监控
Thanos组件监控
http://gra.etcd.jd.com/dashboards/f/roTQ8bBMz/thanos
https://mp.weixin.qq.com/s?__biz=Mzg5NjA1MjkxNw==&mid=2247489464&idx=1&sn=3d021be40c572b399ac54800da1f6923&chksm=c007ac62f770257424c824aa51f2edb920a5a15f273f0b2b80f1a60933959bbffca708418a1b&scene=21#wechat_redirect
https://github.com/tkestack/kvass/blob/master/README_CN.md
Prometheus配置文件生成
https://line.github.io/promgen/index.html
| Thanos | |||
| Thanos+Kvass | |||
| victoriametrics |
**对超大规模的服务做分片
第一,我们可以不用 Kubernetes 的服务发现,自行实现一下 sharding 算法,比如针对节点级的服务,可以将某个节点 shard 到某个 group 里,然后再将其注册到 Prometheus 所支持的服务发现注册中心,推荐 consul,最后在 Prometheus 配置文件加上 consul_sd_config 的配置,指定每个 Prometheus 实例要采集的 group。
- jobname: ‘cadvisor-1’
consulsd_configs:
- server: 10.0.0.3:8500
services:
- cadvisor-1 # This is the 2nd slave
在未来,你甚至可以直接利用 Kubernetes 的 EndpointSlice 特性来做服务发现和分片处理,在超大规模服务场景下就可以不需要其它的服务发现和分片机制。不过暂时此特性还不够成熟,没有默认启用,不推荐用(当前 Kubernentes 最新版本为 1.18)。
