- 文本预处理及其作用
- 文本处理的基本方法
- 将返回一个生成器对象
- 若需直接返回列表内容, 使用jieba.lcut即可
- 将返回一个生成器对象
- 若需直接返回列表内容, 使用jieba.lcut即可
- 将返回一个生成器对象
- 若需直接返回列表内容, 使用jieba.lcut_for_search即可
- 对’女干事’, ‘交换机’等较长词汇都进行了再次分词.
- 没有使用用户自定义词典前的结果:
- 使用了用户自定义词典后的结果:
- 词性标注
- 结果返回一个装有pair元组的列表, 每个pair元组中分别是词汇及其对应的词性, 具体词性含义请参照 附录: jieba词性对照表
- 加载中文命名实体识别的预训练模型MSRA_NER_BERT_BASE_ZH
- 这里注意它的输入是对句子进行字符分割的列表, 因此在句子前加入了list()
- >>> list(‘上海华安工业(集团)公司董事长谭旭光和秘书张晚霞来到美 国纽约现代艺术博物馆参观。’)
- [‘上’, ‘海’, ‘华’, ‘安’, ‘工’, ‘业’, ‘(’, ‘集’, ‘团’, ‘)’, ‘公’, ‘司’, ‘董’, ‘事’, ‘长’, ‘谭’, ‘旭’, ‘光’, ‘和’, ‘秘’, ‘书’, ‘张’, ‘晚’, ‘霞’, ‘来’, ‘到’, ‘美’, ‘国’, ‘纽’, ‘约’, ‘现’, ‘代’, ‘艺’, ‘术’, ‘博’, ‘物’, ‘馆’, ‘参’, ‘观’, ‘。’]
- 返回结果是一个装有n个元组的列表, 每个元组代表一个命名实体, 元组中的每一项分别代表具体的命名实体, 如: ‘上海华安工业(集团)公司’; 命名实体的类型, 如: ‘NT’-机构名; 命名实体的开始索引和结束索引, 如: 0, 12.
- 文本张量表示方法
- 文本数据分析
- 文本特征处理
- 文本数据增强
文本预处理及其作用
文本语料在输送给模型前一般需要一系列的预处理工作, 才能符合模型输入的要求, 如: 将文本转化成模型需要的张量, 规范张量的尺寸等, 而且科学的文本预处理环节还将有效指导模型超参数的选择, 提升模型的评估指标.
文本处理的基本方法
分词
分词就是将连续的字序列按照一定的规范重新组合成词序列的过程。我们知道,在英文的行文中,单词之间是以空格作为自然分界符的,而中文只是字、句和段能通过明显的分界符来简单划界,唯独词没有一个形式上的分界符, 分词过程就是找到这样分界符的过程.
作用
词作为语言语义理解的最小单元, 是人类理解文本语言的基础. 因此也是AI解决NLP领域高阶任务, 如自动问答, 机器翻译, 文本生成的重要基础环节.
中文分词工具jieba
- 支持多种分词模式
- 精确模式
- 全模式
- 搜索引擎模式
- 支持中文繁体分词
- 支持用户自定义词典
jieba的安装:
pip install jieba
jieba的使用
- 精确模式分词:试图将句子最精确地切开,适合文本分析
```python
import jieba content = “工信处女干事每月经过下属科室都要亲口交代24口交换机等技术性器件的安装工作” jieba.cut(content, cut_all=False) # cut_all默认为False
将返回一个生成器对象
若需直接返回列表内容, 使用jieba.lcut即可
jieba.lcut(content, cut_all=False) [‘工信处’, ‘女干事’, ‘每月’, ‘经过’, ‘下属’, ‘科室’, ‘都’, ‘要’, ‘亲口’, ‘交代’, ‘24’, ‘口’, ‘交换机’, ‘等’, ‘技术性’, ‘器件’, ‘的’, ‘安装’, ‘工作’] ```
- 全模式分词:把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能消除 歧义
```python
import jieba content = “工信处女干事每月经过下属科室都要亲口交代24口交换机等技术性器件的安装工作” jieba.cut(content, cut_all=True) # cut_all默认为False
将返回一个生成器对象
若需直接返回列表内容, 使用jieba.lcut即可
jieba.lcut(content, cut_all=True) [‘工信处’, ‘处女’, ‘女干事’, ‘干事’, ‘每月’, ‘月经’, ‘经过’, ‘下属’, ‘科室’, ‘都’, ‘要’, ‘亲口’, ‘口交’, ‘交代’, ‘24’, ‘口交’, ‘交换’, ‘交换机’, ‘换机’, ‘等’, ‘技术’, ‘技术性’, ‘性器’, ‘器件’, ‘的’, ‘安装’, ‘安装工’, ‘装工’, ‘工作’] ```
- 搜索引擎模式分词:在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词
```python
import jieba content = “工信处女干事每月经过下属科室都要亲口交代24口交换机等技术性器件的安装工作” jieba.cut_for_search(content)
将返回一个生成器对象
若需直接返回列表内容, 使用jieba.lcut_for_search即可
jieba.lcut_for_search(content) [‘工信处’, ‘干事’, ‘女干事’, ‘每月’, ‘经过’, ‘下属’, ‘科室’, ‘都’, ‘要’, ‘亲口’, ‘交代’, ‘24’, ‘口’, ‘交换’, ‘换机’, ‘交换机’, ‘等’, ‘技术’, ‘技术性’, ‘器件’, ‘的’, ‘安装’, ‘工作’]
对’女干事’, ‘交换机’等较长词汇都进行了再次分词.
