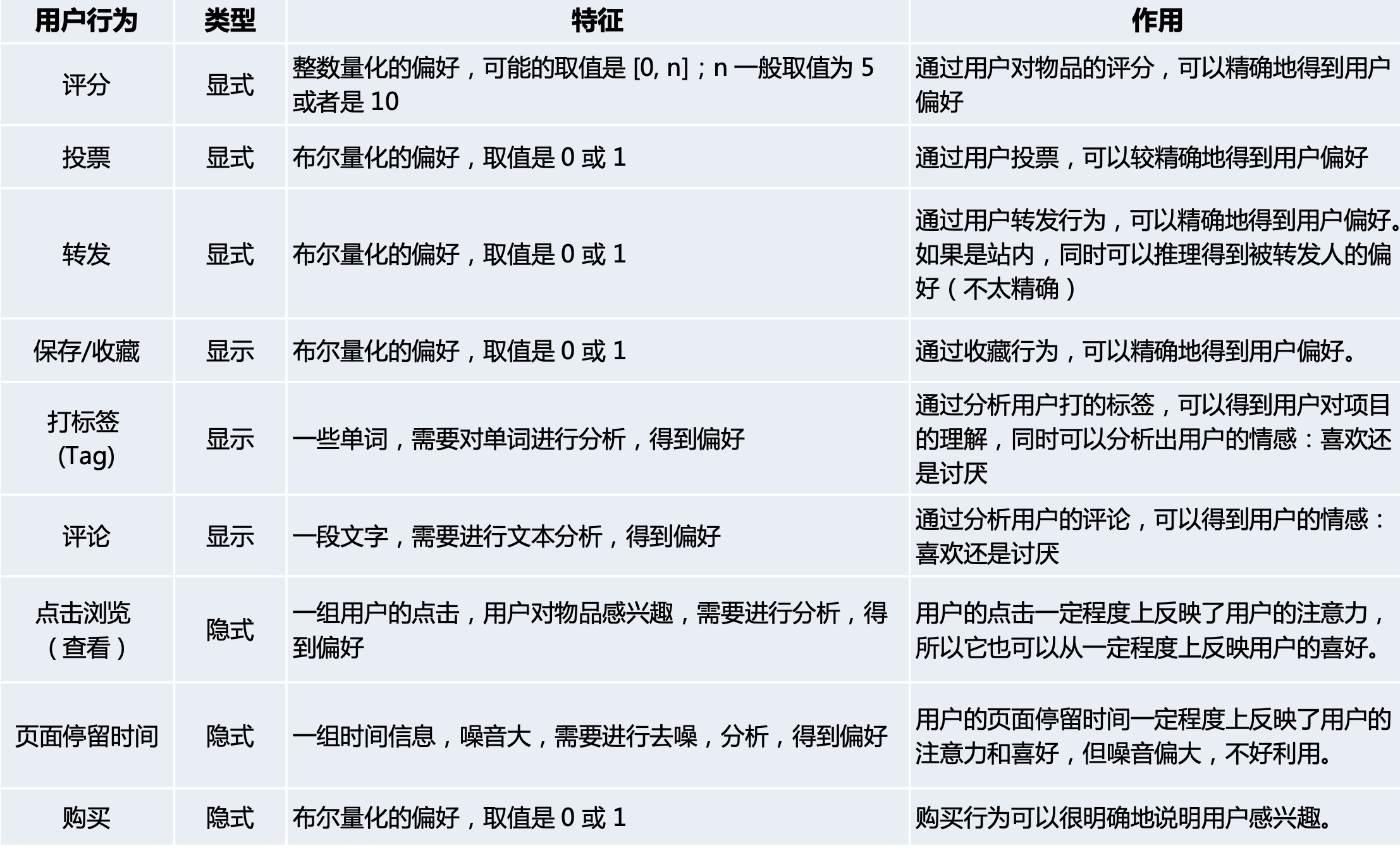
- 基于物品的信息
概念图
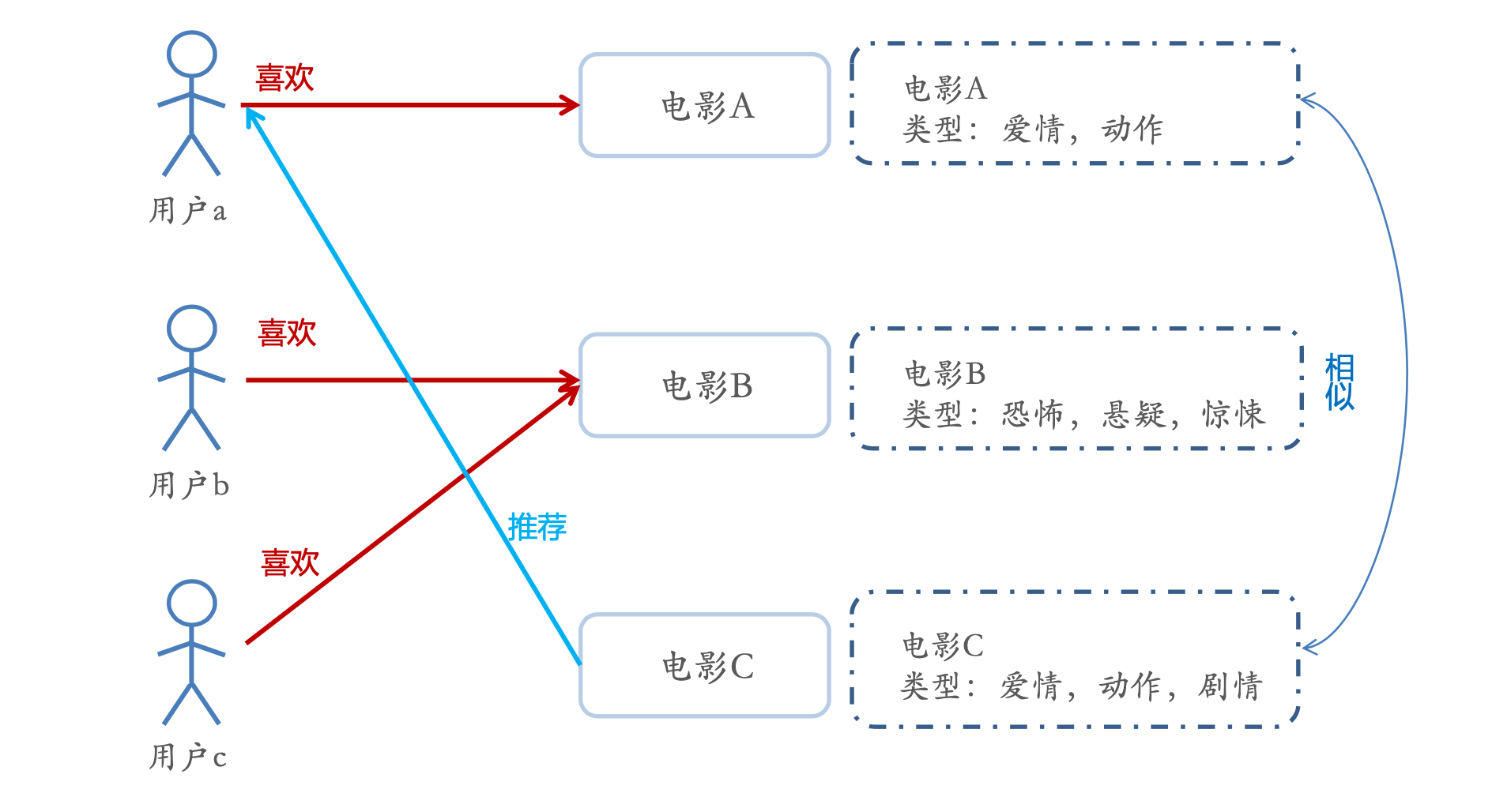
概念
- 定义:(
 ) 根据推荐物品或则内容数据,发现物品的相关性,再基于用户过去的喜爱记录,为用户推荐相似的物品
) 根据推荐物品或则内容数据,发现物品的相关性,再基于用户过去的喜爱记录,为用户推荐相似的物品 - 通过提取物品内在或则外在的特征值,实现 相似度计算
- 将 用户个人文本信息的特征 和 物品的特征 相匹配,即可得到用户对物品的喜爱程度
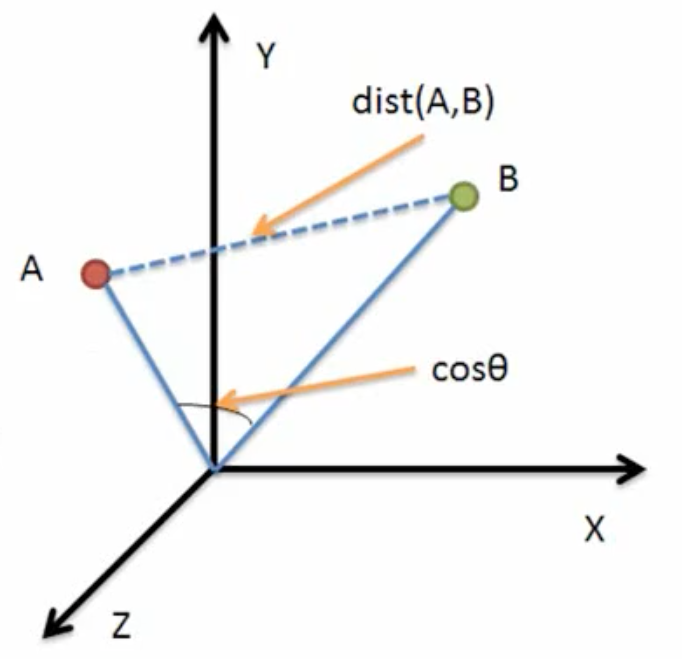
什么是相似度计算?
- 采用:余弦相似度
- 公式:

如图:
什么是用户个人文本信息的特征提取?
- 分词、语义处理和情感处理 (
 )
) - 潜在语义分析 (
