
1. Intelligent Stack(智能堆叠)特征
- 网络硬件虚拟化,可以实现统一管理(最多9台)
- 实现转发平面合一
- 跨设备链路聚合
- 设备会自动备份堆叠前的配置文件,以.bak的后缀保存在FLash中
- 设备版本需要兼容(可以自动同步,Standby自动同步Master的版本,建议手工同步)
- 不同厂商接入设备堆叠
将多台设备通过专用堆叠接口(堆叠板卡)或业务口连接起来,形成的一台虚拟逻辑设备
1)连接拓扑
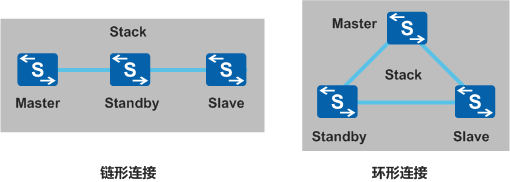
| 连接拓扑 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 链形连接 | 首尾不需要有物理连接,适合长距离堆叠 | - 可靠性低:其中一条堆叠链路出现故障,就会造成堆叠分裂 |
堆叠链路带宽利用率低:整个堆叠系统只有一条路径
| 堆叠成员交换机距离较远时,组建环形连接比较困难,可以使用链形连接 | | 环形连接 |
- 可靠性高:其中一条堆叠链路出现故障,环形拓扑变成链形拓扑,不影响堆叠系统正常工作堆叠链路带宽利用率高:数据能够按照最短路径转发
| 首尾需要有物理连接,不适合长距离堆叠 | 堆叠成员交换机距离较近时,从可靠性和堆叠链路利用率上考虑,建议使用环形连接 |
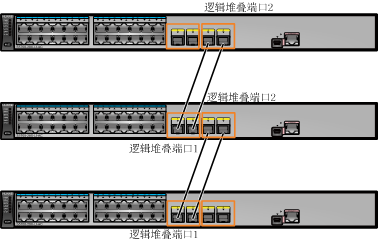
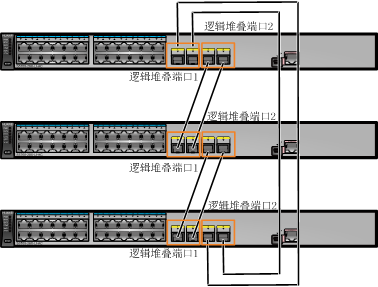
2)建立连接方式
- 堆叠卡:不用做任何配置,但距离短。不用配置指定的堆叠物理口


- 业务口:不需要堆叠卡,支持长距离堆叠。需要将物理接口加入到逻辑的堆叠口中(Stack-Port 0 和 Stack-Port 1)