- 中文繁体分词:针对中国香港, 台湾地区的繁体文本进行分词.```python>>> import jieba>>> content = "煩惱即是菩提,我暫且不提">>> jieba.lcut(content)['煩惱', '即', '是', '菩提', ',', '我', '暫且', '不', '提']
- 使用用户自定义词典:
- 添加自定义词典后, jieba能够准确识别词典中出现的词汇,提升整体的识别准确率.
- 词典格式: 每一行分三部分:词语、词频(可省略)、词性(可省略),用空格隔开,顺序不可颠倒.
- 词典样式如下, 具体词性含义请参照附录: jieba词性对照表, 将该词典存为userdict.txt, 方便之后加载使用.
```python云计算 5 n李小福 2 nreasy_install 3 eng好用 300韩玉赏鉴 3 nz八一双鹿 3 nz
import jieba jieba.lcut(“八一双鹿更名为八一南昌篮球队!”)
没有使用用户自定义词典前的结果:
[‘八’, ‘一双’, ‘鹿’, ‘更名’, ‘为’, ‘八一’, ‘南昌’, ‘篮球队’, ‘!’]
- 添加自定义词典后, jieba能够准确识别词典中出现的词汇,提升整体的识别准确率.
jieba.load_userdict(“./userdict.txt”)
使用了用户自定义词典后的结果:
[‘八一双鹿’, ‘更名’, ‘为’, ‘八一’, ‘南昌’, ‘篮球队’, ‘!’] ```
中英文分词工具hanlp
中英文NLP处理工具包, 基于tensorflow2.0, 使用在学术界和行业中推广最先进的深度学习技术
- 安装
pip install hanlp
- 使用hanlp进行中文分词:
>>> import hanlp# 加载CTB_CONVSEG预训练模型进行分词任务>>> tokenizer = hanlp.load('CTB6_CONVSEG')>>> tokenizer("工信处女干事每月经过下属科室都要亲口交代24口交换机等技术性器件的安装工作")['工信处', '女', '干事', '每', '月', '经过', '下', '属', '科室', '都', '要', '亲口', '交代', '24口', '交换机', '等', '技术性', '器件', '的', '安装', '工作']
- 使用hanlp进行英文分词
# 进行英文分词, 英文分词只需要使用规则即可>>> tokenizer = hanlp.utils.rules.tokenize_english>>> tokenizer('Mr. Hankcs bought hankcs.com for 1.5 thousand dollars.')['Mr.', 'Hankcs', 'bought', 'hankcs.com', 'for', '1.5', 'thousand', 'dollars', '.']
词性标注
词性标注(Part-Of-Speech tagging, 简称POS)就是标注出一段文本中每个词汇的词性。词性: 语言中对词的一种分类方法,以语法特征为主要依据、兼顾词汇意义对词进行划分的结果, 常见的词性有14种, 如: 名词, 动词, 形容词等.
作用
词性标注以分词为基础, 是对文本语言的另一个角度的理解, 因此也常常成为AI解决NLP领域高阶任务的重要基础环节.
- 使用jieba进行中文词性标注
```python
import jieba.posseg as pseg pseg.lcut(“我爱北京天安门”) [pair(‘我’, ‘r’), pair(‘爱’, ‘v’), pair(‘北京’, ‘ns’), pair(‘天安门’, ‘ns’)]
结果返回一个装有pair元组的列表, 每个pair元组中分别是词汇及其对应的词性, 具体词性含义请参照附录: jieba词性对照表
- 使用hanlp进行中文词性标注```python>>> import hanlp# 加载中文命名实体识别的预训练模型CTB5_POS_RNN_FASTTEXT_ZH>>> tagger = hanlp.load(hanlp.pretrained.pos.CTB5_POS_RNN_FASTTEXT_ZH)# 输入是分词结果列表>>> tagger(['我', '的', '希望', '是', '希望', '和平'])# 结果返回对应的词性['PN', 'DEG', 'NN', 'VC', 'VV', 'NN']
- 使用hanlp进行英文词性标注
>>> import hanlp# 加载英文命名实体识别的预训练模型PTB_POS_RNN_FASTTEXT_EN>>> tagger = hanlp.load(hanlp.pretrained.pos.PTB_POS_RNN_FASTTEXT_EN)# 输入是分词结果列表>>> tagger(['I', 'banked', '2', 'dollars', 'in', 'a', 'bank', '.'])['PRP', 'VBD', 'CD', 'NNS', 'IN', 'DT', 'NN', '.']
命名实体识别
命名实体识别(Named Entity Recognition,简称NER)就是识别出一段文本中可能存在的命名实体,通常我们将人名, 地名, 机构名等专有名词统称命名实体. 如: 周杰伦, 黑山县, 孔子学院, 24辊方钢矫直机.
