MapReduce框架原理
MapReduce框架运行流程:

InputFormat数据输入
InputFormat是一个抽象类,它有很多实现类,例如 FileInputFormat、CombineFileInputFormat、TextInputFormat等。
前面的WordCount示例中,我们使用文件输入,使用的就是 FileInputFormat。
InputFormat类有两个抽象方法:
getSplits:判断当前的输入的文件是否可以被切分createRecordReader:创建一个Reader
切片与MapTask并行度决定机制
MapTask的并行度决定Map阶段的任务处理并发度,进而影响到整个 Job 的处理速度。
数据块:Block是HDFS物理上把数据分成一块一块的,数据块是HDFS存储数据单位。
数据切片:数据切片只是在逻辑上对输入进行分片,并不会在磁盘上将其切分成片进行存储。数据切片是MapReduce程序计算输入数据的单位,一个切片会对应启动一个MapTask。
数据块是物理上的分开存储,例如一个129Mb的数据文件,在存入 hdfs 时,因为hdfs一个数据块默认大小只有128Mb,所以会被分成两个数据块存储:block0存储128Mb,block1存储1Mb,这两个数据块可能存储在不同的服务器上,这个是物理上的分开存储。
数据切片是逻辑上的切片,不是真正的物理磁盘上分开存储。例如将这个129Mb的文件切成一个100Mb和一个29Mb两个片,那么只会找个位置记录下来:0-100索引位置属于第一个片,100-129索引位置属于第二个片,并不影响物理上的存储。
切片的大小会影响到执行的效率:
如果切片个数太少,例如 1Gb 的数据只切2个切片,那么就只会有两个MapTask并行执行,效率太低;
如果切片个数太多,例如 1Kb 的数据切了5个切片,那么初始化的过程可能比真正执行花费的时间还长,效率也不高;
如果切片大小和数据块大小不一致,例如每个数据块128Mb,每个切片设置为100Mb,那么数据块上剩余的28Mb就需要通过网络IO传递给其他节点进行执行,效率也不高;
如图:对于一个300Mb的文件切成3片(即产生3个MapTask)
如果切片大小设置为100Mb(红色线条),那么:
- 第一个MapTask只能执行DataNode1上存储的128Mb数据中的100Mb
- MapTask2需要通过网络IO获取DataNode1上剩余的28Mb,加上DataNode2上的一部分,组成100Mb
- MapTask3需要通过网络IO获取DataNode2上剩余的数据,加上DataNode3上的进行处理
这样就会因为这些网络IO导致效率低下。
如果切片代销设置为128Mb(蓝色线条),那么:
- MapTask1执行本机DataNode1上的128Mb
- MapTask2执行本机DataNode2上的128Mb
- MapTask3执行本机DataNode3上的数据
没有了网络IO,效率就会高很多
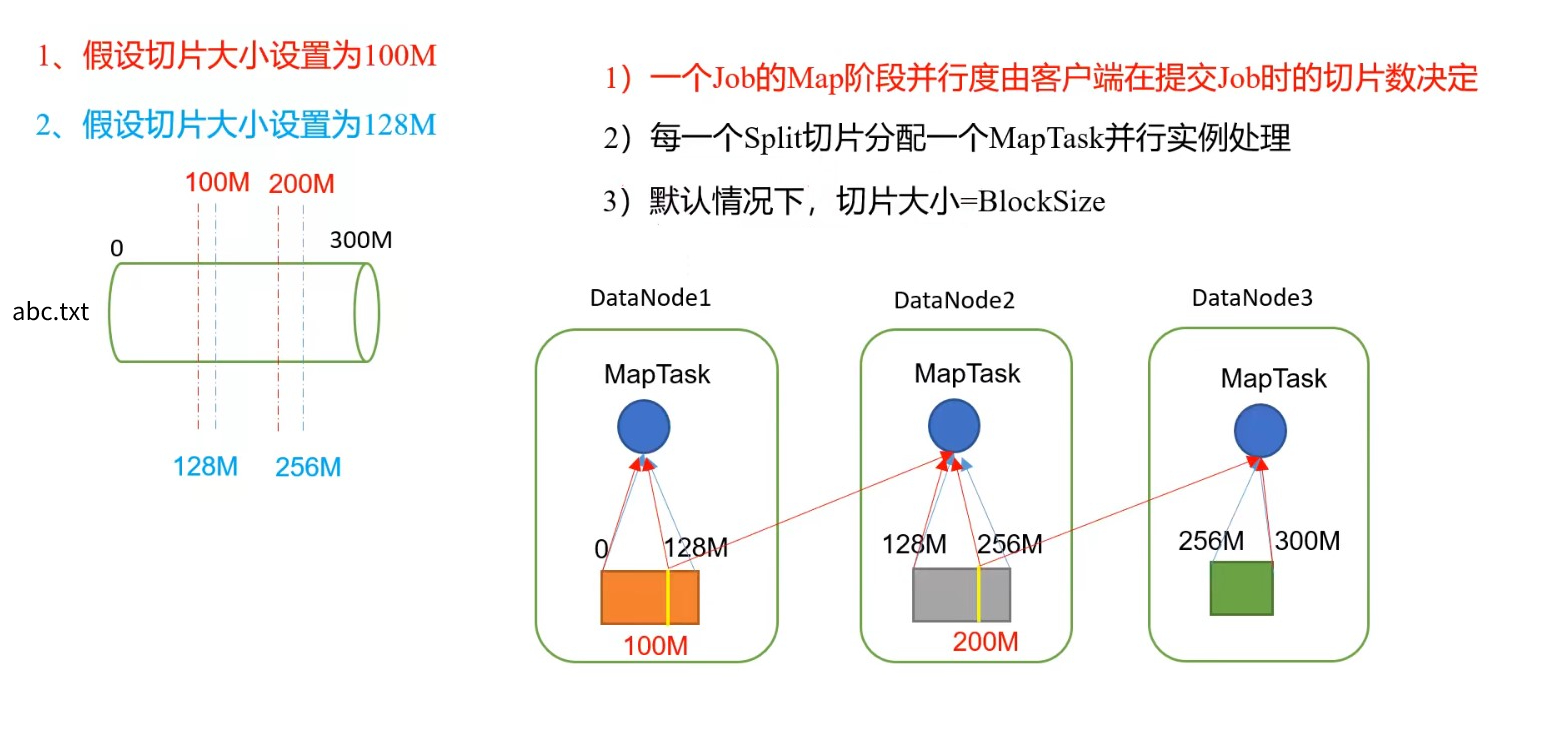
Hadoop默认参数中,切片大小就是等于数据块大小。(也可以自定义配置,但不推荐)
切片时,不考虑数据集整体,而是逐个针对每一个文件单独切片。
例如:输入数据中有两个文件(a.txt、b.txt),其中 a.txt 大小为300Mb, b.txt大小为100Mb。切片时,不会按整体400Mb切分,而是逐个对这两个文件进行切分。切片大小为128Mb的话:
先将a.txt切分成3个片:128Mb、128Mb、44Mb,然后再将b.txt切分成一个100Mb的片。最后产生4个切片、4个MapTask。
而不是将b.txt追加到a.txt上,因为b.txt的block和a.txt的block不是同一个,如果合一起切就又会产生网络IO。
job提交流程的源码分析
根据前面写的WordCount程序可知,MapReduce中真正执行job的是job.waitForCompletion(true)方法。job.waitForCompletion(true)方法中调用了submit()提交job。
submit()方法的源码如下:
public void submit() throws IOException, InterruptedException, ClassNotFoundException {ensureState(JobState.DEFINE); // 确认job的状态为DEFINE(未运行)状态setUseNewAPI(); // 如果使用的是mapred包(hadoop 1.x)中的类,做一些特殊配置进行兼容// 获取hadoop集群的连接// connect()方法内部会调用到Cluster类构造方法,Cluster构造方法会调用initialize()初始化方法// Cluster的initialize()初始化方法中,会得到两个Provider:YarnClientProtocolProvider、LocalClientProtocolProvider// 如果配置项mapreduce.framework.name的值为yarn,则使用YarnClientProtocolProvider;如果为local,则使用LocalClientProtocolProvider// mapreduce.framework.name在mapred-default.xml默认值为local,我们本地的hadoop没有修改该配置项,所以本地运行WordCount会使用本地模式运行,即输入、输出路径都是本地路径。而我们的hadoop102集群中,在mapred-site.xml中将该值配置为了yarn,所以在hadoop102上运行WordCount程序时走的是Yarn,即输入、输出路径都是hdfs路径。connect();final JobSubmitter submitter = getJobSubmitter(cluster.getFileSystem(), cluster.getClient());status = ugi.doAs(new PrivilegedExceptionAction<JobStatus>() {public JobStatus run() throws IOException, InterruptedException, ClassNotFoundException {// 向集群提交job信息return submitter.submitJobInternal(Job.this, cluster);}});state = JobState.RUNNING; // 将DEFINE(未运行)状态改为 RUNNING(运行)LOG.info("The url to track the job: " + getTrackingURL());}
submitter.submitJobInternal(Job.this, cluster)向集群提交job信息的源码:
JobStatus submitJobInternal(Job job, Cluster cluster)
throws ClassNotFoundException, InterruptedException, IOException {
// 校验output文件夹是否存在。如果存在,会抛出异常output文件夹已存在
checkSpecs(job);
Configuration conf = job.getConfiguration();
addMRFrameworkToDistributedCache(conf);
