py的优势
Python 作为一门动态编程语言,以简单易用的特性变得越来越流行,同时 Python 具有丰富活跃的生态环境,包含各种任务用途的软件。比如 Web 开发框架 Django、Flask,数据库访问处理 SQLAlchemy,爬虫框架 Scrapy, 数据分析 NumPy, Pandas 等软件包都基于 Python 开发。有了这些高质量软件包的支持,我们就可以完成各种各样的任务需求。
同时 Python 也是一门胶水语言,可以快速绑定到其他语言实现的数据分析框架上,这样由于 Python 动态语言的特性就可以快速实现相关模型。比如 TensorFlow 核心使用 C++ 开发,但是同时提供了 Python 绑定,这样就可以很方便的使用 Python 代码快速学习 TensorFlow 了。同理,当使用 Python 实现数据分析模型以后,如果发现模型中有些部分需要更高性能的编程语言进行实现时,也可以很方便的绑定替换。
感触
好用的设计
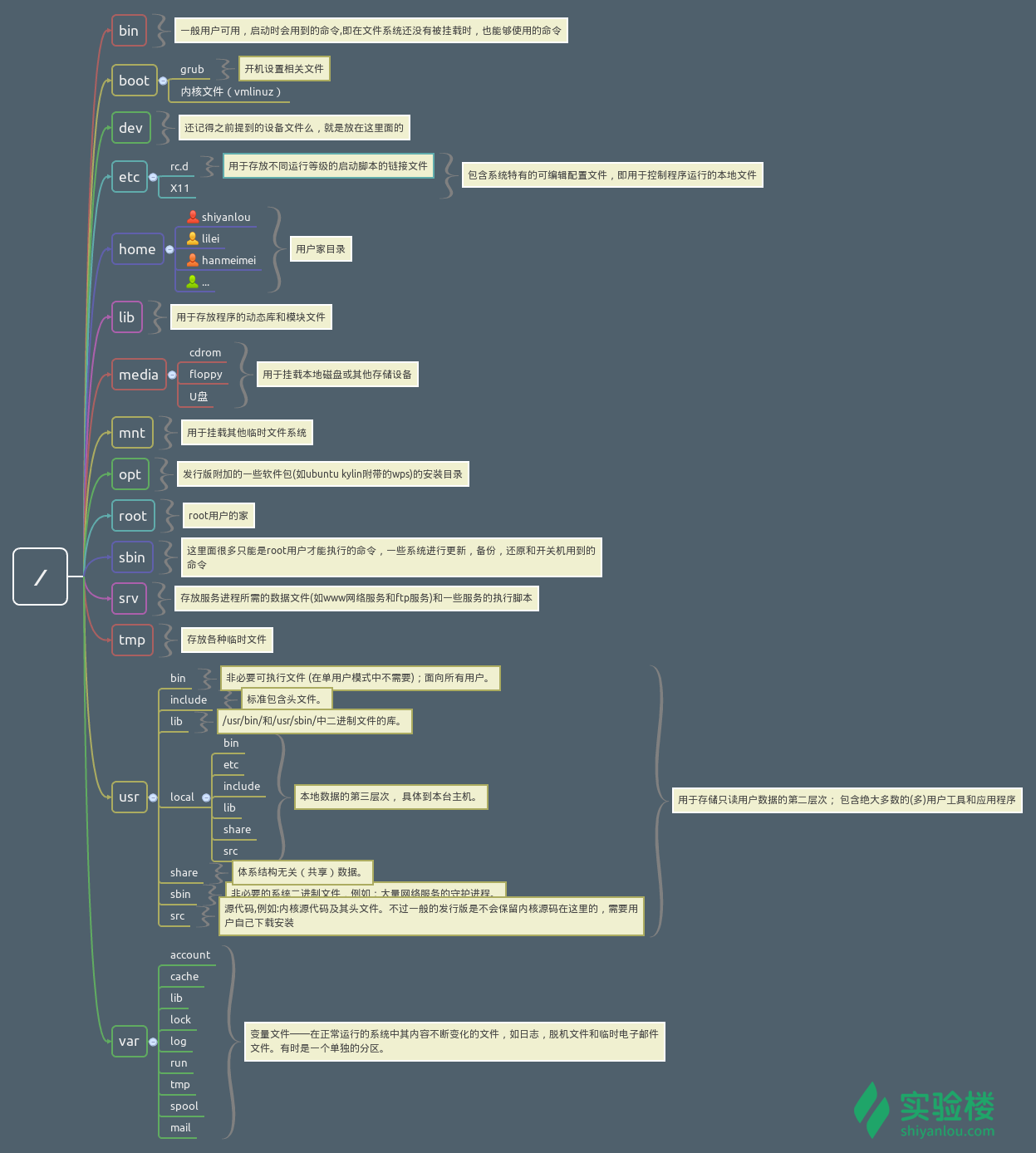
目录结构
应该和计算机系统比较相关
文件操作
ls -al可以看全部目录。仓库主目录有.git隐藏目录,删除的话就是普通的目录了
ls -la创建.git 目录
unzip解压文件
py文件操作
感觉好像和我在processing里用到的java的文件操作差不多?(还是processing的文件操作?