作用
同词汇一样, 命名实体也是人类理解文本的基础单元, 因此也是AI解决NLP领域高阶任务的重要基础环节
- 使用hanlp进行中文命名实体识别:
```python
import hanlp
加载中文命名实体识别的预训练模型MSRA_NER_BERT_BASE_ZH
recognizer = hanlp.load(hanlp.pretrained.ner.MSRA_NER_BERT_BASE_ZH)
这里注意它的输入是对句子进行字符分割的列表, 因此在句子前加入了list()
>>> list(‘上海华安工业(集团)公司董事长谭旭光和秘书张晚霞来到美 国纽约现代艺术博物馆参观。’)
[‘上’, ‘海’, ‘华’, ‘安’, ‘工’, ‘业’, ‘(’, ‘集’, ‘团’, ‘)’, ‘公’, ‘司’, ‘董’, ‘事’, ‘长’, ‘谭’, ‘旭’, ‘光’, ‘和’, ‘秘’, ‘书’, ‘张’, ‘晚’, ‘霞’, ‘来’, ‘到’, ‘美’, ‘国’, ‘纽’, ‘约’, ‘现’, ‘代’, ‘艺’, ‘术’, ‘博’, ‘物’, ‘馆’, ‘参’, ‘观’, ‘。’]
recognizer(list(‘上海华安工业(集团)公司董事长谭旭光和秘书张晚霞来到美国纽约现代艺术博物馆参观。’)) [(‘上海华安工业(集团)公司’, ‘NT’, 0, 12), (‘谭旭光’, ‘NR’, 15, 18), (‘张晚霞’, ‘NR’, 21, 24), (‘美国’, ‘NS’, 26, 28), (‘纽约现代艺术博物馆’, ‘NS’, 28, 37)]
返回结果是一个装有n个元组的列表, 每个元组代表一个命名实体, 元组中的每一项分别代表具体的命名实体, 如: ‘上海华安工业(集团)公司’; 命名实体的类型, 如: ‘NT’-机构名; 命名实体的开始索引和结束索引, 如: 0, 12.
- 使用hanlp进行英文命名实体识别```python>>> import hanlp# 加载英文命名实体识别的预训练模型CONLL03_NER_BERT_BASE_UNCASED_EN>>> recognizer = hanlp.load(hanlp.pretrained.ner.CONLL03_NER_BERT_BASE_UNCASED_EN))# 这里注意它的输入是对句子进行分词后的结果, 是列表形式.>>> recognizer(["President", "Obama", "is", "speaking", "at", "the", "White", "House"])[('Obama', 'PER', 1, 2), ('White House', 'LOC', 6, 8)]# 返回结果是一个装有n个元组的列表, 每个元组代表一个命名实体, 元组中的每一项分别代>表具体的命名实体, 如: 'Obama', 如: 'PER'-人名; 命名实体的开始索引和结束索引, 如: 1, 2.
文本张量表示方法
将一段文本使用张量进行表示,其中一般将词汇为表示成向量,称作词向量,再由各个词向量按顺序组成矩阵形成文本表示.
举个栗子
["人生", "该", "如何", "起头"]==># 每个词对应矩阵中的一个向量[[1.32, 4,32, 0,32, 5.2],[3.1, 5.43, 0.34, 3.2],[3.21, 5.32, 2, 4.32],[2.54, 7.32, 5.12, 9.54]]
作用
将文本表示成张量(矩阵)形式,能够使语言文本可以作为计算机处理程序的输入,进行接下来一系列的解析工作.
文本张量表示的方法:
- one-hot编码
- Word2vec
- Word Embedding
one-hot词向量表示
又称独热编码,将每个词表示成具有n个元素的向量,这个词向量中只有一个元素是1,其他元素都是0,不同词汇元素为0的位置不同,其中n的大小是整个语料中不同词汇的总数.
onehot编码实现:
# 导入用于对象保存与加载的joblibfrom sklearn.externals import joblib# 导入keras中的词汇映射器Tokenizerfrom keras.preprocessing.text import Tokenizer# 假定vocab为语料集所有不同词汇集合vocab = {"周杰伦", "陈奕迅", "王力宏", "李宗盛", "吴亦凡", "鹿晗"}# 实例化一个词汇映射器对象t = Tokenizer(num_words=None, char_level=False)# 使用映射器拟合现有文本数据t.fit_on_texts(vocab)for token in vocab:zero_list = [0]*len(vocab)# 使用映射器转化现有文本数据, 每个词汇对应从1开始的自然数# 返回样式如: [[2]], 取出其中的数字需要使用[0][0]token_index = t.texts_to_sequences([token])[0][0] - 1zero_list[token_index] = 1print(token, "的one-hot编码为:", zero_list)# 使用joblib工具保存映射器, 以便之后使用tokenizer_path = "./Tokenizer"joblib.dump(t, tokenizer_path)
输出
鹿晗 的one-hot编码为: [1, 0, 0, 0, 0, 0]王力宏 的one-hot编码为: [0, 1, 0, 0, 0, 0]李宗盛 的one-hot编码为: [0, 0, 1, 0, 0, 0]陈奕迅 的one-hot编码为: [0, 0, 0, 1, 0, 0]周杰伦 的one-hot编码为: [0, 0, 0, 0, 1, 0]吴亦凡 的one-hot编码为: [0, 0, 0, 0, 0, 1]# 同时在当前目录生成Tokenizer文件, 以便之后使用
onehot编码器的使用
# 导入用于对象保存与加载的joblib# from sklearn.externals import joblib# 加载之前保存的Tokenizer, 实例化一个t对象t = joblib.load(tokenizer_path)# 编码token为"李宗盛"token = "李宗盛"# 使用t获得token_indextoken_index = t.texts_to_sequences([token])[0][0] - 1# 初始化一个zero_listzero_list = [0]*len(vocab)# 令zero_List的对应索引为1zero_list[token_index] = 1print(token, "的one-hot编码为:", zero_list)
输出效果
李宗盛 的one-hot编码为: [1, 0, 0, 0, 0, 0]
one-hot编码的优劣势
- 优势:操作简单,容易理解.