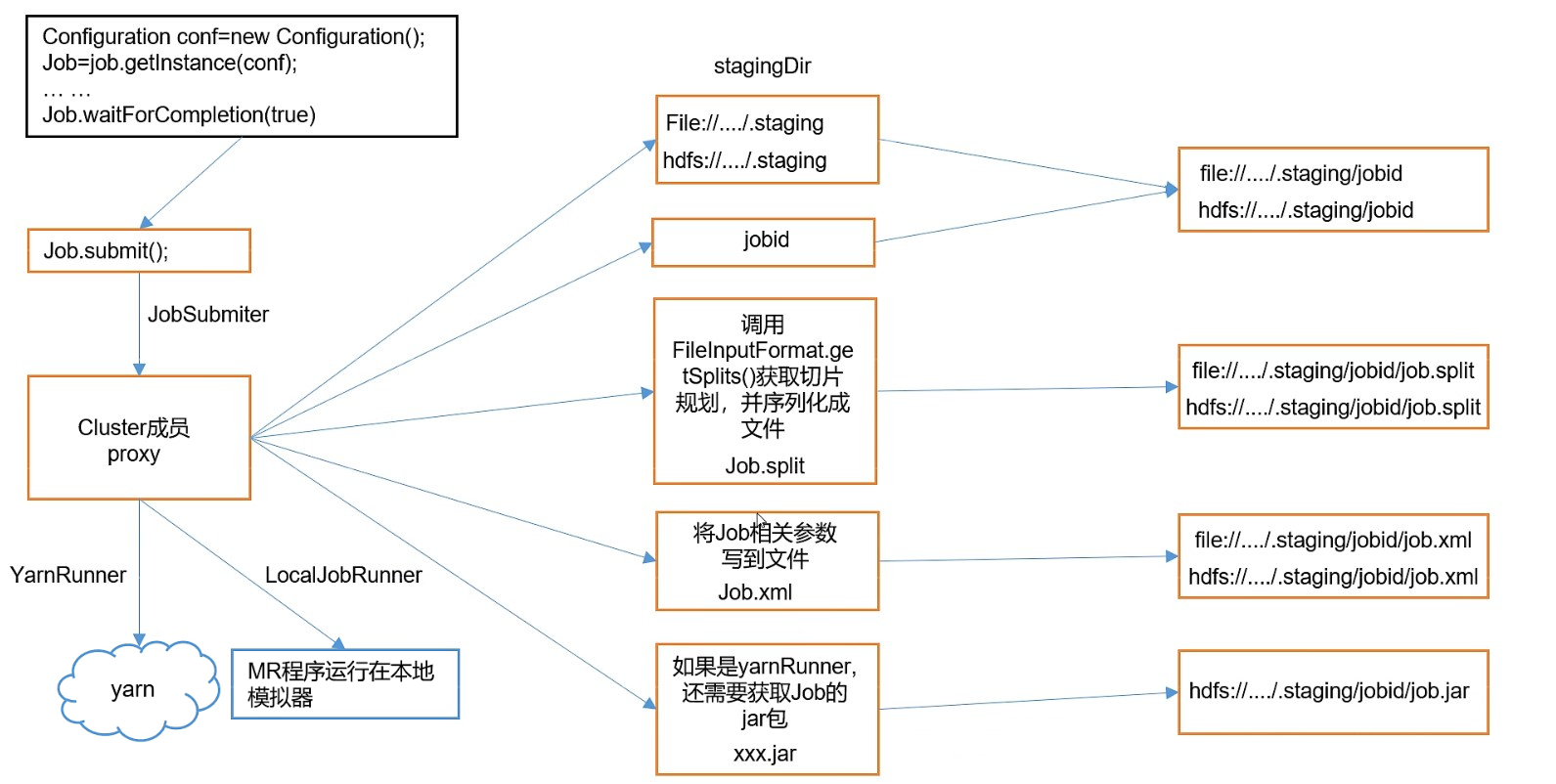
// 获取临时路径(该路径后面会用于临时存放job的切片等信息,处理完毕后该文件夹会清空)
// 该路径的前面一部分可以通过mapreduce.jobtracker.staging.root.dir进行配置
// 如果没有配置,则默认取/tmp/hadoop/mapred/staging
// 然后再后面加上 <当前用户名(用户名为空则取dummy)+随机数>/.staging
// 例如:/tmp/hadoop/mapred/staging/tengyer2113150384/.staging
Path jobStagingArea = JobSubmissionFiles.getStagingDir(cluster, conf);
// ......配置一些命令行信息。省略
// 创建一个jobID,提交的每个任务都有一个唯一的jobID,例如:job_local2113150384_0001
JobID jobId = submitClient.getNewJobID();
job.setJobID(jobId);
// 在上面创建的/tmp/hadoop/mapred/staging/tengyer2113150384/.staging基础上,
// 创建一个新的path:/tmp/hadoop/mapred/staging/tengyer2113150384/.staging/job_local2113150384_0001
Path submitJobDir = new Path(jobStagingArea, jobId.toString());
JobStatus status = null;
try {
// ........ 中间这一块是设置一些配置信息、缓存信息,省略
// 将job的jar包、依赖、配置文件等内容提交到集群
// yarn模式才会将jar包提交到集群,local模式不提交
copyAndConfigureFiles(job, submitJobDir);
Path submitJobFile = JobSubmissionFiles.getJobConfPath(submitJobDir);
LOG.debug("Creating splits at " + jtFs.makeQualified(submitJobDir));
// 切片,将切片信息临时保存到/tmp/hadoop/mapred/staging/tengyer2113150384/.staging/job_local2113150384_0001
// 会生成 job.split、.job.split.crc、job.splitmetainfo、.job.splitmetainfo.crc文件,保存切片信息
int maps = writeSplits(job, submitJobDir);
// 将切片的个数赋值给将来要创建的MapTask数量,有几个切片就有几个MapTask
conf.setInt(MRJobConfig.NUM_MAPS, maps);
LOG.info("number of splits:" + maps);
int maxMaps = conf.getInt(MRJobConfig.JOB_MAX_MAP,
MRJobConfig.DEFAULT_JOB_MAX_MAP);
if (maxMaps >= 0 && maxMaps < maps) {
throw new IllegalArgumentException("The number of map tasks " + maps +
" exceeded limit " + maxMaps);
}
// ....... 队列、缓存等信息。省略
// 在/tmp/hadoop/mapred/staging/tengyer2113150384/.staging/job_local2113150384_0001下创建 jbo.xml、.job.xml.crc
// job.xml中保存了job运行需要的配置参数信息
writeConf(conf, submitJobFile);
//
// Now, actually submit the job (using the submit name)
// 真正的提交 job
//
printTokens(jobId, job.getCredentials());
status = submitClient.submitJob(
jobId, submitJobDir.toString(), job.getCredentials());
if (status != null) {
return status;
} else {
throw new IOException("Could not launch job");
}
} finally {
if (status == null) {
LOG.info("Cleaning up the staging area " + submitJobDir);
if (jtFs != null && submitJobDir != null)
jtFs.delete(submitJobDir, true);
}
}
}
最后,在job.waitForCompletion(true)运行完monitorAndPrintJob()方法后,/tmp/hadoop/mapred/staging/tengyer2113150384/.staging/job_local2113150384_0001文件夹被清空。
程序运行示意图:
FileInputFormat切片源码分析
在submitter.submitJobInternal(Job.this, cluster)向集群提交job信息的源码中,执行到int maps = writeSplits(job, submitJobDir);时会进行切片。
writeSplits(job, submitJobDir)中,会进行判断,Hadoop 1.x的程序会调用 writeOldSplits(jConf, jobSubmitDir),Hadoop 2.x的程序会调用writeNewSplits(job, jobSubmitDir)。
writeNewSplits(job, jobSubmitDir)会调用具体的InputFormat实现类的getSplits(job)去进行切片。
以本次的WordCount程序为例,该程序使用到的InputFormat实现类为 FileInputFormat,其getSplits(JobContext job)方法源码:
public List<InputSplit> getSplits(JobContext job) throws IOException {
StopWatch sw = new StopWatch().start();
// getFormatMinSplitSize()在本类中固定返回1
// getMinSplitSize(job)获取配置项mapreduce.input.fileinputformat.split.minsize的值,在mapred-default.xml中该配置项默认值为0
// 所以两个数取最大值结果为1
long minSize = Math.max(getFormatMinSplitSize(), getMinSplitSize(job));
