https://civitai.com/articles/2056
介绍
通过阅读本文,您将较为详细地了解包括
- 训练脚本对数据集的二次加工;
- WebUI 部分内部算法;
- 数据集的加工和维护;
- 负面文本嵌入的制作;
- 文本嵌入模型的相互转换;
- 模型融合的原理和常见模型融合算法;
- ……
1 训练集
1.1 预处理器
通常,在您人工修饰完训练集后,训练脚本将接手进一步处理训练集。本节将介绍训练脚本是如何完成这一过程的。
训练脚本会 (1) 处理图像标注;(2) 分桶图像;(3) 缓存潜变量。本节将详细讲解这些内容。
1.1.1 标注转向量
训练脚本将图像标注处理为 SD 模型可读取的向量形式,在训练中成为模型输入。在训练中,这一过程通常发生在每一步训练时,或如果启用缓存文本标注,则发生在训练开始前。
一段文字描述转变成为模型可接受输入的过程是 (i) 使用分词器(tokenizer)打碎并翻译文本为词元,常以词元的 id 储存,(ii) 将所有的词元合并为一个词嵌入(embedding)。该词嵌入可被模型接受。
1.1.2 自动宽高比分桶
自动长宽比分桶,Aspect Ratio Bucket,简称 ARB,是一项 允许不同宽高比例分辨率的训练图像存在于统一训练集中 的技术。它将 接近 同一宽高比的图像划分到相同的“桶(bucket)”中,分别进行训练。
ARB 使训练图像得以完整地投入训练,不仅缓解了 由于图像裁剪导致的畸形问题,如断剑、人体畸形、裁切不良等,还 节省了裁图的工程量,且目前为止还未发现明显缺点。
早期的 SD 模型,如 SD1.5,通常采用方形 512x512 分辨率的图像训练,加上机器学习领域偏好方图为训练素材以方便对图像作压缩和变换,这一时期的训练通常使用 512x512 的方图训练。而这并不必要,您可以使用任意分辨率和宽高比例的图像训练,且只要保证图像的宽和高都是 8 的倍数(受模型本身要求)即可。SDXL 模型在训练中也使用了 ARB,具体分辨率如图 1 所示,并取得了很棒的结果。
在训练中,依次训练所有桶,对于每个桶,取出批次大小(batch size)数量的图像进行训练。对于桶中多余不足一个批次的图像,则以较小的批次大小训练。
注:SDXL 论文提出了将训练图像的分辨率作为额外输入训练模型,Kohya 训练脚本具有此功能。
下文将从易到难地介绍分桶算法的实现。
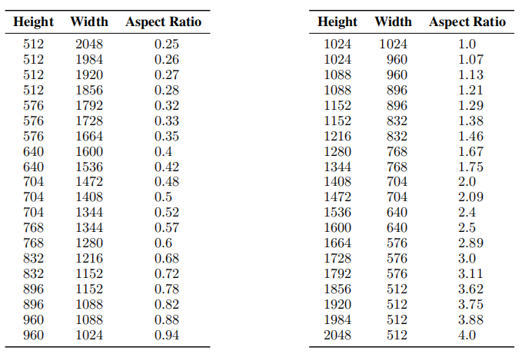
图 1:SDXL1.0 模型训练中所使用的 ARB 分桶比例图表。
分桶算法
分桶算法有很多种,有能力的读者也可以自己撰写自己的分桶算法。分桶算法的基本思想是,在不过度破坏原图比例的情况下,将原图缩小至某个特定的像素量。这里,像素量 = 宽 x 高。
每个“桶”就是一个 特定的分辨率,例如 512x768,所有训练集中分辨率最接近 512x768 的图像都会被扔进该桶。
分桶算法一
- 输入:最大分辨率 (max_w x max_h),一些图像
- 对于每张图像,将图像 等比缩放 至宽 x 高恰好等于最大分辨率后,按照将缩放后图像的分辨率,将它归入桶中。
接下来,优化分桶算法一,使其输出图像的宽和高均能被某个整数 d 整除,以满足模型对输入图像宽高的要求。这里,d 常为 32 或 64。
分桶算法二
- 输入:最大分辨率 (max_w x max_h),一些图像,除数 d
- 对于每张图像:(i) 首先计算出像素量恰好等于最大分辨率,且宽高比等于该图像分辨率的尺寸,记为宽 w 和高 h。(ii) 之后,逐渐减小 w 和 h 至恰好能被 d 整除,记该衰减后的宽和高为 w’ 和 h’。(ii) 最后,将图像缩放至 w’ x h’,并放入桶 w’ x h’ 中。