- 劣势:完全割裂了词与词之间的联系,而且在大语料集下,每个向量的长度过大,占据大量内存.
正因为one-hot编码明显的劣势,这种编码方式被应用的地方越来越少,取而代之的是稠密向量的表示方法word2vec和word embedding.
word2vec
是一种流行的将词汇表示成向量的无监督训练方法, 该过程将构建神经网络模型, 将网络参数作为词汇的向量表示, 它包含CBOW和skipgram两种训练模式
CBOW(Continuous bag of words)模式:
给定一段用于训练的文本语料, 再选定某段长度(窗口)作为研究对象, 使用上下文词汇预测目标词汇
CBOW模式下的word2vec过程说明
- 假设我们给定的训练语料只有一句话: Hope can set you free (愿你自由成长),窗口大小为3,因此模型的第一个训练样本来自Hope can set,因为是CBOW模式,所以将使用Hope和set作为输入,can作为输出,在模型训练时, Hope,can,set等词汇都使用它们的one-hot编码. 如图所示: 每个one-hot编码的单词与各自的变换矩阵(即参数矩阵3x5, 这里的3是指最后得到的词向量维度)相乘之后再相加, 得到上下文表示矩阵(3x1).
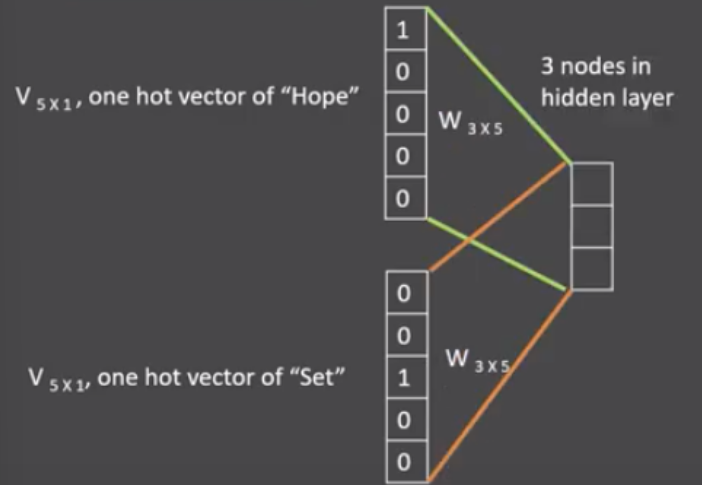
接着, 将上下文表示矩阵与变换矩阵(参数矩阵5x3, 所有的变换矩阵共享参数)相乘, 得到5x1的结果矩阵, 它将与我们真正的目标矩阵即can的one-hot编码矩阵(5x1)进行损失的计算, 然后更新网络参数完成一次模型迭代

- 最后窗口按序向后移动,重新更新参数,直到所有语料被遍历完成,得到最终的变换矩阵(3x5),这个变换矩阵与每个词汇的one-hot编码(5x1)相乘,得到的3x1的矩阵就是该词汇的word2vec张量表示
skipgram
给定一段用于训练的文本语料, 再选定某段长度(窗口)作为研究对象, 使用目标词汇预测上下文词汇
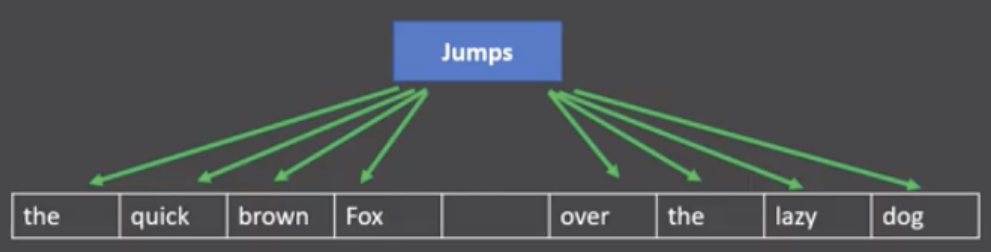
skipgram模式下的word2vec过程说明
- 假设我们给定的训练语料只有一句话: Hope can set you free (愿你自由成长),窗口大小为3,因此模型的第一个训练样本来自Hope can set,因为是skipgram模式,所以将使用can作为输入 ,Hope和set作为输出,在模型训练时, Hope,can,set等词汇都使用它们的one-hot编码. 如图所示: 将can的one-hot编码与变换矩阵(即参数矩阵3x5, 这里的3是指最后得到的词向量维度)相乘, 得到目标词汇表示矩阵(3x1).
