Yarn工作机制
概略流程图
核心的流程:
- 作业的提交:
Client提交作业给ReourceManager - 资源的申请:
AppMaster(MRAppMaster)向ResourceManager申请资源 - 作业状态汇报:
Container(MapTask、ReduceTask) 向Container(MRAppMaster)汇报作业的执行状态 - 节点状态汇报:
NodeManager向ResourceManager汇报节点的状态
当用户向Yarn提交一个应用(不管是MapReduce还是Spark)后,Yarn将分为两个阶段运行该应用程序:
- 客户端申请资源,启动运行本次程序的
ApplicationMaster(不同应用程序有自己不一样的ApplicationMaster,比如MapReduce的是MRAppMaster,Spark的可能是Spark自己实现的ApplicationMaster) - 由
ApplicationMaster根据本次程序内部具体情况,为它申请资源,并监控它的整个运行过程,直到运行完成
以 MapReduce的 WordCount为例:
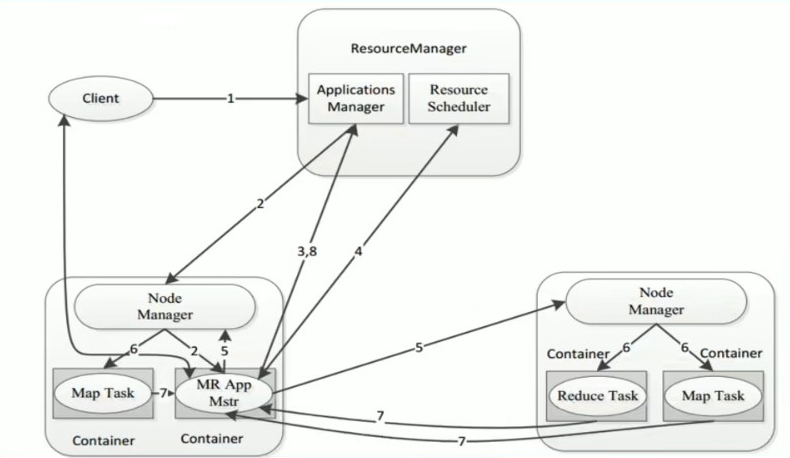
MapReduce提交Yarn的交互流程:
- 用户通过客户端向Yarn中
ResourceManager提交应用程序(jar包、切片、job参数xml等) ResourceManager为该应用程序分配第一个Container,并与对应的NodeManager通信,要求它在这个Container中启动这个应用程序的ApplicationMaster(MapReduce程序中的MRAppMaster)ApplicationMaster启动成功之后,首先向ResourceManager注册并保持通信,这样用户可以直接通过ResourceManager查看应用程序的运行状态(运行了百分之几)ApplicationMaster为本次程序内部的各个Task任务向ResourceManager申请资源,并监控它的运行状态- 一旦