 )
)
什么是物品特征的提取?
- 专家标签 (
 )
) - 用户自定义标签 (
 )
) - 降维分析数据、提取隐语义标签 (
 )
)
基于内容推荐系统的高层次结构
概念图
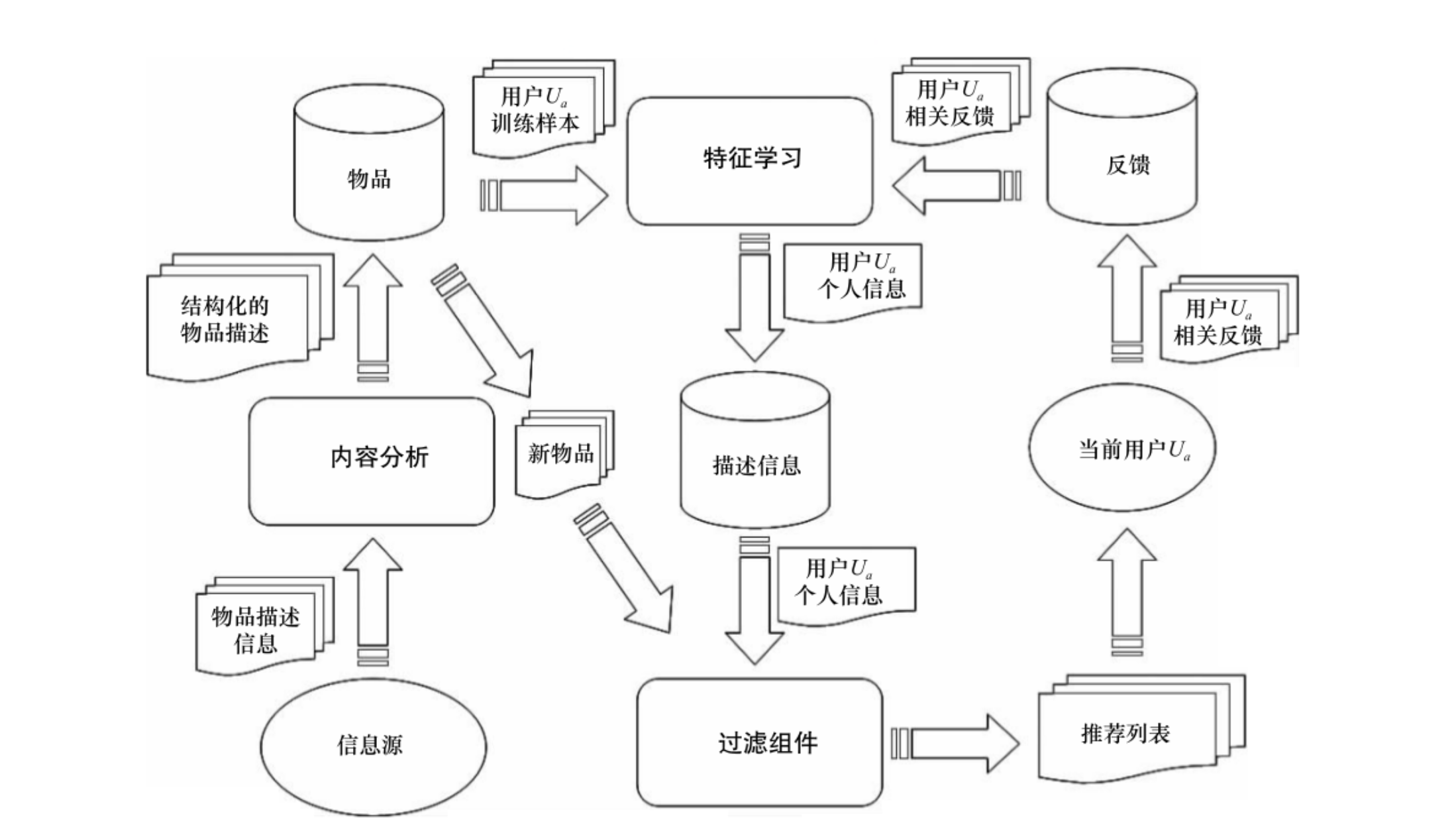
什么是特征工程?
- 以房屋是否售出为例
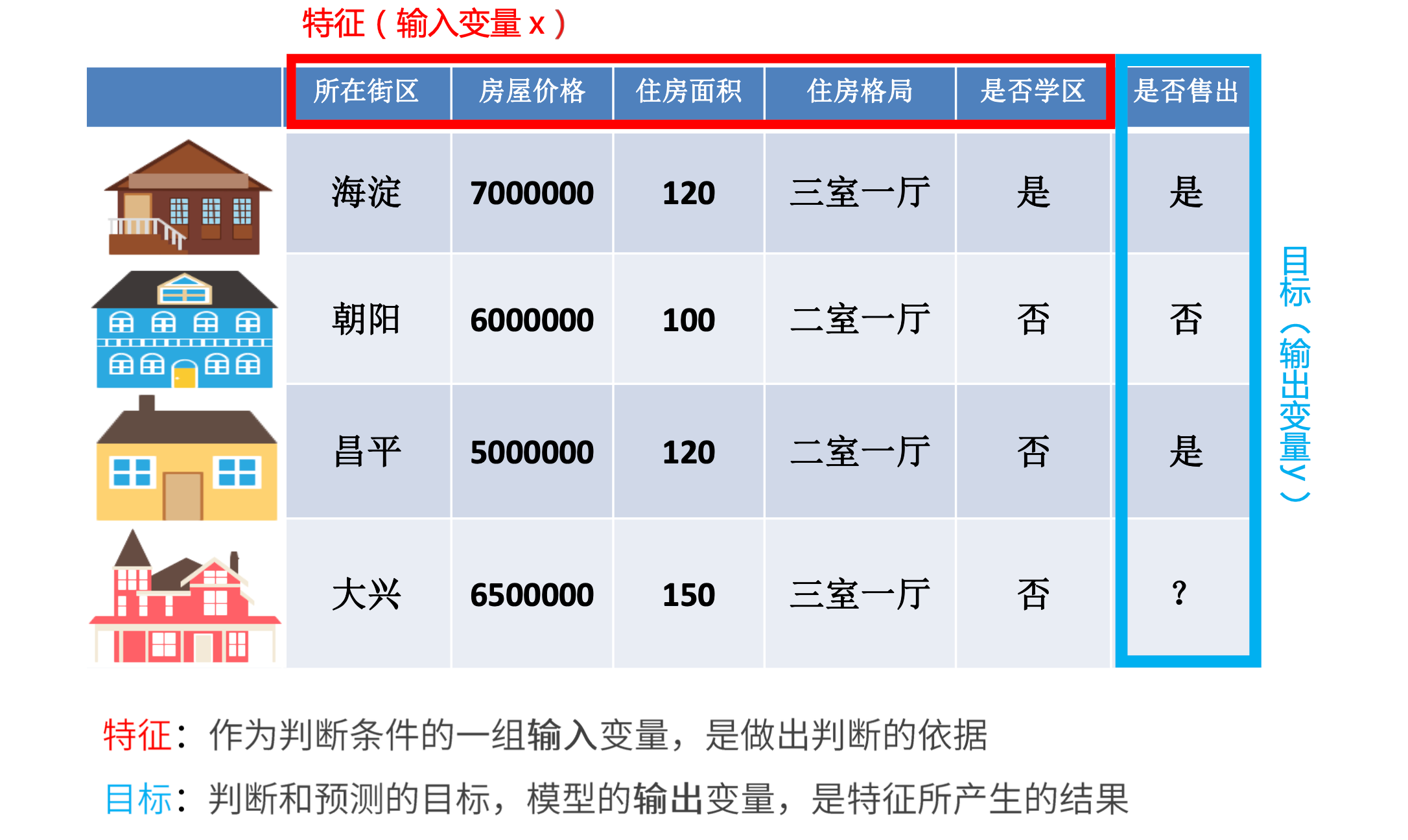