接着, 将目标词汇表示矩阵与多个变换矩阵(参数矩阵5x3)相乘, 得到多个5x1的结果矩阵, 它将与我们Hope和set对应的one-hot编码矩阵(5x1)进行损失的计算, 然后更新网络参数完成一次模 型迭代.

最后窗口按序向后移动,重新更新参数,直到所有语料被遍历完成,得到最终的变换矩阵即参数矩阵(3x5),这个变换矩阵与每个词汇的one-hot编码(5x1)相乘,得到的3x1的矩阵就是该词汇的word2vec张量表示.
word embedding(词嵌入)
- 通过一定的方式将词汇映射到指定维度(一般是更高维度)的空间.
- 广义的word embedding包括所有密集词汇向量的表示方法,如之前学习的word2vec, 即可认为是word embedding的一种.
- 狭义的word embedding是指在神经网络中加入的embedding层, 对整个网络进行训练的同时产生的embedding矩阵(embedding层的参数), 这个embedding矩阵就是训练过程中所有输入词汇的向量表示组成的矩阵.
文本数据分析
作用:
文本数据分析能够有效帮助我们理解数据语料, 快速检查出语料可能存在的问题, 并指导之后模型训练过程中一些超参数的选择.
方法:
- 标签数量分布
- 句子长度分布
- 词频统计与关键词词云
基于真实的中文酒店评论语料来讲解常用的几种文本数据分析方法
train.tsv数据样式
sentence label早餐不好,服务不到位,晚餐无西餐,早餐晚餐相同,房间条件不好,餐厅不分吸烟区.房间不分有无烟房. 0去的时候 ,酒店大厅和餐厅在装修,感觉大厅有点挤.由于餐厅装修本来该享受的早饭,也没有享受(他们是8点开始每个房间送,但是我时间来不及了)不过前台服务员态度好! 1有很长时间没有在西藏大厦住了,以前去北京在这里住的较多。这次住进来发现换了液晶电视,但网络不是很好,他们自己说是收费的原因造成的。其它还好。 1非常好的地理位置,住的是豪华海景房,打开窗户就可以看见栈桥和海景。记得很早以前也住过,现在重新装修了。总的来说比较满意,以后还会住 1交通很方便,房间小了一点,但是干净整洁,很有香港的特色,性价比较高,推荐一下哦 1酒店的装修比较陈旧,房间的隔音,主要是卫生间的隔音非常差,只能算是一般的 0酒店有点旧,房间比较小,但酒店的位子不错,就在海边,可以直接去游泳。8楼的海景打开窗户就是海。如果想住在热闹的地带,这里不是一个很好的选择,不过威海城市真的比较小,打车还是相当便宜的。晚上酒店门口出租车比较少。 1位置很好,走路到文庙、清凉寺5分钟都用不了,周边公交车很多很方便,就是出租车不太爱去(老城区路窄爱堵车),因为是老宾馆所以设施要陈旧些, 1酒店设备一般,套房里卧室的不能上网,要到客厅去。 0
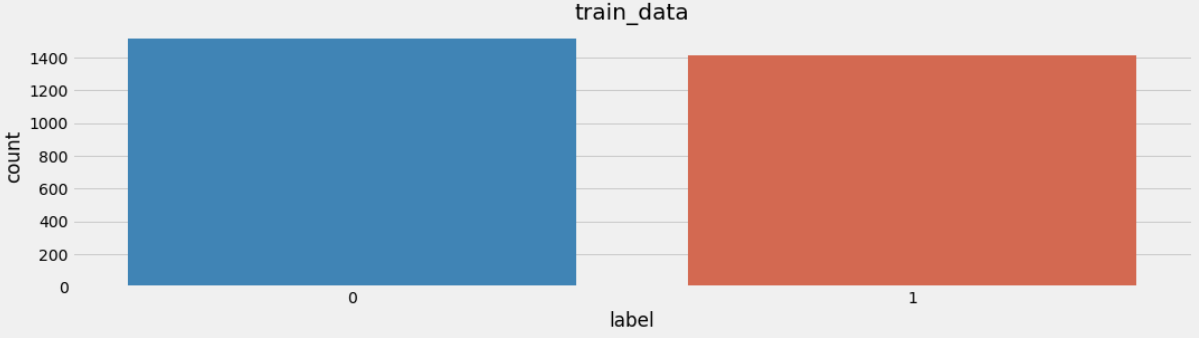
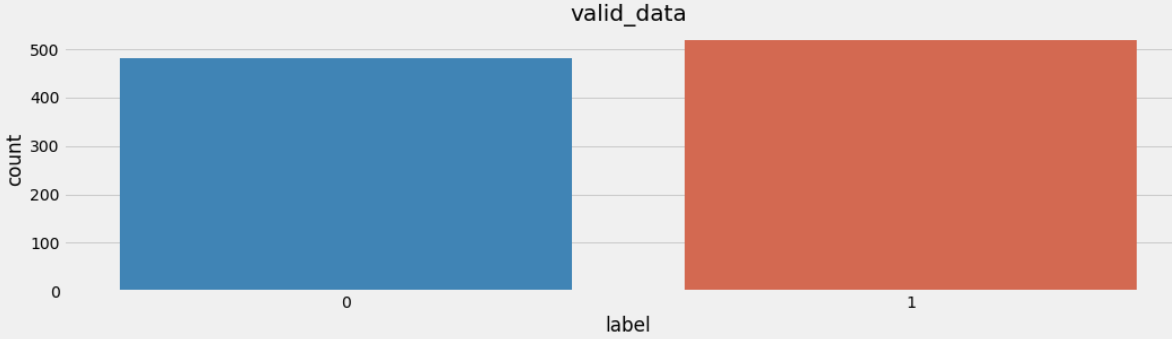
得训练集和验证集的标签数量分布