ApplicationMaster申请到资源后,便于对应的NodeManager通信,要求它启动任务 NodeManager为任务设置好运行环境之后,将任务启动命令写到一个脚本中,并通过运行该脚本启动任务- 各个任务通过 RPC 协议向
ApplicationMaster汇报自己的状态和进度,让ApplicationMaster随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务。在应用程序运行过程中,用户可以随时通过RPC向ApplicationMaster查询应用程序的当前运行状态 - 应用程序运行完成后,
ApplicationMaster向ResourceManager注销并关闭自己(ApplicationMaster也是一个Container,所以也需要注销关闭)
详细流程图
Yarn执行流程图:
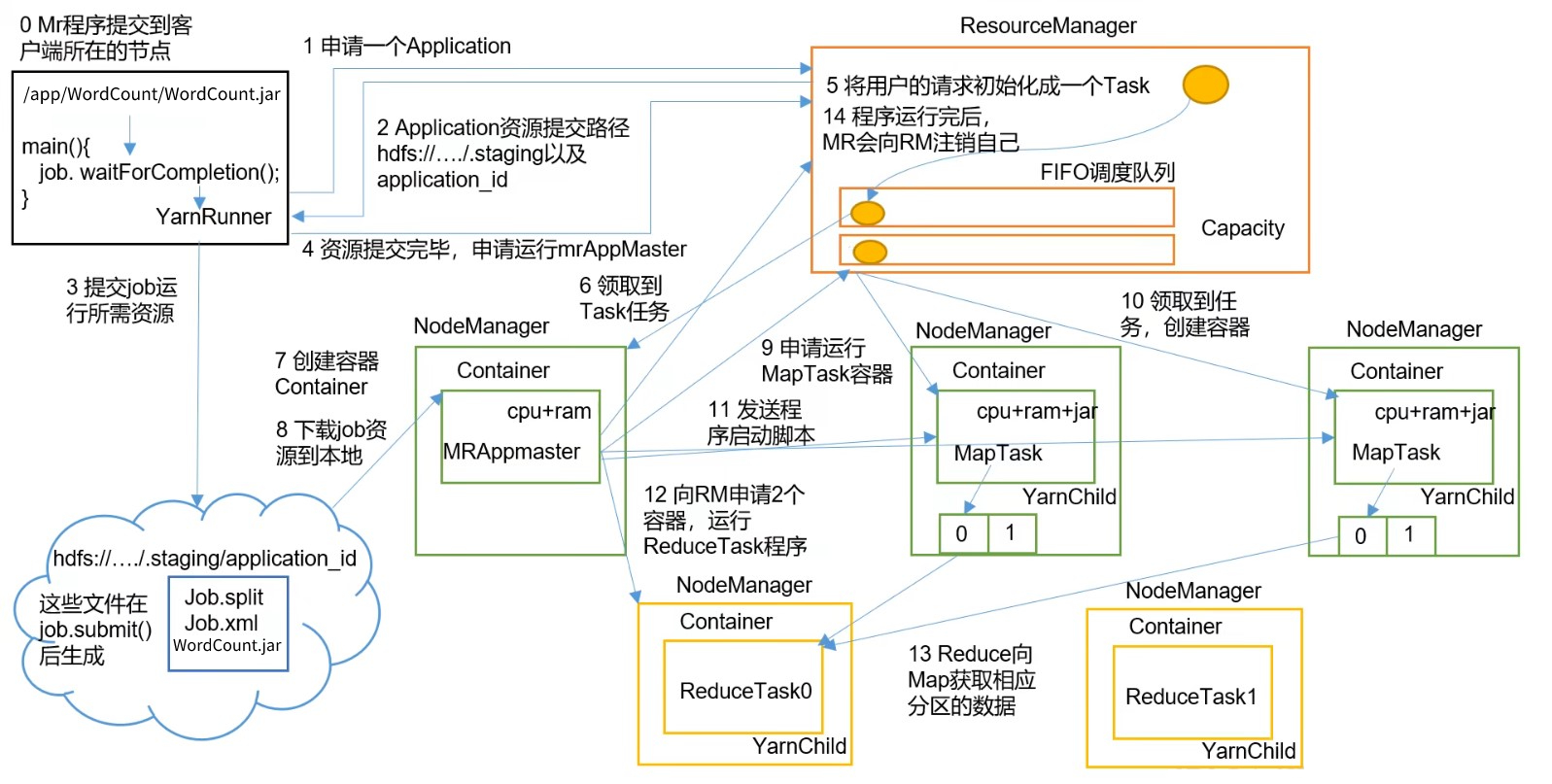
作业提交过程:
Client调用job.waitForCompletion()方法,创建一个YarnRunner(本地模式是LocalRunner)向Yarn集群的ResourceManager申请提交作业运行一个ApplicationResourceManager返回给Client一个提交资源的路径、一个Application的id,用于本次Application运行Client将运行job所需要的资源(jar包、切片、job参数xml等)提交到指定的路径Client资源提交完毕,申请运行MRAppMaster
ResourceManager处理:
ResourceManager收到用户的请求后,初始化为一个Task。
因为Yarn是一个调度平台,ResourceManager可能要同时接收多个不同的应用程序发来的 job,所以ResourceManager会将这个Task放到一个调度队列中