什么是特征?
- 定义:数据中抽取出来的对结果预测有用的信息
- 特征的个数即数据的观测维度
- 特征工程最用:从专业背景知识和技巧处理数据,使得特征能够在机器学习算法上发挥更好作用的过程
- 特征工程包括:特征清洗 (采样、清洗异常样本),特征处理和特征选择
- 特征按照不同的数据类型 (离散型和连续型) 有不同的特征处理方法
- 数值型
- 类别型
- 时间型
- 统计型
数值型
- 定义:连续型数值表示当前维度,通常会对数值特征进行数学上的处理,主要做法是 归一化 和 离散化
- 归一化:特征之间应该是平等的,区别应当体现在特征内部;有些特征数值特别大而有些特征数值特别小,会因为本身的幅值差异造成机器学习效果不佳
- 公式:

- 公式:
- 例如,对房屋中的房屋价格和住房面积进行归一化处理:
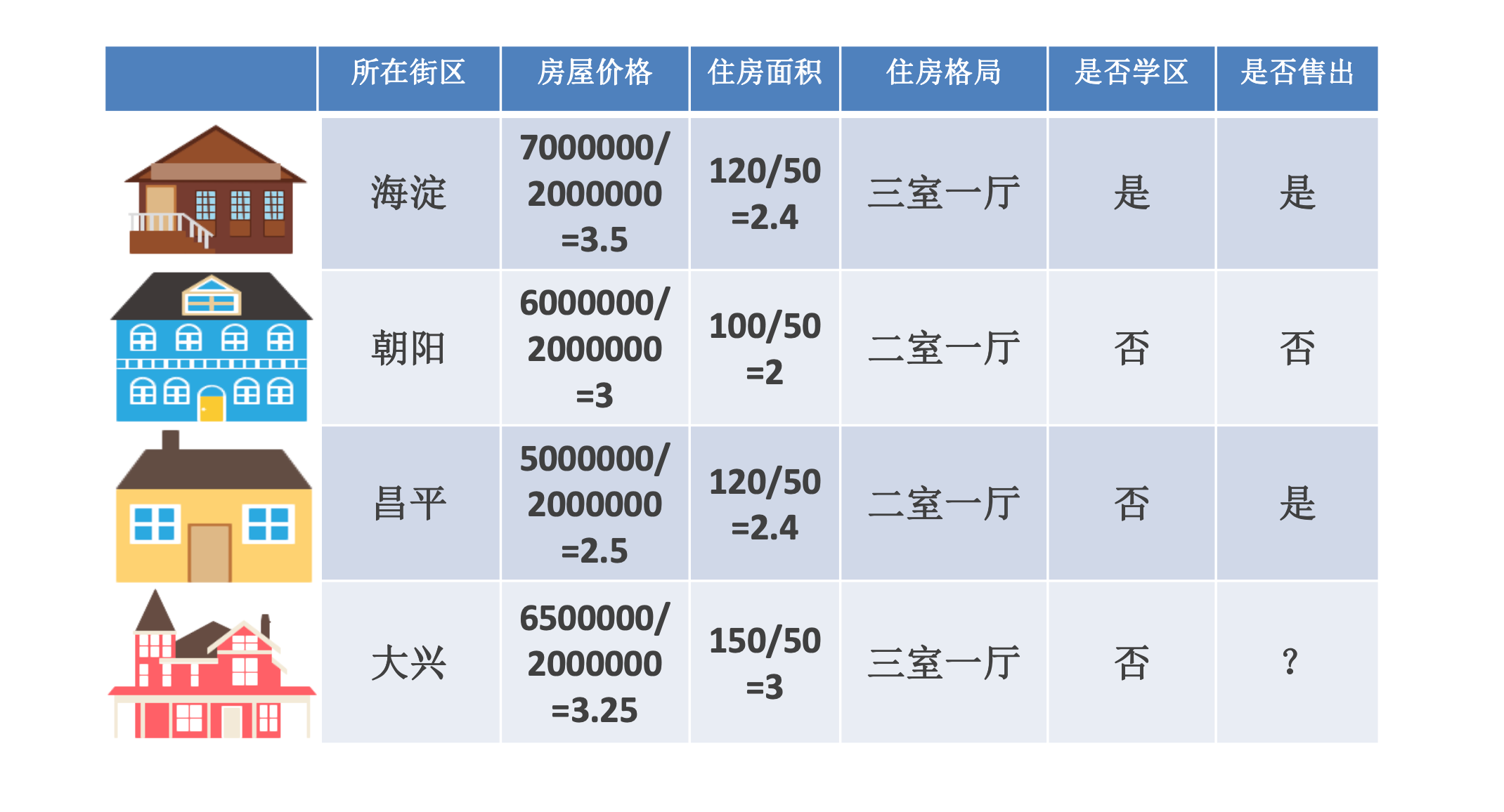