// 获取配置项mapreduce.input.fileinputformat.split.maxsize的值,mapred-default.xml中默认没有该配置项
// 没有该配置项时,取默认值:Long.MAX_VALUE
long maxSize = getMaxSplitSize(job);
// generate splits
List<InputSplit> splits = new ArrayList<InputSplit>();
List<FileStatus> files = listStatus(job);
boolean ignoreDirs = !getInputDirRecursive(job)
&& job.getConfiguration().getBoolean(INPUT_DIR_NONRECURSIVE_IGNORE_SUBDIRS, false);
// 循环遍历所有输入文件,分别对每个文件进行分片
// 这也证明了:切片时,不考虑数据集整体,而是逐个针对每一个文件单独切片。
for (FileStatus file: files) {
if (ignoreDirs && file.isDirectory()) {
continue;
}
// 获取文件路径、内容长度
Path path = file.getPath();
long length = file.getLen();
if (length != 0) {
BlockLocation[] blkLocations;
if (file instanceof LocatedFileStatus) {
blkLocations = ((LocatedFileStatus) file).getBlockLocations();
} else {
FileSystem fs = path.getFileSystem(job.getConfiguration());
blkLocations = fs.getFileBlockLocations(file, 0, length);
}
// 判断文件是否允许切片
// 对于普通文本文件,从文件中间截断不会有影响。
// 但是如果是一些压缩文件(有些压缩文件也支持切片),截断后内容不完整程序就无法处理类。所以一些压缩文件就只允许切成1个片(即没有切片)
if (isSplitable(job, path)) {
// 获取数据块大小。
// local本地模式,默认的数据块大小是 32Mb
// Hadoop 1.x:默认的数据块大小是 64Mb
// Hadoop 2.x/3.x:默认的数据块大小是 128Mb
long blockSize = file.getBlockSize();
// 计算切片大小
// 该方法的实现为:Math.max(minSize, Math.min(maxSize, blockSize))
// 由前面的配置可知,minSize为1,maxSize为Long.MAX_VALUE,blockSize为 32Mb(当前是本地模式运行)
// 所以 Math.min(maxSize, blockSize) = 32Mb, Math.max(minSize, 32Mb) = 32Mb
// 即:默认情况下,切片大小等于块大小
long splitSize = computeSplitSize(blockSize, minSize, maxSize);
// 进行切片,只有大于切片大小的 SPLIT_SLOP(本类中该值固定为1.1) 倍才切。
// 例如,传入一个 66Mb 的文件:
// 第一次进while时,66Mb > 35.2Mb(32Mb * 1.1), 会被切分一个 32Mb的片,剩余 34Mb
// 第二次进while时, 34Mb < 35.2Mb (32Mb * 1.1), 那么剩下的 34Mb 就不再切分了,就当做1个片处理
// 这样做的好处是:防止过度切分,导致最后一台服务器过于空闲,初始化时间比真正处理数据时间还长,拉低效率。
// 例如上面剩下的 34Mb 如果继续切分成 32Mb 和 2 Mb的片,最后处理 2Mb 的那台机器真正处理的数据量太少,造成资源浪费、效率降低
long bytesRemaining = length;
while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) {
int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining);
splits.add(makeSplit(path, length-bytesRemaining, splitSize,
blkLocations[blkIndex].getHosts(),
blkLocations[blkIndex].getCachedHosts()));
bytesRemaining -= splitSize;
}
if (bytesRemaining != 0) {
int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining);
splits.add(makeSplit(path, length-bytesRemaining, bytesRemaining,
blkLocations[blkIndex].getHosts(),
blkLocations[blkIndex].getCachedHosts()));
}
} else { // not splitable
// 对于不能切片的文件,直接设置成1个片
if (LOG.isDebugEnabled()) {
// Log only if the file is big enough to be splitted
if (length > Math.min(file.getBlockSize(), minSize)) {
LOG.debug("File is not splittable so no parallelization "
+ "is possible: " + file.getPath());
}
}
splits.add(makeSplit(path, 0, length, blkLocations[0].getHosts(),
blkLocations[0].getCachedHosts()));
}
} else {
//Create empty hosts array for zero length files
splits.add(makeSplit(path, 0, length, new String[0]));
}
}
// Save the number of input files for metrics/loadgen
job.getConfiguration().setLong(NUM_INPUT_FILES, files.size());
sw.stop();
if (LOG.isDebugEnabled()) {
LOG.debug("Total # of splits generated by getSplits: " + splits.size()
+ ", TimeTaken: " + sw.now(TimeUnit.MILLISECONDS));
}
return splits;
}
writeNewSplits方法执行完input.getSplits(job)切片后,会调用将切片信息写入stag文件夹中:JobSplitWriter.createSplitFiles(jobSubmitDir, conf, jobSubmitDir.getFileSystem(conf), array);