AppMaster处理:
- 比较空闲的
NodeManager到ResourceManager上领取任务,拿到Task - 在该
NodeManager上创建一个Container容器,并分配 CPU 和 内存,在该容器中启动MRAppMaster进程 MRAppMaster进程到集群资源路径上,将 job 的资源下载到本地MRAppMaster根据 job 资源中的切片信息,向ResourceManager申请开启MapTask容器运行MapTask
MapTask处理:
MRAppMaster向ResourceManager申请运行MapTask后,其他空闲的NodeManager向ResourceManager领取任务创建容器,分配 cpu内存,下载 jar 包。
因为MapTask是以容器为单位运行的,一个NodeManager上可以运行多个容器。所以可能出现 切片时切分了2个MapTask,结果这两个MapTask都以容器的形式在同一个NodeManager上运行。MRAppMaster向MapTask发送程序启动脚本,启动这些MapTask。这时这些运行MapTask的NodeManager上就会创建YarnChild进程进行运行。MapTask会向MRAppMaster汇报自己的进度。当运行完成时,将结果持久化到磁盘,并通知MRAppMaster。
AppMaster处理:
MRAppMaster监控到MapTask运行完毕之后,会向ResourceManager申请开启ReduceTask容器运行ReduceTask
ReduceTask处理:
- 与
MapTask类似,NodeManager领取到ReduceTask任务,创建容器,分配cpu内存。然后从Map节点获取相应分区的结果数据。ReduceTask容器运行的进程也叫做YarnChild。ReduceTask向MRAppMaster汇报进度。当运行完成时,通知MRAppMaster
AppMaster处理:
