by: Hazel Hu
在SD模型训练中,训练集对模型的性能起着至关重要的作用。训练集主要是由是图像及其对应的文本描述组成。
今天主要和大家分享的是,如何选择训练集的图片,描述文本打标部分将在之后单独写篇文章分享。
在选择训练集图片时,我们主要从3个方面来进行图片的收集和清洗:图片内容,图片质量,图片数量及尺寸。
1、图片内容
1.1、多样性
训练集图片保持多样性主要有以下几大好处:
::提升泛化能力,
::多样性的训练集可以帮助模型更好地捕捉不同的数据分布,模型能够从不同类型、样式和情境的数据中学习到普遍性的特征和模式。具有良好泛化能力的模型可以从已学到的知识中抽象出通用性的规律,从而在处理新的、未见过的数据时表现出色,它更有可能生成具有多样性和创新性的图像,因为它已经学习到如何适应不同的情况。
::避免过拟合,
::一个训练集包含的数据越多样,模型就越不容易过拟合。过拟合可能导致模型仅仅记住了训练集中的特定样本,而无法在新数据上表现良好。
::适应多种场景和样式,
::模型可以学习到适应不同场景、样式和风格的能力。这可以使模型在生成时更灵活地融合和转换不同的特征。
注意:相对于泛化能力而言,适应多场景和样式这是一种更具局部性的能力,它要求模型能够捕捉到特定背景或场景中的特征和元素,然后根据这些信息生成相应的图像。提升泛化能力是一种关于模型在新数据上的表现的整体性能,而适应多种场景样式则侧重于模型在特定情境下生成适合于该情境的图像。
那在实际操作的时候,我们要如何做呢?下面以我做的一个戒指设计模型为例:
::需要注意这个多样性程度基本上是根据你训练目的来决定的::。
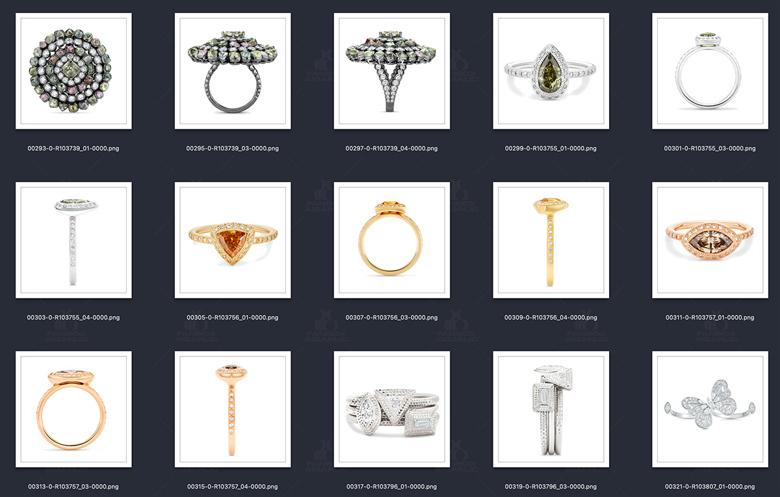
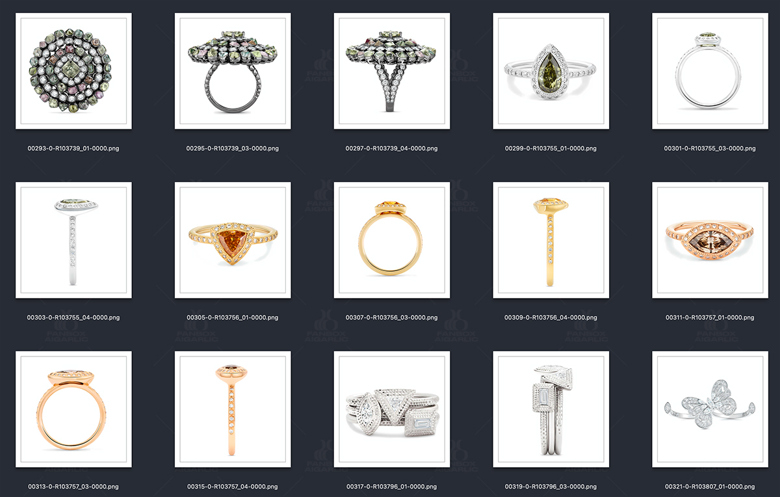
比如我在设计这个模型的时候,我希望能控制一下内容:戒圈款式,戒圈材质,宝石种类,切割方式,副石,镶嵌方式,视角等。那么我在准备训练集的时候,势必要保障训练集都能覆盖这些方面。因此,为了让我收集素材更具有目的性,提升找图的效率,我拆分这些分类下常见的类型,整理了一份表格,作为收集素材和打标的基础。
下面展示一下部分拆分的维度以及训练集的截图:


上面戒指模型可能相对垂类,如果是换成我们最常见的人物角色模型,那么维持训练集的多样性可以参考以下维度(具体需要哪些,也是根据训练目的来的,你想控制什么,那么最好包含该类型的训练样本,并不是所有类型的样本都需要):
角色:一般来说,角色特征主要是通过头部来体现,因此在训练的时候需要多角度的头像,比如正脸,侧脸,低头,抬头等。
景别:特写(人体肩部以上)、近景(人体胸部以上)、中景(人体膝部以上)、全景(人体的全部和周围部分环境)、远景(被摄体所处环境)
服饰:款式多样,比如官方服装,正装,休闲装,泳装等,颜色也要多样。
表情:开心,难过,微笑等等,可点击此处查看B站up收集的一些表情名称。
视角:正视图、侧视图、俯视图,仰视图等
动作:站立,走路,叉腰等等,可点击此处查看B站up收集的一些动作名称。
1.2、一致性
一般来说,一致性大多数指的是风格的一致性,比如水彩风,野兽派画风,莫兰迪色,产品摄影,时尚摄影,或者特定的艺术家风格诸如此类的。