- 堆叠物理/逻辑接口连接方式必须采用交叉相连(端口编号交叉 XG0/0/1 → XG0/0/2、Stack-port 0/1 → Stack-port 0/2)
3. iStack Role
1)iStack 角色类型
- iStack成员角色的产生方式:堆叠系统建立、新设备加入、堆叠分裂、堆叠合并
- Master:主设备,只能有一个,管理整个堆叠系统(向成员设备分配堆叠ID、收集成员设备的拓扑信息,计算堆叠转发表项和破环点下发给所有成员设备)
- Standby:备设备,只能有一个,在Master设备失效后接替Master工作
- Slave:成员设备,除了主备设备以外都是,主要负责业务转发(Slave设备越多,整个堆叠系统转发能力越强)
2)iStack 角色选举
- 系统运行时间越长优越先
- 成员优先级大的优先,默认100
- 成员背板MAC小的优先
4. 堆叠系统
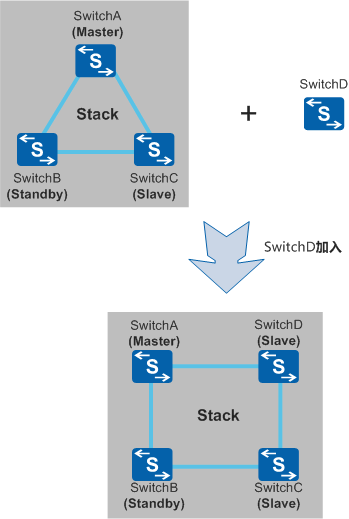
1)成员加入
在已经形成的堆叠系统中加入新的成员设备。新加入的设备,只会成为一个Slave设备,不会影响主备设备
成员加入步骤:
- 堆叠系统稳定运行
- 新加入成员配置好堆叠参数并保存断电
- 连接好堆叠线缆后上电
2)成员退出
- Master 成员退出,Standby 升为 Master 并更新 topo
- Standby 成员退出,Slave 设备之间重新选举 Standby 并更新 topo
- Slva 成员退出,更新 topo
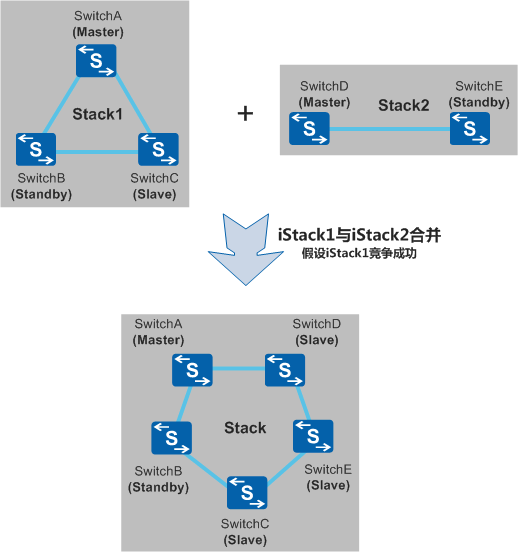
3)系统合并