- 在所有
ReduceTask都运行完成时,AppMaster向ResourceManager申请注销AppMaster和前面的MapTask、ReduceTask。
调度器和调度算法
调度器(Resource Scheduler)是属于ResourceManager内部的一个组件,当有多个 job 提交过来的时候,使用调度器进行调度。
在理想情况下,应用程序提出的请求都将立即得到Yarn批准。但在实际中,资源是有限的,并且繁忙的在群集上。Yarn调度程序的工作是根据一些定义的策略为应用程序分配资源。
在Yarn中,负责给应用程序分配资源的就是Scheduler,它是ResourceMananger的核心组件之一。
Scheduler完全专用于调度作业,它无法跟踪应用程序的状态。
一般而言,调度并没有一个“最佳”策略,而是要根据实际情况进行调整,所以Yarn提供了多种调度器和可配置的策略供选择。
Hadoop作业调度器主要有三种:先进先出调度器(FIFO)、容量调度器(Capacity Scheduler)、公平调度器(Fair Scheduler)。
Apache的Hadoop 3.x 默认的资源调度器是 Capacity Scheduler。CDH 的yarn默认使用的是 Fair Scheduler。
可以通过配置文件配置:yarn-site.xml
<property><description>The class to use as the resource scheduler.</description><name>yarn.resourcemanager.scheduler.class</name><!-- 默认使用的 Capacity Scheduler --><value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value></property>
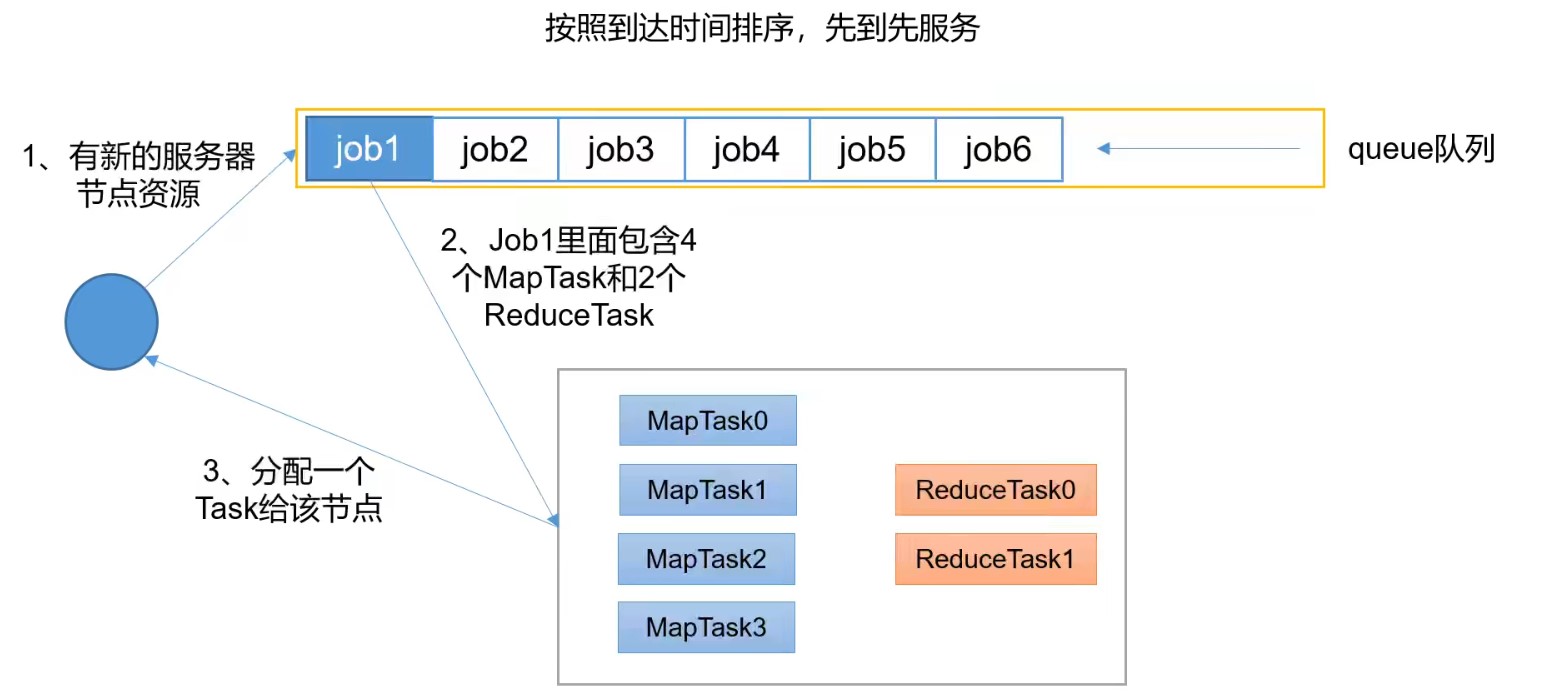