但实际上不同的训练任务,一致性的表现可能在其他地方有所体现,如背景的一致性,环境场景的一致性,元素的一致性等等。
那么训练集保持一致性有什么好处呢?
::降低噪声,训练加速:::一致性强的训练集可以降低训练数据中的噪声和干扰,模型更容易学习到真实的特征和模式,而不会被不相关的变化干扰,更快地收敛。 ::生成更稳定,风格保持更完整:::一致性强的训练集可以帮助模型理解特定的样式、规律和特征。这有助于模型在生成时保持稳定性,不会在不同生成中产生过大的变化,同时在面对一些不完整的输入变化时进行填补,从而生成更加连贯统一的图像。
保持一致性并不意味着所有图像都是完全相同的,而是在一定程度上,训练集中的图像在某些特定特征方面保持相似性,以帮助模型聚焦在任务的关键方面。不同的任务和应用目的可能需要在不同的特征上保持一致性。
比如说,我在训练戒指模型的时候,我希望他们能够在背景,色调,构图等保持一致性,因此,我基本找的都是纯白色背景,带着小阴影这样的样本。但是,我又希望他们在戒指本身的款式,宝石种类,切割方式上进行调整,因此该部分的我选择了很多不同样式的戒指,丰富样本的多样性。
需要注意的是,一致性过强的训练集可能会限制模型的泛化能力,使其在面对未见过的情况时表现不佳。对于需要具有较强的泛化能力模型,引入一些多样性和变化可能是更为合适的做法。因此,我们结合实际的任务,决定在哪些维度上需要保持一致性以及在一致性保持程度是很重要的。
1.3、注意事项
除了多样性和一致性外,我们图片内容还要注意什么呢呢?
a、主体
不要遮挡主体关键特征,这会影响到模型学习效果,可能会出现一些奇奇怪怪掉san的东西。作为一般规则,尽量避免选择手离人脸太近的图像,除非你就是为了让模型学习这个特征。
不要选择主体被切割的图片,比如说,四肢展示不完整,这样会导致模型生成身体部位错位的人。或者一个场景中一个圆形的主体被切了一部分,此时它在模型先验认知中不是一个圆形了,但是你还是标注为圆形,这样让模型混淆。因此,选图时尽可能保证主体物局部的完整性。
以下为一些不利于学习脸部特征的案例:

b、背景
清洗掉任何包含太多元素或杂乱的图像,尽可能选择简单的,具有规律的背景,这样可以让模型更加关注人物和物体本身,而不被背景变化干扰,且过于复杂的背景在标注描述上会很难表达清楚画面内容。
避免透明背景,尽管透明背景可以解决一些问题,但是他会产生一些其他问题。第一,透明背景处理不好,会在主体旁边留下一些边缘线或者边框,而模型在学习的时候可能把这个特征也学习上。第二,泛化问题,都是纯色背景也可能有这个问题,因为只见过这种,所以后期很难生成其他相对复杂的背景。我们可以在训练集里面加含有透明背景或者是纯色背景的图,但是不能够全部都是,除非你就是想要生成的图像都是这样的。
c、水印、logo、和文本
请务必从图片中删除任何水印、logo和文本,无论多小,因为这些东西都会被当成图像学习,如果PS都没办法处理的,那么干脆就把它删掉。
2、图片质量
2.1、清晰度
一般来说,清晰度首先看图像的分辨率,分辨率越高,能包含的细节就越多,从人像上来说,就是能清晰看到皮肤纹理,发丝等等细节,当然要注意,分辨率高的不一定就是合适的,比如磨皮过度的。
此外要避免图片伪影,图片伪影是啥呢?
