本文为您介绍如何训练LoRA模型。
背景信息
Stable Diffusion(下文简称SD)是深度学习文生图的一个模型,相对Midjunery,其显著优势在于开源性。SDWebUI是SD的一个可视化浏览器操作界面,它集成了丰富的功能,不仅可以在网页端进行文生图、图生图等操作,还可以通过安装各类插件以及导入多种模型等方式,满足更高程度的定制化的绘图需求,从而生成一个较为可控的结果。 通过SDWebUI服务生成各种图片需要使用多种模型,模型的能力直接决定生成图片的效果。不同的模型具有不同的侧重点,不同模型有各自的特色与适用领域,需要针对性地采用不同的训练数据集及训练策略来培养。其中,LoRA是一种轻量化的模型微调训练方法,在原大模型的基础上对模型微调,生成特定的角色或画风。LoRA模型训练方式速度较快,模型文件大小适中,对训练的配置要求较低。 Kohya是当前应用比较广泛的训练LoRA模型的开源服务。Kohya’s GUI是一个程序包,整合了训练需要用到的环境,提供可以用于模型训练的用户界面,所有动作都在自身环境中运行,不会干扰其他的程序。在SDWebUI里也可以使用一些扩展插件去做模型训练,但如果都在SD中操作有时候会互相干扰,产生报错 。 其他模型微调方法请参见模型介绍【内测中】。准备LoRA训练数据集
确定LoRA类型
首先您需要确定希望训练的LoRA模型的类型,比如是角色类型还是风格类型。 例如,需要训练一个阿里云进化设计语言体系下的阿里云3D产品图标风格的风格模型。 ### 数据集内容要求
数据集由图片和图片对应的文本描述标注两种文件组成。
### 数据集内容要求
数据集由图片和图片对应的文本描述标注两种文件组成。
准备数据集内容:图片
- 图片要求
- 数量:15张以上(一般不小于10张)。
