Thanos+Kvass
https://github.com/tkestack/kvass
https://github.com/tkestack/kvass/blob/master/README_CN.md
服务发现
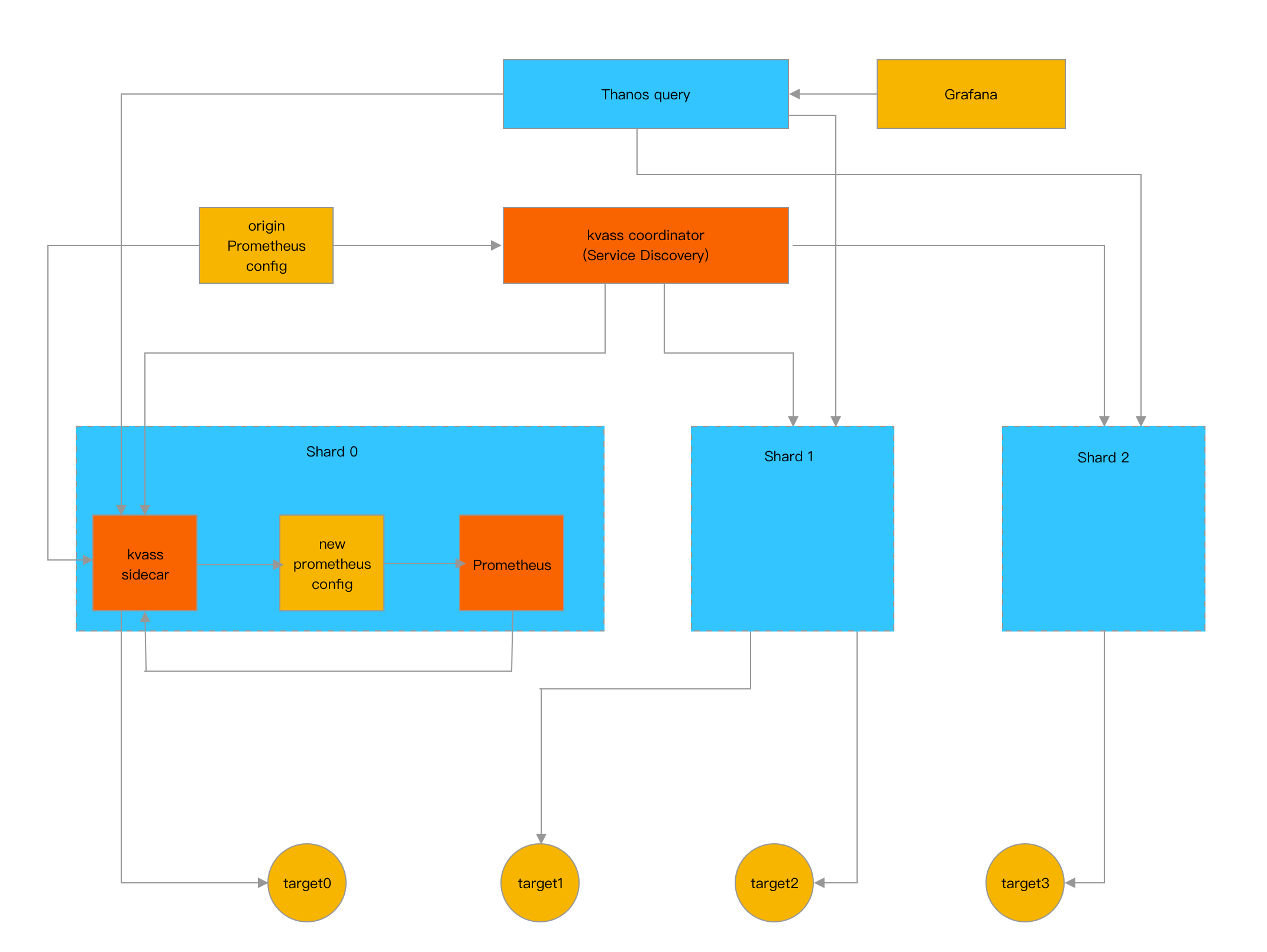
Kvass coordinaor引用了原生Prometheus的服务发现代码,用于实现与Prometheus 100%兼容的服务发现能力,针对服务发现得到的待抓取targets,Coordinaor会对其应用配置文件中的relabel_configs进行处理,得到处理之后的targets及其label集合。服务发现后得到的target被送往负载探测模块进行负载探测。
负载探测
负载探测模块从服务发现模块获得处理之后的targets,结合配置文件中的抓取配置(如proxy,证书等)对目标进行抓取,随后解析计算抓取结果,获得target的series规模。
负载探测模块并不存储任何抓取到的指标数据,只记录target的负载,负载探测只对target探测一次,不维护后续target的负载变化,长期运行的target的负载信息由Sidecar维护,我们将在后面章节介绍。
target 分配与扩容
