源之间稳定高效的数据同步功能。
目前开源版本只支持单机模式,需要依赖调度系统?
https://zhuanlan.zhihu.com/p/81817787

若有收获,就点个赞吧
0 人点赞