- 质量:分辨率适中,画质清晰。
- 风格:需要一套统一风格的图片内容。
- 内容:图片需凸显要训练的主体物形象,不宜有复杂背景以及其他无关的内容,尤其是文字。
- 尺寸:分辨率是64的倍数,显存低可以裁剪为512512,显存高可以裁剪为768768。
- 图片预处理
- 质量调整:图片分辨率适中即可,保证画质清晰,但也无需太大。画质会影响模型训练的结果。如果自己准备的图片分辨率比较小,不是很清晰,可以使用SD WebUI中Extra页面中进行分辨率放大,也可以使用其他图像处理工具去处理图像的分辨率。
- 尺寸调整量调整:可以前往像birme这种站点批量裁剪后批量下载,也可以使用SDWebUI裁剪或手动裁剪。
- 图片部分准备完毕示例
 将图片存放至本地文件夹中。
将图片存放至本地文件夹中。
创建数据集并上传文件
上传前需要注意文件的属性和命名要求,如果只是用平台管理数据集文件或者给图片打标,直接上传文件或文件夹都可以,对这些文件和文件夹的命名没有特殊要求。 如果数据集打标完之后,需要用平台的Kohya做LoRA模型训练,对于上传的文件属性和命名要求如下。- 命名格式:数字+下划线+任意名称
- 命名含义:自定义。
- 数字:每张图片重复训练次数,一般要求≥100。总训练次数一般要求>1500,因此若文件夹内包含10张图片,则每张图片训练1500/10=150次,图片文件夹名数字部分可为150;若文件夹内包含20张图片,则每张图片训练1500/20=75(<100)次,图片文件夹名数字部分可为100。
- 任意名称:本文以100_ACD3DICON为例,您可以根据实际情况自定义。
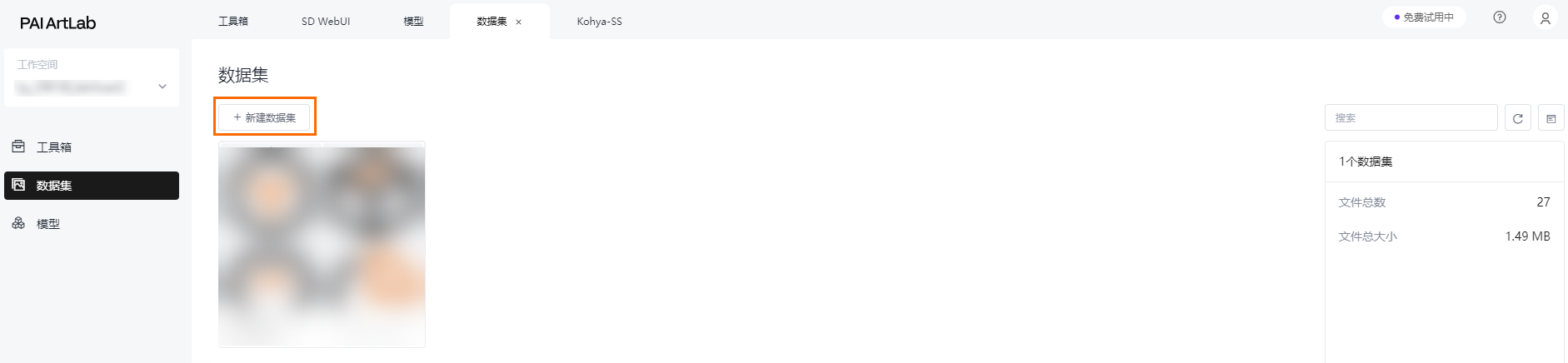