在Prometheus单机性能瓶颈那一节,我们介绍过Prometheus的内存和series相关,确切来说,Prometheus的内存和其head series直接相关。Prometheus 会将最近(默认为2小时)采集到的数据的series信息缓存在内存中,我们如果能控制好每个分片内存中head series的数目,就能有效控制每个分片的内存使用量,而控制head series实际就是控制分片当前采集的target列表。
基于上边的思路,Kvass coordinaor会周期性的对每个分片当前采集的target列表进行管理:分配新target,删除无效target。
在每个周期,Coordinaor会首先从所有分片获得当前运行状态,其中包括分片当前内存中的series数目及当前正在抓取的target列表。随后针对从服务发现模块得到的全局target信息进行以下处理
· 如果该target已经被某个分片抓取,则继续分配给他,分片的series数不变。
· 如果该target没有任何分片抓取,则从负载探测模块获得其series(如果还未探测完则跳过,下个周期继续),从分片中挑一个目前内存中series加上该target的series后依然比阈值低的,分配给他。
· 如果当前所有分片没法容纳所有待分配的targets,则进行扩容,扩容数量与全局series总量成正比。
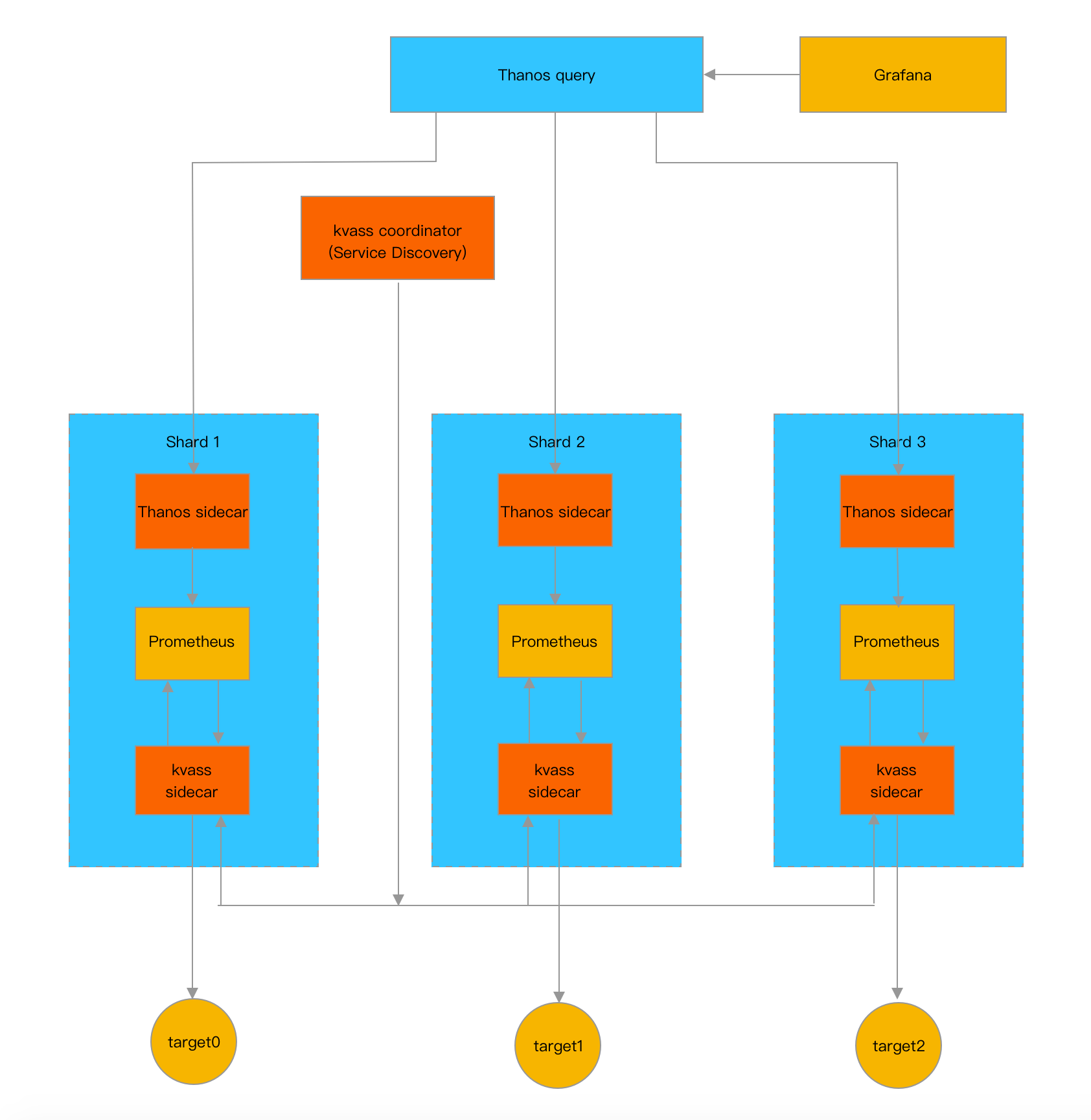
target 迁移和缩容
在系统运行过程中,target有可能会被删除,如果某个分片的target被删除且超过2小时,则该分片中的head series就会降低,也就是出现了部分空闲,因为target分配到了不同分片,如果有大量target被删除,则会出现很多分片的内存占用都很低的情况,这种情况下,系统的资源利用率很低,我们需要对系统进行缩容。
当出现这种情况时,Coordinaor会对target进行迁移,即将序号更大的分片(分片会从0进行编号)中的target转移到序号更低的分片中,最终让序号低的分片负载变高,让序号高的分片完全空闲出来。如果存储使用了thanos,并会将数据存储到cos中,则空闲分片在经过2小时后会删除(确保数据已被传到cos中)。
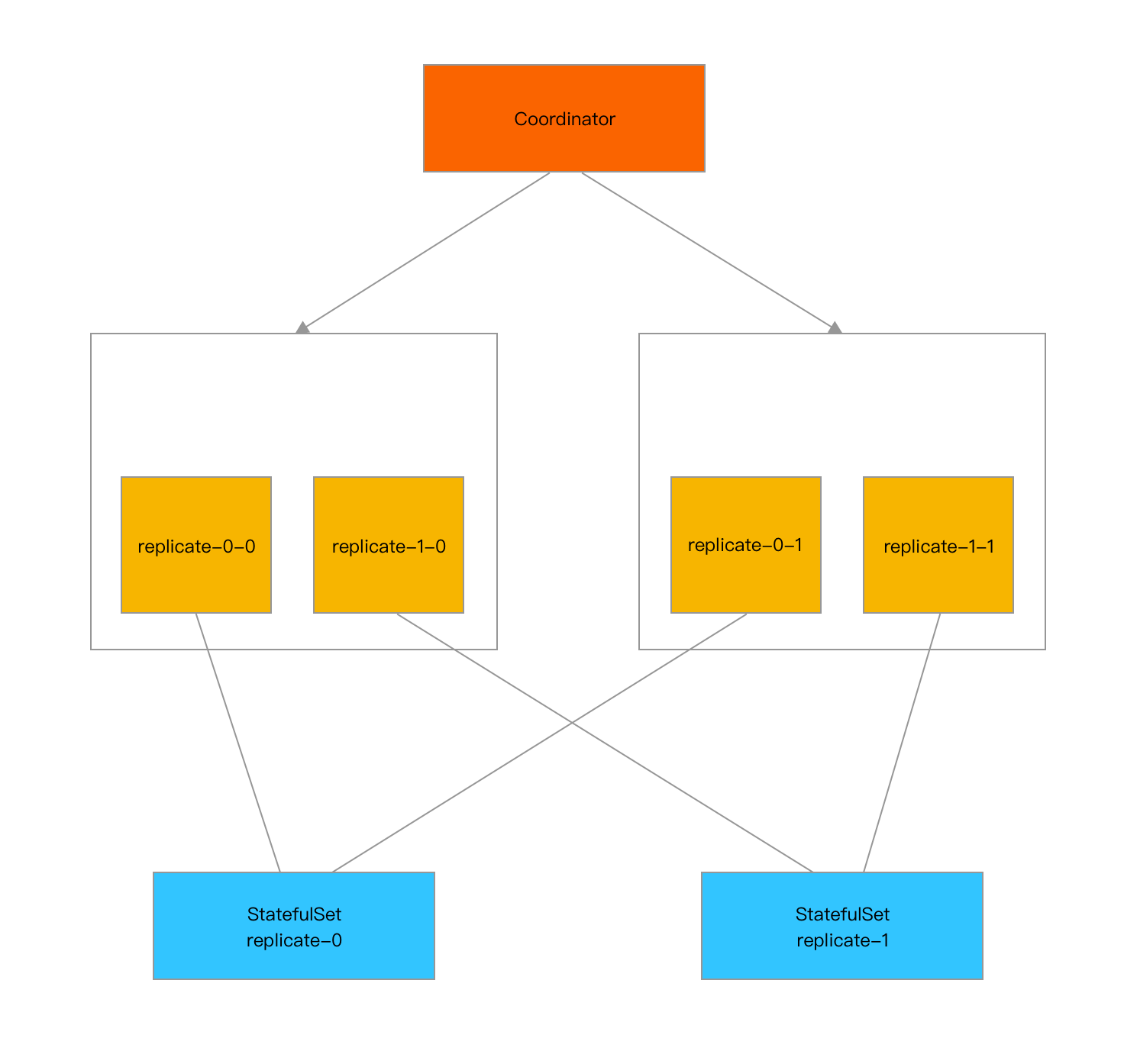
多副本
Kvass的分片当前只支持以StatefulSet方式部署。
Coordinator将通过label selector来获得所有分片StatefulSet,每个StatefulSet被认为是一个副本,StatefulSet中编号相同的Pod会被认为是同一个分片组,相同分片组的Pod将被分配相同的target并预期有相同的负载。

若有收获,就点个赞吧
0 人点赞