第二,用 Kubernetes 的 node 服务发现,再利用 Prometheus relabel 配置的 hashmod 来对 node 做分片,每个 Prometheus 实例仅抓其中一个分片中的数据:
- job_name: ‘cadvisor-1’
metrics_path: /metrics/cadvisor
scheme: https
# 请求 kubelet metrics 接口也需要认证和授权,通常会用 webhook 方式让 apiserver 代理进行 RBAC 校验,所以还是用 ServiceAccount 的 token
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
kubernetes_sd_configs:
- role: node
# 通常不校验 kubelet 的 server 证书,避免报 x509: certificate signed by unknown authority
tls_config:
insecure_skip_verify: true
relabel_configs:
- source_labels: [__address]
modulus: 4 # 将节点分片成 4 个 group
target_label: tmp_hash
action: hashmod
- source_labels: [tmp_hash]
regex: ^1$ # 只抓第 2 个 group 中节点的数据(序号 0 为第 1 个 group)
action: keep
hash_mod
用 Kubernetes 的 node 服务发现,再利用 Prometheus relabel 配置的 hashmod 来对 node 做分片,每个 Prometheus 实例仅抓其中一个分片中的数据: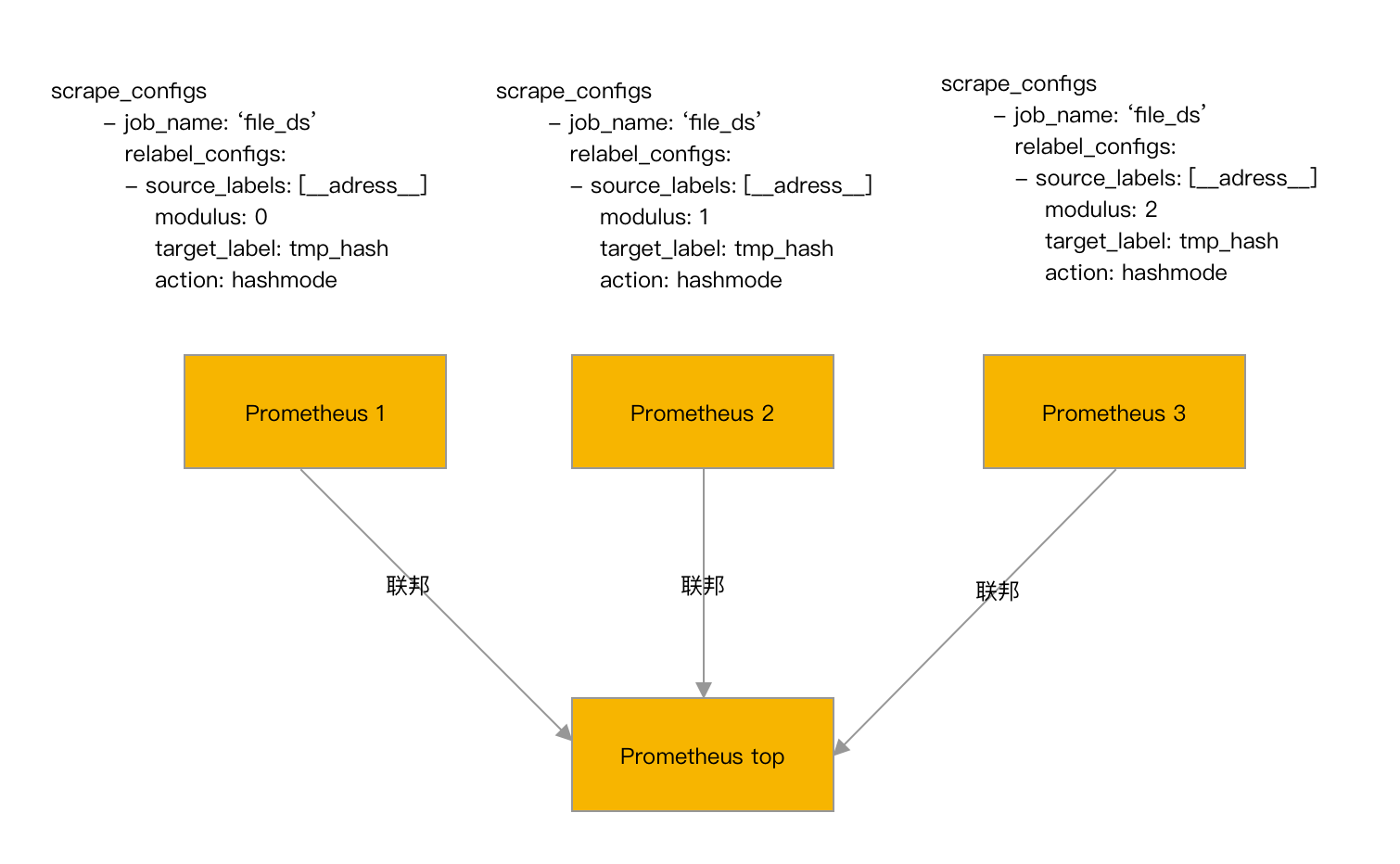