- 创建数据集在数据集页面,单击新建数据集,并输入数据集名称,此处以acd3dicon为例。
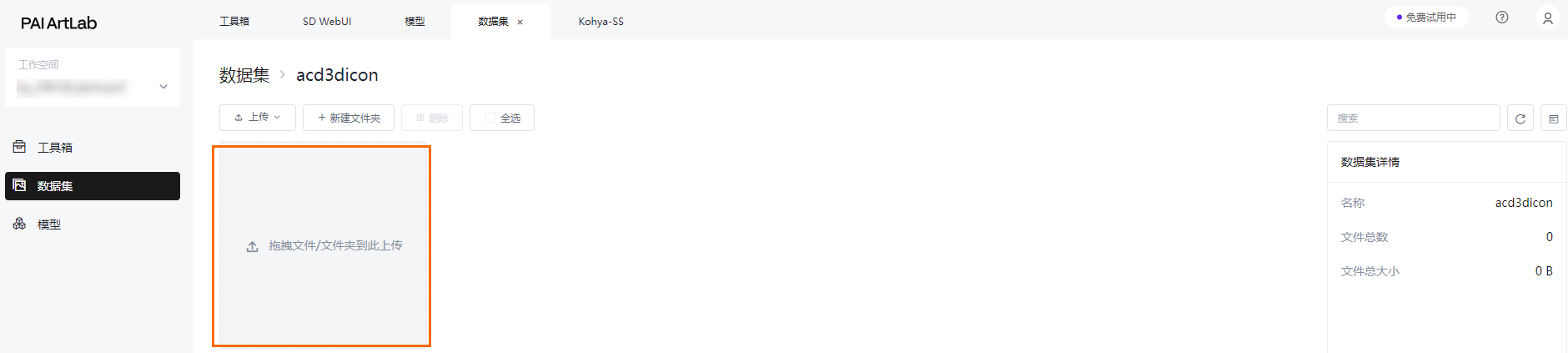
- 上传数据集文件单击已创建的数据集,将整理好的数据集图片文件夹从本地拖拽上传。
 上传成功。
上传成功。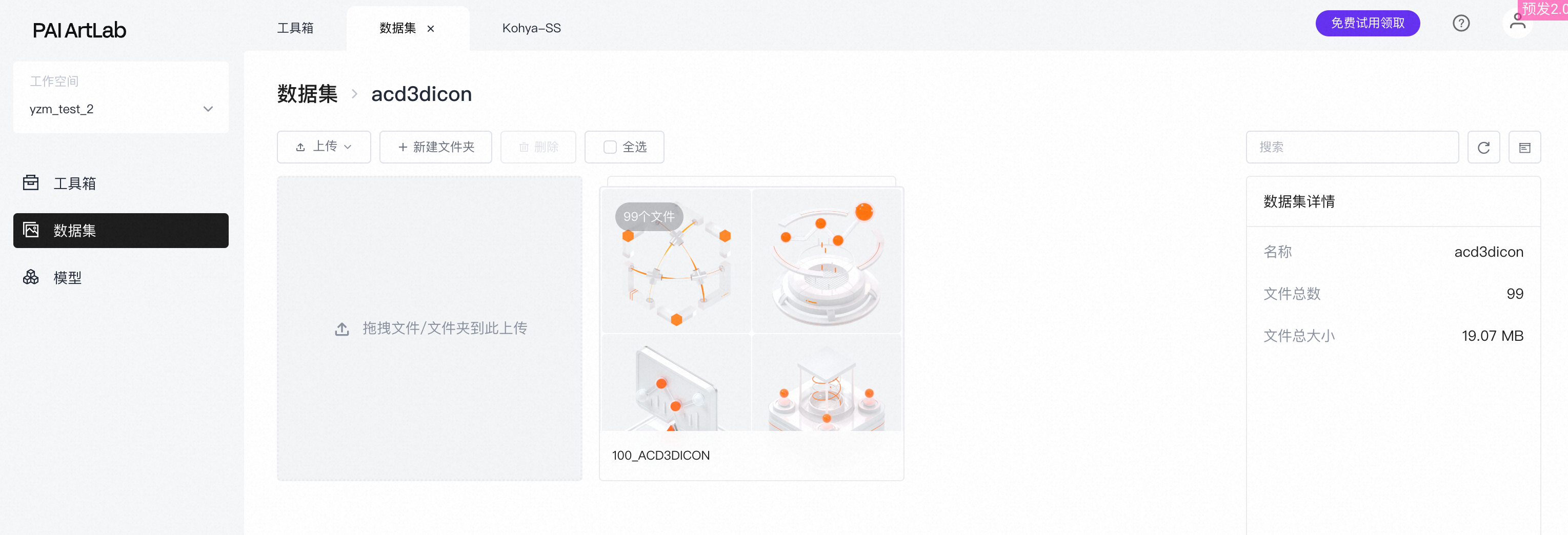
- 进入到文件夹里可以查看到已上传的图片。
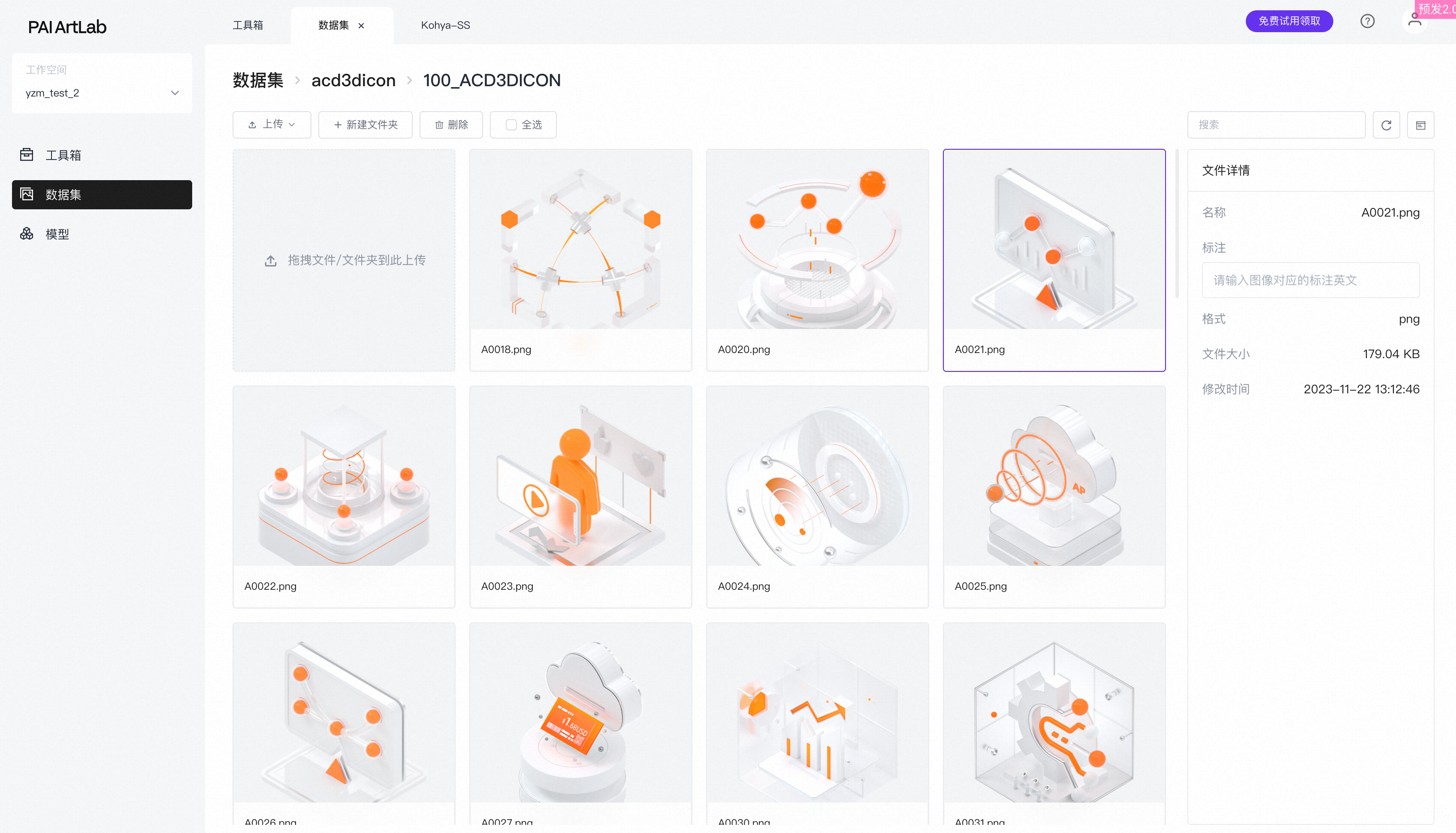
准备数据集内容:图片标注
图片标注是指每张图片对应的文字的描述,文字描述的标注文件,是与图片同名的TXT格式的文件。- 图片标注要求例如,针对这类3D图标画面打标的信息维度的拆分。
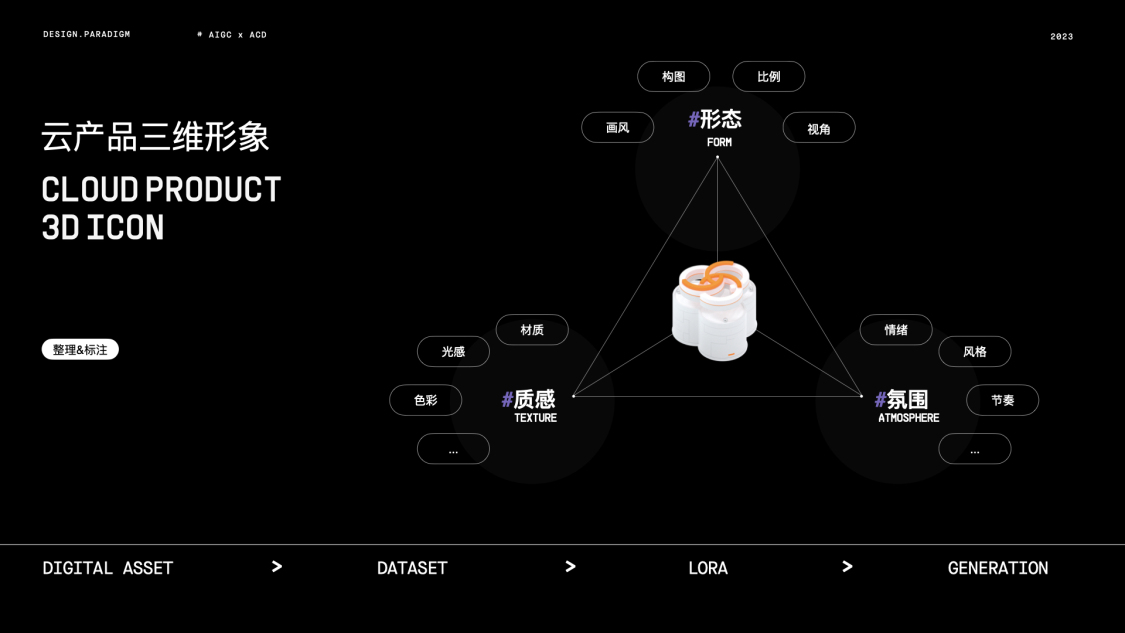
| 分类 | 关键词 | ||
|---|---|---|---|
| 业务 | 产品/业务 | 数据库、云安全、计算平台、容器、云原生等(英文) | |
| 云计算元素 | Data processing、Storage、Computing、Cloud computing、Elastic computing、Distributed storage、Cloud database、Virtualization、Containerization、Cloud security、Cloud architecture、Cloud services、Server、Load balancing、Automated management、Scalability、Disaster recovery、High availability、Cloud monitoring、Cloud billing | ||
