背景
项目以推荐系统建设领域知名的经过修改过的 MovieLens 数据集作为依托,以 某科技公司电影网站真实业务数据架构为基础,构建了符合教学体系的一体化的电影推荐系统,包含了离线推荐与实时推荐体系,综合利用了协同过滤算法以及基于 内容的推荐方法来提供混合推荐。提供了从前端应用、后台服务、算法设计实现、平台部署等多方位的闭环的业务实现。
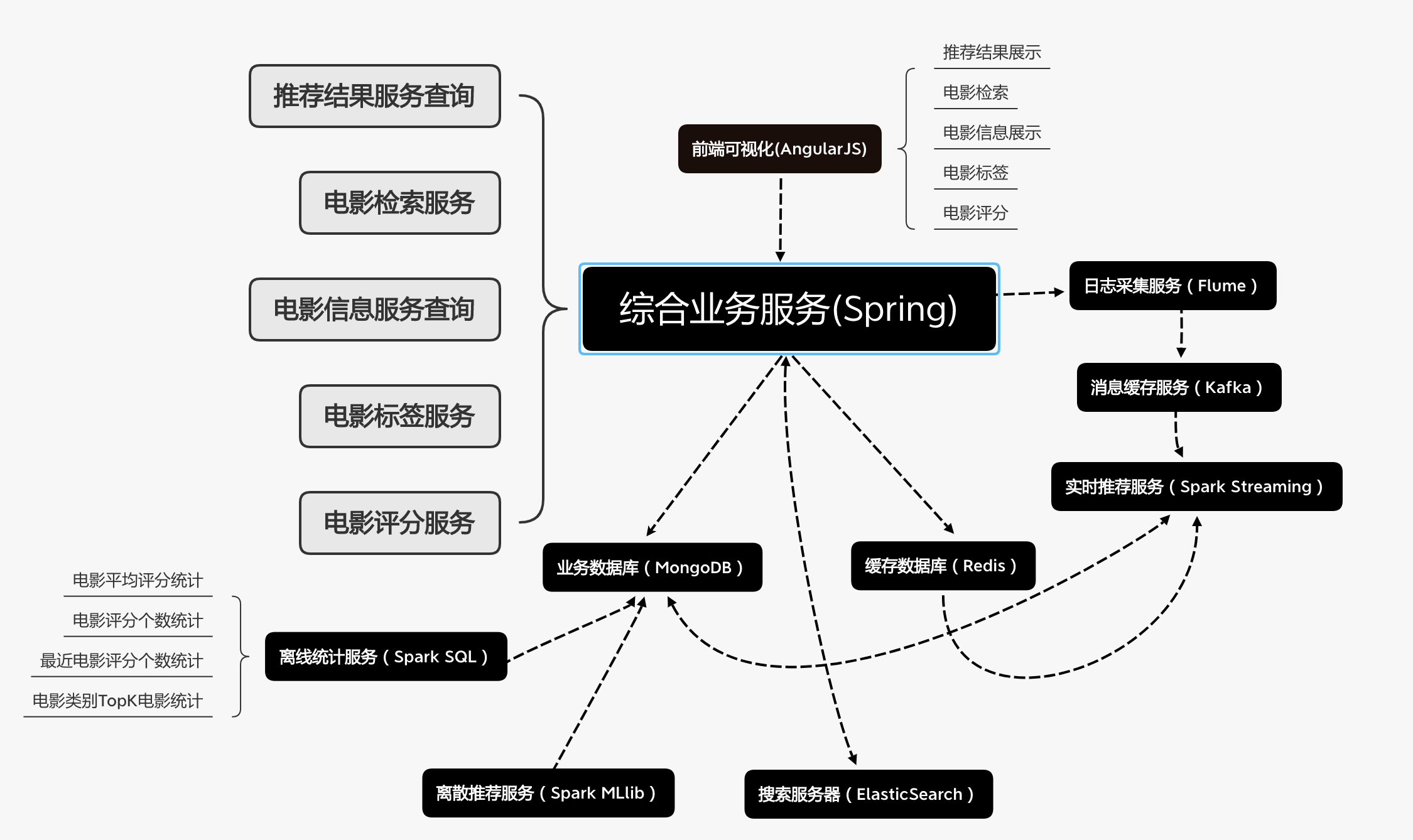
电影推荐系统架构图
链接:电影推荐系统框架.xmind
**
用户可视化
主要负责实现和用户的交互以及业务数据的展示,主体采用 AngularJS2 进行实现,部署在 Apache 服务上。
综合业务服务
主要实现 JavaEE 层面整体的业务逻辑,通过 Spring 进行构建,对接业务需求。部署在 Tomcat 上。
数据存储部分
业务数据库:项目采用广泛应用的文档数据库 MongDB 作为主数据库,主要负责平台业务逻辑数据的存储。
- 缓存数据库:项目采用 Redis 作为缓存数据库,主要用来支撑实时推荐系统部分对于数据的高速获取需求。
搜索服务器:项目采用 ElasticSearch 作为模糊检索服务器,通过利用 ES 强大的匹配查询能力实现基于内容的推荐服务。
离线推荐部分
离线统计服务:批处理统计性业务采用 Spark Core + Spark SQL 进行实现,实现对指标类数据的统计任务。
离线推荐服务:离线推荐业务采用 Spark Core + Spark MLlib 进行实现,采用 ALS 算法进行实现。
实时推荐部分
日志采集服务:通过利用 Flume-ng 对业务平台中用户对于电影的一次评分行为进行采集,实时发送到 Kafka 集群。
- 消息缓冲服务:项目采用 Kafka 作为流式数据的缓存组件,接受来自 Flume 的数据采集请求。并将数据推送到项目的实时推荐系统部分。
- 实时推荐服务:项目采用 Spark Streaming 作为实时推荐系统,通过接收 Kafka 中缓存的数据,通过设计的推荐算法实现对实时推荐的数据处理,并将结构合并更新到 MongoDB 数据库。

若有收获,就点个赞吧
0 人点赞