# 导入必备工具包import seaborn as snsimport pandas as pdimport matplotlib.pyplot as plt# 设置显示风格plt.style.use('fivethirtyeight')# 分别读取训练tsv和验证tsvtrain_data = pd.read_csv("./cn_data/train.tsv", sep="\t")valid_data = pd.read_csv("./cn_data/dev.tsv", sep="\t")# 获得训练数据标签数量分布sns.countplot("label", data=train_data)plt.title("train_data")plt.show()# 获取验证数据标签数量分布sns.countplot("label", data=valid_data)plt.title("valid_data")plt.show()
训练集标签数量分布
验证集标签数量分布:
分析:
在深度学习模型评估中, 我们一般使用ACC作为评估指标, 若想将ACC的基线定义在50%左右, 则需要我们的正负样本比例维持在1:1左右, 否则就要进行必要的数据增强或数据删减. 上图中训练和验证集正负样本都稍有不均衡, 可以进行一些数据增强.
获取训练集和验证集的句子长度分布
# 在训练数据中添加新的句子长度列, 每个元素的值都是对应的句子列的长度train_data["sentence_length"] = list(map(lambda x: len(x), train_data["sentence"]))# 绘制句子长度列的数量分布图sns.countplot("sentence_length", data=train_data)# 主要关注count长度分布的纵坐标, 不需要绘制横坐标, 横坐标范围通过dist图进行查看plt.xticks([])plt.show()# 绘制dist长度分布图sns.distplot(train_data["sentence_length"])# 主要关注dist长度分布横坐标, 不需要绘制纵坐标plt.yticks([])plt.show()# 在验证数据中添加新的句子长度列, 每个元素的值都是对应的句子列的长度valid_data["sentence_length"] = list(map(lambda x: len(x), valid_data["sentence"]))# 绘制句子长度列的数量分布图sns.countplot("sentence_length", data=valid_data)# 主要关注count长度分布的纵坐标, 不需要绘制横坐标, 横坐标范围通过dist图进行查看plt.xticks([])plt.show()# 绘制dist长度分布图sns.distplot(valid_data["sentence_length"])# 主要关注dist长度分布横坐标, 不需要绘制纵坐标plt.yticks([])plt.show()
训练集句子长度分布:

验证集句子长度分布
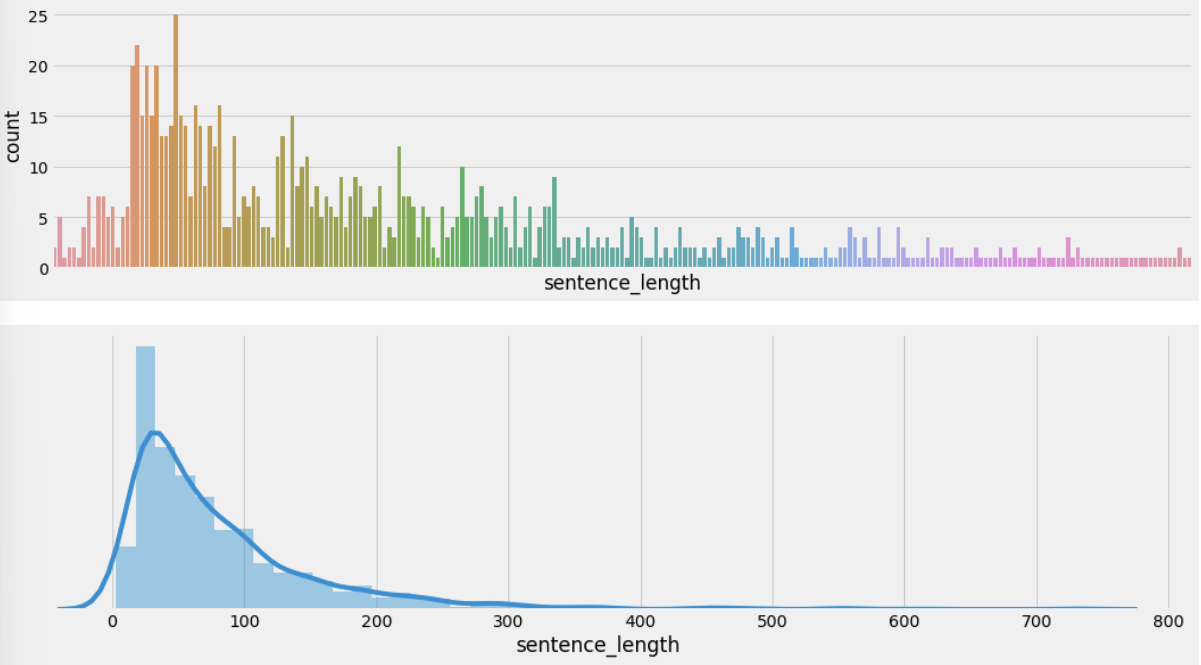
分析:
通过绘制句子长度分布图, 可以得知我们的语料中大部分句子长度的分布范围, 因为模型的输入要求为固定尺寸的张量,合理的长度范围对之后进行句子截断补齐(规范长度)起到关键的指导作用. 上图中大部分句子长度的范围大致为20-250之间.