| 设计(质感) | 环境&构图 | viewfinder、isometric、hdri environment、white background、negative space | |
| 材质 | glossy texture、matte texture、metallic texture、glass texture、frosted glass texture | ||
| 照明 | studio lighting、soft lighting | ||
| 色彩 | alibaba cloud orange、white、black、gradient orange、transparent、silver | ||
| 情绪 | rational、orderly、energetic、vibrant | ||
| 质量 | UHD、accurate、high details、best quality、1080P、16k、8k | ||
| 设计(氛围) | … | … |
- 给图片添加标注您可以手动为每个图片添加对应的文字描述,但当图片量非常大的情况下,手动打标非常耗时耗力。此时您可以选择借助神经网络,完成对所有图片批量生成文本描述的工作。您也可以在Kohya中选择使用一个叫做BLIP的图像打标模型。
打标数据集
- 在Kohya-SS页面,选择Utilities>Captioning>BLIP Captioning。
- 选择已创建的数据集里面上传的图片文件夹。
- 输入一些预置词,这是让机器给每一张图片都批量加上您输入的标注文本。您可以结合自己对数据集图片拆分的维度去添加预置词,不同类型的图片打标的维度也不同。
- 单击Caption Image即可开始打标。
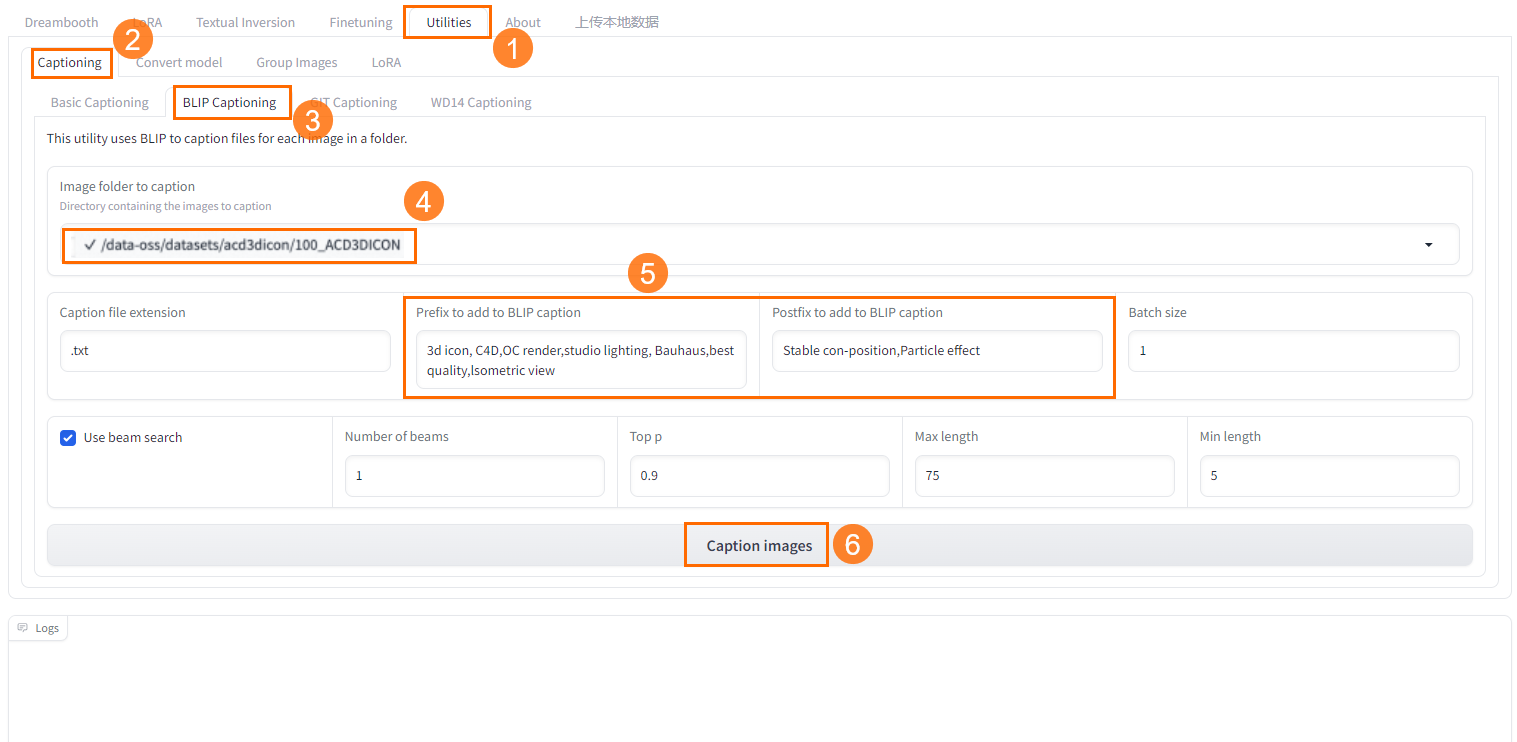