InputSplit只是记录了切片的元数据信息,比如切片的起始位置、长度、所在的节点列表等,并不是真的进行了切片。提交切片规划文件到Yarn上,Yarn上的MRAppMaster就可以根据切片规划文件计算开启MapTask个数。
修改切片的大小
根据切片的源码可知,切片的大小为:
long splitSize = Math.max(minSize, Math.min(maxSize, blockSize));
其中,blockSize为数据块大小,一般由磁盘读写速度决定,平时不会随便更改。
所以,如果要修改切片大小,可以通过调整 minSize、maxSize 进行修改:
- 如果想要调整的切片大小,大于数据块的大小,就需要调整
minSize的大小。max(minSize, min(Long.MAX_VALUE, blockSize))时就可以取到minSize - 如果想要调整的切片大小,小于数据块的大小,就需要调整
maxSize的大小。max(1, min(maxSize, blockSize))时 就可以取到maxSize minSize可以通过mapred-site.xml的mapreduce.input.fileinputformat.split.minsize配置(默认在mapred-default.xml中配置为0);maxSize可以通过mapred-site.xml的mapreduce.input.fileinputformat.split.maxsize配置(默认在mapred-default.xml中没有配置);
获取切片相关信息的 JavaAPI
获取切片的文件名称:
String name = inputSplit.getPath().getName();
根据文件类型获取切片信息:
FileSplit inputSplit = (FileSplit) context.getInputSplit();
TextInputFormat切片机制
FileInputFormat常见的实现类包括:TextInputFormat、KeyValueTextInputFormat、NLineInputFormat、CombineTextInputFormat、自定义InputFormat等。
TextInputFormat是FileInputFormat的默认实现类。
按行读取每条记录。
key是存储在该行在整个文件中的起始字节偏移量(即该行第一个字符在整个文件中的位置),LongWritable类型。
value是这行的内容,不包括任何终止符(换行符和回车符),Text类型
CombineTextInputFormat切片机制
默认的TextInputFormat切片机制是第任务按文件规划切片,不管文件多小,都会是一个单独的切片,都会交给一个MapTask。这样如果有大量小文件,就会产生大量的MapTask,处理效率变低。
CombineTextInputFormat用于小文件过多的场景,可以将多个小文件从逻辑上规划到一个切片中,这样多个小文件就可以交给一个或多个MapTask处理。
虚拟存储切片最大值设置:
CombineTextInputFormat.setMaxInputSplitSize(job, 4194304); // 4Mb
虚拟存储切片最大值设置最好根据实际的小文件大小情况来设置具体的值。
生成切片的过程包括虚拟存储过程和切片过程2个部分。
虚拟存储过程阶段:将输入目录下所有文件,依次和设置的setMaxInputSplitSize的值进行比较:
- 如果不大于设置的最大值,那逻辑上分为一个块;
- 如果数据大小超过设置的最大值,但是不超过最大值的2倍,则将文件均匀切分成2个块(防止出现太小的切片)
- 如果大于设置的最大值的2倍,则按照最大值切割出一块;
例如:设置最大值为 4Mb
- 输入的文件 a.txt 为 1.7Mb, 小于 4Mb,单独划分一块
- 输入的文件 b.txt 为 5.1Mb, 大于 4Mb 但小于 8Mb(4Mb的2倍),则均匀划分成2个 2.55Mb的块
- 输入的文件 c.txt 为 8.02Mb,大于 8Mb , 则先划分出一个 4Mb 的块;剩余的块大小为 4.02 Mb,大于 4Mb 但小于 8Mb ,再分成两个 2.01Mb 的块
切片过程:判断虚拟存储的文件大小是否大于 setMaxInputSplitSize
- 大于等于 则单独形成一个切片
- 小于 则和下一个虚拟存储文件进行合并,共同形成一个切片
例如我们前面的WordCount程序,如果输入的文件为多个小文件,可以在Java中配置使用CombineTextInputFormat:
job.setInputFormatClass(CombineTextInputFormat.class); // 设置使用CombineTextInputFormat,否则默认使用的是TextInputFormat
CombineTextInputFormat.setMaxInputSplitSize(job, 4194304); // 设置CombineTextInputFormat的最大值
MapReduce工作流程
概略执行过程
WordCount程序执行过程:

MapReduce概略执行过程图:
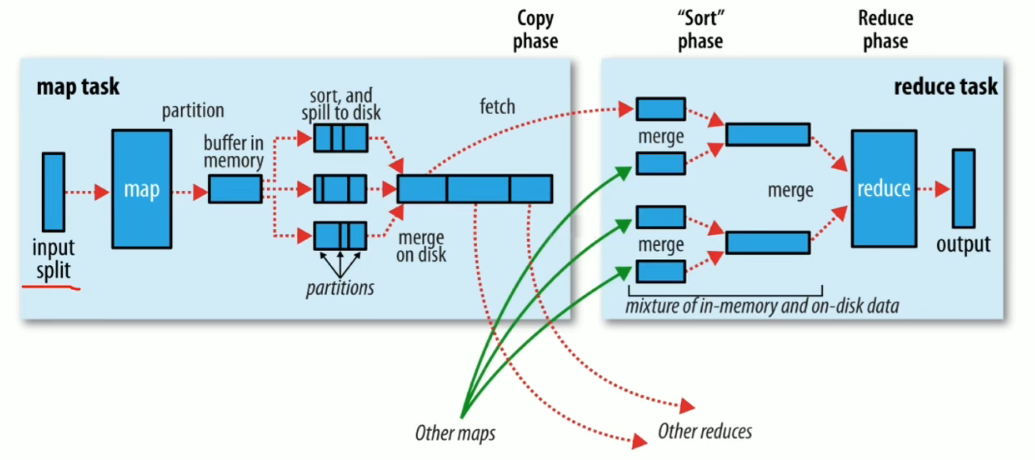
Map阶段的概略执行过程:
- 把输入目录下的文件按照一定的标准逐个进行 逻辑切片,形成切片规划。
默认切片大小等于数据块大小。
每一个切片由一个MapTask进行处理。 - 对切片中的数据按照一定的规则读取解析,并返回 key-value 键值对。
默认使用的TextInputFormat进行按行读取数据。key是每一行的起始位置偏移量,value是本行的内容 - 调用
Mapper类的**map()**方法处理数据。TextInputFormat每读取解析出一个 key-value, 就会调用一次Mapper的map()方法 - 按照一定的规则,对
Mapper输出的键值对进行分区(patition)。
分区的数量就是ReduceTask运行的数量。默认不分区,因为只有一个ReduceTask。 Mapper输出数据如果直接写到磁盘效率比较慢,所以会先写入内存缓冲区,达到比例时溢出(spill)到磁盘上。溢出的时候会根据key进行排序(sort)。
默认根据key进行字典排序- 对所有溢出文件进行最终的
合并(merge),成为一个文件
Reduce阶段的概略执行过程:
- ReducetTask会主动从MapTask复制拉取(fetch)属于自己分区的数据
- 把拉取来的数据,全部进行合并(merge),把分散的数据合并成一个大的数据。再对合并后的数据进行排序
- 对排序后的键值对调用
**reduce()**方法。
键相等的键值对会被合并成{ key1: [value1_1, value1_2, value1_3], key2:[value2_1, value2_2] }的形式,每个键调用一次reduce()方法。 - 最后把这些输出的键值对写入到 hdfs 文件中
详细的执行过程
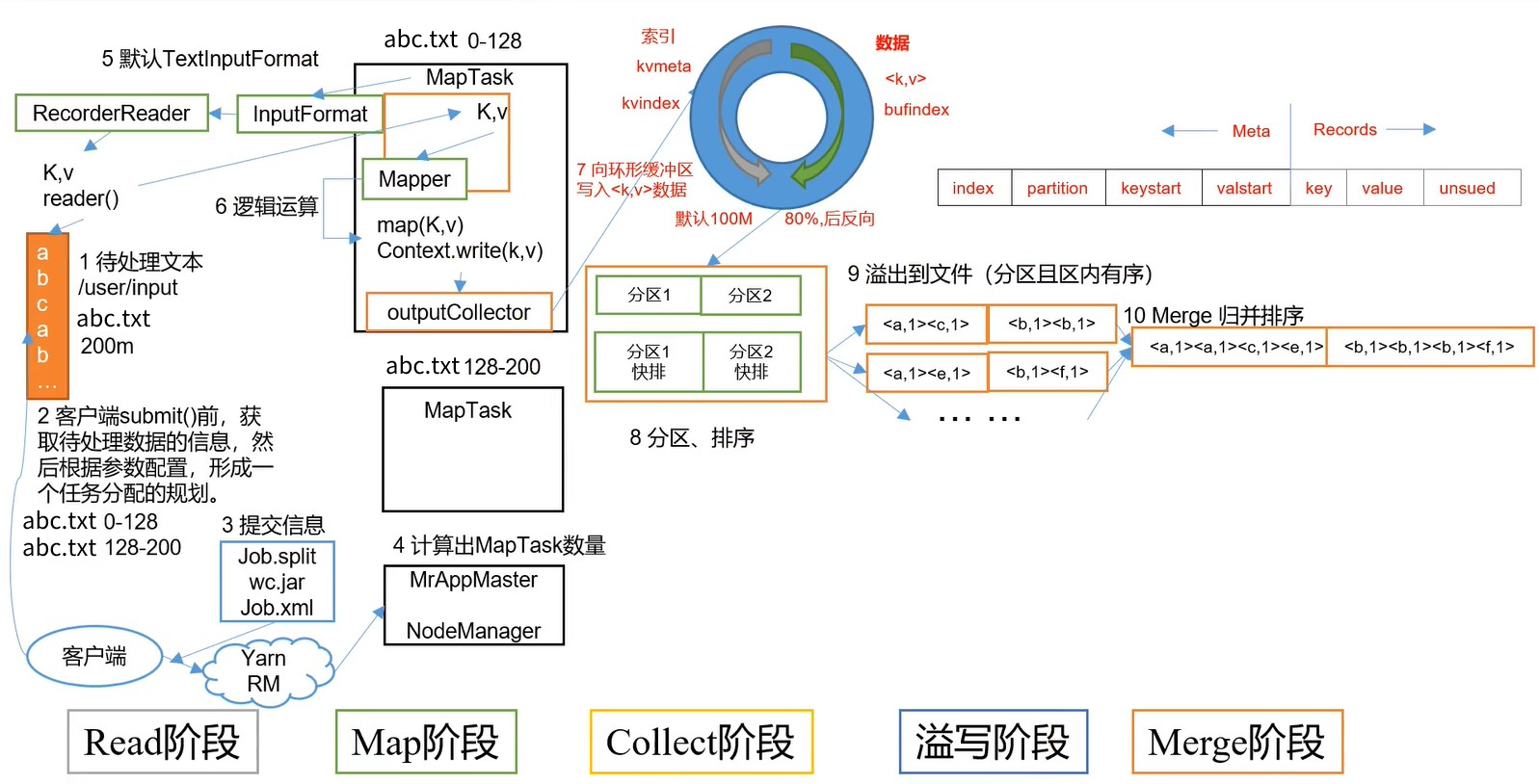
MapReduce工作流程图(一):

流程:
- 客户端准备待处理文本
- 客户端在真正
submit()前,规划好需要切分的片,在stage文件夹生成切片信息、job信息、jar包等文件 - 将stage中的切片信息文件、job信息、jar包提交给Yarn