先进先出调度器(FIFO)
FIFO调度器(First In First Out):单队列,根据提交作业的先后顺序,先来先服务。调度工作不考虑优先级和范围,适用于负载较低的小规模集群。当使用大型共享集群时,它的效率较低且会导致一些问题。
FIFO Scheduler拥有一个控制全局的队列queue,默认queue名称为default,该调度器会获取当前集群上所有的资源信息作用与这个全局的queue。
优点:无需配置,先到先得,易于执行。
缺点:任务的优先级不会变高,因此高优先级的作业也需要等待,不适合共享集群。
FIFO是 Hadoop 1.x 中的 JobTracker 原有的调度器实现,在Yarn中保留了下来。实际生产中用到大数据的场景都是高并发的,所以一般不会采用这种调度器。
容量调度器(Capacity Scheduler)
Capacity Scheduler 是 Yahoo 开发的多用户调度器,是Apache版的 Hadoop 3.x 的默认调度策略。
该策略允许多个组织共享整个集群资源,每个组织可以获得集群的一部分计算能力。通过为每个组织分配专门的队列,然后再为每个队列分配一定的集群资源,这样整个集群就可以通过设置多个队列的方式给多个组织提供服务了。
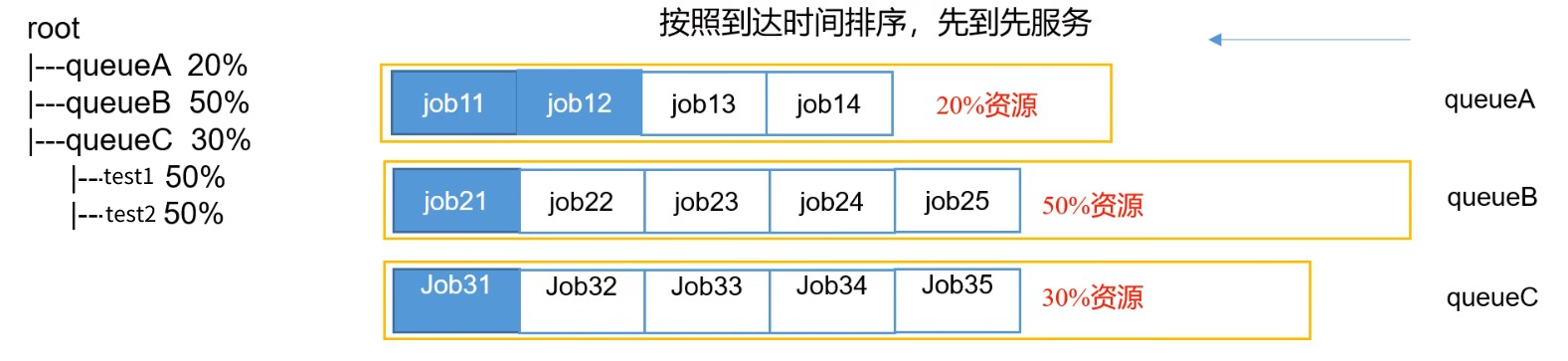
Capacity可以理解成一个个的资源队列,这个资源队列是用户自己去分配的。队列内部又可以垂直划分,这样一个组织内部的多个成员就可以共享这个队列资源了,在一个队列内部,资源的调度是采用的是先进先出(FIFO)策略。
Capacity Scheduler调度器以队列为单位划分资源。简单点说,就是一个个队列有独立的资源,队列的结构和资源是可以进行配置的。
优点:
- 层次化的队列设计(Hierarchical Queues):层次化的管理,可以更容易、更合理分配和限制资源的使用
- 容量保证(Capacity Guarantees):每个队列上都可以设置一个资源的占比,保证每个队列都不会占用整个集群的资源