- 在下方的日志里可以查看打标的进度和打标完成的提示。
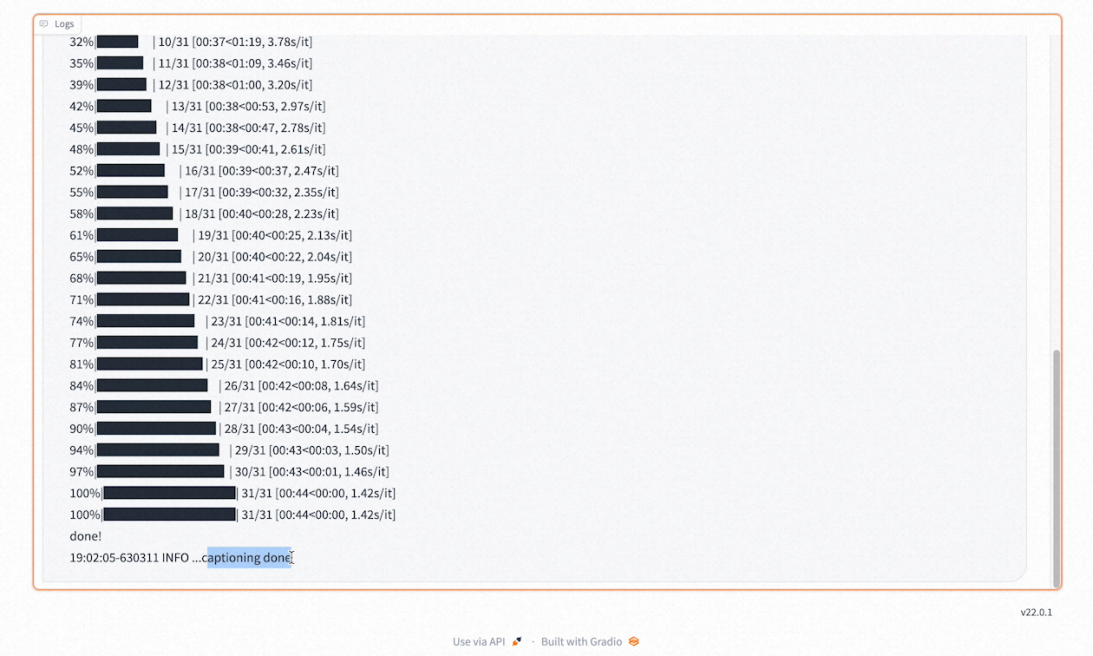
- 再返回到数据集里面,可以看到刚才上传的图片已经有对应的标注文件。
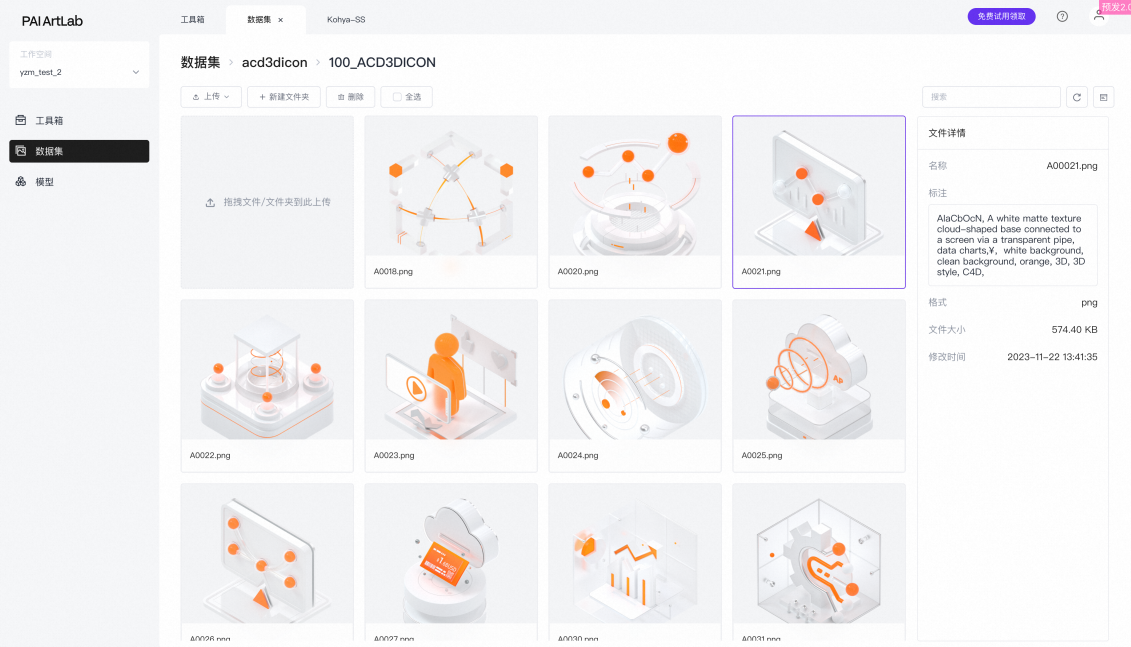
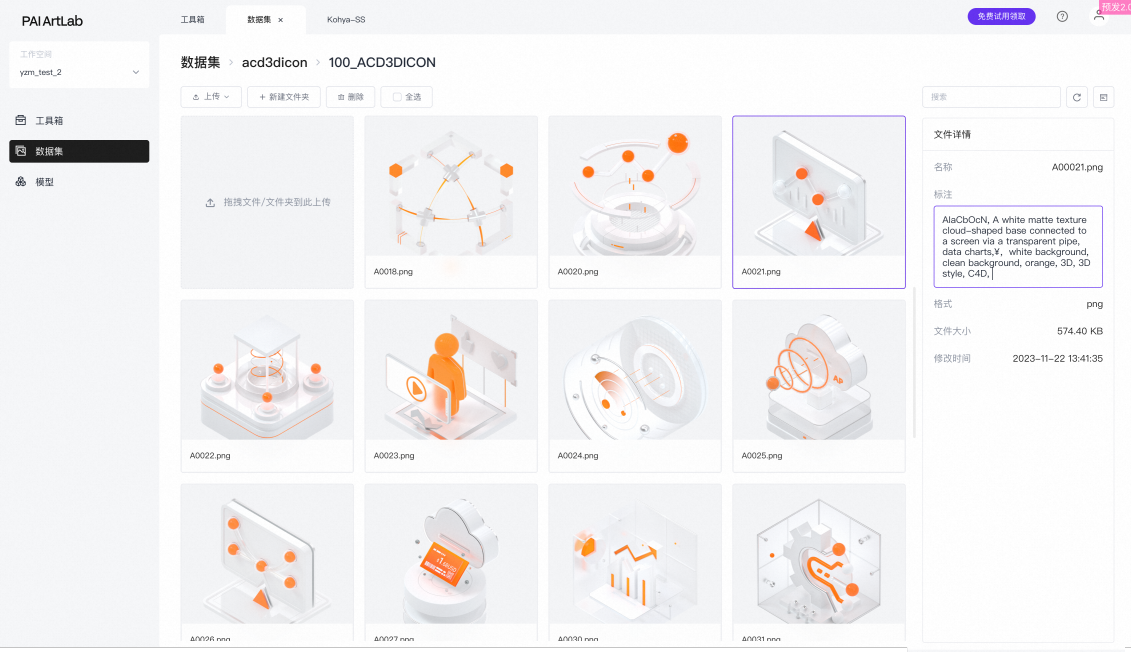
- (可选)对于不合适的标注可以手动修改。
kohya实操:LORA模型训练1
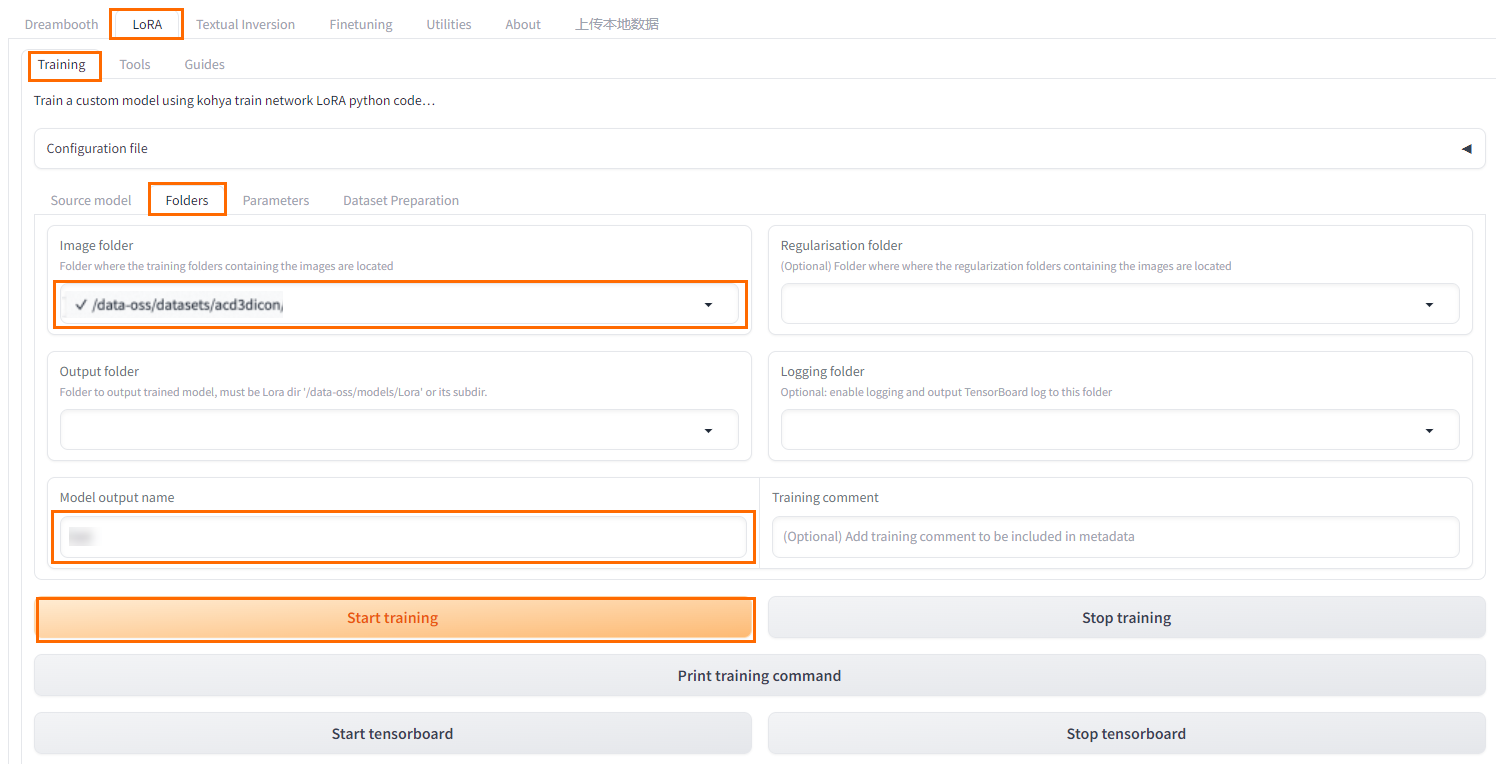
- 在Kohya-SS页面,选择LoRA>Training>Folders。
- 选择已上传了数据集文件夹的数据集。说明数据集文件打标时,要选到数据集下面图片的文件夹;做模型训练时,要选择放置数据集文件夹的数据集。
- 设置训练参数。
- 单击Start training。
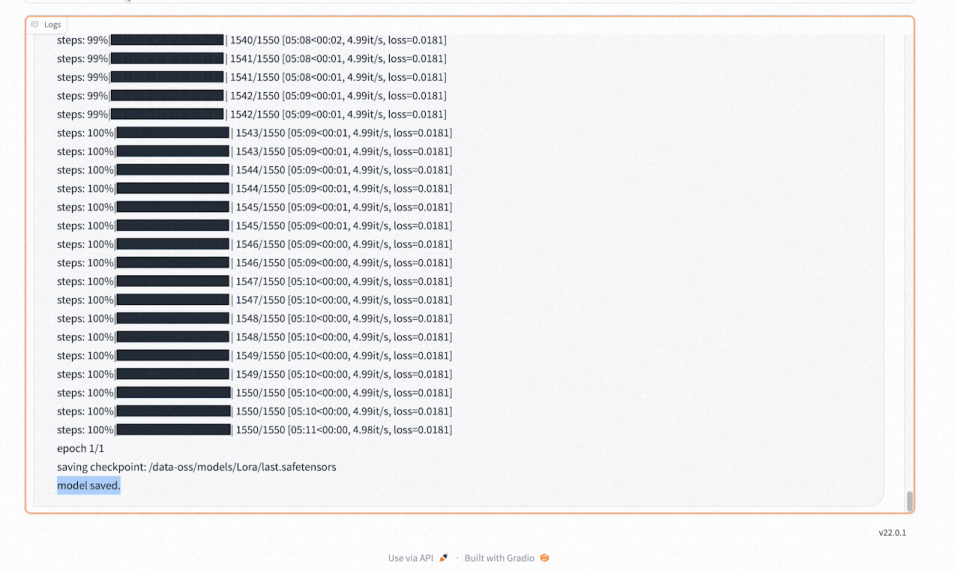
- 在下方的日志里可以查看模型训练进度和模型训练完成的提示。
kohya实操:LORA模型训练2
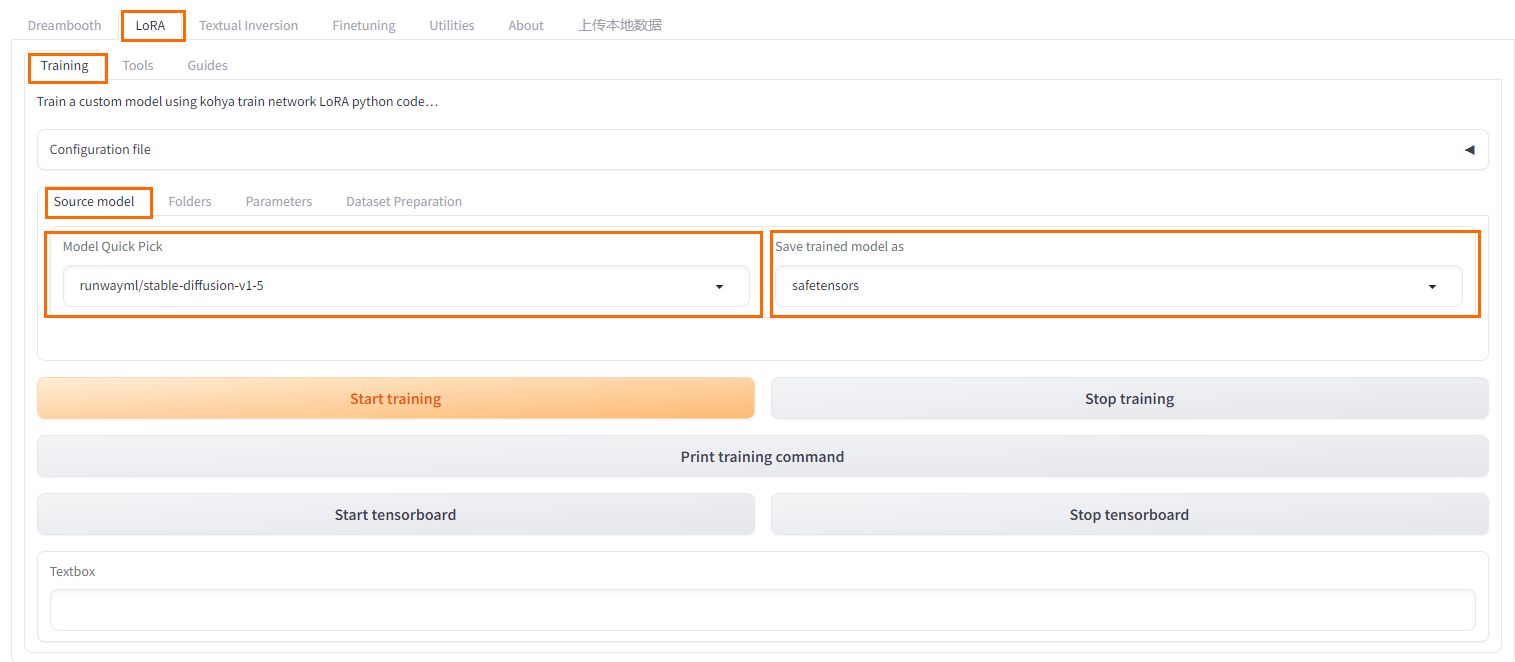
- 在Kohya-SS页面,选择LoRA>Training>Source model。
- 选择训练模型和模型类型。本文以safetensors为例,相比较checkpoint来说更具有安全性。
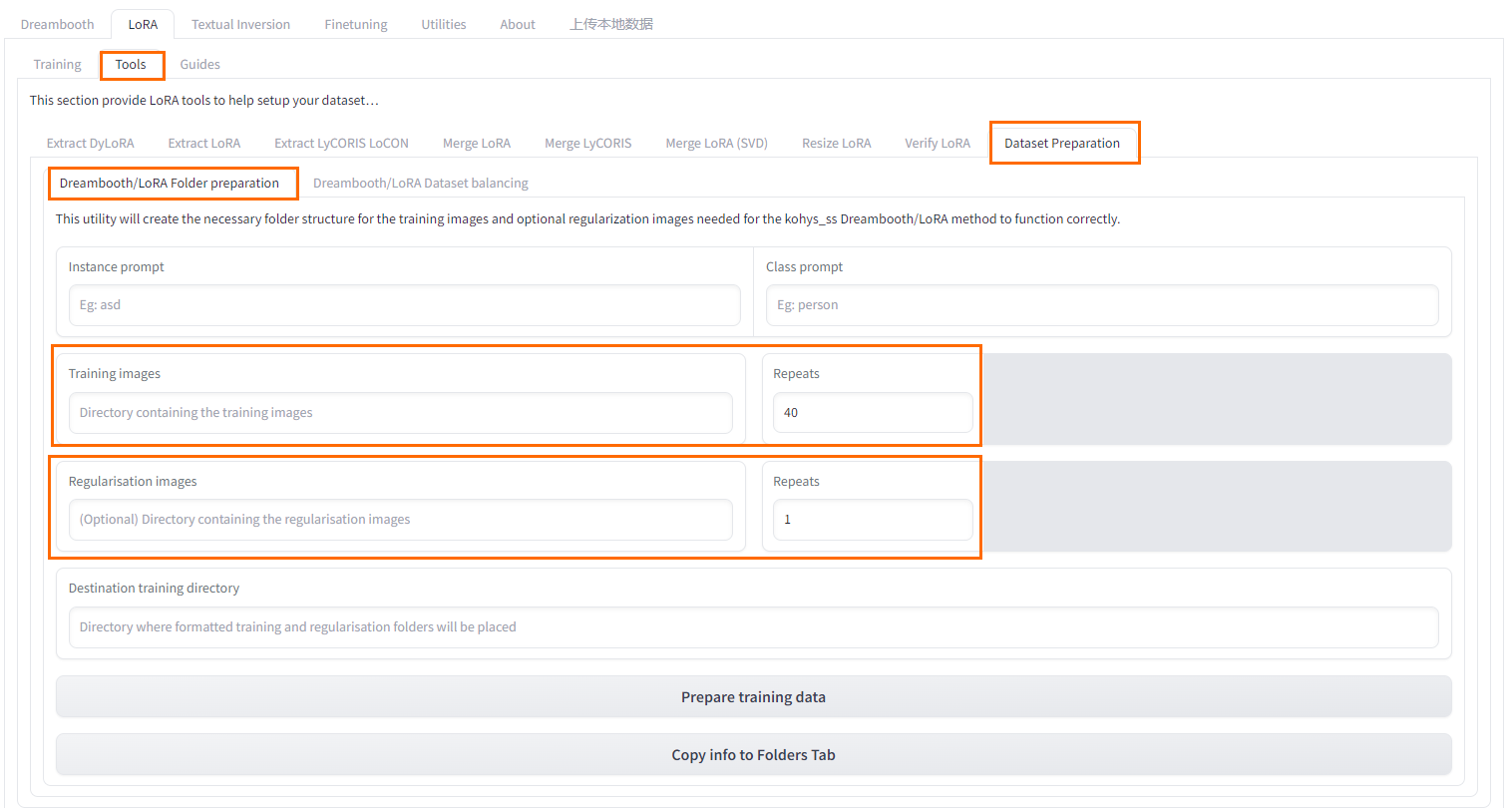
- 在Kohya-SS页面,选择LoRA>Tools>Dataset Preparation>Dreambooth/LoRA Folder preparation。