- Yarn根据切片信息,进行切片划分MapTask
- MapTask中首先由
InputFormat处理文件(默认是FileInputFormat的实现类TextInputFormat),如果isSplit方法判断结果允许分片,则创建RecorderReader读取文件并处理成为 key-value形式(TextInputFormat创建的是LineRecordReader,处理结果中 key 为偏移量,value为这一行的内容)。将处理的 key-value 传递给Mapper作为输入 Mapper对传入的 key-value 进行逻辑运算,并将结果通过context.write(key, value)输出给ouputCollectorMapper的 key-value 结果会写到内存中的环形缓冲区中。因为计算结果直接输出到磁盘时,效率比较低下,所以设计了一个缓冲区。先将结果存入缓冲区,达到比例时才溢出(spill)写到磁盘上,溢写的时候根据 key 进行排序(默认根据key字典序排序)。
在写入环形缓冲区之前,会先按照一定的规则对Mapper输出的键值对进行分区(partition)。默认情况下,只有一个ReduceTask,所以不分区。最后分区的数量就是ReduceTask的数量。
环形缓冲区默认100Mb,分为两部分,一部分用来写索引(记录key和value的位置、分区信息等元数据),一部分用来写真实的数据记录。
当环形缓冲区中存储的数据达到 80% 时,就开始逆着向磁盘中溢写:找到索引和数据的中间位置,倒序着向磁盘中写入。此时因为缓冲区还剩20%,所以即使有新数据进来也可以正常写入到内存缓冲区。
当环形缓冲区达到100%时,因为末尾的数据刚刚已经溢写到了磁盘,所以数据可以反方向的向环中写入,覆盖掉已经写入磁盘中的数据。如果内存中的数据写入过多,将要覆盖掉还没写入磁盘的数据时,程序就会进入等待,等这部分数据被写入磁盘后,内存中新数据才能将这部分旧数据覆盖。- 存入的数据会记录分区信息,当数据达到 80% 时,在溢写前会先进行排序,使用的是快排算法。排序时是修改的索引元数据中的
keystart、valuestart,而不是直接移动 key-value - 数据每达到一次 80%,就产生一次溢写文件,最后就会产生大量的溢写文件。
每次溢写只产生一个溢写文件,虽然有多个分区,但是这些分区数据都存储在这一个溢写文件中,只是会把它们在一个文件中分隔开。 - 对第9步产生的大量溢写文件进行合并(merge)和排序。
因为第9步的文件中,每个文件在第8步时都单独进行了排序,所以每个文件内部都是有序的。所以再对这些有序文件进行排序时,就可以使用归并排序算法。
合并后的文件依然是按不同分区分隔的,所以排序时也是按照分区进行排序的,不同分区并没有进行整体排序。 - 预聚合,对分区内的相同 key 进行一次预聚合,方便后面发送给下一步。但是预聚合有前提条件,不是每次都能预聚合,例如:
{a: 1, a: 1, b: 1}被合并为:{a:2, b:1}
接上图,MapReduce工作流程图(二):
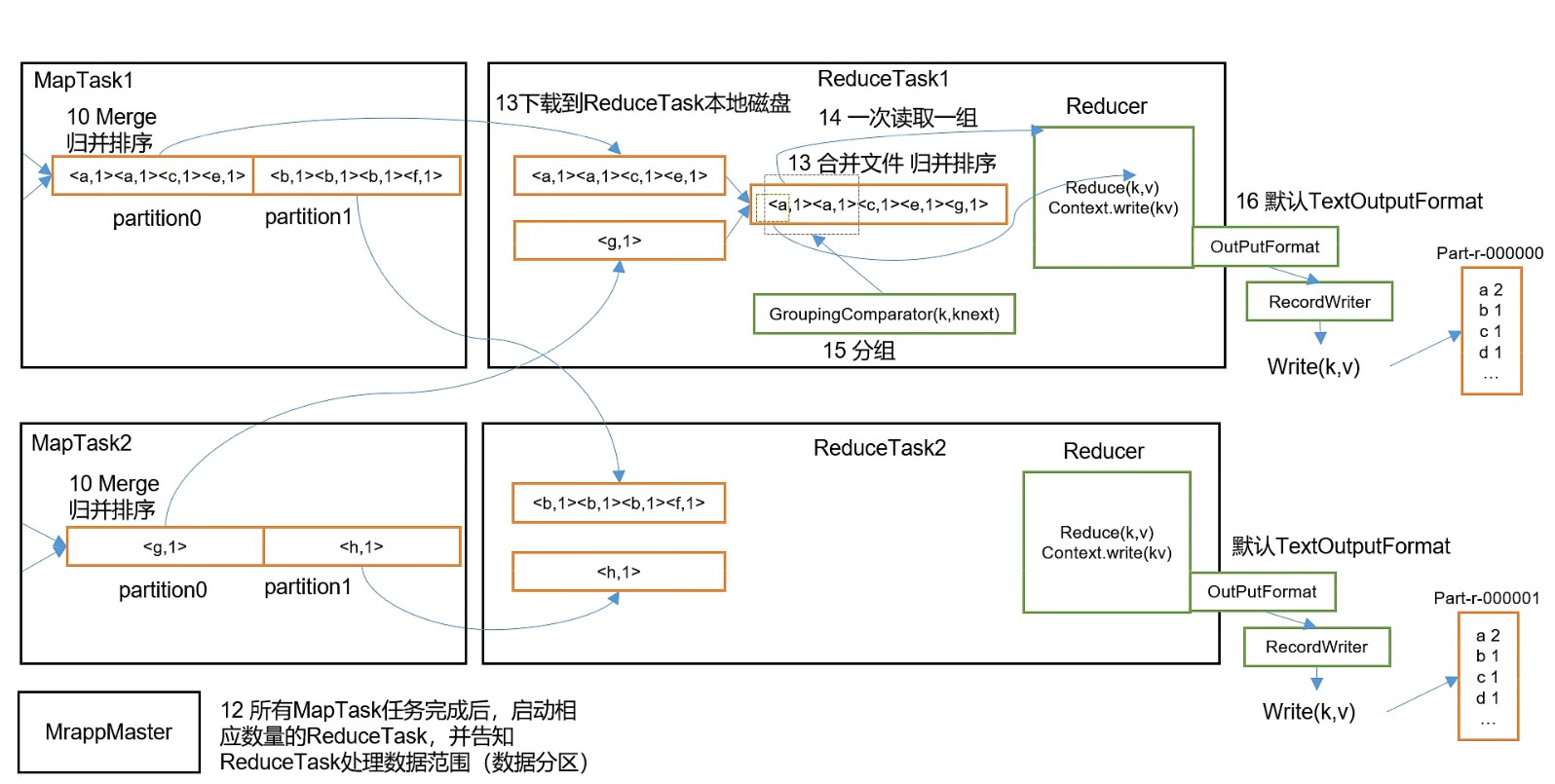
流程:接上面的步骤
- MapTask任务完成后,启动对应数量的ReduceTask处理。
对于数据量较少的文件,一般都会等所有的MapTask都完成时才启动ReduceTask。
但是对于MapTask特别多时,可以配置推测执行等策略,在部分MapTask工作完成后就进行部分Reduce合并 - ReduceTask主动从MapTask拉取自己指定分区的数据(不是MapTask推送给ReduceTask)。
每个MapTask的指定分区内数据是有序的,但是ReduceTask会对应多个MapTask,所以还需要对该ReduceTask拿到的所有MapTask指定分区的数据进行合并和归并排序。 - 因为13步进行了归并排序,所以可以从前向后遍历所有的 key-value, 如果 key 和前一个相同,就接着获取下一个 key ,直到出现不同的 key ,然后将前面的这些相同 key 的值作为一个集合,连同 key 一起将这一组内容传入
reduce()方法。在reduce()方法中执行对应的业务逻辑 - 还可以进行分组操作
- 将
reduce()方法的结果写成数据文件,使用的是OutputFormat(默认使用的TextOutputFormat)
Shuffle机制
Map方法之后、Reduce方法之前的数据处理过程称之为Shuffle。
Shuffle的本意是洗牌、混洗的意思。把一组有规则的数据尽量打乱成无规则的数据。而在MapReduce中,Shuffle更像是洗牌的逆过程,将Mapper端的无规则输出,按照指定的规则“打乱”成具有一定规则的数据,以便Reducer端接收处理。
Shuffle是MapReduce程序的核心和精髓,也是MapReduce被诟病最多的地方。MapReduce相比较于Spark、Flink计算引擎慢的原因,和Shuffle机制有很大关系。
Shuffle中频繁涉及到数据在内存、磁盘之间的多次往复。
Shuffle流程
Mapper端的Shuffle:
- Collect阶段:将MapTask的结果收集输出到默认大小为100M的环形缓冲区,保存之前会对 key 进行分区的计算,默认hash分区
- Spill阶段:当内存中的数据量达到一定的阈值时,就会将数据写入本地磁盘。在将数据写入磁盘之前需要对数据进行一次排序的操作。如果配置了
combiner,还会将有相同分区号和key的数据进行排序。 - Merge阶段:把所有溢出的临时文件进行一次合并操作,以确保一个MapTask最终只产生一个中间数据文件。
Reducer端的Shuffle:
- Copy阶段:ReduceTask启动Fetcher线程到已经完成MapTask的节点上复制一个属于自己的数据
- Merge阶段:在ReduceTask远程复制数据的同时,会在后台开启两个线程对内存到本地的数据进行合并操作
- Sort阶段:在对数据进行合并的同事,会进行排序操作。由于MapTask阶段已经对数据进行了局部的排序,ReduceTask只需保证Copy的数据最终整体有效性即可。
Shuffle整体流程:

Partition分区
将统计结果按照条件输出到不同文件中(分区),比如将MapReduce结果按照手机号前3位输出到不同的文件中。
分区的个数决定了会产生多少个ReduceTask,也决定了最后生成的结果文件。
当不配置ReduceTask个数时,默认只有1个ReduceTask,也就只有1个分区。此时走的分区类是Hadoop的一个内部类,其分区方法getPartition会固定返回一个0,即最后所有的结果都生成到0号文件(part-r-00000)中。
当配置了ReduceTask个数大于1,但是没有指定分区类时,Hadoop 默认使用的分区类是HashPartitioner,分区方式是 hash分区 :
将key取 hash 值,然后对ReduceTask个数取余。key.hashcode() % numReduceTask(每个分区都会产生一个ReduceTask,所以ReduceTask个数就是分区个数)
例如,设置ReduceTask个数为2,最后生成的结果文件中,就会按照 key 的 hash 将结果存入2个结果文件中:
// 设置ReduceTask个数为2,
// 每个ReduceTask产生一个结果文件,最后就会产生2个结果文件:0号文件(part-r-00000)、1号文件(part-r-00001)