图像伪影(Image Artifact)是指原本被拍摄物体并不存在而在图像上却出现各种形态的影像。在图像处理后,尤其在合成图片中,表现为不自然的、能让人看出是人为处理过的痕迹、区域、瑕疵等。
常见的图像伪影包含:
重影,在某些情况下,由于光线的反射、折射等,在主体图像旁边或周围出现明显的、重复的、虚幻的图像副本。这些副本可能比主体图像稍微模糊或透明。
振铃伪影,由于图像处理过程中的信号过程或滤波引起的。例如,过度锐化图像可能会导致该现象,它通常出现在图像的锐利边缘附近以伪边缘形式出现。
运动模糊,拍摄运动中的物体时,可能出现运动模糊,导致图像中的物体轮廓模糊不清。
简而言之,就是要选择轮廓清晰的,主体分界线明显的图片。
2.2、其他衡量标准
除了清晰度之外,还可以根据以下维度对训练集图片进行清洗:
图像对比度,高对比度图像具有明显的黑白分界,而低对比度图像可能会显得灰暗和模糊。适当的对比度可以增强图像的清晰度和细节。
色彩准确度,颜色失真或色偏可能会影响图像的真实感,且适当的色彩平衡可以保持图像的自然感。
图像亮度,适当的亮度可以使图像中的亮暗区域都有适当的细节,但过度曝光或欠曝光可能会导致图像细节丢失或不清晰。
3、图片数量及尺寸
3.1、图片数量
训练集所需的图片数量其实没有什么统一的标准,因为这个取决于你想要模型学习的概念的复杂程度。当然要想效果好,当然是图片数量越多越好,但是请注意宁缺毋滥。
相较于总体的数量而言,图片各类型的配比可能是更加难以把控的。一般来说,最好采取均衡原则,比如,各景别配比,各服装配比等等,但这也不是绝对的,比如说有些服装简单,有些服装复杂,那么复杂的可能需要更多的样本量等等,可以先跑一个模型出来,然后进行分析,针对性补充训练集。
3.2、图片尺寸
在尺寸方面,其实现在训练脚本都是支持自动分桶,系统根据它们的分辨率和纵横比将它们放在不同的桶里。但是,经过测试,如果分辨率过于随机以及多种,可能会导致模型质量降低。因此最好,采用同样的分辨率,或者平衡分布,比如横版,竖版,正方形都是1:1:1。
一般来说训练集的尺寸可以采用,512512,512768,768768,768512,1024*1024,可根据自己硬件水平选择,一般来说选择64倍像素的图片都可以。
最后,任何的指南都是仅供参考。多实践才是王道,一个失败的LoRA教给你的东西会更多。
额外分享一个我找训练集图片的神仙的网站:haveibeentrained
该网站包含SD V1.5的训练集LAION-5B的图片资源,以图搜图就可以找到很多同类型的素材。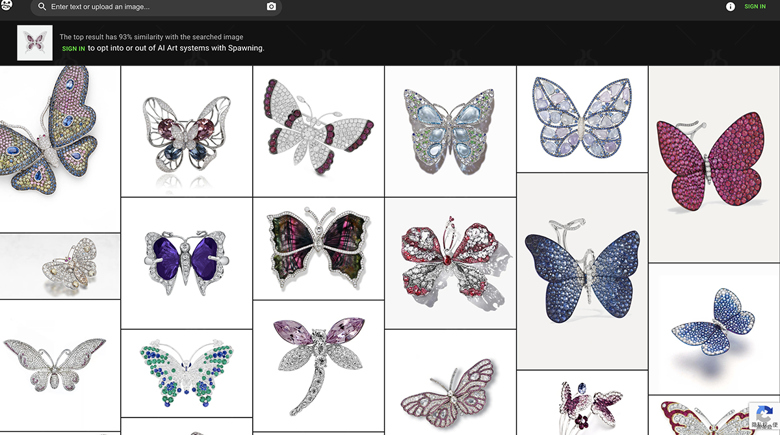

若有收获,就点个赞吧
0 人点赞