- 安全(Security):每个队列有严格的访问控制。用户只能向自己的队列里提交任务,而且不能修改或访问其他队列的任务
- 弹性分配(Elasticity):空闲的资源可以被分配给任何队列;当多个队列出现争用的时候,则按照权重比例进行平衡
特点:
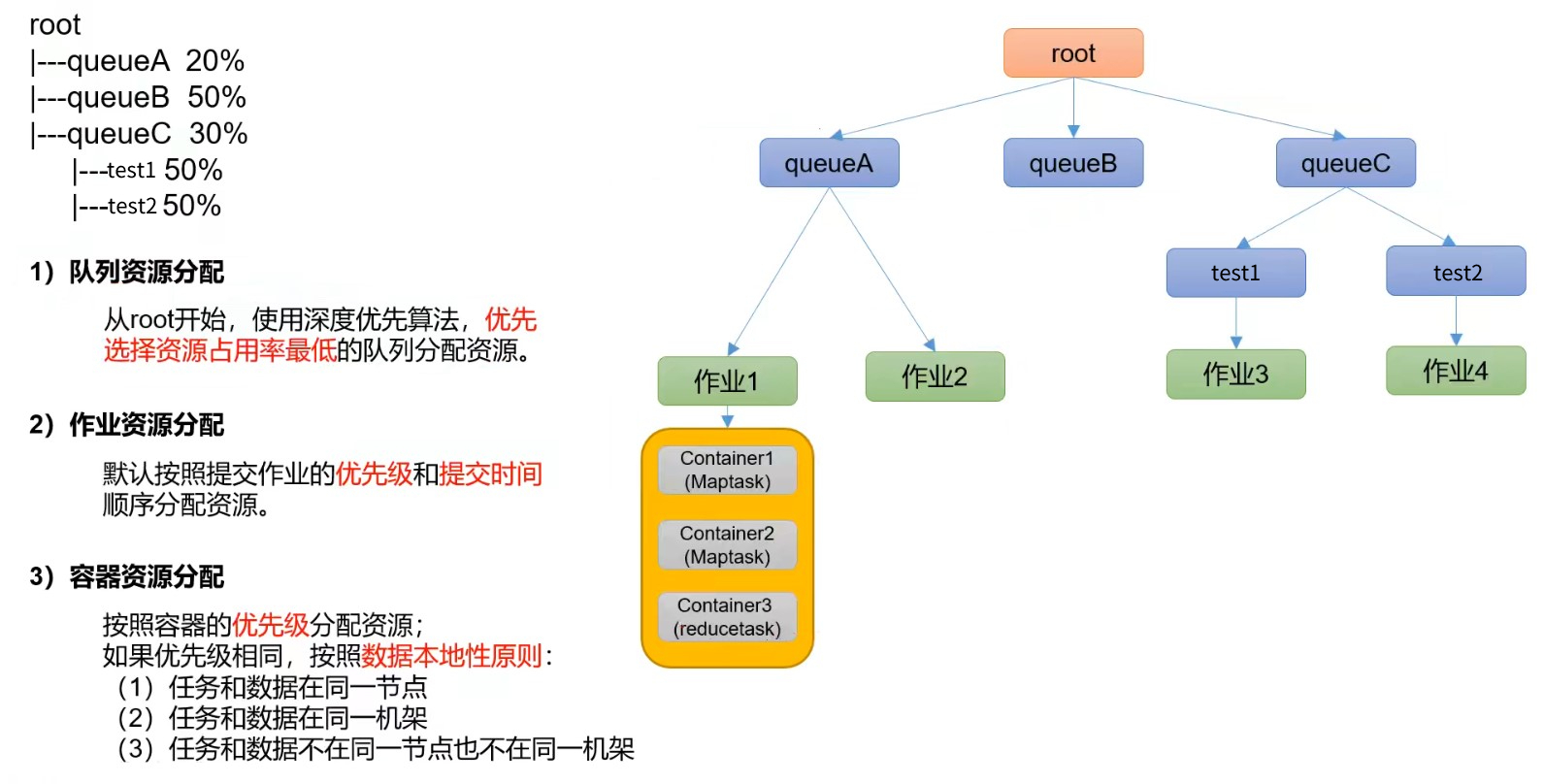
- 多队列:每个队列可配置一定的资源量,每个队列可配置一定的资源量,每个队列采用FIFO调度策略。
虽然每个队列采用的是FIFO,但是如果前一个job占用的资源较少,第二个job也可以同步执行。例如queueA中设置了8G内存,job11只消耗2G内存,那么job12就可以同步执行 - 容量保证:管理员可以为每个队列设置资源最低保证、使用上限
- 灵活性:如果一个队列中的资源有剩余,可以暂时共享给其他需要资源的队列,而一旦该队列有新的应用程序提交,则其他队列借调的资源会归还给该队列
- 多租户:支持多用户共享集群和多应用程序同时运行。为了防止同一个用户的作业独占队列中的资源,该调度器会对同一个用户提交的作业所占的资源量进行限定。
资源分配算法:
公平调度器(Fair Scheduler)
Fair Scheduler,公平调度器,是 Facebook 开发的多用户调度器。 提供了Yarn应用程序 公平地共享大型集群中资源 的另一种形式。使所有应用在平均情况下随着时间的流式可以获得相等的资源份额。
Fair Scheduler设计目标是为所有的应用分配公平的资源(对公平的定义通过参数来设置)。
公平调度可以在多个丢列建工作,允许资源共享和抢占。
优点:
- 分层队列:队列可以按层次结构排列以划分资源,并可以配置权重以按特定比例共享集群
- 基于用户或组的队列映射:可以根据提交任务的用户名或组来分配队列。如果任务指定了一个队列,则在该队列中提交任务
- 资源抢占:根据应用的配置,抢占和分配资源可以是友好的或者强制的。默认不启用资源抢占