获取训练集和验证集的正负样本长度散点分布
# 绘制训练集长度分布的散点图sns.stripplot(y='sentence_length',x='label',data=train_data)plt.show()# 绘制验证集长度分布的散点图sns.stripplot(y='sentence_length',x='label',data=valid_data)plt.show()
训练集上正负样本的长度散点分布

验证集上正负样本的长度散点分布

分析:
通过查看正负样本长度散点图, 可以有效定位异常点的出现位置, 帮助我们更准确进行人工语料审查. 上图中在训练集正样本中出现了异常点, 它的句子长度近3500左右, 需要我们人工审查.
获得训练集与验证集不同词汇总数统计
# 导入jieba用于分词# 导入chain方法用于扁平化列表import jiebafrom itertools import chain# 进行训练集的句子进行分词, 并统计出不同词汇的总数train_vocab = set(chain(*map(lambda x: jieba.lcut(x), train_data["sentence"])))print("训练集共包含不同词汇总数为:", len(train_vocab))# 进行验证集的句子进行分词, 并统计出不同词汇的总数valid_vocab = set(chain(*map(lambda x: jieba.lcut(x), valid_data["sentence"])))print("训练集共包含不同词汇总数为:", len(valid_vocab))
输出效果:
训练集共包含不同词汇总数为: 12147训练集共包含不同词汇总数为: 6857
获得训练集上正负的样本的高频形容词词云
# 使用jieba中的词性标注功能import jieba.posseg as psegdef get_a_list(text):"""用于获取形容词列表"""# 使用jieba的词性标注方法切分文本,获得具有词性属性flag和词汇属性word的对象,# 从而判断flag是否为形容词,来返回对应的词汇r = []for g in pseg.lcut(text):if g.flag == "a":r.append(g.word)return r# 导入绘制词云的工具包from wordcloud import WordClouddef get_word_cloud(keywords_list):# 实例化绘制词云的类, 其中参数font_path是字体路径, 为了能够显示中文,# max_words指词云图像最多显示多少个词, background_color为背景颜色wordcloud = WordCloud(font_path="./SimHei.ttf", max_words=100, background_color="white")# 将传入的列表转化成词云生成器需要的字符串形式keywords_string = " ".join(keywords_list)# 生成词云wordcloud.generate(keywords_string)# 绘制图像并显示plt.figure()plt.imshow(wordcloud, interpolation="bilinear")plt.axis("off")plt.show()# 获得训练集上正样本p_train_data = train_data[train_data["label"]==1]["sentence"]# 对正样本的每个句子的形容词train_p_a_vocab = chain(*map(lambda x: get_a_list(x), p_train_data))#print(train_p_n_vocab)# 获得训练集上负样本n_train_data = train_data[train_data["label"]==0]["sentence"]# 获取负样本的每个句子的形容词train_n_a_vocab = chain(*map(lambda x: get_a_list(x), n_train_data))# 调用绘制词云函数get_word_cloud(train_p_a_vocab)get_word_cloud(train_n_a_vocab)
训练集正样本形容词词云

训练集负样本形容词词云

获得验证集上正负的样本的形容词词云
# 获得验证集上正样本p_valid_data = valid_data[valid_data["label"]==1]["sentence"]# 对正样本的每个句子的形容词valid_p_a_vocab = chain(*map(lambda x: get_a_list(x), p_valid_data))#print(train_p_n_vocab)# 获得验证集上负样本n_valid_data = valid_data[valid_data["label"]==0]["sentence"]# 获取负样本的每个句子的形容词valid_n_a_vocab = chain(*map(lambda x: get_a_list(x), n_valid_data))# 调用绘制词云函数get_word_cloud(valid_p_a_vocab)get_word_cloud(valid_n_a_vocab)
验证集正样本形容词词云

验证集负样本形容词词云:

分析:
根据高频形容词词云显示, 我们可以对当前语料质量进行简单评估, 同时对违反语料标签含义的词汇进行人工审查和修正, 来保证绝大多数语料符合训练标准. 上图中的正样本大多数是褒义词, 而负样本大多数是贬义词, 基本符合要求, 但是负样本词云中也存在”便利”这样的褒义词, 因此可以人工进行审查
文本特征处理
作用:
文本特征处理包括为语料添加具有普适性的文本特征, 如:n-gram特征, 以及对加入特征之后的文本语料进行必要的处理, 如: 长度规范. 这些特征处理工作能够有效的将重要的文本特征加入模型训练中, 增强模型评估指标.
方法:
- 添加n-gram特征
- 文本长度规范
n-gram特征
给定一段文本序列, 其中n个词或字的相邻共现特征即n-gram特征, 常用的n-gram特征是bi-gram和tri-gram特征, 分别对应n为2和3.