在 Python 中访问文件非常简单,主要通过 open 函数完成相关操作。下面通过代码进行演示,首先通过终端输入以下命令创建 hello.txt文件,Jupyter Notebook 中执行终端命令需要添加 !,本地终端中无需添加
!echo 'hello shiyanlou!' > hello.txtf = open("hello.txt")f.read()
可以指定 open 函数调用参数,如果想写文件,可以通过 open(‘hello.txt’, ‘w+’) 打开文件:
import jsond = [{'id': 5348, 'name': 'Luo'}, {'id': 13, 'name': 'Lei'}]content = json.dumps(d)with open('users.json', 'w+') as f:f.write(content)f = open('users.json')print(f.read())f.close()
以上代码中,先将一个字典通过 json.dumps 转换为 JSON 字符串,然后通过 open(‘users.json’, ‘w+’) 打开文件,并将文件写入到 users.json 文件中。这里需要注意的时候,由于文件对象同时也是一个上下文管理器,所以可以通过 with 关键字打开文件,这样当 with 代码块执行完以后,文件对象就会自动关闭,避免忘记关闭文件的情况发生。
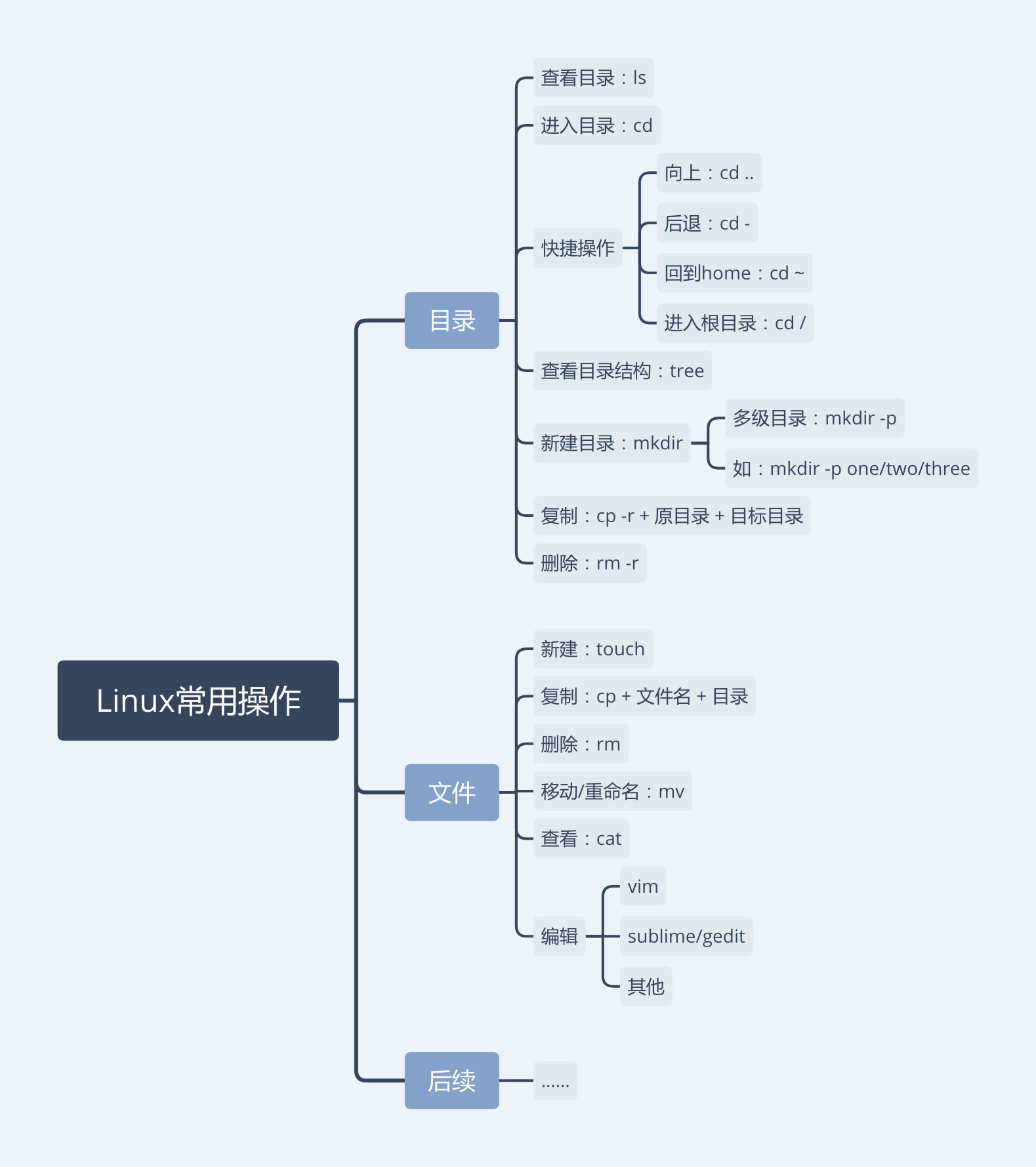
脚本操作
输入python3开始运行脚本语言
terminal操作
python3 xxx.py 直接运行
python3 -i xxx.py
homebrew操作
用途是方便地下载软件安装包,指令为brew xx,但是由于连接的服务器在国外,下载速度很慢,要想用要想办法将服务器路径改成国内的镜像
git操作(在terminal中操作
2022.6.28修订
Source:
菜鸟教程 https://www.runoob.com/git/git-workflow.html
gitee上传教程 这个比较清楚,上传有两种方法,一种是远程复制到本地,一种是本地上传到远程https://gitee.com/help/articles/4120
step0 完全不会git操作的话,可以直接在网站上上传
step1 安装git并配置
官网安装,可用homebrew下载或者直接下载安装包,mac部分自带
#在terminal中git version #检查安装版本git config #查看配置git config --global #更改全局配置
step2.1 设置本地目录作为git仓库(可以用在自己只改公用仓库的一个分支的时候
22.6.28更新:
设置本地目录作为git仓库,可以用在自己只改公用仓库的一个分支的时候,clone远程仓库的话全部分支都会被复制下来.
流程参考这个:https://blog.csdn.net/rory_wind/article/details/108374879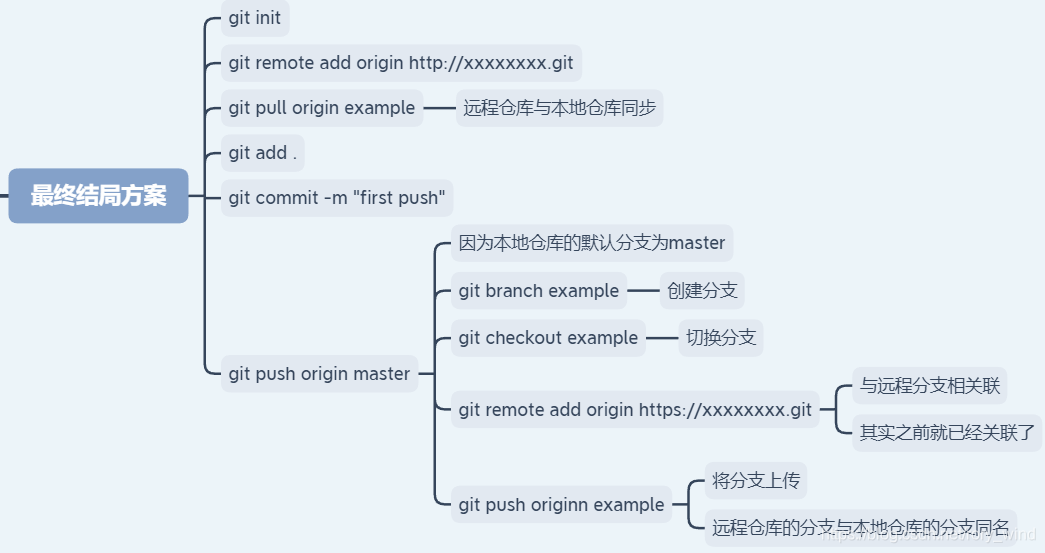
git init [newrepo] #初始化newrepo目录为new repository,不写就是默认当前文件夹
Git 使用 git init 命令来初始化一个 Git 仓库,Git 的很多命令都需要在 Git 的仓库中运行,所以 git init 是使用 Git 的第一个命令。
在执行完成 git init 命令后,Git 仓库会生成一个 .git 目录,该目录包含了资源的所有元数据,其他的项目目录保持不变。
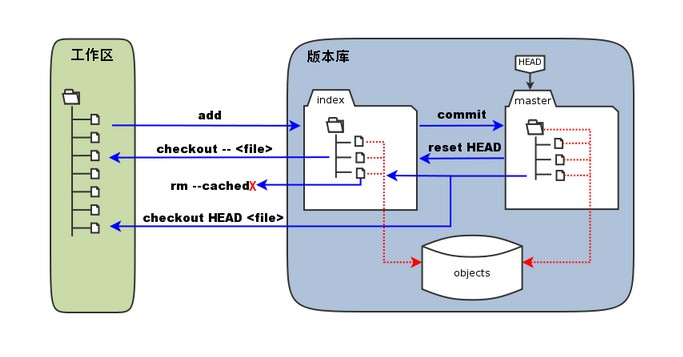
本地工作区-〉本地暂存区
ls -la #查看创建的.git 目录
初始化后,会在 newrepo 目录下会出现一个名为 .git 的目录,所有 Git 需要的数据和资源都存放在这个目录中。
如果当前目录下有几个文件想要纳入版本控制,需要先用 git add 命令告诉 Git 开始对这些文件进行跟踪,然后提交:
git add *.cgit add README
git add [文件名] 本地文件-〉本地暂存区,准备上传
git add . 全部
git rm —cached [文件名]/ git reset —[文件名]取消暂存,git reset —全部撤销
本地暂存区-〉本地版本库