- 保证最小配额:可以设置队列最小资源,允许将保证的最小份额分配给队列,保证用户可以启动任务。当队列不能满足最小资源时,可以从其他队列抢占。当队列资源使用不完时,可以给其他队列使用。这对于确保某些用户、组或者生产应用使用获得足够的资源
- 允许资源共享:即当一个应用运行时,如果其他队列没有任务执行,则可以使用其他队列。当其他队列有应用需要资源时再将占用的队列释放出来。所有的应用都从资源队列中分配资源
- 默认不限制每个队列和用户可以同时运行应用的数量:可以配置来限制队列和用户并行执行的应用数量。限制并行执行应用数量不会导致任务提交失败,超出的应用会在队列中等待。
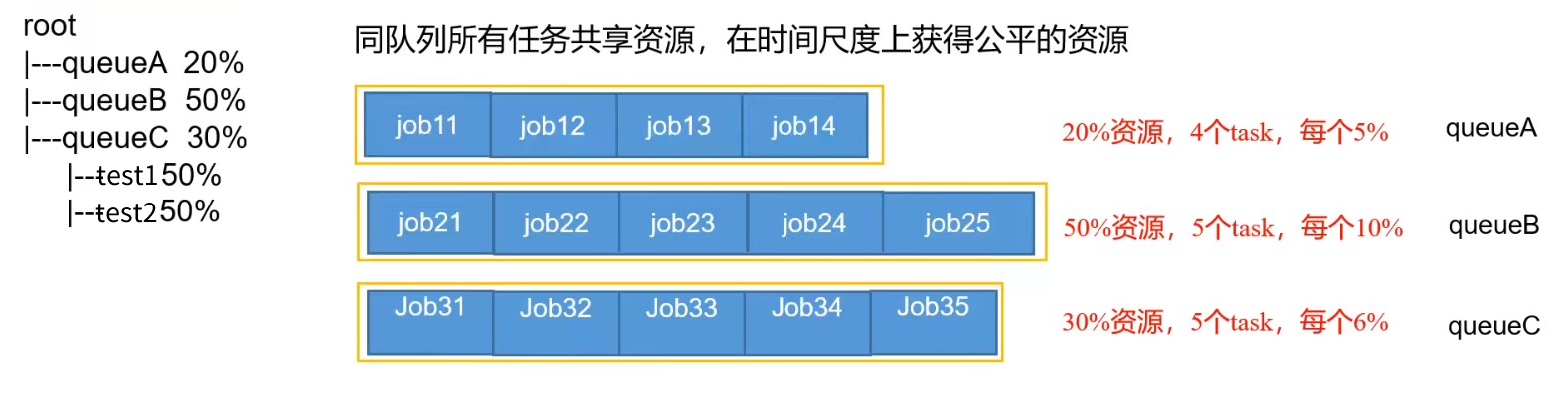
公平调度器的默认配置下:如果目前一个队列中有4个job正在运行,此时来了第5个job,这5个job共同平分整个队列的资源。
与容量调度器相同点:
- 多队列:支持多队列多作业
- 容量保证:管理员可以为每个队列设置资源最低保证、资源使用上限
- 灵活性:如果一个队列中的资源有剩余,可以暂时共享给那些需要资源的队列,而一旦该队列有新的应用程序提交,则其他队列借调的资源会归还给该队列
- 多租户:支持多用户共享集群和多应用程序同时运行;为了防止同一个用户的作业独占队列中的资源,该调度器会对同一个用户提交的作业所占资源量进行限定
公平调度器与容量调度器的核心调度策略不同:
- 容量调度器:优先选择 资源利用率低 的队列
- 公平调度器:优先选择对资源的 缺额 比例大的
公平调度器与容量调度器支持的单独设置资源分配方式不同:
- 容量调度器:FIFO、DRF
- 公平调度器:FIFO、FAIR、DRF
缺额产生的原因:
如果目前一个队列中有4个job正在运行,此时来了第5个job。理想情况下,如果使用公平调度器,第5个job进来之后马上就和前4个job平分整个队列的资源。
但是实际情况中,job5进来之后,只能先得到一点点资源,等待一段时间让其他job释放出一些资源出来。此时,第5个job应该分配的资源和实际得到的资源之间的差额就是缺额。