配置文件分割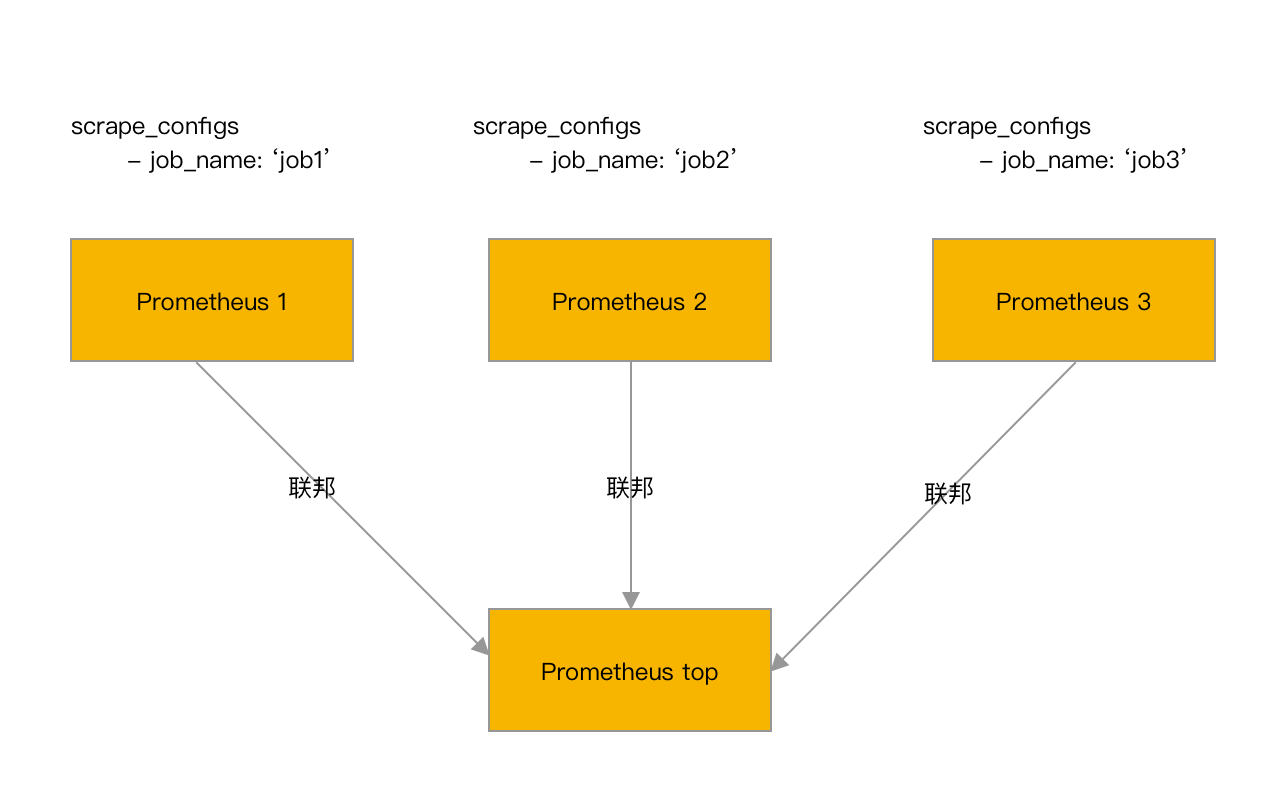
无论是hash_mod的方式,还是配置文件分割的方式,其本质都是将数据切分到多个采集配置中,由不同Prometheus进行采集。两者都存在以下几个缺点:
· 对预监控数据要有所了解:使用上述方法的前提是使用者必须对监控对象会上报的数据有所了解,例如必须知道监控对象会上报某个用于hash_mod的label,或者必须知道不同job的整体规模,才能对job进行划分。
· 实例负载不均衡:虽然上述方案预期都是希望将数据打散到不同Prometheus实例上,但实际上通过某些label的值进行hash_mod的,或者干脆按job进行划分的方式并不能保证每个实例最终所采集的series数是均衡的,实例依旧存在内存占用过高的风险。
· 配置文件有侵入:使用者必须对原配置文件进行改造,加入Relabel相关配置,或者将一份配置文件划分成多份,由于配置文件不再单一,新增,修改配置难度大大增加。
· 无法动态扩缩容:上述方案中的由于配置是根据实际监控目标的数据规模来特殊制定的,并没有一种统一的扩缩容方案,可以在数据规模增长时增加Prometheus个数。当然,用户如果针对自己业务实际情况编写扩缩容的工具确实是可以的,但是这种方式并不能在不同业务间复用。
· 部分API不再正常:上述方案将数据打散到了不同实例中,然后通过联邦或者Thanos进行汇总,得到全局监控数据,但是在不额外处理的情况下会导致部分Prometheus 原生API无法得到正确的值,最典型的是/api/v1/targets (https://prometheus.io/docs/prometheus/latest/querying/api/#targets),上述方案下无法得到全局targets值。

若有收获,就点个赞吧
0 人点赞