// 按照key的hash值,对2取余,结果为0的存入0号文件,结果为1的存入1号文件
job.setNumReduceTasks(2);
用户可以自定义分区类Partitioner:
- 自定义类,继承
Partitioner,实现getPartition()分区方法 - 在 job 驱动类中,设置使用自定义的Partitioner:
job.setPartitionerClass(MyPartitioner.class);
- 根据自定义Partitioner的逻辑,设置相应数量的ReduceTask:
job.setNumReduceTasks(5);
自定义Partitioner:
package com.study.mapreduce.partition;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
/**
* 根据手机号前3位分区
*/
public class MyPartitioner extends Partitioner<Text, IntWritable> {
@Override
public int getPartition(Text key, IntWritable value, int numPartitions) {
String phoneStart = key.toString().substring(0, 3);
int result = 0;
// 分区号必须从0开始,逐一增加
switch (phoneStart) {
case "133":
result = 0;
break;
case "139":
result = 1;
break;
case "192":
result = 2;
break;
case "188":
result = 3;
break;
default:
break;
}
return result;
}
}
在Driver中配置使用该分区类,根据分区类中的逻辑设置ReduceTask个数:
// 设置分区类、ReduceTask个数
job.setPartitionerClass(MyPartitioner.class);
job.setNumReduceTasks(4);
如果Partitioner中分区结果有 5 个,而设置的ReduceTask个数是 4 个(比分区个数少),程序运行时就可能出现 IOException:Illegal partition for xxxx(4)。
如果设置的ReduceTask为1,那么就不会走我们的Partitioner,而是全部输出的0号文件(走的Hadoop默认的Partitioner内部类)。
如果Partitioner中分区结果有5个,但是设置的 ReduceTask 个数是 6 个,程序可以正常运行,最后会产生 6 个结果文件,且第6个结果文件是空的。这样最后分配的第6个ReduceTask被浪费了,分配了该节点但是没有处理数据。
总结:
- 如果 ReduceTask的数量 >
getPartition的结果数,程序可以正常运行,但是会产生几个空的输出文件,最后几个分配的节点没有处理数据,空耗资源; - 如果 1 < ReduceTask的数量 <
getPartition的结果数,则有部分数据没有ReduceTask处理,会抛出IOException; - 如果 ReduceTask的数量 = 1,则不管有没有设置自定义分区类,最终走的都是Hadoop默认的一个固定返回0的分区类,只会分配一个ReduceTask,也只会产生一个结果文件;
- 如果ReduceTask的数量 = 0,则表示不进行Reduce汇总,Hadoop也不会再进行Shuffle,直接将MapTask的结果输出到文件
- 分区
getPartition方法中,分区号必须从0开始,逐1增加
WritableComparable排序
MapTask和ReduceTask均会对数据按照key进行排序。该操作是Hadoop的默认行为,任何应用程序中的数据均会被排序,不管业务逻辑上是否需要。
默认的排序是按照字典顺序排序,且实现该排序的方法是快速排序算法。
所以mapper()方法的结果中,key必须要是可以排序的。
对于MapTask,它会将处理的结果暂时放到环形缓冲区中,当环形缓冲区使用率达到一定阈值后,再对缓冲区中的数据进行一次快速排序,并将这些有序数据溢写到磁盘上,而当数据处理完毕后,它会对磁盘上所有文件进行归并排序。
对于ReduceTask,它从每个MapTask上远程拷贝(拉取fetch)相应的数据文件。如果文件大小超过一定阈值,则溢写到磁盘上,否则存储在内存中:
- 如果内存中文件大小或数目超过一定阈值,则进行一次合并后溢写到磁盘上;
- 如果磁盘上文件数目达到一定阈值,则进行一次归并排序以生成一个更大的文件;
- 当所有数据拷贝完毕后,ReduceTask统一对内存和磁盘上的所有数据进行一次归并排序;
排序分类:
- 部分排序:MapReduce根据输入记录的 key 对数据集进行排序,保证输出的每个文件内部有序。
- 全排序:最终输出结果只有一个文件,且文件内部有序。实现方式是只设置一个ReduceTask。但该方法在处理大型文件时效率低,因为一台机器处理完所有文件,完全丧失了MapREduce所提供的并行架构。
- 辅助排序(
GroupingComparator分组排序):在Reduce端对 key 进行分组。应用于:在接收的key为bean对象时,想让一个或几个字段相同的key进入同一个reduce方法时,可以采用分组排序。 - 二次排序:在自定义排序过程中,如果
compareTo中的判断条件为两个,即为二次排序。
如果使用自定义的 JavaBean 作为key传输,那么这个 JavaBean 需要实现 WritableComparable 接口并重写compareTo方法。
WritableComparable接口继承了Writable和Comparable。我们也可以直接在 JavaBean 里面实现Writable和Comparable
对输出的value排序
MapReduce只能对 key 进行排序,无法对 value 进行排序。
如果想要对 value 进行排序,则需要分两个MapReduce进行:
- 第一个MapReduce计算出想要得到的 key-value;
- 然后将第一个 MapReduce 的 value 作为第二个 MapReduce 的 key 进行排序;
例如,第一个MapReduce的结果为:(格式手机号开头\t数量)
133111 3
133222 0
133333 1
139111 3
139222 1
139333 4
192111 2
192222 2
192333 0
188111 1
188222 0
需要对第一个结果文件的value进行排序,则第二个MapReduce的写法:
Mapper
package com.study.mapreduce.secondarycomparable;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* 对第一个MapReduce产生的结果的value进行排序。
* MapReduce不支持对value进行排序,所以需要拆成两个MapReduce,将第一个MapReduce的结果的value作为第二个MapReduce的key
*/
public class SecondaryComparableMapper extends Mapper<LongWritable, Text, IntWritable, Text> {