git config -l#查看配置信息,--global user.email/user.name 填写配置信息用户名email|cat -n ~/.gitconfig 也可以查看配置信息git commit -m '初始化项目版本'以上命令将目录下以 .c 结尾及 README 文件提交到仓库中。
git commit -m “first commit[注释]” 本地暂存区-〉本地仓库
检查方法,查看版本历史记录
git log #查看版本区的历史记录|git log [分支名],git log -n查看n个数字,git log --author,git log --graph图示法查看提交历史(?),倒序查看git log --reverse以时间正序排列记录git blame <file> #以列表形式查看指定文件的历史修改记录git status #查看commit状态git diff #比较文件的不同,即暂存区和工作区的差异。git rm #将文件从暂存区和工作区中删除。git mv #移动或重命名工作区文件。#本地查看git log -p #查看所有文件所有详细内容,最好不要看全部,文件全打开了真的很多,按q退出git show #查看最新一次commit,按q退出git log --stat #查看文件的行数,哪些行有删改,按q退出git log --oneline #只显示一行,比较简洁,按q退出git shortlog #看哪些作者改了,不用按q退出git diff #比较的是本地的工作区和本地暂存区的区别
git log有很多参数可以选择
https://blog.csdn.net/jjlovefj/article/details/86476925
git diff之间的比较
https://zhuanlan.zhihu.com/p/152624325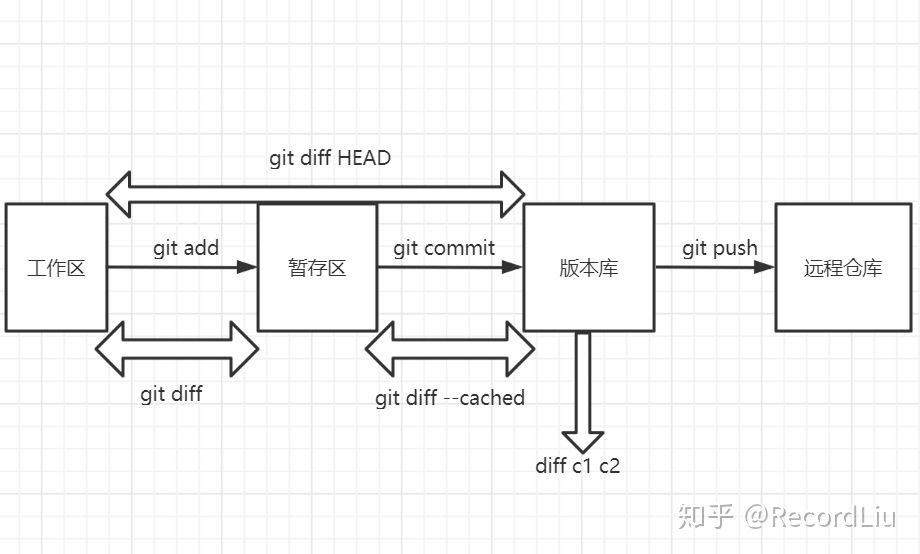
step3 本地版本库-〉远程仓库
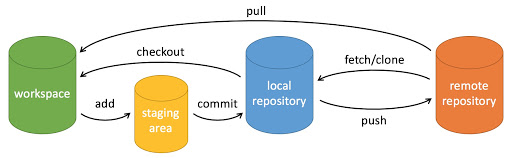
git remote add [主机名默认为origin] [仓库链接],git remote -v查看本地仓库关联的远程仓库git push [主机名默认为origin] [分支名默认为master] 本地仓库-〉远程仓库
检查方法
git branch -avv查看所有分支信息,可以看到此时远程仓库分支的版本号和本地分支版本号一致,说明上传成功(一般对比前4位即可)
step 2.2 远程仓库-〉本地,然后再来操作(这个感觉更简单
#1.克隆远程仓库到本地(自动完成了remote操作,所以不需要remote add)git clone [url] #拷贝git仓库到本地|git [本地主机名] clone -o [url] [本地仓库的主目录名]#2.上传git add .git commit -m "commit comment"git push [origin] [master]#3.下载#还没有很会用fetch+merge,下载什么分支到自己的什么分支?#保险起见用这两个比较好,不会直接覆盖掉本地的内容git fetch [origin] [master]#fetch后怎么比较和本地的区别?git merge [origin/master]#merge后比较区别#如果纯下载不影响本地文件可以用这个git pull [origin] [master]
git fetch+merge 和 git pull 区别?主要是会不会直接覆盖本地
https://zhuanlan.zhihu.com/p/123370920
merge后比较区别,merge的时候用 —no-of
https://www.zhihu.com/question/33316478
修改(版本回退)
方案一:修改文件后从头提交
在git目录下 echo ‘str’ > text.txt
git diff查看修改状态 git diff —cached查看全部修改
方案二:撤销最近一次提交,修改后再提交
vim编辑器
终端 vim xxx.py
i insert
esc+:wq back to terminal
chmod +x xxx.py 执行权限
./xxx.py 运行
#!/usr/bin/env python3 vim里py文件开头要写入
输入输出
格式化输出
https://blog.csdn.net/python1639er/article/details/112325519
一、占位符的3种形式
- ‘%.3f’%name #保留3位小数的浮点数
- ‘{:.3f}’.format(name) #保留3位小数的浮点数