在实践中,我们会遇到部分训练图像的像素量低于最大分辨率的情况。这时,我们通常不希望放大它们。为了解决这一问题,我们有分桶算法三。
分桶算法三
- 输入:最大分辨率 (max_w x max_h),一些图像,除数 d
- 对于每张图像,在分桶算法二的基础上,额外判断原始图像的像素量是否已经小于最大分辨率,若是,则跳过算法二的步骤 (i),直接将 w 和 h 设为原始图像的尺寸。
如要自行定义分桶,例如,复刻 SDXL 的分桶,则可以采用分桶算法四。
分桶算法四
- 输入:一些桶,一些图像,除数 d
- 定义宽高比为 宽除高,则每张图像和桶均具有一个宽高比。分桶时,对于每张图像,为它匹配 宽高比最接近的桶 并放入。如果图像分辨率不匹配,则将图像缩放为桶的分辨率后再放入。
Kohya 训练脚本的分桶算法
Kohya 系训练脚本是一种稍微更复杂的分桶算法。青龙、秋叶的脚本均属此类。这里将介绍帮助读者手算的简化算法。
Kohya 分桶算法 - 简化版
- 输入:最大分辨率 (max_w x max_h),一些图像,除数 d
- 记 max_area = max_w x max_h。
- 对于每张图像,如果该图像的宽 imgw 乘高 img_h 大于 max_area,记 img_area = img_w x img_h,那么该图像将 能被 d 整除地 被分入桶 ( img_w × (max_area/img_area) x _height × (max_area/area)) 之中。
- 如果该图像的像素量小于 max_area,则该图像将 能被 d 整除地分入桶 img_w × img_h 之中。
注:此处的分桶算法为禁用 upscale 的情况。这种情况下,另两个分桶算法的输入,即最大分辨率 max_resolution 和最小分辨率 min_resolution,不会产生实际效果。
原版的 Kohya 分桶算法在计算细节上进行了优化。
技巧
- 合理分配桶的数量。桶过多,每个桶中图像少,其中多余不足一个批次的图像将以更低的批次大小训练,从而干扰训练且拖慢训练速度;桶过少,每个图像可供选择的宽高比变少,有的图像不得不经过不良缩放或裁切以适应桶的尺寸。经验法则是,训练图像越多,桶可以越多,反之。
- (需要较强的代码基础)模拟分桶。用类似的算法模拟自己所用脚本的分桶方式,以提前得知图像经过处理后的状态,检查是否有不良缩放和裁切。或提前手动分桶以保证裁切前后图像完好。推荐使用 Lanczos 采样方法以高质量地缩放图像。
1.1.3. 缓存潜变量
缓存潜变量,cache latents,是常见的训练提速方式。我们知道,SD 模型最终训练的是潜变量,潜变量由 VAE 编码图像而得到的,可以简单地认为潜变量为 缩小原始图像至原来的 1/8 得到的压缩图像(具体缩放倍数取决于 VAE)。
在不缓存潜变量时,每一步训练都需要 VAE 解码训练图像来获得潜变量图像,非常耗时。将解码后的潜变量预先存储起来,方便训练期间调用即缓存潜变量。存储这些潜变量需要额外的显存开销,因此这一技术是以显存换取时间。
普通的缓存潜变量仅在运行期间单次有效。因此,将潜变量保存为本地文件后,后续训练中便无需再次缓存。
1.2 数据集
1.2.1 数据缺失
在训练某种概念,特别是风格训练时,往往会出现训练图像数量不足的情况。在训练集有限的情况下,我们常考虑用以下方法扩充训练集:
- 在训练中启用 随机水平翻转。这将在训练中随机水平翻转训练图像。该参数应当总是对训练有帮助的。
- 特写裁切。将分辨率过大的图像裁切出各种分辨率下的特写。例如,从远到近,可将一张图像加工为整图、人物特写、半身特写和面部特写。其中,尽量保证裁切后分辨率不小于训练时的分辨率,且裁切出的内容能独立成图。该方法在训练图充足时也是有效的,特别是对于风格学习。推测是因为越贴近原图分辨率的训练图所带有的风格信息越丰富。裁切图像的有用工具如网站 Birme, Fotor;软件则如 Microsoft Photos, Photoshop。