private IntWritable outKey = new IntWritable();
private Text outValue = new Text();
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, IntWritable, Text>.Context context) throws IOException, InterruptedException {
String[] valueArray = value.toString().split("\t");
outValue.set(valueArray[0]);
outKey.set(Integer.valueOf(valueArray[1]));
context.write(outKey, outValue);
}
}
Reducer:
package com.study.mapreduce.secondarycomparable;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class SecondaryComparableReducer extends Reducer<IntWritable, Text, Text, IntWritable> {
@Override
protected void reduce(IntWritable key, Iterable<Text> values, Reducer<IntWritable, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {
// 逐个输出,不能再汇总
// 因为第一个MapReduce才是计算,这个MapReduce只是对第一个MapReduce的value排序
for (Text value : values) {
context.write(value, key); // 将 key-value 再颠倒一下,还原成第一个MapReduce的样子
}
}
}
Driver:
package com.study.mapreduce.secondarycomparable;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class SecondaryComparableDriver {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
Configuration config = new Configuration();
Job job = Job.getInstance(config);
job.setJarByClass(SecondaryComparableDriver.class);
job.setMapperClass(SecondaryComparableMapper.class);
job.setReducerClass(SecondaryComparableReducer.class);
job.setMapOutputKeyClass(IntWritable.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 将第一个MapReduce的结果文件作为本地MapReduce的输入文件
FileInputFormat.setInputPaths(job, new Path("/app/WordCount/output/output15"));
FileOutputFormat.setOutputPath(job, new Path("/app/WordCount/output/output16"));
boolean success = job.waitForCompletion(true);
System.exit(success ? 0 : 1);
}
}
Combiner合并
在Reducer之前,对当前Mapper计算结果先进行一次小的合并再输出。例如第一个MapTask上计算结果是{a:1, a:1, a:1, b:1, c:1, c:1},经过Combiner合并后,MapTask输出结果为{a:3, b:1, c:2}。(Combiner只对当前MapTask合并,而Reducer是对从MapTask上拉取来的所有数据进行合并)
特点:
Combiner是MR程序中Mapper和Reducer之外的一种组件。即Combiner不是必须的,可以选择性的添加- 自定义
Combiner组件的父类也是Reducer Combiner和Reducer的区别在于运行的位置:Combniner是在MapTask所在的节点运行;Reducer是接收全局所有Mapper的输出结果;Combiner的意义就是对每一个MapTask的输出进行局部汇总,以减小Reducer从Mapper拉取时的网络传输流量Combiner能够应用的前提是:不能影响最终的业务逻辑。而且Combiner输出的 key-value 应该能够跟Reducer的输入 key-value 类型对应起来。
编写自定义Combiner:
package com.study.mapreduce.combiner;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* Combiner就是一个小的Reducer,继承的类也是Reducer
* 只在当前的MapTask上运行,对当前MapTask上的结果进行汇总
*/
public class MyCombiner extends Reducer<Text, IntWritable, Text, IntWritable> {
IntWritable outValue = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable value : values) {
sum += value.get(); // value是IntWritable类型,需要调用get()进行类型转换
}
outValue.set(sum);
context.write(key, outValue);
}
}
在 job 中使用 Combiner:
// 设置Combiner
job.setCombinerClass(MyCombiner.class);
Combiner虽然运行在MapTask上,但是其属于Shuffle阶段。而Shuffle阶段是为了沟通Map阶段和Reduce阶段的。所以,如果 ReduceTask 数量设置为0(即没有ReduceTask阶段),也就不会执行Shuffle阶段,也就不会运行 Combiner。
// 将 ReduceTask 数量设置为0,程序就不会运行ReduceTask。
// 没有ReduceTask,也就不会执行Shuffle阶段,所以Shuffle阶段的Combiner也就不会执行
job.setNumReduceTasks(0);
最终生成的结果文件为:part-m-00000(中间的m表示这个结果文件是MapTask阶段输出的),结果文件中并没有Combiner对MapTask的汇总。
一般情况下,Combiner和Reducer的逻辑完全一样,所以可以直接将Reducer设置到Combiner中:
// 因为MyCombiner和WordCountReducer的逻辑完全一样,所以可以直接使用Reducer