- (python 3.6) f’{name:.{3}}’ #总共保留3位数字 #?具体区别原因未知 ```python value = 12.34567 print(f’{value:{10}.{4}}’) print(‘{:10.4f}’.format(value))
runfile(‘/Users/kakazou/.spyder-py3/temp.py’, wdir=’/Users/kakazou/.spyder-py3’) 12.35 12.3457
二、2、3形式中活用槽的嵌套,实现定义格式中的参数用变量表示<br />(python123)练习3:<a name="nFFmY"></a>### 星号三角形---读入一个整数N,N是奇数,输出由星号字符组成的等边三角形,要求:<br />第1行1个星号,第2行3个星号,第3行5个星号,依次类推,最后一行共N的星号。---| | 输入示例 | 输出示例 || --- | --- | --- || 示例1 | 3 | * || | | *** |使用2形式:```pythonn = eval(input())for i in range(1,n+1,2):print("{0:^{1}}".format('*'*i, n))
关键是对.format()中槽机制的理解,槽中可以嵌套槽,用来表示宽度、填充等含义。
使用3形式:
num = int(input())for i in range(num//2+1):out = '*'*(i*2+1)print(f'{out:^{num}}')
数据结构
在 Python 中 我们不需要为变量指定数据类型。
- 不可变数据(3 个):Number(数字)、String(字符串)、Tuple(元组);
- 可变数据(3 个):List(列表)、Dictionary(字典)、Set(集合)。
一行内可以进行多个变量赋值,可以用来交换 a,b=b,a //原理是利用了tuple封装、解封的性质(tuple是使用,创建的)
关键字运算符表达式
数学、关系、逻辑运算符
== 数值比较
is 对象身份比较,比的是内存位置
感觉对于可变操作之后判断一下调整的是哪个对象还是挺有用的
eval()
内建函数
去掉参数最外侧的引号并执行余下语句
可以对表达式运算求值,数字用二进制表示也可以运算
>>>x = 7>>> eval( '3 * x' )21>>> eval('pow(2,2)')4>>> eval('2 + 2')4>>> n=81>>> eval("n + 4")85
类型转换
- float()转换时str时忽略空格
a = 'time is : 3.5.'b = a.split(':')print(b)d = b[1]print(d)print(type(d))print(d[:-1])c = float(d[:-1])print(c)
Numbers(immutability)
interger, floor
bin(), complex
Strings(immutability)
运算符
formatted output
- f-string expression
f’hello, i am {name}, my salary is {salary:.2f}’
or f’hello, i am {name}, my salary is {salary:.2f}’
- format method
"Year {} Rs. {:.2f}".format(year, value) 称为字符串格式化,大括号和其中的字符会被替换成传入 str.format() 的参数,也即 year 和 value。其中 {:.2f}的意思是替换为 2 位精度的浮点数。
print(a,end=’ ‘) //默认end是换行符
slicing and indexes
methods
- str.find(element, srtat index, stop index) ->output:index
找不到的话是-1(找到头了也没找到)
类似与str.index
- ‘’.join连接字符串
-
notes
?不确定正确性,查不到,直接创建字符串的话也不会有这个长度多了一个的问题。——\0 伪0,好像是加了end=‘’之后字符串才会有,不这样存的话不会有(所内py培训)
Booleans
True or False
Lists
运算符
create-列表推导式