- 离散化:等步长 和 等频
- 等步长
- 等频:
min -> 25% -> 75% -> max
类别型
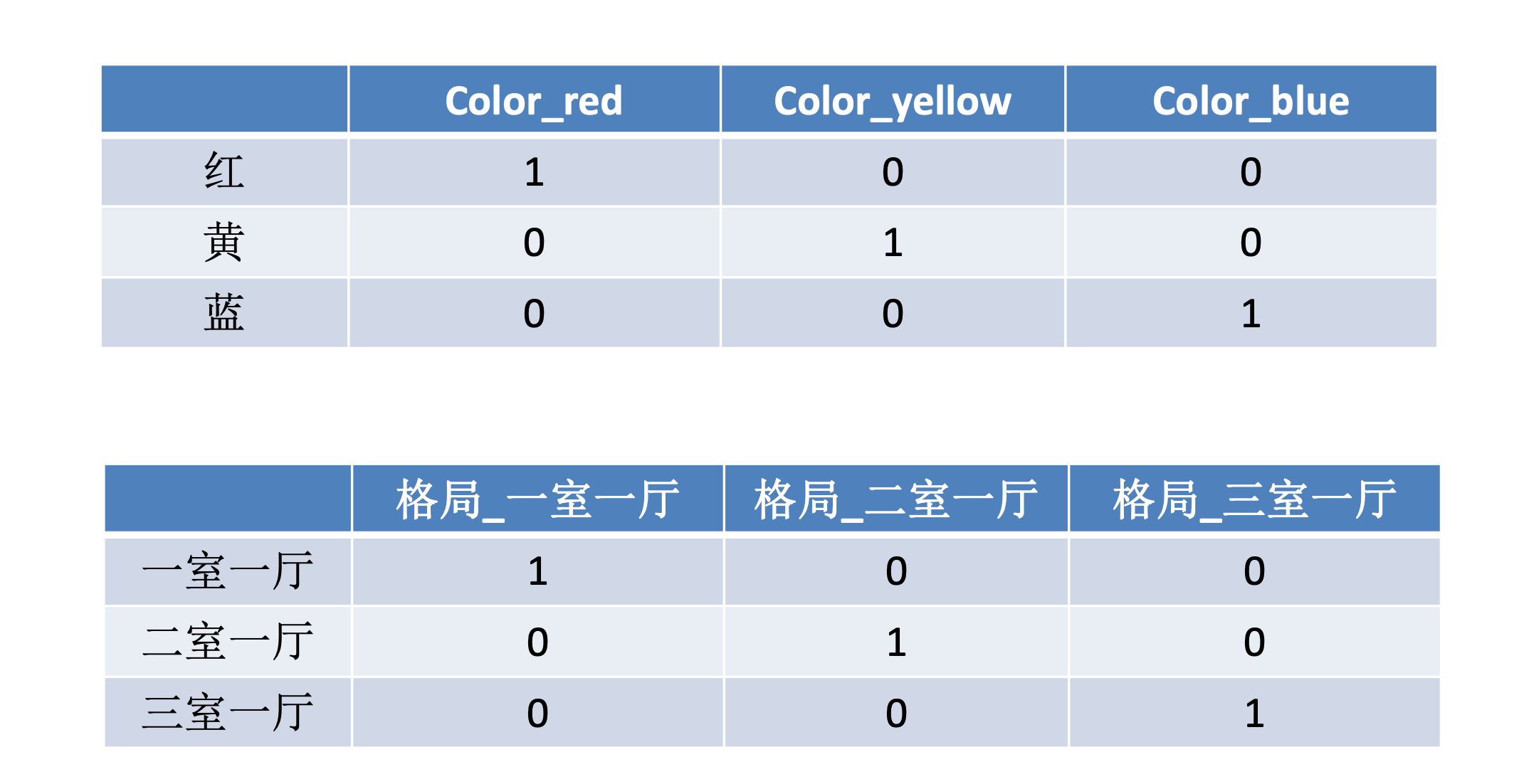
- 定义:离散型,类别型数据本身没有大小关系,需要将它们编码为数字,但它们之间不能有预先设定的大小关系,因此既要让数据公平平等,也要区分数据类别,有效的作法 one-hot 编码
- 独热编码
 :
:- 例如将数据处理为以下格式:
时间型
- 连续型或者离散型
- 连续型:
- 持续时间 (持续上网的时间)
- 间隔时间
- 离散型
- 一天中哪几个时间段
- 一周中的星期几
- 一年中的哪个月/星期
- 工作日/周末
统计型
- 加减平均:商品价格高于平均多少
- 分为线:商品属于售出商品价格的分位线
- 次序性:商品处于热门商品的第几位
- 比例类:商品的好/中/差比例
什么是反馈数据?