- 相似图补充。添加类似风格的其他图像。如用写实填充写实,用油画填充油画。但必须与原图具有相当的相似度,否则将画蛇添足。一种道听途说的方法是将这些补充图像用作正则化图像参与训练,而不与真正的训练集混淆,即以一个更低的学习率对待它们,而与原风格越不相似的图像,学习率应该越低。
1.2.2 画面损伤
在训练中,SD 模型会敏感地学习到图像上的无用信息,例如污渍、水印、不完整的剑等等,为成品模型带来缺陷。如果您坚持使用这些图像,那么学习如何正确应对这些情况对您至关重要。
除了裁切和手绘修补,我们还可以采用内补绘制来修复图像损伤。现存的内补绘制模型能应对大部分情况。以下是一些常用内补绘制方法和模型:
- PS 内容识别填充:PS 自带的的内容识别填充功能将能解决大部分的小范围图像损伤,如去除小型的水印或多余的物体等。该功能识别选区附近的内容来填补所选区域的内容。如果填补的区域周围为纯色或为具有规律的图案纹理的效果更佳;
- PS 魔术橡皮擦:同上,为内补绘制算法。更擅长“去除”某个物体。较低版本的 PS 中似乎无此功能;
- PS AI:与 PS 内容识别填冲相比,AI 识别填充更胜一筹,效果是所有方法中最好的,且能够修补大范围损伤。缺点是需要付费,且速度较慢;
- SD 内补绘制模型:众所周知。速度慢,效果一般,未来可期;
- OpenCV:速度快,效果差,需要一定的编程能力。模型对应 Python 的 cv2 库。使用参考见:OpenCV: Image Inpainting
- Lama Inpainter:速度适中,效果一般,需要较强的编程能力。推荐用于 批量地重绘某个区域,在给定一批图像时,该区域可设为某个固定区域,或由某个目标检测(如 YOLOv5)或分割模型选择。
除了正确地处理图像损伤,在大量图像中检测它们也非常重要。以下提供一些检测图像内容损伤的思路:
- 利用脚本检查图像标注:要求一定的编程基础。如果对数据集进行了标注,则可利用脚本检测图像标注中是否存在与内容损伤有关的关键词,例如“watermark”, “signature”等。
- 利用 AI 技术检测图像内容:要求较强的编程基础。可以使用一些 AI 模型检测图像是否包含内容损伤。如 YOLOv5 等。
1.2.3 图像重复
重复的图像对训练几乎没有影响。可如果您执意想要去重,且具有较强的编程基础,则可以考虑使用本节将介绍的算法思路。
考虑到训练集图像较多,若使用常规的相似度比较算法则会变得复杂且耗时。因此,本节使用 感知哈希算法(Perceptual Hashing Algorithm)。感知哈希算法为每个图像计算一个哈希值,称为 感知哈希(Perceptual Hash),作为图像的“身份证”。相似图像的感知哈希非常接近。不同感知哈希值的差异大小通过汉明距离(Hamming Distance)衡量。缩放图像几乎不会改变感知哈希,而裁切图像会。
一个感知哈希通常可以表示为一个 16 进制的字符串,该字符串可作为哈希表(字典)的键。下文照此思路,提供一个简单的感知哈希去重算法,用于去重一些图像。对于重复图像,该算法删除分辨率较低的一者。
感知哈希去重算法
- 输入:一些图像
- 建立一个空的哈希表(字典)
- 为训练集中的每个图像计算一个感知哈希,以其作为键,图像(或图像文件的路径)作为值,添加到哈希表中。在构造过程中,键冲突的两个图像即为完全重复的图像,保留分辨率高者即可。
注:无需通过计算汉明距离判断图像相似。因为感知哈希的精度受哈希尺寸的影响,所以,我们只需将感知哈希的尺寸由原先的 8 减小至 6,即可模糊化地去重。
2 WebUI 的部分技术原理
2.1 生成过程预览的原理