>>> squares = []>>> for x in range(10):... squares.append(x**2)...>>> squares[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]squares = list(map(lambda x: x**2, range(10)))squares = [x**2 for x in range(10)]>>> [(x, y) for x in [1,2,3] for y in [3,1,4] if x != y][(1, 3), (1, 4), (2, 3), (2, 1), (2, 4), (3, 1), (3, 4)]>>> combs = []>>> for x in [1,2,3]:... for y in [3,1,4]:... if x != y:... combs.append((x, y))...>>> combs[(1, 3), (1, 4), (2, 3), (2, 1), (2, 4), (3, 1), (3, 4)]>>> a=[1,2,3]>>> z = [x + 1 for x in [x ** 2 for x in a]]>>> z[2, 5, 10]
matrix and unpacking
slicing and indexes
List[::-1] reverse
切片操作不改变列表么,当对切片赋值,此操作可以改变列表的尺寸,或清空它。严格来说,这里并不算真正的切片操作,只是上面代码中赋值运算符左边的这种操作与切片操作形式一样而已。
methods
Addition: append(obj), insert, extend(seq)
Deletion: pop(index=-1), remove(obj)
栈:后进先出 list.pop()
队列:先进先出 list.pop(0)
Find: index,count
Order: sort, reverse
insert list.insert(index,value)
function
len, max/min, sort, enumerate()枚举(默认从0开始)
Dictionaries
Keys must be immutable
dict.items()方法 返回可遍历的(键, 值) 元组数组。
>>> data{'Kushal': 'Fedora', 'Jace': 'Mac', 'kart_': 'Debian', 'parthan': 'Ubuntu'}>>> for x, y in data.items():... print("{} uses {}".format(x, y))...Kushal uses FedoraJace uses Mackart_ uses Debianparthan uses Ubuntu
create
>>> data = {'kushal':'Fedora', 'kart_':'Debian', 'Jace':'Mac'}>>> data{'kushal': 'Fedora', 'Jace': 'Mac', 'kart_': 'Debian'}>>> data['kart_']'Debian'#可以通过包含键值对的元组创建字典>>> dict((('Indian','Delhi'),('Bangladesh','Dhaka'))){'Indian': 'Delhi', 'Bangladesh': 'Dhaka'}
add/ delete
>>> data['parthan'] = 'Ubuntu'>>> data{'kushal': 'Fedora', 'Jace': 'Mac', 'kart_': 'Debian', 'parthan': 'Ubuntu'}>>> del data['kushal']>>> data{'Jace': 'Mac', 'kart_': 'Debian', 'parthan': 'Ubuntu'
Sets
集合是一个无序不重复元素的集。基本功能包括关系测试和消除重复元素。集合对象还支持 union(联合),intersection(交),difference(差)和 symmetric difference(对称差集)等数学运算。
create
大括号或 set() 函数可以用来创建集合。注意:想要创建空集合,你必须使用 set() 而不是 {}。后者用于创建空字典,我们在下一节中介绍的一种数据结构。
logical operation