公平调度器设计目标是:在时间尺度上,所有作业获得公平的资源。调度器会 优先为缺额大的作业分配资源 。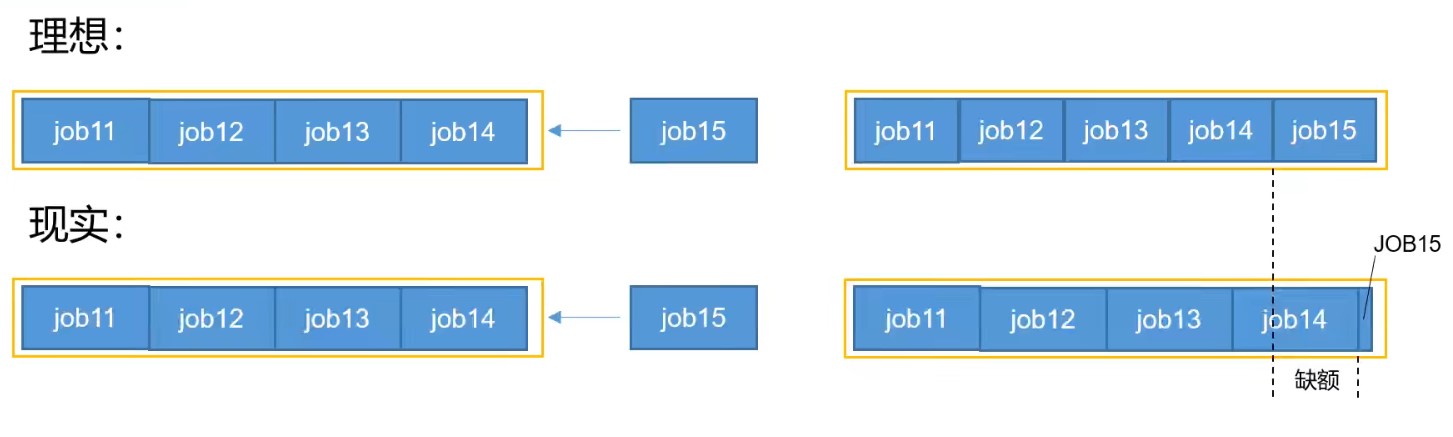
公平调度器的资源分配策略:
- FIFO策略:公平调度器每个队列资源分配策略如果选择FIFO的话,此时就相当于是容量调度器
- Fair策略(默认)
- DRF策略
Fair策略:
Fair策略是一种基于最大最小公平算法实现的资源多路复用方式,默认情况下,每个队列内部采用该方式分配资源。这意味着,如果一个队列中有两个应用程序同时运行,则每个应用程序可得到 1/2 的资源;如果三个应用程序同时运行,则每个应用程序可以得到 1/3 的资源。
具体的资源分配流程和容量调度器一致:先选择队列,再选择作业,再选择容器。这三步的每一步都是按照公平策略分配资源。(银行家算法)
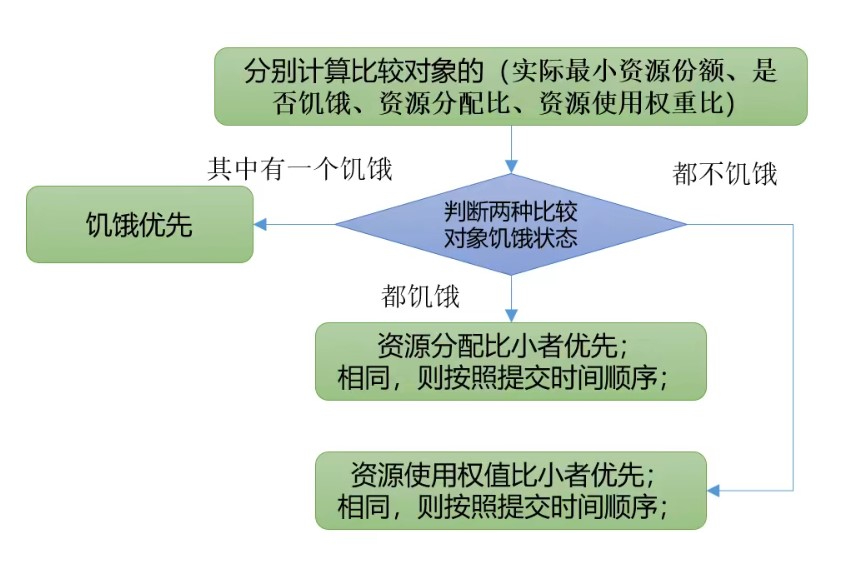
实际最小资源份额:mindshare = Min(资源需求量, 配置的最小资源)
是否饥饿:isNeedy = 资源使用量 < mindshare
资源分配比:minShareRatio = 资源使用量 / Max(mindshare, 1)
资源使用权重比:useToWeightRatio = 资源使用量 / 权重
DRF策略:(Dominant Resource Fairness)
其他的调度器分配资源时都是单一标准,例如只考虑内存(Yarn默认情况),但是很多时候我们的资源分配要同时兼顾CPU、内存、网络带宽等资源,很难衡量两个应用应该分配的资源比例。
假设集群中的应用A需要2个CPU、300GB内存,应用B需要6个CPU、100G内存,那么意味着应用A是内存主导的,应用B是CPU主导的。针对这种情况,可以选择DFR策略对不同应用进行不同资源的同一个比例限制。

若有收获,就点个赞吧
0 人点赞