job.setCombinerClass(WordCountReducer.class);
OutputFormat数据输出
OutputFormat是MapReduce输出的基类,所有MapReduce的输出类都实现了 OutputFormat接口。
默认使用的是OutputFormat下的 FileOutputFormat下的TextOutputFormat。
自定义OutputFormat:例如在FileOutputFormat基础上自定义
- 自定义类,继承
FileOutputFormat - 改写
FileOutputFormat中实现RecordWrite的内部类FilterRecordWriter
自定义OutputFormat示例:
package com.study.mapreduce.output;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.RecordWriter;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.util.UUID;
/**
* 自定义输出:
* 在job中设置输出文件夹路径,如果结果的key带有spring就输出到指定文件夹下的test01.txt,否则输出到指定文件夹下的test02.txt
*/
public class MyOutputFormat extends FileOutputFormat<Text, IntWritable> {
@Override
public RecordWriter<Text, IntWritable> getRecordWriter(TaskAttemptContext job) throws IOException, InterruptedException {
// 返回一个我们自定义的输出Writer
MyRecordWriter writer = new MyRecordWriter(job);
return writer;
}
}
/**
* 自定义RecordWriter类,需要继承RecordWriter
*/
class MyRecordWriter extends RecordWriter<Text, IntWritable> {
private FSDataOutputStream fsOut1;
private FSDataOutputStream fsOut2;
public MyRecordWriter(TaskAttemptContext job) {
try {
// 创建输出流
FileSystem fileSystem = FileSystem.get(job.getConfiguration());
String defaultPath = "/app/WordCount/myoutput/" + UUID.randomUUID().toString();
String pathParent = job.getConfiguration().get(FileOutputFormat.OUTDIR, defaultPath); // 读取job设置的输出路径
// 创建两个输出的文件
// 获取job中配置的SpringFileName、OtherFileName
String subPath1 = pathParent + "/" + job.getConfiguration().get("SpringFileName");
String subPath2 = pathParent + "/" + job.getConfiguration().get("OtherFileName");
fsOut1 = fileSystem.create(new Path(subPath1));
fsOut2 = fileSystem.create(new Path(subPath2));
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 写操作
*/
@Override
public void write(Text key, IntWritable value) throws IOException, InterruptedException {
// 根据key是否为spring,输出到指定文件
if("spring".equalsIgnoreCase(key.toString())) {
fsOut1.writeBytes(key + "@" + value + "\n");
} else {
fsOut2.writeBytes(key + "@" + value + "\n");
}
}
/**
* 关闭IO流
*/
@Override
public void close(TaskAttemptContext context) throws IOException, InterruptedException {
IOUtils.closeStream(fsOut1);
IOUtils.closeStream(fsOut2);
}
}
在 job 中使用我们自定义的OutputFormat:
// 设置自定义OutputFormat
job.setOutputFormatClass(MyOutputFormat.class);
// 给job添加一个属性,用作配置输出文件路径。属性名为FileOutputFormat.OUTDIR常量
// 程序中可以通过 job.getConfiguration().get(FileOutputFormat.OUTDIR) 获取
// FileOutputFormat的 _SUCCESS 文件默认也会生成到该路径下
FileOutputFormat.setOutputPath(job, new Path("/app/WordCount/myoutput/output1"));
// 给job再添加两个属性SpringFileName、OtherFileName
job.getConfiguration().set("SpringFileName", "test01.txt");
job.getConfiguration().set("OtherFileName", "test02.txt");
MapTask、ReduceTask工作机制
MapTask工作流程图:
ReduceTask工作机制:
MapTask的并行度由切片个数决定,切片个数由输入文件和切片规则决定。
ReduceTask的并行度同样影响整个 job 的执行并发度和效率,但与MapTask的并发数不同,ReduceTask数量可以直接手工设置:
// 设置ReduceTask的个数,默认值是1
job.setNumReduceTasks(4);
当ReduceTask = 0 时,表示没有Reduce阶段,输出的文件个数和MapTask个数一致(直接将MapTask的结果输出到文件。
ReduceTask默认值是1,且OutputFormat默认每个ReduceTask有1个结果文件,所以最终输出的文件只有1个。
如果ReduceTask个数设置为1,即使设置了自定义分区,最后依然使用Hadoop默认的不分区。即 执行分区的前提是 ReduceTask 个数大于1。
如果数据分布不均匀,就可能在Reduce阶段产生数据倾斜。此时如果分区不合理,就会造成某几个ReduceTask过于繁忙,而其他的ReduceTask又过于空闲。
有些情况下需要计算全局的汇总结果,这种情况就只能有1个ReduceTask。

若有收获,就点个赞吧
0 人点赞