1. 填写各项
Instance Prompt(必填项):实例名称。
ClassPrompt:类别提示词(必填项),使用类别图像才会用到。
Training images:训练素材所在路径(文件夹)。
Regularisation images:类别图像所在路径(文件夹)。
Destination Training Directory:训练结果输出路径(文件夹)。
Repeats:重复每张图片训练次数。
+ 无类别图像:准备10张训练素材图片,重复值设为上10下1,一个训练周期(epoch)=10x10=100。
+ 有类别图像:若有训练素材与类别图像素材数量比为1:100,即1张训练素材图用到100张类别图像素材,上方训练重复值设为100,下方类别图像重复设为1。上方训练重复次数=每张训练图片使用的类别图片数量,下方类别图像重复无特殊需求一般设置为1。
 2. 准备数据&转到文件夹
2. 准备数据&转到文件夹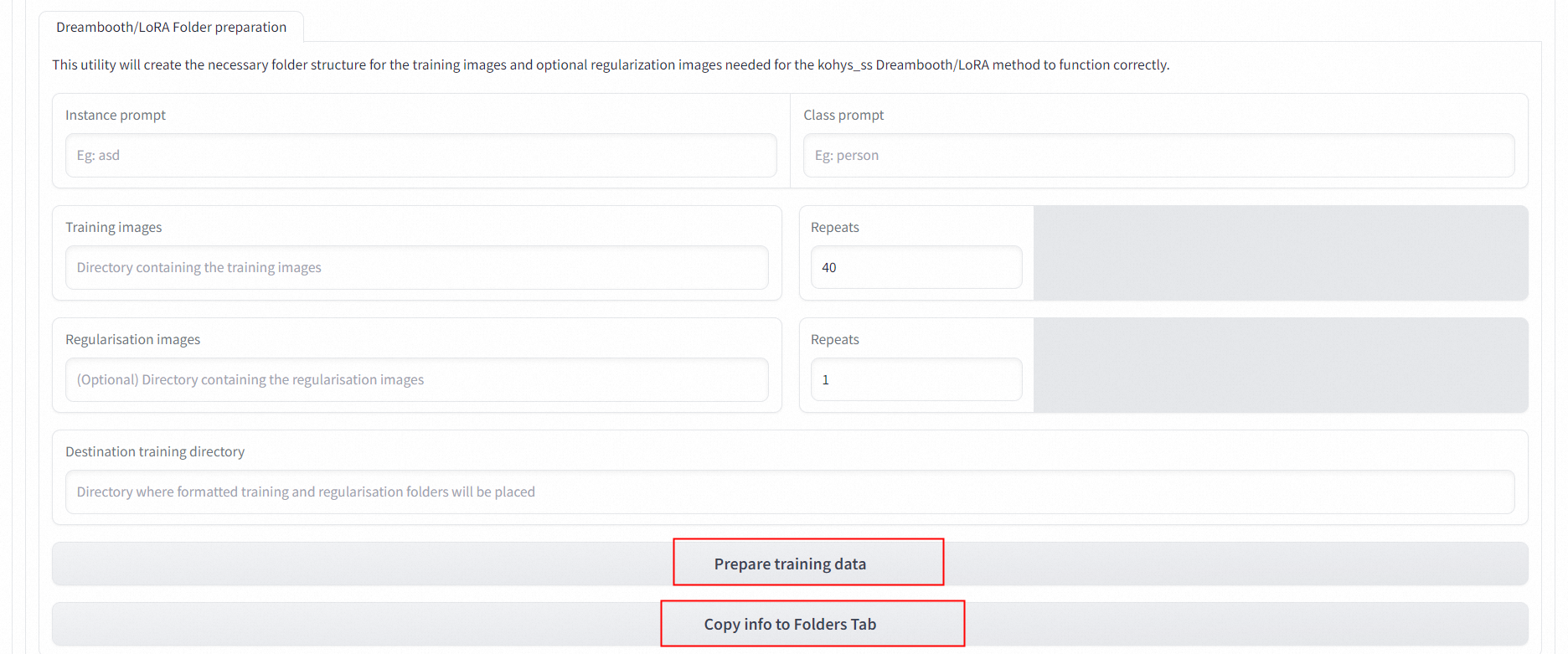 上述部分完成后单击Prepare training data和Copy info to Folders Tab,将本页填写信息转到Folder页面。
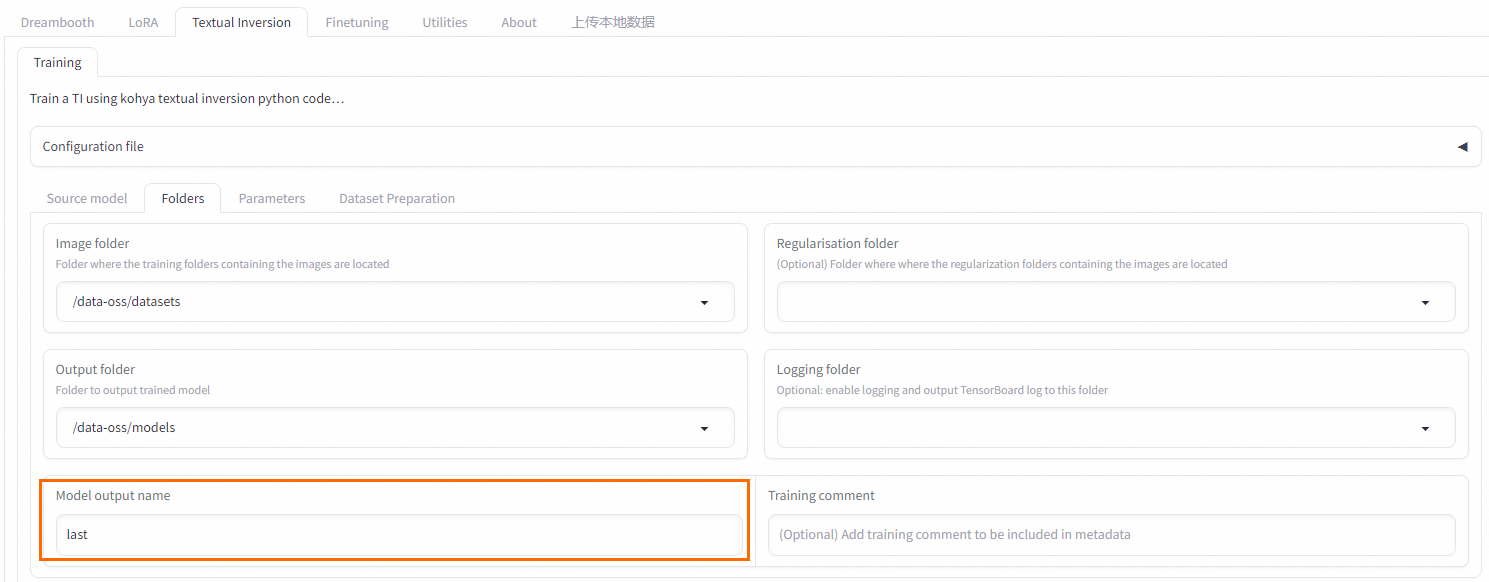
上述部分完成后单击Prepare training data和Copy info to Folders Tab,将本页填写信息转到Folder页面。 - Folder页面查看复制的信息,填写训练模型输出文件名。
Training Parameters 部分常用训练参数介绍说明
| 参数 | 功能 | 设置说明 |
|---|---|---|
| 参数 | 功能 | 设置说明 |