>>> basket = {'apple', 'orange', 'apple', 'pear', 'orange', 'banana'}>>> print(basket) # 你可以看到重复的元素被去除{'orange', 'banana', 'pear', 'apple'}>>> 'orange' in basketTrue>>> 'crabgrass' in basketFalse>>> # 演示对两个单词中的字母进行集合操作...>>> a = set('abracadabra')>>> b = set('alacazam')>>> a # a 去重后的字母{'a', 'r', 'b', 'c', 'd'}>>> a - b # a 有而 b 没有的字母{'r', 'd', 'b'}>>> a | b # 存在于 a 或 b 的字母{'a', 'c', 'r', 'd', 'b', 'm', 'z', 'l'}>>> a & b # a 和 b 都有的字母{'a', 'c'}>>> a ^ b # 存在于 a 或 b 但不同时存在的字母{'r', 'd', 'b', 'm', 'z', 'l'}
add/ delete
>>> a = {'a','e','h','g'}>>> a.pop() # pop 方法随机删除一个元素并打印'h'>>> a.add('c')>>> a{'c', 'e', 'g', 'a'}
Tuples(immutability)
创建 以,分割
只有一个元素时也需要,
a = 123,b = (123,)c = (123)# type(a,b,c) #这样是不行的,type函数默认后面的a,b,c是一个元组了!>>> type(a)<class 'tuple'>>>> type(b)<class 'tuple'>>>> type(c)<class 'int'>
#!/usr/bin/env python3days = int(input("Enter days: "))print("Months = {} Days = {}".format(*divmod(days, 30)))
divmod(num1, num2) 返回一个元组,这个元组包含两个值,第一个是 num1 和 num2 相整除得到的值,第二个是 num1 和 num2 求余得到的值,然后我们用 * 运算符拆封这个元组,得到这两个值。
条件判断
任何不为0的值都为真值
if单向判断
if……else双向
if……elif……else多向
可以暂时不写pass
循环
- for循环
for in:
要特别注意的是,range() 函数返回的并不是列表而是一种可迭代对象(range对象),可以通过list(range())转换成列表。range(start index, stop index, step(could be negative))
print('My name is')for i in range(5):print('Jimmy Five Times (' + str(i) + ')')
- while循环
有些编程语言没有for循环,只有while循环,这个时候就需要设定累加的index
print('My name is')i = 0while i < 5:print('Jimmy Five Times (' + str(i) + ')')i = i + 1
关键字:Break/ continue
-
函数
def 函数名(参数=可设置一个值为没有传入参数时的默认值,*b可设置为数量可变参数), 关于参数有一件特殊的事情值得注意:保存在参数中的值,在函数返回后就丢失了。大多数参数是由它们在函数调用中的位置决定的,但是还可以通过名称来传入参数。
- return 定义返回值或表达式, 不设置的时候,python程序默认是None(无返回值,例如print()函数的返回值就是None)
?匿名函数
```python d = {‘k1’: 5, ‘k2’: 2, ‘k3’: 3}
d.items() sorted(d.items(), key=lambda x: x[1])
以上代码中,首先定义了一个字典,然后通过 sorted 函数结合匿名函数对字典的键值对安装值得大小进行了排序。这里的匿名函数 lambda x: x[1] 非常简单,返回键值元组的第二个元素,例如 ('k2', 2) 中的 2 。<a name="YLXQP"></a># 对象和类类相当于自定义一个像list等等的分类,然后自己添加想用的属性进去,只需要class.就有很多自定义的方法可以使用啦```pythonclass Course:""" course class"""def __init__(self, name, desc):self.name = nameself.description = descself.labs = []def register_lab(self, lab):self.labs.append(lab)@property #使用装饰器def lab_count(self):return len(self.labs)