在图像生成过程中,我们无法直接观测到潜变量。只有在经过 VAE 的解码后,我们才能查看图像内容。VAE 的解码大约需要 2~3 个迭代步数的时间,每步迭代都使用 VAE 去解码潜变量显然是不合适的。
WebUI 预览生成图像的过程使用了近似 VAE 解码技术。该技术使用一个微型的 VAE,称为 VAE-Approx,快速解码生成过程的潜变量为质量较低的图像以供预览。
3 模型训练
3.1 高级参数讲解
3.1.1 Zero SNR Terminal
原论文:[2305.08891] Common Diffusion Noise Schedules and Sample Steps are Flawed (arxiv.org)
TODO
3.1.2 Rescale CFG
原论文:[2305.08891] Common Diffusion Noise Schedules and Sample Steps are Flawed (arxiv.org)
TODO
3.1.3 V-Prediction Loss
原论文:[2202.00512] Progressive Distillation for Fast Sampling of Diffusion Models (arxiv.org)
TODO
4 文本嵌入
我们知道,一个 embedding (emb) 模型装载了某个文本概念,或是一段提示词。它诱导 SD 模型生成该概念的内容。emb 作用的对象是 SD 模型的文本编码器而不是 UNET 本身,因此无法生成那些 SD 模型本身不知道的内容。
本节将介绍以下有关文本嵌入(Text Embedding)的内容:
- 负面文本嵌入
- .pt 和 .safetensors 的相互转换
- SD1.5 和 SDXL 文本嵌入的相互转换
为了方便,以下文本嵌入简称为 emb。
4.1 负面文本嵌入
负面文本嵌入,简称 负面 emb 或 neg emb,是正常 emb 的逆向使用。但如今,负面 emb 的意义已凌驾于正常 emb 之上。广为人知的负面 emb 如 EasyNegative 和 badhandv4 等。
负面 emb 的思路非常直观,虽然人们难以教会模型关于“好”的概念,因为“好”的定义相对模糊,但“坏”的定义更为具体且容易获取,例如畸变、伪影、低分辨率等。因此,负面 emb 的职责就是告诉模型什么是糟糕的——类似施肥。
本节将介绍负面 emb 的炼制过程和基于经验的推荐参数。
4.1.1 生成数据集:挑选工业原料
既然要教会模型什么是“糟糕透顶”的,就需要准备丑陋至极,不堪入目的训练集。那么,什么才是所谓的“丑陋至极,不堪入目”呢?根据经验法则,满足以下条件的图像/训练集最有利于训练:
- 为了避免干扰正常概念,图像应基本不具备任何正常的概念。例如,大量的 画面损毁,人体畸变 等。
- 为了不改变风格,且使 emb 模型有足够的的泛化能力,训练集图像应具有所训练概念之下的各种风格、色彩、对比度、亮度、细节复杂程度、构图、人物动作。
- 训练图像越多越好。通常来说,应多于 500 张。
训练图像可直接由 SD 模型生成。为了使生成的图像尽可能“难看”,可以选用 SD1.5 类型下较差的模型,并在提示词中填写如“low quality, worst quality, deformity, bad anatomy, distorted fingers”等提示词,同时调低采样步数,换用效果差的采样器等。
为了使训练集多样,您可以在不同的提示词、采样步数、CFG 等参数下生成尽量多的图像。
您可以人工地“破坏图像”,例如,常用的生成分辨率是 512x512。可若要训练“低分辨率”的概念,则可生成低于 512x512 分辨率的图像后再放大为 512x512,即可制作低分图。
发挥您的作图技巧,生成最丑陋,最不堪入目的图像吧!