|---|---|---|
| LoRA Type | 选择LoRA类型 | + LoCON:可以调整SD的每一层如Res,Block,Transformer。 + LoHA:同样大小处理更多信息。 |
| LoRA network weights | LoRA网络权重,如果要接着训练则选用最后训练的LoRA | 选填。 |
| Train batch size | 训练批量大小 | 根据显卡性能,12 GB显存最大为1,8 GB最大为2。 |
| Epoch | 训练轮数——将所有数据训练一次为一轮 | 自行计算。一般: Kohya中总训练次数=训练图片数量x重复次数x训练轮数/训练批量大小。 WebUI中总训练次数=训练图片数量x重复次数。 使用类别图像时,在Kohya或在WebUI中总训练次数都会乘2;在Kohya中模型存储次数会减半。 |
| Save every N epochs | 每N个训练周期保存一次 | 如设为2,则每完成2轮训练保存一次训练结果。 |
| Caption Extension | 打标文件扩展名 | 选填。 训练图集中注解/提示文件的格式,.txt。 如图: 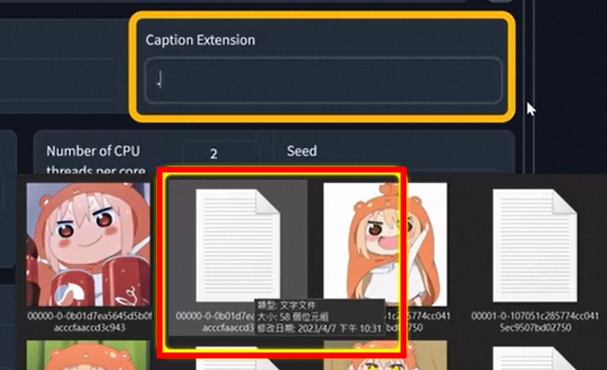 |
| Mixed precision | 混合精度 | 视显卡性能决定。默认可选no、fp16、bf16。30以上显卡可选bf16。 |
| Save precision | 保存精度 | 同上。 |
| Number of CPU threads per core | CPU每核线程数 | 主要为显存,根据所购实例和需求调整。 |
| Learning rate | 学习率 | 默认0.0001。 |