将稳定运行的两个堆叠系统合并成一个堆叠系统,堆叠系统的Master进行角色竞争,竞争成功的堆叠系统的角色保持不变,竞争失败的堆叠系统全部重启,以 Slave 角色加入到堆叠系统
系统合并步骤:
- 堆叠系统稳定运行
- 两个堆叠系统之间连接堆叠线缆
- 两个堆叠主设备进行竞争
- 竞争失败的堆叠系统自动重启
- 重启后以 Slave 设备加入堆叠系统
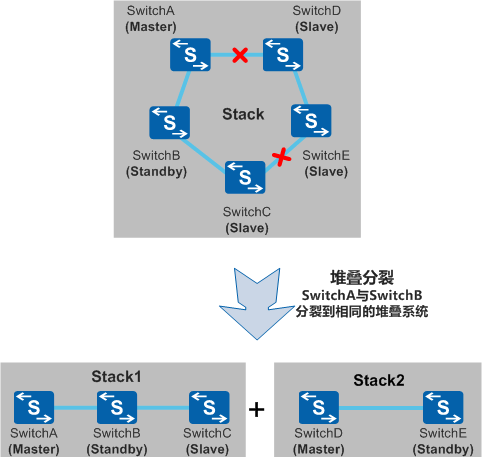
4)系统分裂
堆叠分裂会导致存在多个配置完全相同的堆叠系统(多主),业务中断。需要多主检测和冲突处理,防止业务中断
5. DAD 多主检测
直连检测和代理检测之间是互斥关系(dual-active 和 mad 都是 DAD 多主检测,只是 VRP 系统版本不同的区别)
- 堆叠系统分裂后通过 MAD 报文,检测并处理堆叠分裂的协议,降低业务中断的风险
- 堆叠状态
- Detect:正常工作状态
- Recovery:堆叠禁用状态
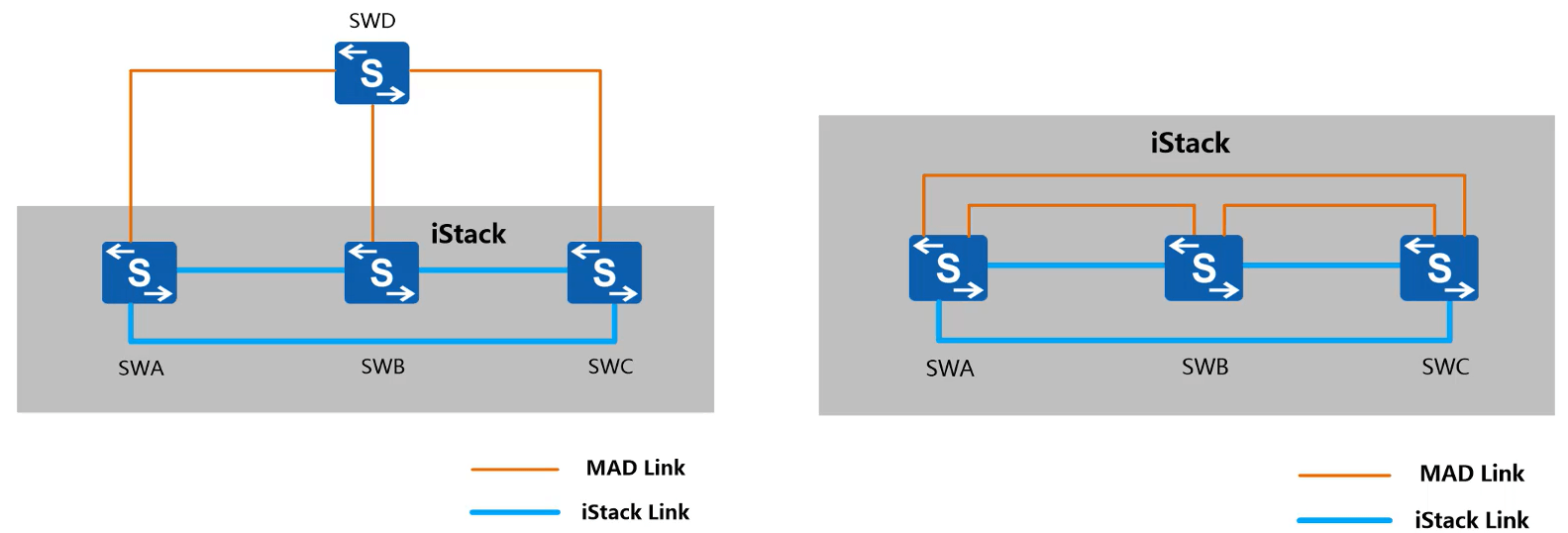
MAD 检测机制
中间设备直连方式:有可能存在中间设备故障的风险
- Full-Mesh 直连方式:堆叠设备之间通过普通线缆直连,存在占用设备额外端口的弊端
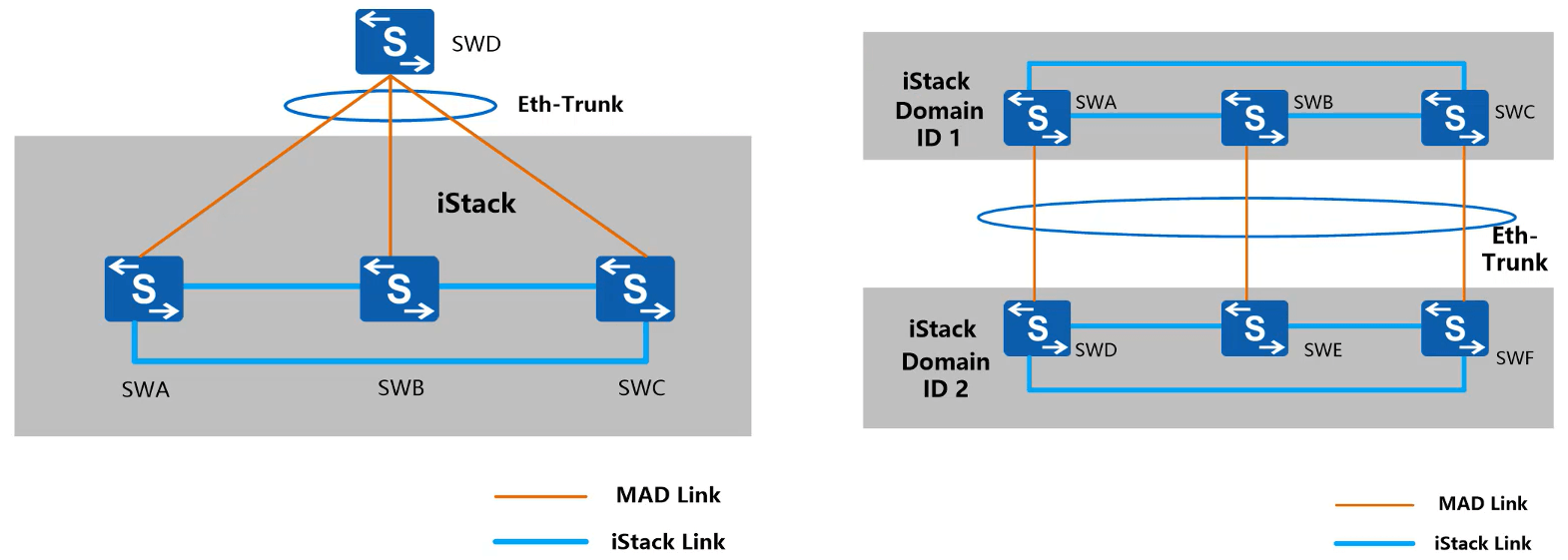
2)代理检测
- 单机代理方式:利用一台设备检测堆叠运行情况。堆叠系统和单机检测设备必须为 Eth-Trunk 模式互连和代理设备需要开启代理功能。不占用额外的接口,也可以作为业务转发
- 两套堆叠系统互为代理:两套堆叠系统互连并开启代理检测功能

若有收获,就点个赞吧
0 人点赞