举个栗子
假设给定分词列表: ["是谁", "敲动", "我心"]对应的数值映射列表为: [1, 34, 21]我们可以认为数值映射列表中的每个数字是词汇特征.除此之外, 我们还可以把"是谁"和"敲动"两个词共同出现且相邻也作为一种特征加入到序列列表中,假设1000就代表"是谁"和"敲动"共同出现且相邻此时数值映射列表就变成了包含2-gram特征的特征列表: [1, 34, 21, 1000]这里的"是谁"和"敲动"共同出现且相邻就是bi-gram特征中的一个."敲动"和"我心"也是共现且相邻的两个词汇, 因此它们也是bi-gram特征.假设1001代表"敲动"和"我心"共同出现且相邻那么, 最后原始的数值映射列表 [1, 34, 21] 添加了bi-gram特征之后就变成了 [1, 34, 21, 1000, 1001]
提取n-gram特征
# 一般n-gram中的n取2或者3, 这里取2为例ngram_range = 2def create_ngram_set(input_list):"""description: 从数值列表中提取所有的n-gram特征:param input_list: 输入的数值列表, 可以看作是词汇映射后的列表,里面每个数字的取值范围为[1, 25000]:return: n-gram特征组成的集合eg:>>> create_ngram_set([1, 4, 9, 4, 1, 4]){(4, 9), (4, 1), (1, 4), (9, 4)}"""return set(zip(*[input_list[i:] for i in range(ngram_range)]))input_list = [1, 3, 2, 1, 5, 3]res = create_ngram_set(input_list)print(res)
输出效果
# 该输入列表的所有bi-gram特征{(3, 2), (1, 3), (2, 1), (1, 5), (5, 3)}
文本长度规范及其作用
一般模型的输入需要等尺寸大小的矩阵, 因此在进入模型前需要对每条文本数值映射后的长度进行规范, 此时将根据句子长度分布分析出覆盖绝大多数文本的合理长度, 对超长文本进行截断, 对不足文本进行补齐(一般使用数字0), 这个过程就是文本长度规范.
实现:
from keras.preprocessing import sequence# cutlen根据数据分析中句子长度分布,覆盖90%左右语料的最短长度.# 这里假定cutlen为10cutlen = 10def padding(x_train):"""description: 对输入文本张量进行长度规范:param x_train: 文本的张量表示, 形如: [[1, 32, 32, 61], [2, 54, 21, 7, 19]]:return: 进行截断补齐后的文本张量表示"""# 使用sequence.pad_sequences即可完成return sequence.pad_sequences(x_train, cutlen)# 假定x_train里面有两条文本, 一条长度大于10, 一天小于10x_train = [[1, 23, 5, 32, 55, 63, 2, 21, 78, 32, 23, 1],[2, 32, 1, 23, 1]]res = padding(x_train)print(res)
输出效果
[[ 5 32 55 63 2 21 78 32 23 1][ 0 0 0 0 0 2 32 1 23 1]]
文本数据增强
优势:
- 操作简便, 获得新语料质量高.
方法:
- 回译数据增强法
回译数据增强目前是文本数据增强方面效果较好的增强方法, 一般基于google翻译接口, 将文本数据翻译成另外一种语言(一般选择小语种),之后再翻译回原语言, 即可认为得到与与原语料同标签的新语料, 新语料加入到原数据集中即可认为是对原数据集数据增强.
存在的问题:
- 在短文本回译过程中, 新语料与原语料可能存在很高的重复率, 并不能有效增大样本的特征空间.
高重复率解决办法:
- 进行连续的多语言翻译, 如: 中文—>韩文—>日语—>英文—>中文, 根据经验, 最多只采用3次连续翻译, 更多的翻译次数将产生效率低下, 语义失真等问题.
回译数据增强实现
# 假设取两条已经存在的正样本和两条负样本# 将基于这四条样本产生新的同标签的四条样本p_sample1 = "酒店设施非常不错"p_sample2 = "这家价格很便宜"n_sample1 = "拖鞋都发霉了, 太差了"n_sample2 = "电视不好用, 没有看到足球"# 导入google翻译接口工具from googletrans import Translator# 实例化翻译对象translator = Translator()# 进行第一次批量翻译, 翻译目标是韩语translations = translator.translate([p_sample1, p_sample2, n_sample1, n_sample2], dest='ko')# 获得翻译后的结果ko_res = list(map(lambda x: x.text, translations))# 打印结果print("中间翻译结果:")print(ko_res)# 最后在翻译回中文, 完成回译全部流程translations = translator.translate(ko_res, dest='zh-cn')cn_res = list(map(lambda x: x.text, translations))print("回译得到的增强数据:")print(cn_res)
输出效果
中间翻译结果:['호텔 시설은 아주 좋다', '이 가격은 매우 저렴합니다', '슬리퍼 곰팡이가 핀이다, 나쁜', 'TV가 잘 작동하지 않습니다, 나는 축구를 볼 수 없습니다']回译得到的增强数据:['酒店设施都非常好', '这个价格是非常实惠', '拖鞋都发霉了,坏', '电视不工作,我不能去看足球']

若有收获,就点个赞吧
0 人点赞