| LR Scheduler | 学习率调度器 | 下拉列表,按需选择cosine或cosine with restart等函数。 |
| LR Warmup(% of steps) | 学习预热步数 | 按需调节,默认为10,可以选不要(0)。 |
| Optimizer | 优化器 | 按需选择,默认AdamW8bit,DAdaptation自动操作。 |
| Max Resolution | 最大分辨率 | 根据图片情况。 |
| Network Rank (Dimension) | 模型复杂度 | 一般默认可设64能适应大部分场景。 |
| Network Alpha | 网络Alpha | 建议可以设小,rank和alpha设置影响最终输出lora大小。 |
| Convolution Rank (Dimension) & Convolution Alpha |
卷积度 | Lora对模型的微调涵盖范围。根据LoRA Type不同做调整。 Kohya官方建议: LoCon:dim<=64,alpha=1(或更低) LoHA:dim<=32,alpha=1 |
| clip skip | 文本编码器跳过层数 | Clip跳过,二次元选2,写实模型选1,动漫模型训练最初就有跳过一层,如使用训练素材也是二次元图像,再跳一层=2。 |
| Sample every n epoch | 每n轮样本 | 每几轮保存一次样本。 |
| Sample Prompts | 提示词样本 | 提示词样本。需要使用命令,参数如下: + —n:提示词、反向提示词。 + —w:图片宽度。 + —h:图片高度。 + —d:图像种子。 + —l:提示词相关性(cfg)。 + —s:迭代步数(steps)。 |

若有收获,就点个赞吧
0 人点赞