以上代码中,我们定义了类 Course ,该类有 registerlab 和 labcount 两个实例方法。实例方法第一个参数是 self,代表实例自己。该类初始化时接受 name 和 desc 两个参数,也就是 __init 方法的参数。
以上代码中,我们使用了 property 装饰器,该装饰器可以使得函数像属性一些样访问。装饰器在 Python 中是作用非常强大,其主要作用就是装饰一个函数并改变函数的访问方式。
以上代码中,我们使用 Course生成了一个 course 示例。可以看到传递的参数其实就是 init 的方法的参数列表。接着可以通过实例访问在 init 方法中定义的属性,比如 course.name 和 course.description。由于使用了属性装饰器,所以可以像访问属性一样通过 course.lab_count 访问 lab_count 方法。
For developers
Foundation
代码风格建议
建议遵守以下约定:
- 使用 4 个空格来缩进
- 永远不要混用空格和制表符
- 在函数之间空一行
- 在类之间空两行
- 字典,列表,元组以及参数列表中,在
,后添加一个空格。对于字典,:后面也添加一个空格 - 在赋值运算符和比较运算符周围要有空格(参数列表中除外),但是括号里则不加空格:
a = f(1, 2) + g(3, 4)
Comments
- 分行注释问题
单行注释:#
多行注释:在每一行注释前添加#,前后3个‘(⚠️实际上这是建立了一个没有分配给任何变量的字符串,在某些情况下可能会出错)
类方法:前后3个‘,添加到类的doc属性中去
- 写注释的方法
退出/结束
- ctrl+c(mac 用 vscode的时候好像不行)
- 要介绍的最后一个控制流概念,是如何终止程序。当程序执行到指令的底部时,
总是会终止。但是,通过调用 sys.exit()函数,可以让程序终止或退出。因为这个函
数在 sys 模块中,所以必须先导入 sys,才能使用它。
库/包
可以安装anaconda,更方便地进行环境的搭建。
导入方法
- import pandas
import matplotlib.pyplot as plt
- from sklearn.cluster import KMeans
使用这种形式的 import 语句,调用 random模块中的函数时不需要 random.前缀。
但是,使用完整的名称会让代码更可读,所以最好是使用普通形式的 import 语句。
中文分词jieba
【基于共现提取《釜山行》人物关系并用关系网络可视化from蓝桥云课】
1.准备剧本busan.txt
2.安装sudo pip3 install jieba
3.准备人名辞典dict.txt 格式:石宇 100 nr(jieba库人名标注)
4.准备变量
根据后面使用到的方法来设计
在代码中,我使用字典类型names保存人物,该字典的键为人物名称,值为该人物在全文中出现的次数。我使用字典类型relationships保存人物关系的有向边,该字典的键为有向边的起点,值为一个字典edge,edge的键是有向边的终点,值是有向边的权值,代表两个人物之间联系的紧密程度。lineNames是一个缓存变量,保存对每一段分词得到当前段中出现的人物名称,lineName[i]是一个列表,列表中存储第i段中出现过的人物。
5.根据每行赋权重
6.去除冗余
# -*- coding: utf-8 -*-
import os, sys #操作系统相关函数需要用
import jieba, codecs, math
import jieba.posseg as pseg #jieba词性
#4.准备变量
names = {} # 姓名字典,该字典的键为人物名称,值为该人物在全文中出现的次数
relationships = {} # 关系字典,该字典的键为有向边的起点,值为一个字典edge,edge的键是有向边的终点,值是有向边的权值,代表两个人物之间联系的紧密程度。
lineNames = [] # 每段内人物关系
#4.建立姓名字典及每段人物关系
jieba.load_userdict("dict.txt") # 加载字典
with codecs.open("busan.txt", "r", "utf8") as f:
for line in f.readlines():
poss = pseg.cut(line) # 分词并返回该词词性,cut jieba分词默认精确模式