4.1.2 训练模型:制作化肥
训练负面 emb 模型与训练一般 emb 模型类似,可以为数据集打上标签。向量数设置为 2~16 左右。初始化词元可以置空,也可以填写为所训练概念,但要注意所填写的内容所占用的词元(token)数应与 emb 模型的向量数匹配,您可以通过一些工具来查看某一句话的词元数,例如 WebUI 的 tokenizer 扩展等。
按照经验,负面 emb 应以更高的学习率训练至过拟合,以免泛化过多而误伤其他概念。通常,起始学习率应介于 1e-3~1e-4 之间(即 0.001~0.0001),终止学习率则介于 1e-5~1e-6 之间。训练至少 1000 步,直至 loss 收敛。
4.1.3 模型评估:肥料的好坏
一个好的负面 emb 的应做到如下几点:
- 有效:修复了所训练的负面概念;
- 不越俎代庖:不误伤其他正常的概念;
- 小而美:不占用过多词元数;
- 泛化:在各种 SD 模型上均有不错的泛化能力(较难实现);
4.2 模型格式的转换
TODO
4.3 模型种类的转换
如今,基于 SDXL 的 emb 模型(简称为 embXL)数量较少,而 SD1.5 具有很多优秀的 emb 模型(简称为 emb1.5)。一个 embXL 包括 CLIP_G 权重和 CLIP_L 权重两部分,其中,CLIP_L 的权重与 emb1.5 具有相同的形状。也就是说,embXL 的其中一部分是 emb1.5 的结构。这使得二者之间相互转化成为可能。
emb1.5 转 embXL
由于 SDXL 具有两个文本编码器,无法完美地将 SD1.5 的 emb 模型转移到 SDXL 上。但是,转移相同部分是可行的。方法是,拷贝 emb1.5 中的权重到 embXL 的 CLIP_L 权重上,并用零来补全 CLIP_G 的权重。
embXL 转 emb1.5
embXL 理论上能够无损地转换为 emb1.5。方法是,提取 embXL 中 CLIP_L 上的权重,将其原封不动地拷贝到 emb1.5 上,即可完成转换。
5 模型融合
5.1 模型权重的储存
AI 模型的权重通常储存在一个哈希表(字典) state_dict 中。state_dict 的键为权重名称,值为权重。按照某一比例混合 state_dict 各层的模型权重即为模型融合。
SD 1.5 模型权重储存格式
在 state_dict 中,文本编码器的权重储存在含有 cond_stage_model.transformer.text_model 的键之中,共197个这样的键。
UNET 的权重储存在含有 model.diffusion_model 的键之中,共有686个这样的键。其中,IN 层为 model.diffusion_model.input_blocks,共248个;OUT 层为model.diffusion_model.output_blocks,共384个;MID 层为 ,model.diffusion_model.middle_block共46个。
VAE 储存在含有 first_stage_model 的键之中,共有248个这样的键。
SD XL 模型权重储存格式
对于 SDXL,含有 conditioner.embedders.0.transformer.text_model 的键对应文本编码器 CLIP_L,即 SD1.5 中的文本编码器,共有197个这样的键。含有 conditioner.embedders.1.model.transformer 的键对应 CLIP_G,共有 385 个这样的键。
UNET 的权重的储存格式与 SD1.5 模型相同,IN, OUT, MID 层各有 574, 868, 226 个键。
VAE 储存在含有 first_stage_model 的键之中,共有248个这样的键。
5.1.1 模型的加载和保存
本节将演示在本地使用python简单地加载和保存一个.safetensors模型。鉴于目前大部分模型都被封装为 .ckpt 或 .safetensors 格式,本节将不针对散装pytorch模型。
模型的加载和保存非常容易,只需使用safetensors包即可。您可以通过在终端输入 pip install safetensors 来安装。以 safetensors 格式的模型为例,以下代码实现了模型权重的加载和保存:
# 模型的加载和保存from safetensors.torch import load_file, save_filemodel_path = "Path/to/your/model.safetensors" # 设置模型路径state_dict = load_file(model_path) # 加载模型文件为 state dictsave_file(state_dict, "Path/to/save/your/model.safetensors") # 保存模
若有需要,您亦可将模型储存为其他易读形式,例如,将模型的键储存为 json 格式以观察模型结构。
5.2 模型融合
模型融合分为三个步骤:(i) 加载模型的 state_dict;(ii) 融合对应键的值,即权重;(iii) 保存模型。本节将详细介绍如何实现模型融合。
5.2.2 分层融合算法
给定需要融合的层,在加载两个模型的 state_dict 后,我们只需按照对应层的键值,依次提取出模型在该层的权重,并进行融合即可。以下模型算法实现了将两个模型 A 和 B 按照一定比例融合。比例越大,融合结果越偏向于模型 B。
模型融合算法一
- 输入:(i) 两个模型的 state_dict sd_A 和 sd_B;(ii) 融合比例 alpha 和 (iii) 待融合的部分;
- 定义融合后的新模型为 sd_M,首先将模型 A 的权重复制到 M 上。
- 对于每个待融合的层,以它为键,在 sd_A 和 sd_B 中找出对应层的权重 w_A 和 w_B,计算 w_M = w_A × (1-alpha) + w_B × alpha。之后,将 w_M 赋值给模型 sd_M 的对应层。
- 输出 sd_M。
这样,我们就完成了简单的分层融合。下文将介绍一些进阶的模型融合算法,例如 SuperMerger 插件中的 cosine_A/B、TrainDifference 等。这些融合算法有助于平滑融合曲线,使结果模型的权重不过度颠簸。
5.2.3 复杂融合算法
TODO

若有收获,就点个赞吧
0 人点赞