基于 UGC 的推荐
- 用户用标签来描述对物品的看法,所以用户生成标签 () 是联系用户和物品的纽带,也是反映用户兴趣的重要数据源
- 用户标签行为的数据集一般由三元组 (用户,物品,标签) 的集合表示,其中一条记录 (
 ) 表示用户
) 表示用户  给物品
给物品  打上了标签
打上了标签 
- 简单算法流程
 :
:- 统计用户最常用的标签
- 对于每个标签,统计被打过这个标签次数最多的物品
- 对于一个用户,首先找到当前用户最常用的标签,然后找到该标签最热门的物品,推荐给该用户
- 即用户
 对物品
对物品  的兴趣公式 :
的兴趣公式 :
其中 表示用户 打过标签 的次数
表示用户 打过标签 的次数  表示物品 被打过标签 的次数
表示物品 被打过标签 的次数
- 存在一个问题:如果某一个热门物品同时对应着热门标签,那么推荐的个性化、新颖度就会降低
- 如何解决:TF-IDF
TF-IDF
- 词频-逆文档频率 (
 ) 是一种用于资讯检索和文本挖掘的常用加权技术
) 是一种用于资讯检索和文本挖掘的常用加权技术  是一种统计方法,用于评估一个字词对以一个文件集或者语料库中的一份文件的重要程度;字词的重要性随着它在文件中出现的次数成正比增加,但是同时会随着它在语料库中的出现的频率成反比下降
是一种统计方法,用于评估一个字词对以一个文件集或者语料库中的一份文件的重要程度;字词的重要性随着它在文件中出现的次数成正比增加,但是同时会随着它在语料库中的出现的频率成反比下降
即:
- 词频 (
 )
)- 指的是某一个给定的词语在该文件中出现的频率。这个数字是对词数的归一化,以防止偏向更长的文件。(同一个词语在长文件里可能会比短文件有更高的词数,而不管该词语重要与否)
 其中
其中  表示词语 在文档
表示词语 在文档  中出现的频率 , 表示 在 中出现的次数 ,n{*,j} 表示文档 的总词数
中出现的频率 , 表示 在 中出现的次数 ,n{*,j} 表示文档 的总词数
- 逆文档频率 (
 )
)- 指的是一个词语普遍重要性的度量,某一特定词语的 $IDF$ ,可以由总文档数目除以包含该词语的文档的数目,再将得到的商对数:

其中, 表示词语 在文档集中的逆文档频率,
表示词语 在文档集中的逆文档频率, 表示文档集中的文档总数,
表示文档集中的文档总数, 表示文档集中包含了词语 的个数
表示文档集中包含了词语 的个数
- 指的是一个词语普遍重要性的度量,某一特定词语的 $IDF$ ,可以由总文档数目除以包含该词语的文档的数目,再将得到的商对数:
- 的主要思想是:如果某个词或则短语在一篇文章中出现的频率
 高,并且在其他文章中很少出现,则认为此词或则短语具有较好的类别区分能力 ,适合用来分类
高,并且在其他文章中很少出现,则认为此词或则短语具有较好的类别区分能力 ,适合用来分类 - 加权的各种形式常被搜索引擎应用,作为文件与用户查询之间相关程度的度量
TF-IDF 对基于 UGC 的推荐的改进
- 为避免热门标签和热门物品获得更多的权重,需要对 “热门” 进行惩罚
- 借鉴 TF-IDF 的思想,以一个物品的所以标签作为 “文档” ,标签作为 “词语”,从而计算标签的 “词频” (在物品所有标签中的频率) 和 “逆文档频率” (在其他物品标签中普遍出现的频率)
- 对热门标签和热门物品的惩罚:

其中, 记录了标签 被多少用户使用过,
记录了标签 被多少用户使用过, 记录了物品 被多少个不同的用户打过标签
记录了物品 被多少个不同的用户打过标签

若有收获,就点个赞吧
0 人点赞

{kind=link}