lineNames.append([]) # 为新读入的一段添加人物名称列表
for w in poss:
if w.flag != "nr" or len(w.word) < 2:
continue # 当分词长度小于2或该词词性不为nr时认为该词不为人名
lineNames[-1].append(w.word) # 为当前段的环境增加一个人物
if names.get(w.word) is None:
names[w.word] = 0
relationships[w.word] = {}
names[w.word] += 1 # 该人物出现次数加 1
#输出检查
#for name, times in names.items():
# print(name, times)
#5.根据每行赋权重
for line in lineNames: # 对于每一段
for name1 in line:
for name2 in line: # 每段中的任意两个人
if name1 == name2:
continue
if relationships[name1].get(name2) is None: # 若两人尚未同时出现则新建项
relationships[name1][name2]= 1
else:
relationships[name1][name2] = relationships[name1][name2]+ 1 # 两人共同出现次数加 1
#6.去除冗余
with codecs.open("busan_node.txt", "w", "gbk") as f:
f.write("Id Label Weight\r\n")
for name, times in names.items():
f.write(name + " " + name + " " + str(times) + "\r\n")
with codecs.open("busan_edge.txt", "w", "gbk") as f:
f.write("Source Target Weight\r\n")
for name, edges in relationships.items():
for v, w in edges.items():
if w > 3:
f.write(name + " " + v + " " + str(w) + "\r\n")
7.可视化软件gephi
启动
$ cd gephi/gephi-0.9.1/bin
$ ./gephi
调节画图参数balabala

环境
spyder
debug

- 可以先设置断点
- 以debug模式运行
- 运行下一行
- 进入结构内部(循环、函数)#小心不要多点,会进入内建函数文档
- 从结构内部出来
- 继续运行到下一个断点,没有断点就运行到最后
- 退出debug模式

vs code配置
添加extension,注意有一些设置需要在setting.json中启用。
调出json的方法:
extension功能快捷键
·yapf整理代码(需要改json)
alt+shift+f
·better comments:几种不同的注释颜色
Jupyter Notebook
Jupyter Notebook 是一个能运行 Python 代码的 Web 应用程序,它是目前进行机器学习实践的主流工具。实验楼依托 Jupyter Notebook,开发出了自己的机器学习 Notebook 在线实验环境。完成本次实验课程内容,你将掌握 Jupyter Notebook 的基本操作,这也是学习后续课程的重要基础。
在谷歌、微软等互联网巨头的赞助下,IPython Notebook 发展成为更加成熟和完善的开源项目,并更名为 Jupyter Notebook。相信部分朋友对这个名字和下面的界面并不陌生。
快捷键
- H:查看所有快捷键。
- S:保存当前 Notebook 内容。
- P:调出 Notebook 命令栏。
- B:在当前单元格下方新建空白单元格。
- M:将单元格格式转换为 Markdown。
- Y:将单元格格式转换为 Code。
- 连续按 D+D:删除当前单元格。(慎用,推荐使用 X 剪切单元格代替,因为其可以起到删除效果,且删错了还可以粘贴回来)
- 连续按 I+I+I:强制中止内核(当某个单元格执行时间较长或卡住时,可以强行中止,中止后前序单元格状态依旧保留,非常好用。)
- Shift + Enter:运行当前单元格内容。(当 Markdown 单元格处于编辑状态时,运行即可复原)

若有收获,就点个赞吧
0 人点赞
